阅读更多
1 Introduction
In the context of a database management system (DBMS), a relation refers to a table that stores related data in rows and columns. This table can be a physical table or a temporary table, like value set, join output etc.
关系型代数(Relational algebra)
| 符号 | 含义 |
|---|---|
σ |
Select, Choose a subset of the tuples from a relation that satisfies a selection predicate |
π |
Projection, Generate a relation with tuples that contains only the specified attributes |
∪ |
Union, Generate a relation that contains all tuples that appear in either only one or both input relations |
∩ |
Intersection, Generate a relation that contains only the tuples that appear in both of the input relations |
- |
Difference, Generate a relation that contains only the tuples that appear in the first and not the second of the input relations |
× |
Product, Generate a relation that contains all possible combinations of tuples from the input relations |
⋈ |
Join, Generate a relation that contains all tuples that are a combination of two tuples (one from each input relation) with a common value(s) for one or more attributes |
⋉ |
Left semi join, gives only those rows in the left rowset that have a matching row in the right rowset. It will not return any columns of the right rowset, so it makes no difference if it matches one or more times |
⋊ |
Right semi join, opposite to left |
⟕ |
Left outer join |
⟖ |
Right outer join |
ρ |
Rename |
← |
Assignment |
δ |
Duplicate Elimination |
γ |
Aggregation |
τ |
Sorting |
÷ |
Division |
2 Advanced Sql
Relational Languages:用户只需要描述结果,而无需描述如何获取结果
Sql支持的语法:
Aggregations + Group ByString / Date / Time OperationsOutput Control + RedirectionSORTLIMIT
Nested QueriesWindow FunctionsCommon Table ExpressionsWITHWITH RECURSIVE
COMMON TABLE EXPRESSIONS
3 Storage 1
存储架构,从上往下依次是:
RegistersL1 Cache、L2 Cache、L3 CacheDRAMSSDHDDNetwork Storage
- 1-3是易失性存储(
volatile storage) - 4-6是非易失性存储(
non-volatile storage)
设计目标:
- 允许
DBMS管理超过内存大小的数据 - 由于直接读写磁盘的开销很大,因此需要避免产生大停顿

为什么不直接使用OS?几乎所有的DMBS都希望完全掌控如下事情:
- 将脏页(
Dirty Page)以合适的顺序刷入磁盘 Prefetching以提高缓存命中率- 缓存替换策略
- 线程调度
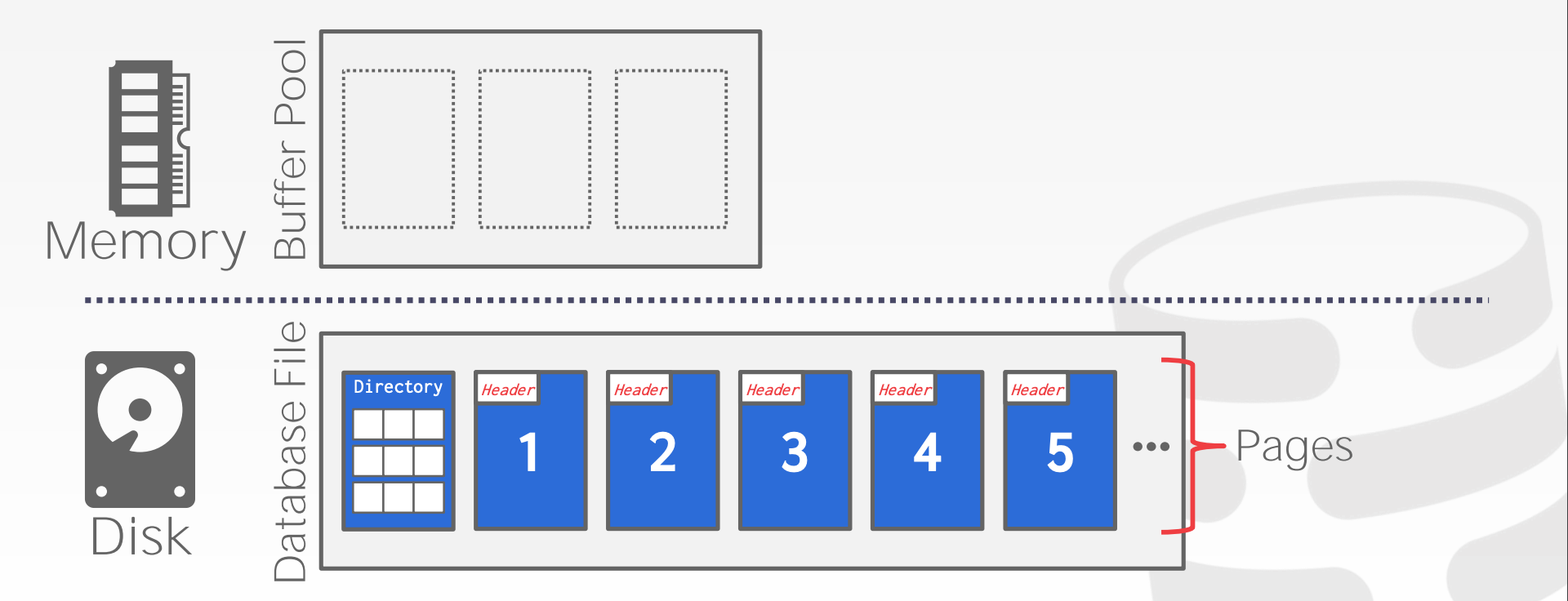
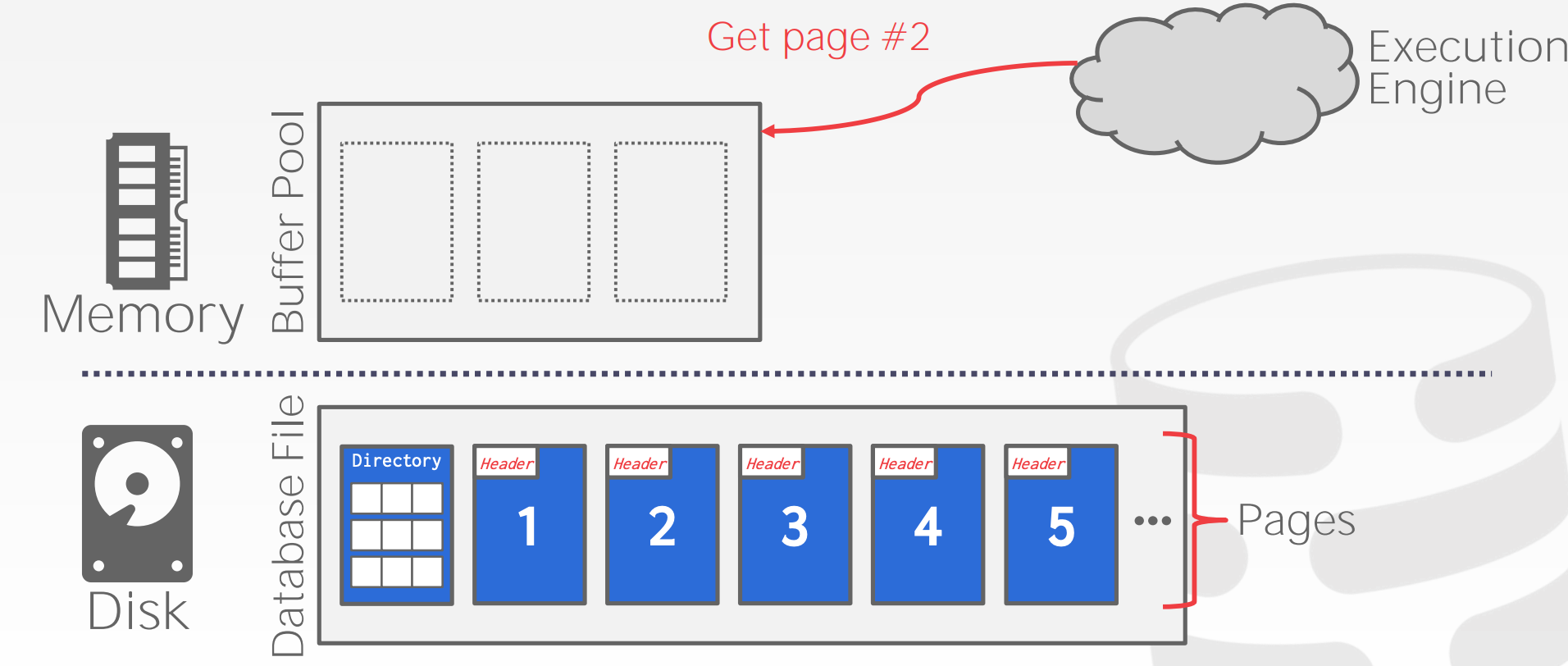
3.1 File Storage
Storage Manager:
- 管理文件,对读写任务进行调度,以提高时间上以及空间上的局部性
- 以
Page的形式管理文件
Database Pages:
- 一个
Page指的是固定大小的数据 - 每个
Page都由一个唯一的标识,该标识可以映射到物理位置 - 该
Page不是Hardware Page也不是OS Page - 组织
Page的形式有如下几种Heap File OrganizationHeap File中包含了一组无序的Page- 实现方式有2种:
Linked List- 每个
Heap File存储2个指针,分别指向Free Page List以及Data Page List - 每个
Page存储2个指针,分别指向Next以及Prev 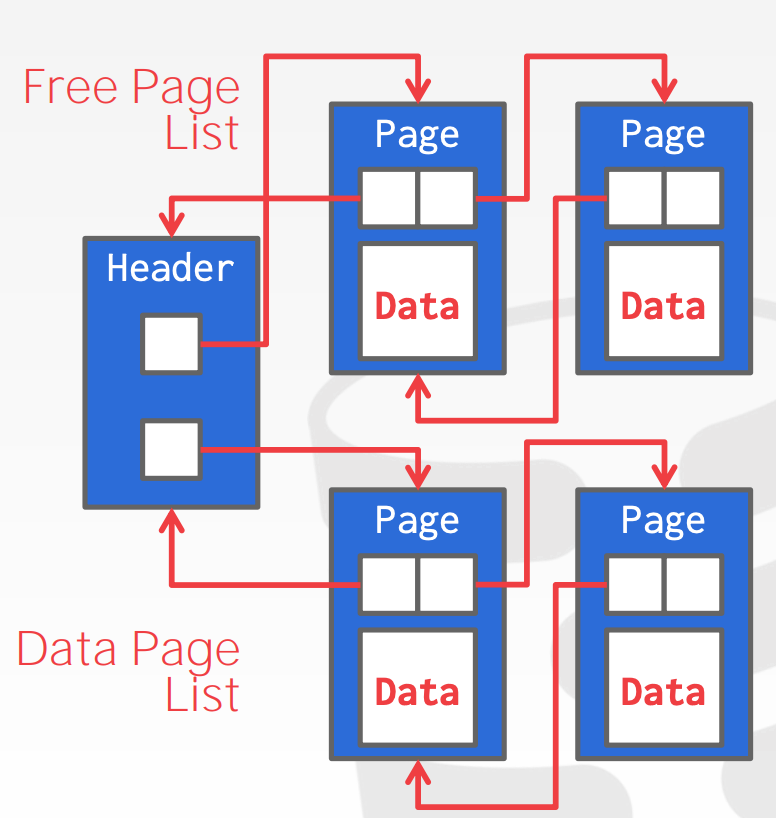
- 每个
Page Directory
Sequential / Sorted File OrganizationHashing File Organization
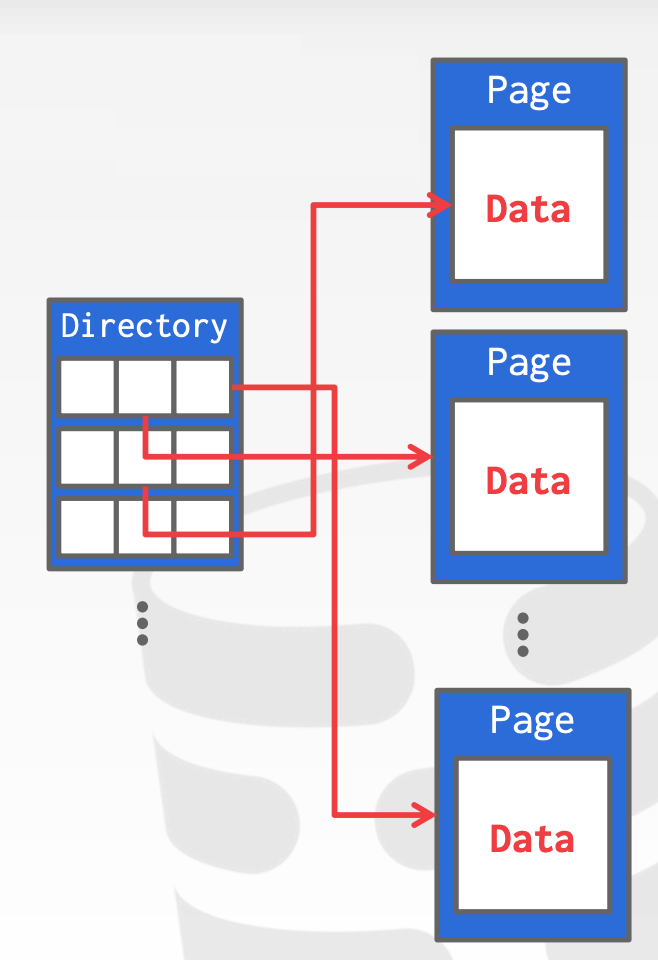
3.2 Page Layout
Page Header:每个Page都包含一个Header用以存储元数据,包括:
Page SizeChecksumDBMS VersionTransaction VisibilityCompression Information
Slotted Pages:
Slot Array中的Slots存储的是对应Tuple的起始偏移量- 同时
Header还需要维护Slot的占用情况以及最后一个Slot的起始偏移量 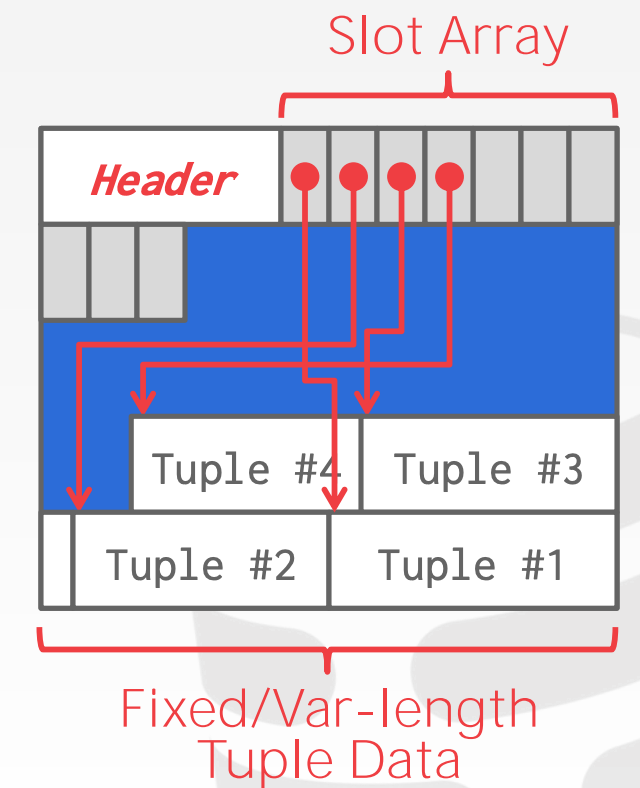
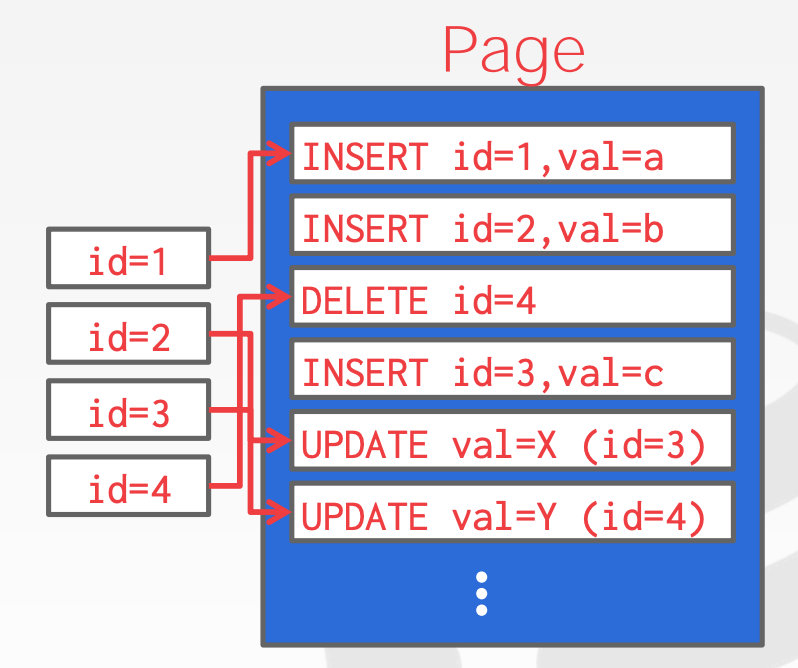
Log-Structured File Organization:
- 不同于
Slotted Pages存储Tuple,Log-Structured File Organization只存储日志记录,包括Insert:存储整个TupleDelete:标记Tuple被删除Update:只包含待更新的属性
- 在读取记录时,
DBMS扫描日志,并依据日志重建Tuple - 构建索引,用于在不同记录之间进行跳转
- 定期整理精简日志
3.3 Tuple Layout
Tuple本质上就是一个字节序列,DBMS需要将Tuple对应的字节序列解析成对应的属性和数值
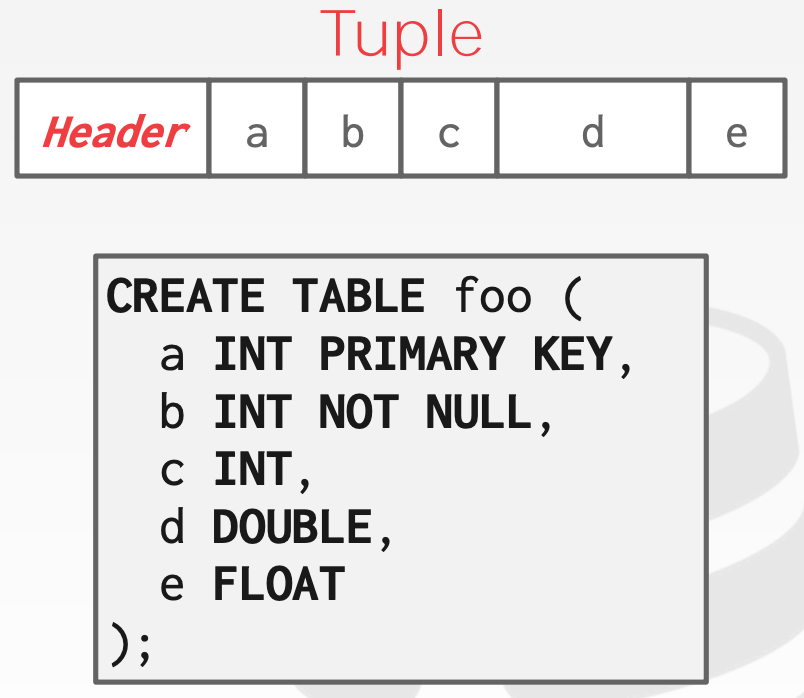
Tuple Header用于存储元数据,包括:
- 可见性(并发控制)
- 针对
NULL的Bit Map
Tuple Data:
- 按照创建
Table时定义的顺序依次存储每个属性
Records ids:
- 每个
Tuple都由一个唯一标识,通常是page_id + offset/slot
4 Storage 2
4.1 Data Representation
integer/bigint/smallint/tinyint:C/C++ Representationfloat/real/numeric/decimal:IEEE-754 Standard/Fixed-point Decimalsvarchar/varbinary/text/blob:header + bytes,其中header中记录长度信息time/date/timestamp:32/64位的整数来存储unix时间戳
Variable Precision Numbers:
- 这些类型包括:
float/real/double precision以及scale会变化- 一般用
C/C++的原生类型来表示 - 效率很高,但是存在
Rounding Errors,比如0.1 + 0.2 != 0.3
Fixed Precision Numbers:
- 这些类型包括:
numeric/decimal precision以及scale固定- 不会出现
Rounding Errors
Postgres对numeric的定义如下:
1 | typedef unsigned char NumericDigit; |
Larget Values:
- 大多数
DBMS系统不允许Tuple的大小超过单个Page的大小 - 部分
DBMS则允许,它们会用一个Overflow Page来存储 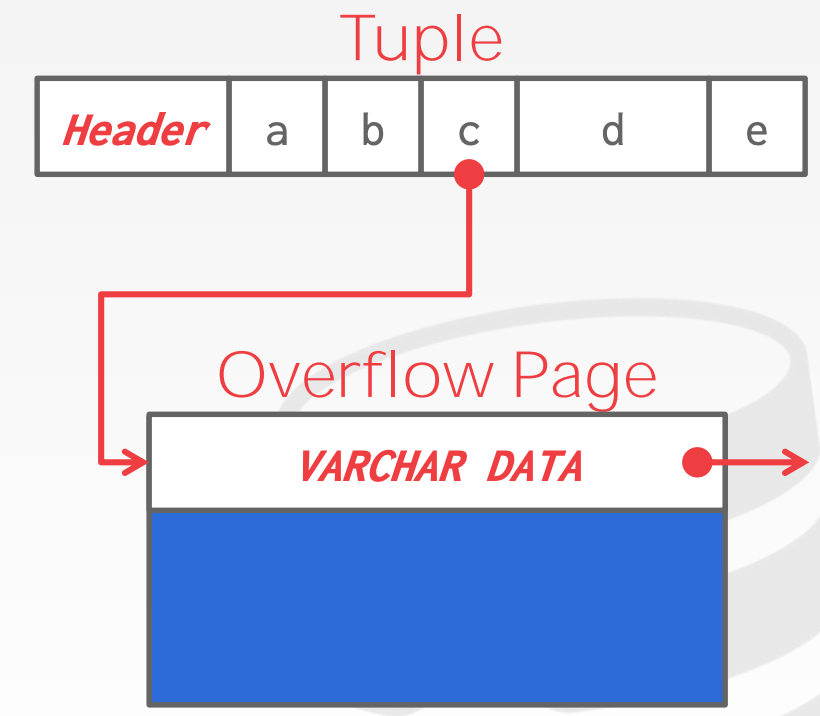
External Value Storage:
- 部分系统允许在外部文件中存储一个特别大的数值,它会被当成
Blob类型 DBMS无法操作外部文件的内容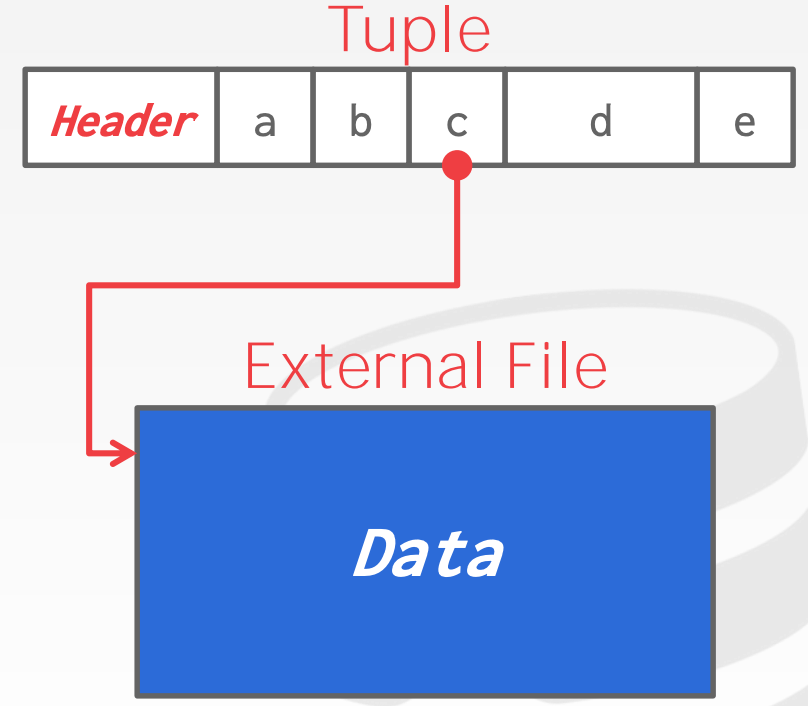
4.2 System Catalogs
DBMS会在catalogs中存储数据库的元数据,包括
- 表、列、索引、视图
- 用户、权限
- 内部统计数据
几乎所有的DBMS都会存储其数据库的目录本身:
- 我们可以通过查询
INFORMATION_SCHEMA来获取数据库的元数据信息
1 | SELECT * FROM INFORMATION_SCHEMA.TABLES |
关系模型并不要求我们将一个Tuple的所有属性都存储在同一个Page中,不同的存储布局适用于不同的工作负载:
OLTP:查询或更新单一实体的部分数据OLAP:查询横跨多实体的大量数据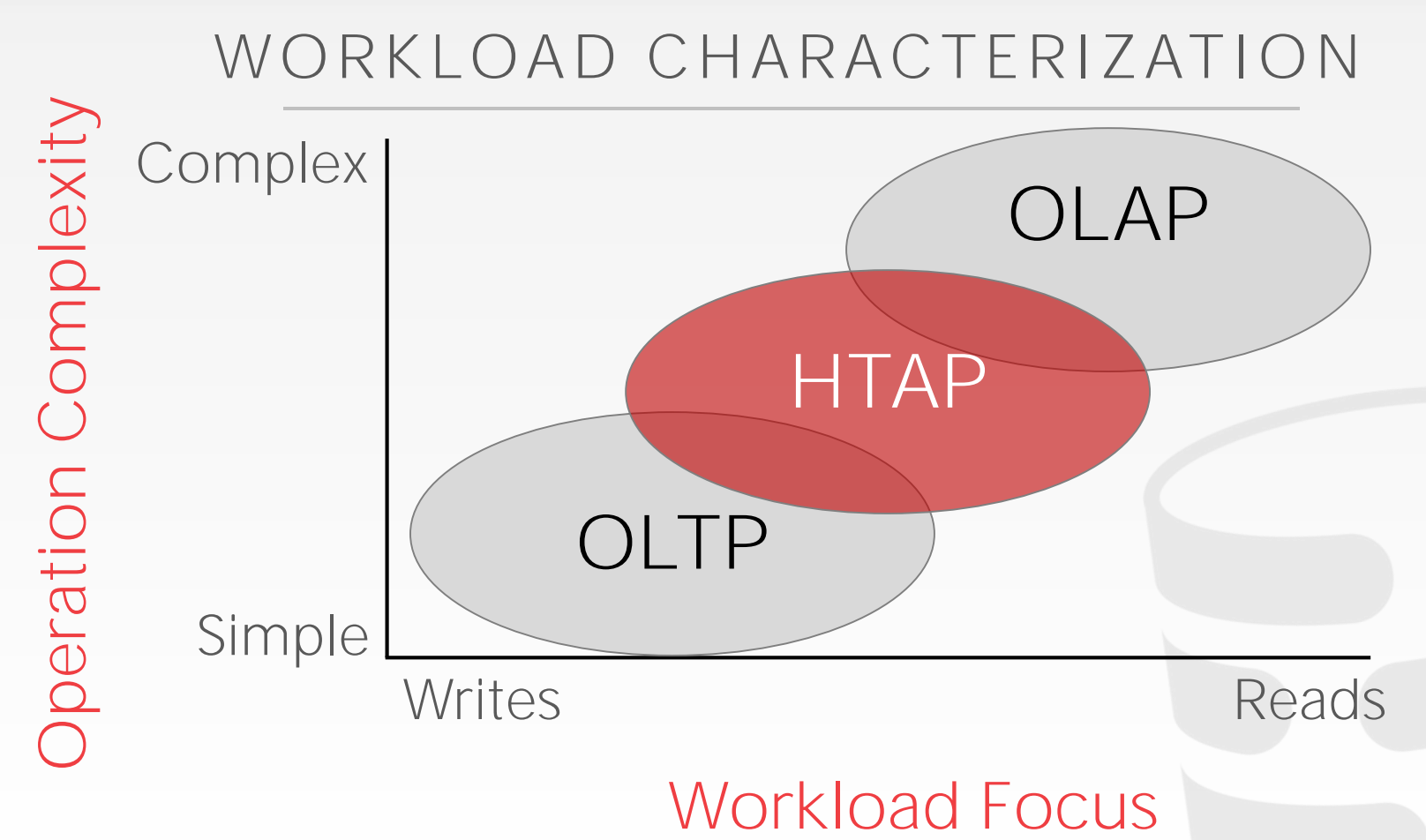
4.3 Storage Models
DBMS可以通过不同的存储方式来适应OLTP或者OLAP的工作负载
4.3.1 N-ARY Storege Model
N-ARY Storage Model又称为行存(Row Storage)
在行存中,DBMS会将一个Tuple中的属性连续存储。对于OLTP而言,这是一种理想的存储模型,因为在OLTP中,大部分的查询只操作单个实体,并且伴随着大量的插入操作
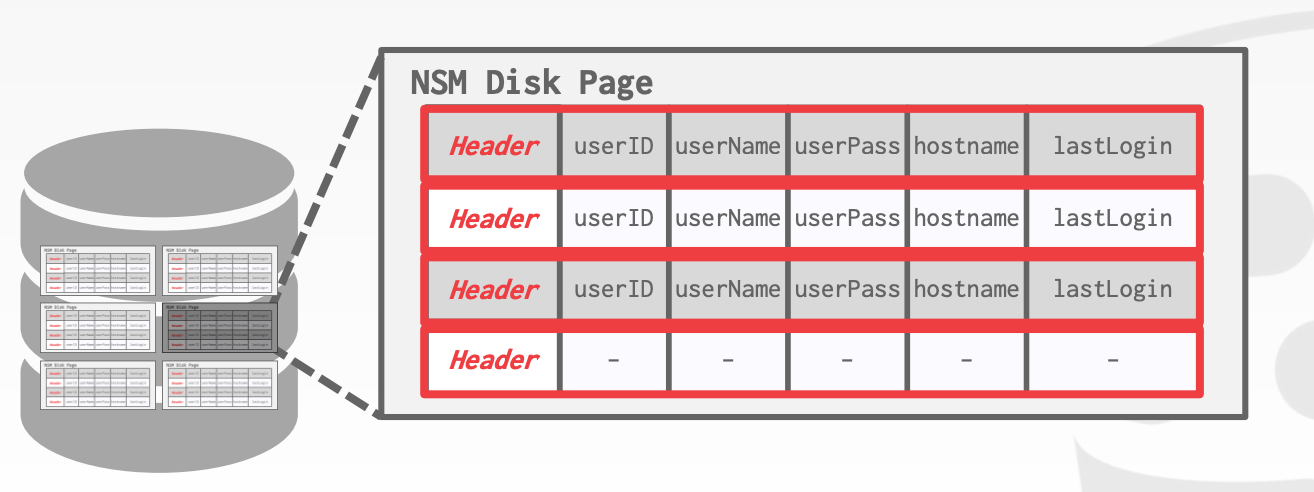
优势:
- 插入、更新、删除效率高
- 对于需要获取全量属性的查询友好
劣势:
- 对于需要全量扫描某几个属性的查询不友好
4.3.2 Decomposition Storage Model
Decomposition Storage Model又称为列存(Column Store)
在列存中,DBMS会独立存储不同的属性。对于OLAP而言,这是一种理想的存储模型,因为在OLAP中,大部分查询都需要扫描全表中的某几个属性
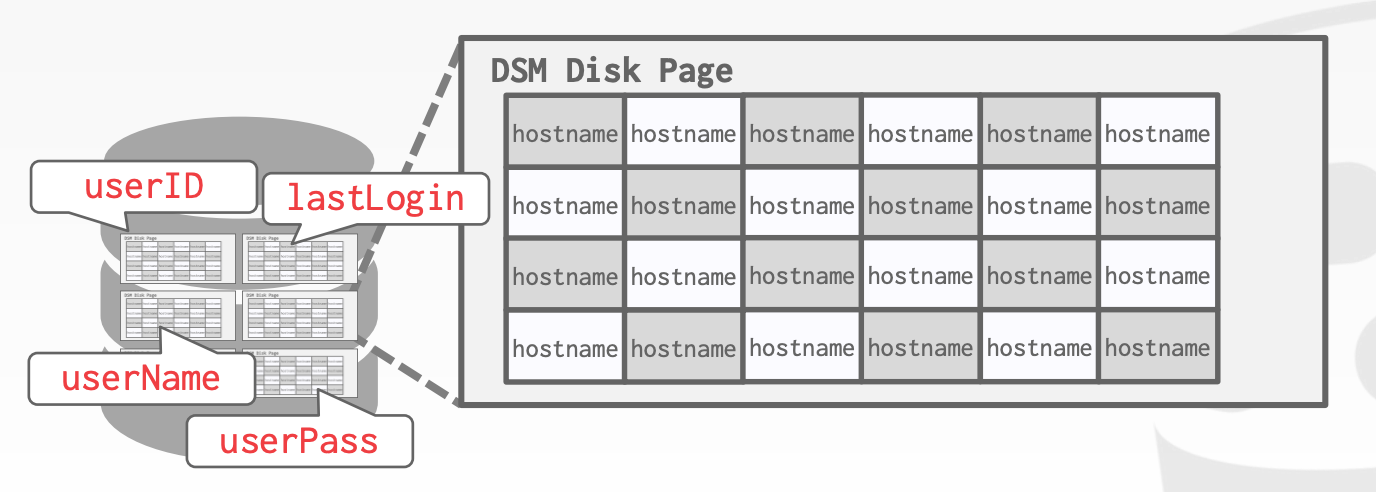
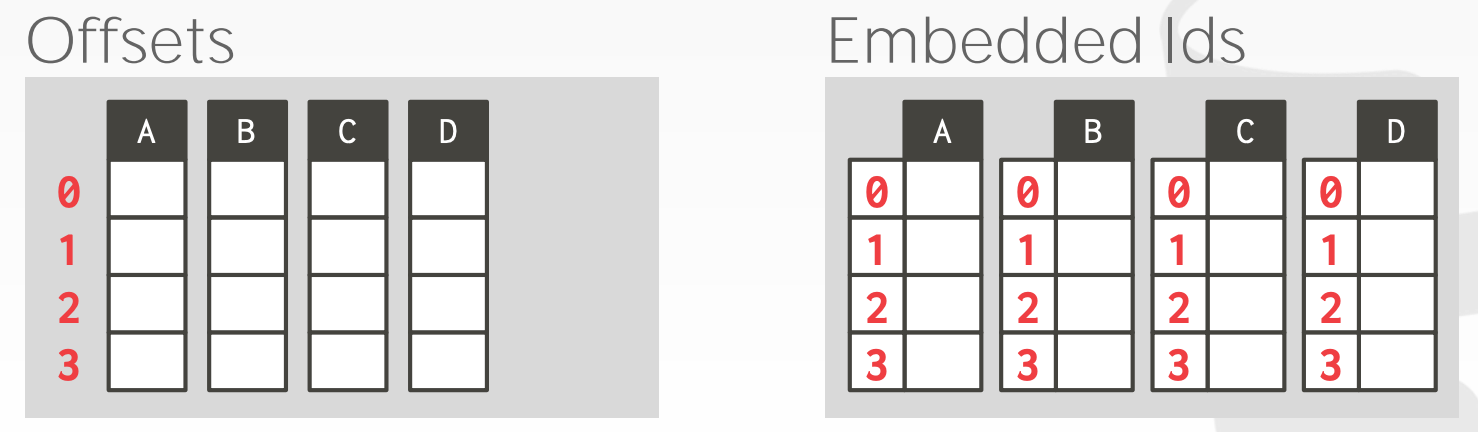
Tuple Identification:
- 方案1:约定同一个
Tuple的不同属性,在其列存中的索引都一样 - 方案2:每个列中的元素,额外存储行信息
优势:
I/O友好,因为只需要查询需要的列- 对数据压缩更友好,同一列中,数据同质化,能达到更好的压缩效率
劣势:
- 全量属性点查、插入、更新、删除不友好
5 Buffer Pool
Database Storage的两个问题:
DBMS如何用磁盘上的文件表示数据库DBMS如何管理其内存并从磁盘来回移动数据
Spatial Control:
- 将
Page刷到磁盘上的什么位置 - 目标是让经常一起使用的页面在磁盘上尽可能地靠近在一起
Temporal Control:
- 何时将
Page读入内存,何时将其写入磁盘 - 目标是最大限度地减少从磁盘读取数据的延时
5.1 Buffer Pool Manager
内存结构
- 内存区域被组织成由多个定长
Page构成的数组,数组中的每个元素称为Frame(Page需要放置到Frame中) - 每个在内存中的
Page都会记录在Page Table中 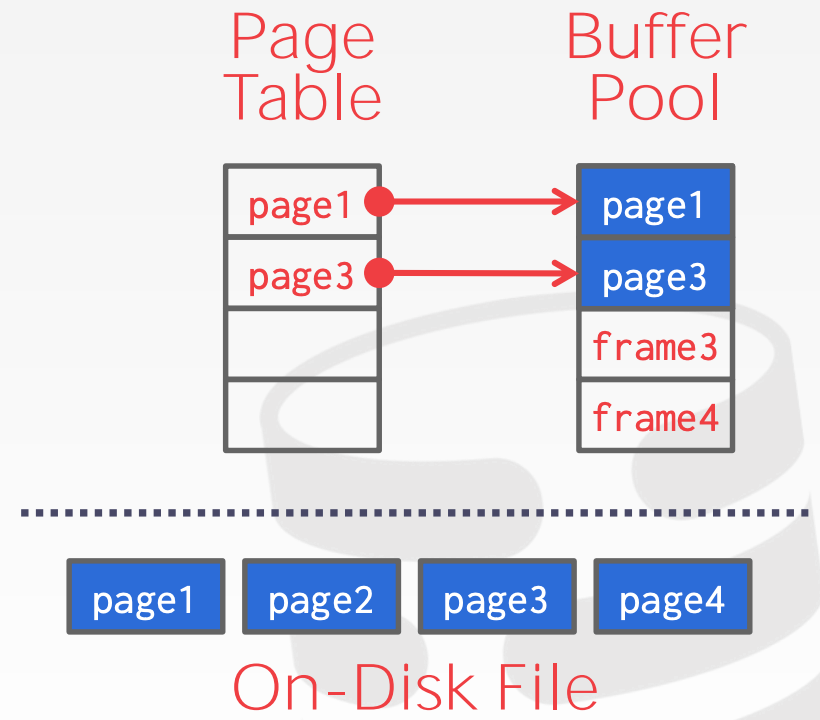
Locks vs. Latches
Locks- 保护数据库的逻辑内容免受其他事务的影响
- 在事务期间持有
- 需要支持回滚
Latches- 保护
DBMS中的关键数据避免收到其其他线程的影响 - 在操作期间持有
- 无需支持回滚
- 保护
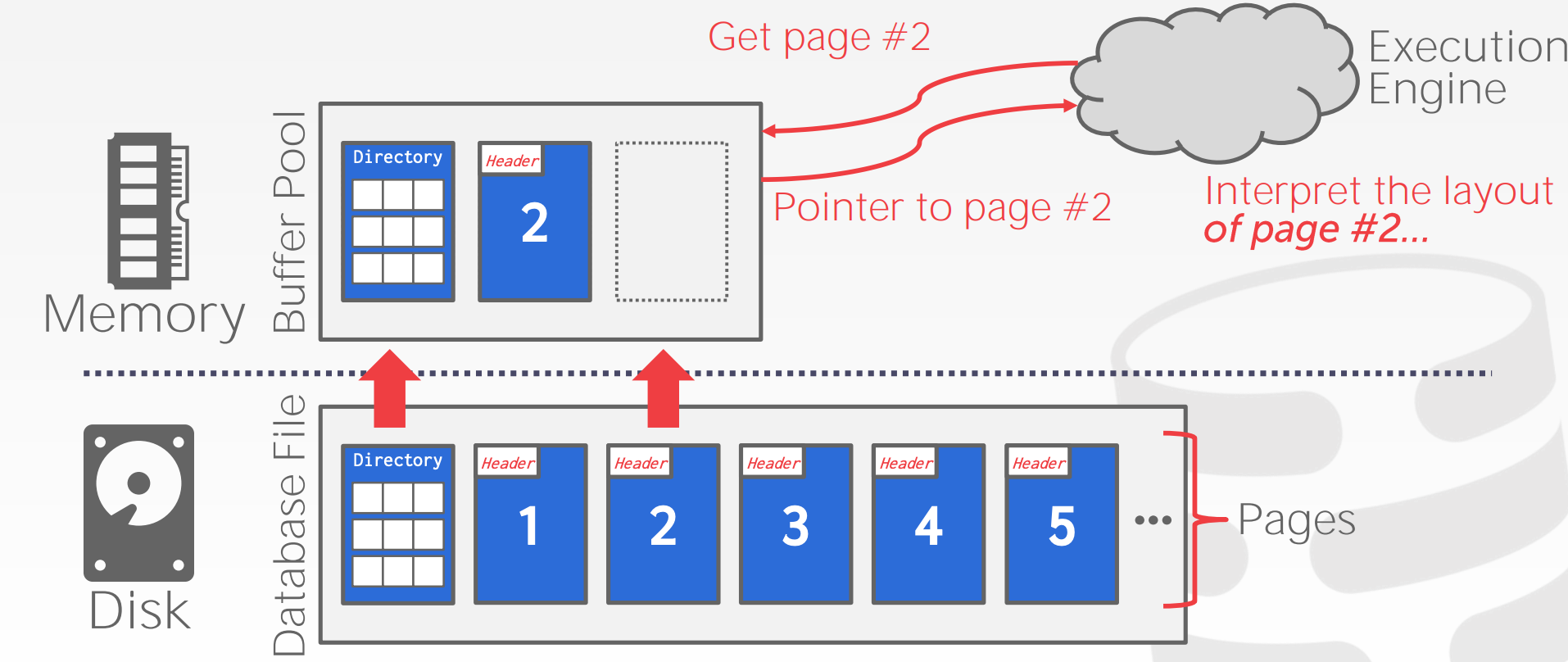
Page Table vs. Page Directory
Page Table- 存储的是
Page Id到Buffer Pool Frame的映射关系
- 存储的是
Page Directory- 存储的是
Page Id到该Page对应的磁盘文件的位置
- 存储的是
Buffer Pool Optimization:
Multiple Buffer PoolPer-database buffer poolPer-page type buffer pool- 分成多个
Pool可以减少Latch的竞争
Pre-Fetching- 针对部分查询,比如
Sequential Scans、Index Scans,可以将Page预取到Buffer Poll中的Frame
- 针对部分查询,比如
Scan Sharing- 相同或者不同的查询(只要
Scan部分相同或相似),可以复用同一份数据(这里指的是内存中的Page,无需取多次)
- 相同或者不同的查询(只要
Buffer Pool BypassSequential Scan不会将从存储层取到的Page放入Buffer Pool,从而降低负载- 在
Informix中被称为Light Scans
大多数DBMS会使用直接I/O(Direct I/O)来绕开OS' Cache
OS Cache提供的预读取、顺序读等特性,并不适用于所有场景,比如数据库- 数据库通常都由自己的一套缓存机制,如果不使用
Direct I/O,就会存在双重Cache
5.2 Replacement Policies
当DBMS需要释放一个Frame来为新的Page腾出空位时,需要决定释放Buffer Pool中的哪一个Frame
替换策略的设计目标包括:
- 正确性
- 准确性
- 效率
- 开销
5.2.1 Least-Recently Used
需要维护每个Page最近一次访问的时间戳。当DBMS需要驱逐一个Page时,选择时间戳最小的那个Page
- 保持
Page的有序性,可以减小驱逐的搜索时间
5.2.2 Clock
Clock类似于LRU,但是不需要为每个Page单独维护一个时间戳,而是:
- 每个
Page维护一个Reverence Bit,当Page被访问时,设置成1 - 通过时钟定时检查,扫描所有
Page的Reverence Bit- 若为
1,那么设置成0 - 若为
0,择驱逐
- 若为
Clock和LRU的共同问题:Sequential Flooding
- 一个扫描全表的查询会读取该表所有的
Page - 这会污染
Buffer Pool,因为每个Page读取一次后就再也不用了
5.2.3 LRU-K
LRU-K核心思想是将「最近使用过1次」的判断标准扩展成「最近使用K次」,需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据
DBMS会用访问记录来预估下一次Page的访问时间
5.2.4 Localization
DBMS根据查询来选择驱逐哪个Page
- 需要追踪每个查询访问的
Page
5.2.5 Priority Hints
DBMS有查询的上下文信息,它能向Buffer Pool提供有关页面是否重要的提示
5.3 Dirty Pages
针对脏页的处理策略
- 如果
Buffer Pool中的Page不是Dirty的,那么可以简单的丢弃它 - 如果
Buffer Pool中的Page是Dirty的,那么需要将其写回存储层以持久化改动
5.3.1 Background Writing
DBMS可以周期性的扫描Page Table,并将脏页写回
- 当脏页被成功写回后,
DBMS可以选择驱逐该Page也可以选择保留该Page并将Dirty Flag置位 - 注意,在日志写入成功之前,不能写回脏页
5.4 Other Memory Pools
DBMS需要使用内存来做其他事情,而不仅仅只是缓存Tuple以及Index,包括:
Sorting + Join BuffersQuery CachesMaintenance BuffersLog BuffersDictionary Caches
5.5 总结
DBMS需要维护缓存而不能依赖OS Cache- 可以借助查询计划来更好地进行决策,包括:
Evictions:如何驱逐Allocations:如何分配Pre-Fetching:如何预取
6 Hash Tables
哈希表实现了一个将键映射到值的无序关联数。通过哈希函数(Hash Function)计算出给定键的数组偏移量,从而找到对应的值
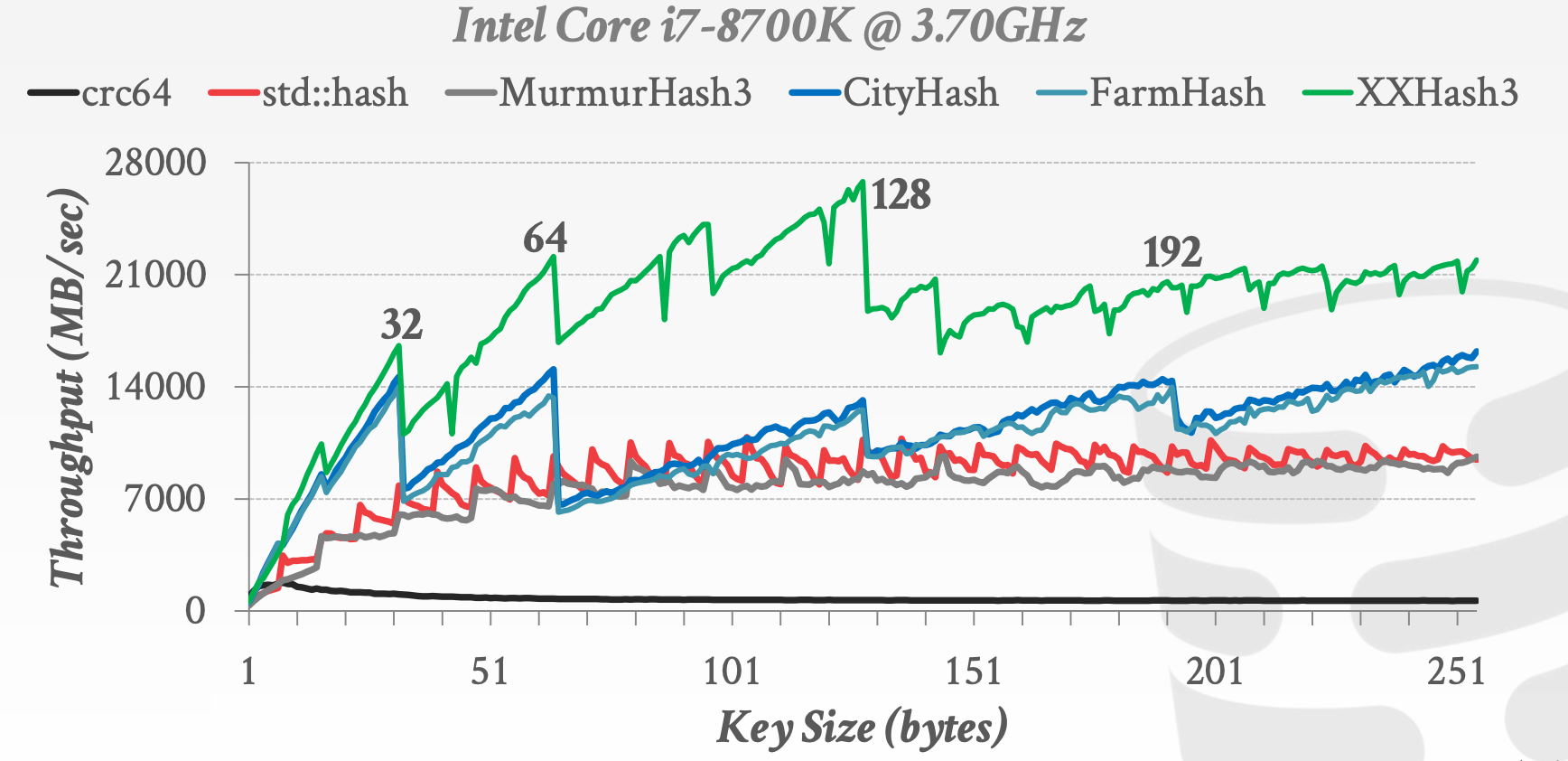
6.1 Hash Functions
关于哈希函数:
- 如何将大的键空间映射到较小的域
- 如何在性能和冲突概率之间权衡
- 如何处理冲突
- 如何在分配大哈希表和通过额外操作和数据结构来实现插入和查找
哈希函数的实现:
6.2 Static Hashing Schemes
6.2.1 Linear Probe Hashing
其实现方式是一个巨大的数组
如何解决冲突:
- 在插入时,若某个槽位上已经有数据了,那么就顺延到下一个槽位,直至找到一个空的槽位。例如,通过哈希函数算出来的偏移量是
3,若位置3上已经有数据了,那么看下槽位4是否空闲,若仍然有数据,继续看槽位5,以此类推,直至找到空的槽位 - 需要记录槽位是否被占用
- 在删除后,有两种选择
Tombstone:将某个槽位标记为删除,这样其他元素就不需要移动Movement:如果有必要的话,移动其他元素
Non-Unique Keys:同一个键映射到不同的值
- 为每个键维护一个链表,哈希表中存的就是键到链表的映射
- 直接在哈希表中进行冗余存储
缺点:
- 键值对存放的槽位可能距离最佳槽位(通过哈希计算出来的槽位)很远,这样会导致较差的性能(在这段距离上,是通过遍历查找的)
示意图参考课件中的18 ~ 31页
6.2.2 Robin Hood Hashing
Robin Hood Hashing是Linear Probe Hashing的变体。每个键值对存放的最佳槽位(通过哈希计算出来的槽位)和实际槽位之间的距离称为d,那么Robin Hood Hashing的核心思想在于降低距离d的总和$\sum{d}$
- 会在插入、删除时,调整已有元素的位置,从而保证$\sum{d}$最小
示意图参考课件中的34 ~ 40页
6.2.3 Cuckoo Hashing
Cuckoo Hashing会维护两个哈希函数和两张哈希表,其中Hash Function 1对应Hash Table 1,Hash Function 2对应Hash Table 2
- 会在插入、删除时,动态调整元素的位置,比如把一个哈希表中的某个元素挪到另一个哈希表中
- 如果动态调整后也无法存入元素,那么会将哈希表进行大小调整(例如扩容)
举个例子:
- 插入键值对
A -> V(A),其中通过Hash Function 1计算出来的槽位是1,且Hash Table 1中的该槽位空闲,那么直接将其存入 - 插入键值对
B -> V(B),其中通过Hash Function 1计算出来的槽位是1(与A冲突),通过Hash Function 2计算出来的槽位是2,且Hash Table 2中的该槽位空闲,那么直接将其存入 - 插入键值对
C -> V(C),其中通过Hash Function 1计算出来的槽位是1(与A冲突),通过Hash Function 2计算出来的槽位是2(与B冲突)- 将
C -> V(C)存入Hash Table 2中的槽位2,此时B -> V(B)被换出 - 将
B -> V(B)存入Hash Table 1中的槽位1,此时A -> V(A)被换出 A -> V(A),通过Hash Function 2计算出来的槽位是3,且Hash Table 2中的该槽位空闲,那么直接将其存入
- 将
示意图参考课件中的42 ~ 49页
6.3 Dynamic Hashing Schemes
Dynamic Hashing Schemes的特点是:在必要时会进行resize操作
6.3.1 Chained Hashing
每个槽位维护一个链表,链表中的元素称为Bucket,每个Bucket存放Hash Key相同的元素
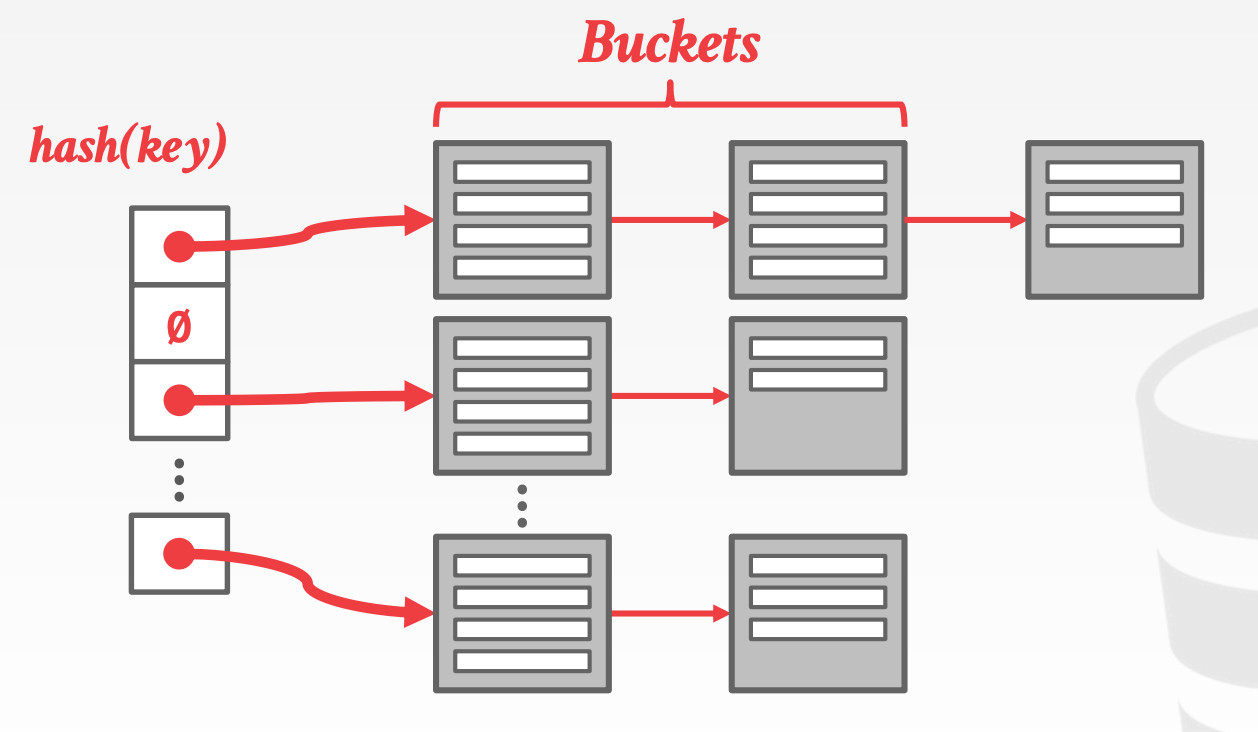
6.3.2 Extendible Hashing
由于Chained Hashing中的Bucket Chain可能会不断膨胀,Extendible Hashing是Chained Hashing的改良版,特点包括:
- 会在必要时对
Bucket Chain进行分裂操作 - 多个
Slot可能指向同一个Bucket Chain - 在
Bucket Chain Split时,会进行reshuffle操作,进行重组
示意图参考课件中的55 ~ 63页
6.3.3 Linear Hashing
Linear Hashing是Extendible Hashing的改良版,特点包括:
- 每个
Bucket会维护一个pointer指向其分裂得到的Bucket(如果有分裂过的话) - 可以通过不同的
Hash来定位指定的Bucket - 可以使用不同的
Overflow标准,包括- 空间利用率
Bucket Chain平均长度
示意图参考课件中的65 ~ 83页
7 Trees1
7.1 Table Indexes
表索引(Table Index)是表中部分属性的副本,且有序组织,用于提高查询效率。DBMS会保证表中数据与索引中的数据在逻辑上是同步的。DBMS的任务之一就是为每个查询寻找最合适的索引
索引的开销包括:
- 存储开销
- 维护成本
7.2 B+ Tree Overview
B-Tree Family包括:
B-TreeB+TreeB*TreeBlink-Tree
B+Tree包含如下特点:
- 平衡树,各叶子节点高度完全一致
- 节点存储的数据多,有利于减少磁盘读写
- 数据有序组织
- 便于顺序访问
- 查询、插入、删除等操作的复杂度是
O(log n)
关于B+Tree的定义可以参考DataStructure-BPlus-Tree
B+Tree叶节点存放的值是什么?
- 存放记录
idPostgreSQLSQLServerDB2Oracle
- 存放
Tuple DataSqliteSQLServerMysqlOracle
B-Tree和B+Tree的差异:
B-Tree在非叶节点也存储具体的数据,更节省空间B+Tree只在叶节点存储数据,因此需要额外的非叶节点来辅助索引过程。对顺序访问、范围查找比较友好
B+Tree可视化网站:
聚簇索引Cluster Indexes是指,整个数据表以primary key作为排序键,进行有序存储
哈希索引 vs. B+Tree
- 哈希索引不支持前缀匹配,比如创建一个包含三列的哈希索引,那么查询条件必须包含这三列才能使用哈希索引
B+Tree支持前缀匹配,比如创建了一个Index(a, b, c),那么a = 5、a = 5 and b = 2都能使用索引
7.3 Design Decisions
在设计实现B+Tree时,需要考虑如下节点:
Node Size:存储性能越差的设备,Node Size建议更大HDD:1MBSSD:10KBMemory:512B
Merge Threshold:在实现时,并不一定要完全按照定义,比如当某个节点中的数据数量少于容量的一半时,可以不执行合并操作。有些DBMS允许underflows,且会定期重新构建整颗树Variable Length Keys- 节点大小固定,存储
Key的指针 - 节点的大小可以动态变化,直接存储
Key,复杂度提升 - 节点大小固定,且给
Key分配的空间是该类型的最大值,不足部分补白,比较浪费空间 Key Map / Indirection,没看懂
- 节点大小固定,存储
Non-Unique IndexesIntra-Node Search
Non-Unique Indexes有如下两种策略:
- 重复存储
Key - 每个
Key维护一个List
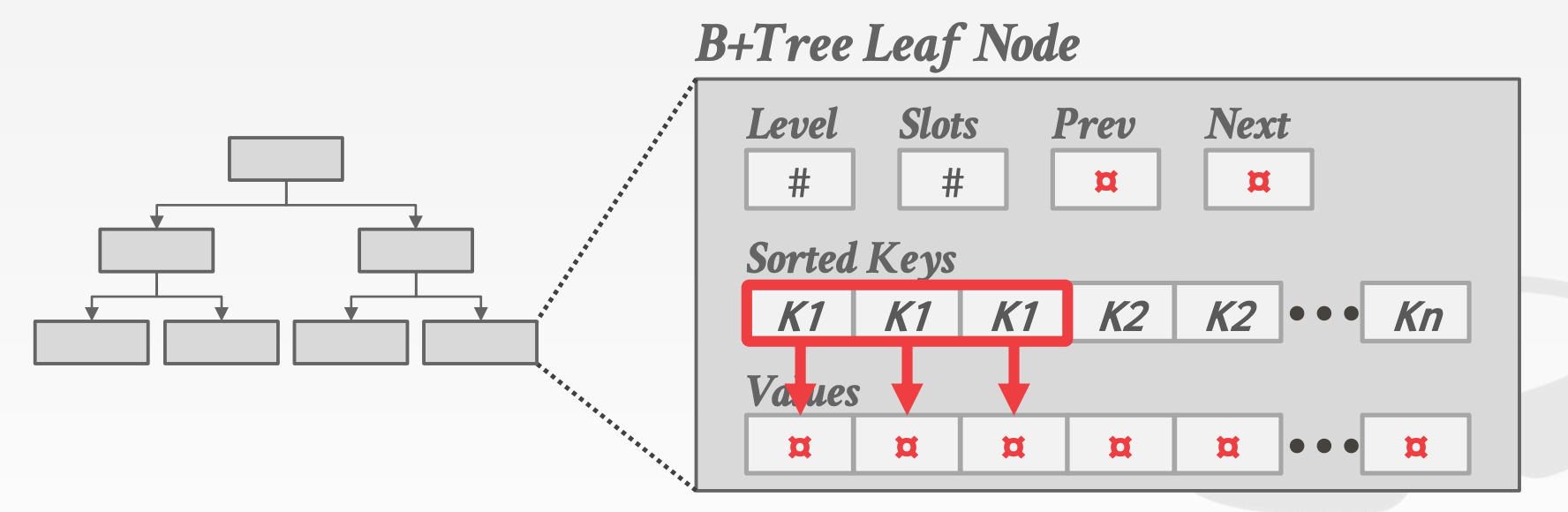
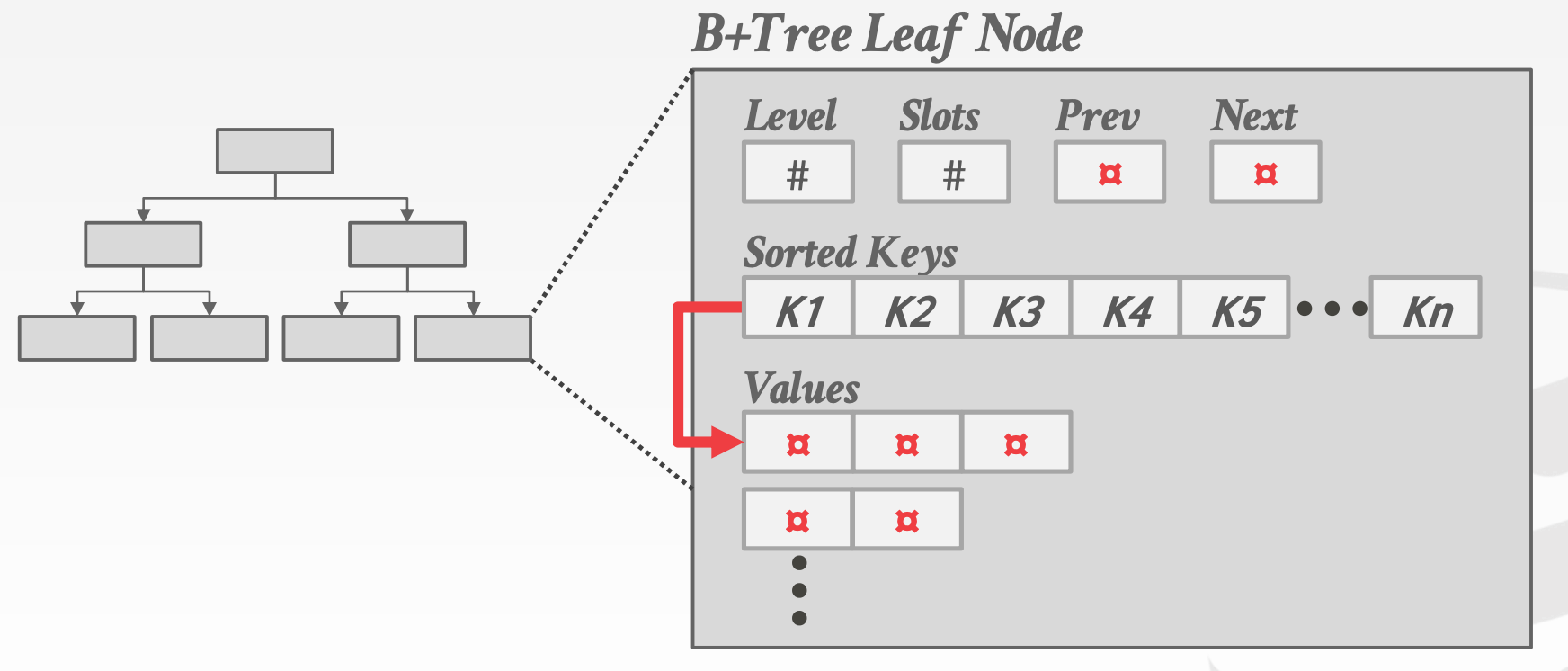
Intra-Node Search节点中的查找策略:
Linear:从左往右遍历Binary:二分查找Interpolation:基于分布信息预估一个位置,然后再继续查找
7.4 Optimization
7.4.1 Prefix Compression
在同一个叶子节点中,由于Key是有序排列的,通常具有相同的前缀
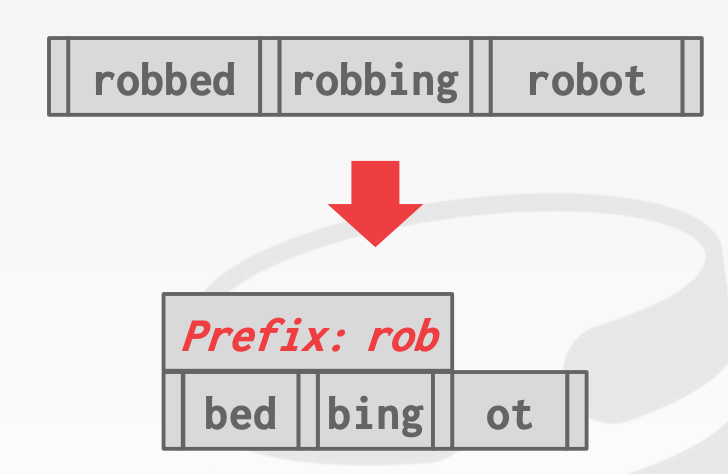
7.4.2 Suffix Truncation
由于非叶子节点在B+Tree仅起到导航作用,因此有时不必存储整个Key,只需要存储前缀即可
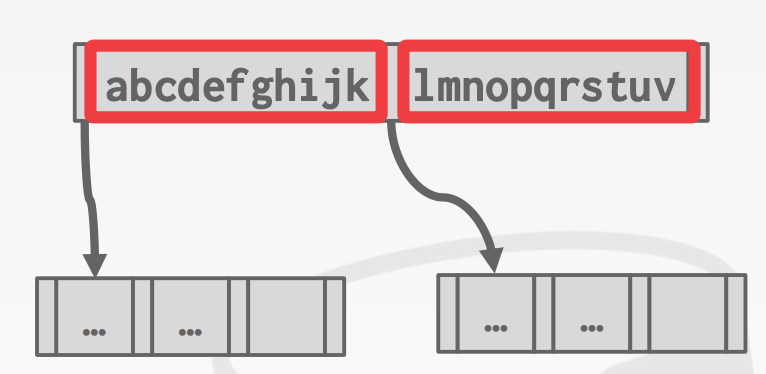
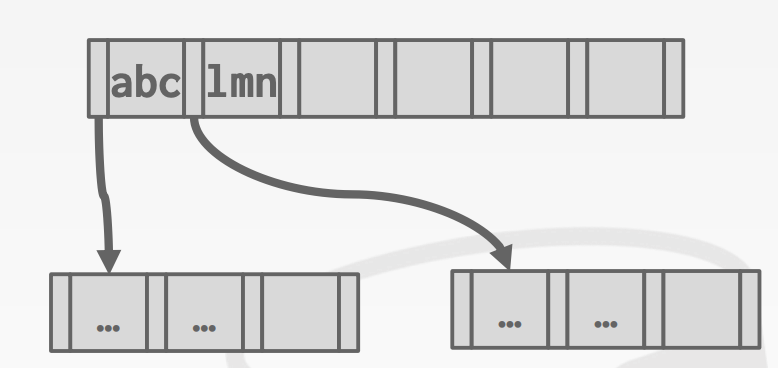
7.4.3 Bulk Insert
构建一颗B+Tree最快的方法是先将所有Key排序,从叶节点开始往上构建,这样可以直接避免分裂操作
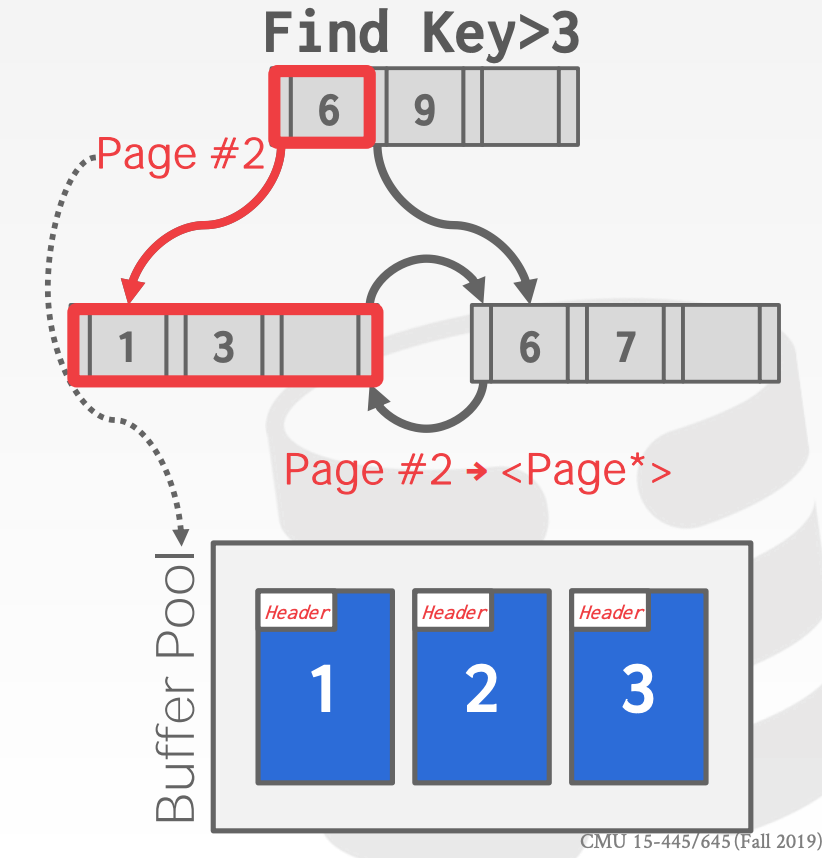
7.4.4 Pointer Swizzling
如果节点通过Page Id来引用其他索引中的节点,那么在内存中通过B+Tree进行查找时,需要将Page Id转换成内存地址。如果该Page已经在Buffer Pool中时,可以用指针代替Page Id
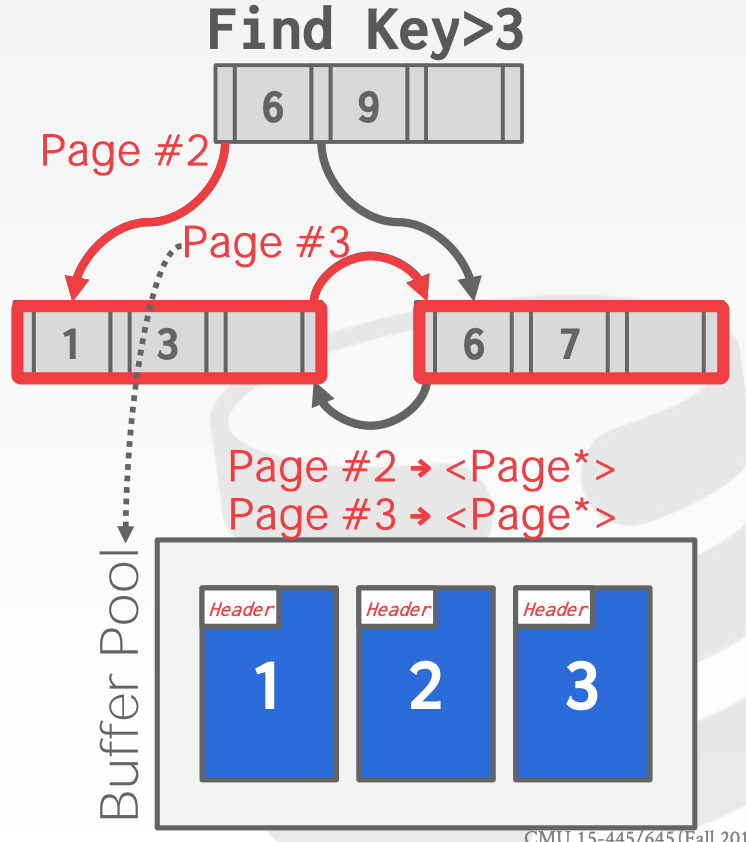
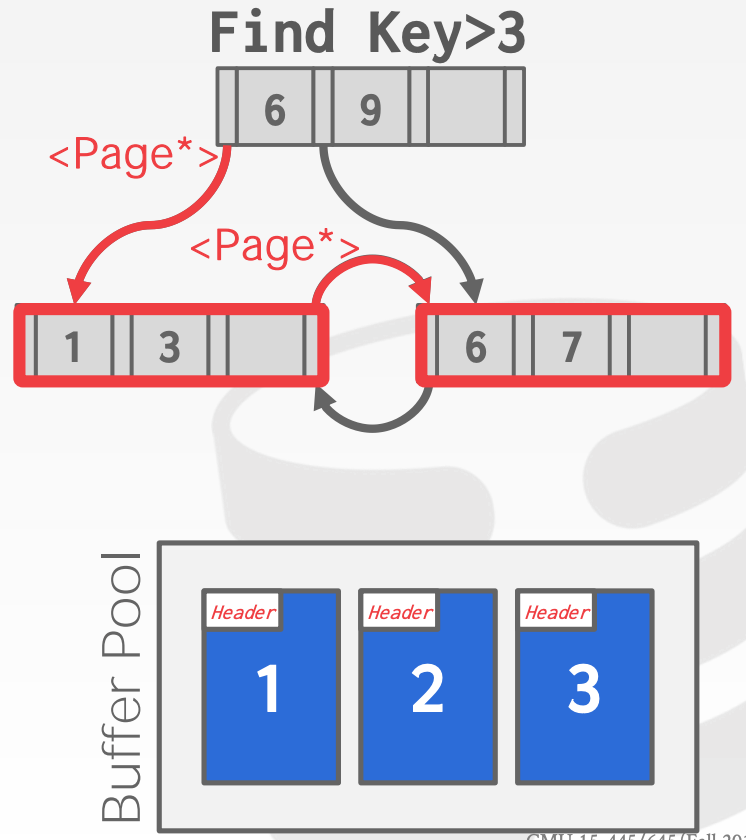
8 Trees2
8.1 More B+Tree
B+Tree如何处理Duplicate Keys:
Append Record Id:额外存储一个Unique Id,来保证所有Key的唯一性Overflow Leaf Nodes:允许叶节点存储多余额定数量的数据,用于存储Duplicate Key
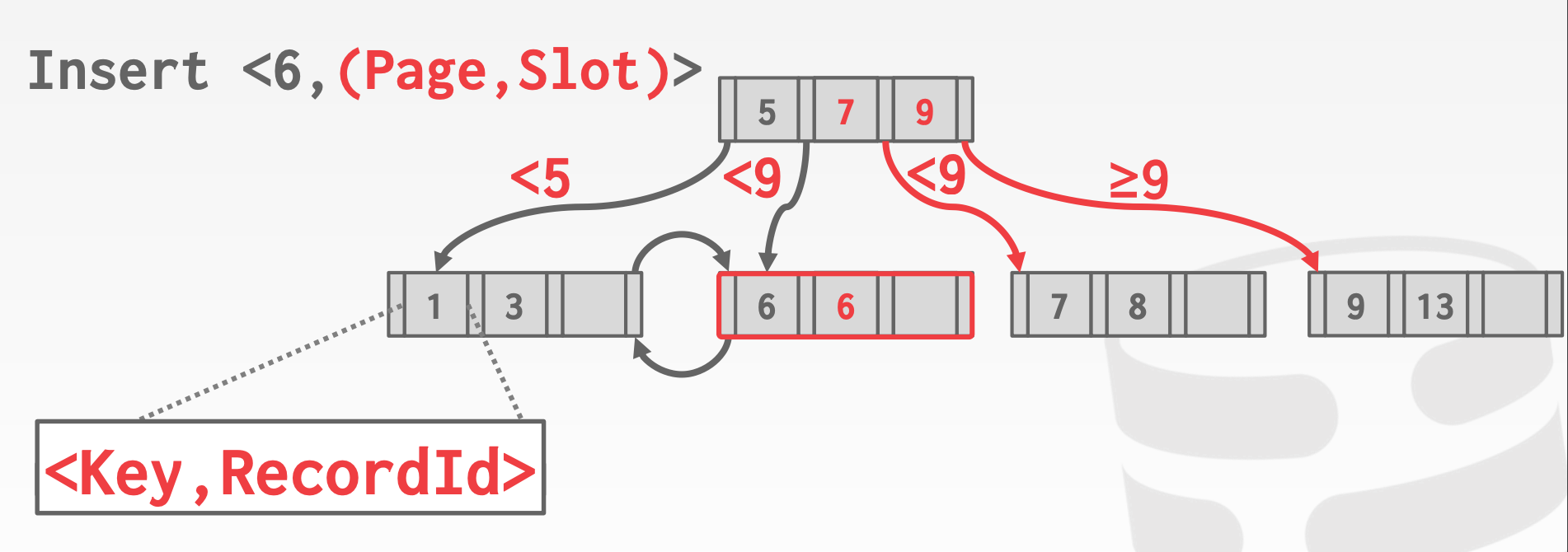
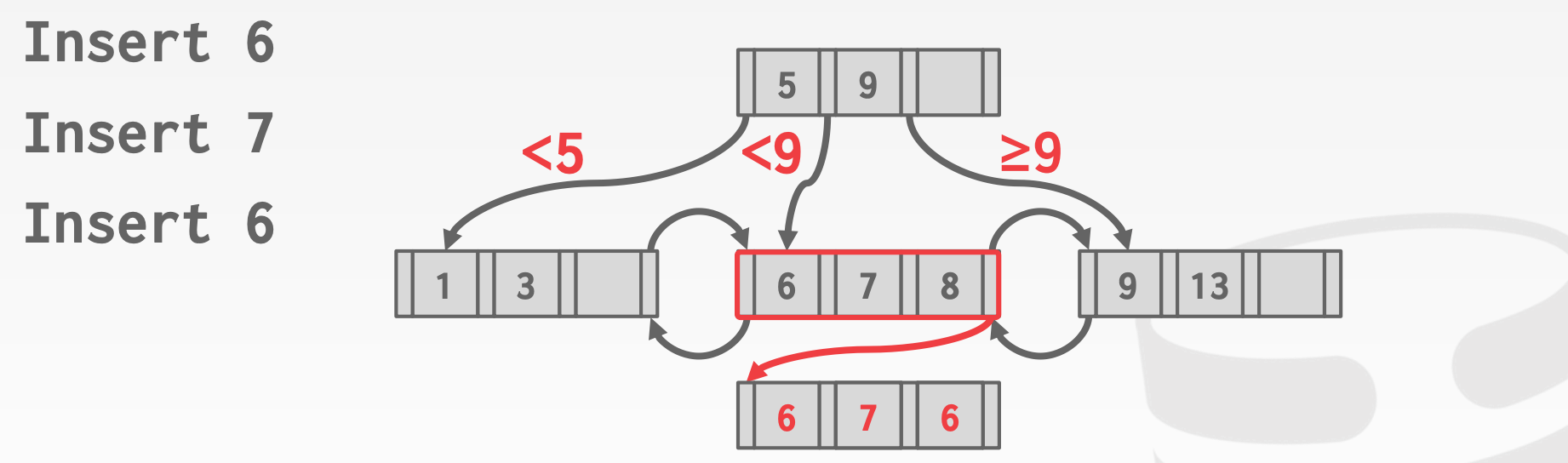
8.2 Additional Index Magic
隐式索引(Implicit Indexes):
- 大多数
DMBS系统会创建一个隐式的索引来实现完整性约束
局部索引(Partial Indexes):
- 仅在一部分数据上创建索引
- 有效降低索引的大小以及维护的开销
- 一个典型的使用场景是,根据日期来分别创建索引,比如每个月,或者每年单独创建索引
1
2
3
4
5
6
7CREATE INDEX idx_foo
ON foo(a, b)
WHERE c = 'WuTang';
SELECT b FROM foo
WHERE a = 123
AND c = 'WuTang';
覆盖索引(Covering Indexes):
- 如果索引中包含查询所需的字段,那么仅通过索引就可以返回所有的
Tuple - 提高查询效率,且可以有效得减少
Buffer Pool的冲突(不需要额外访问Page了)1
2
3
4
5CREATE INDEX idx_foo
ON foo(a, b);
SELECT b FROM foo
WHERE a = 123;
Index Include Columns:
- 在索引中存储额外的列,这部分信息只能通过索引来查询。例如,
CREATE INDEX idx_foo ON foo(a, b) INCLUDE (c); - 这些额外的列只存储在叶节点中,且不属于
Search Key1
2
3
4
5
6
7CREATE INDEX idx_foo
ON foo(a, b)
INCLUDE(c);
SELECT b FROM foo
WHERE a = 123
AND c = `WuTang`
Observation:
- 非叶子结点中的
Key仅起到导航作用,并不能判断出该Key是否真的存在,只能访问到叶子节点中,才能知道某个Key是否存在 - 可以通过
Buffer Pool来协助快速确定某个Key是否存在
8.3 Tries Tree
Tries Tree称为前缀树或者字典树
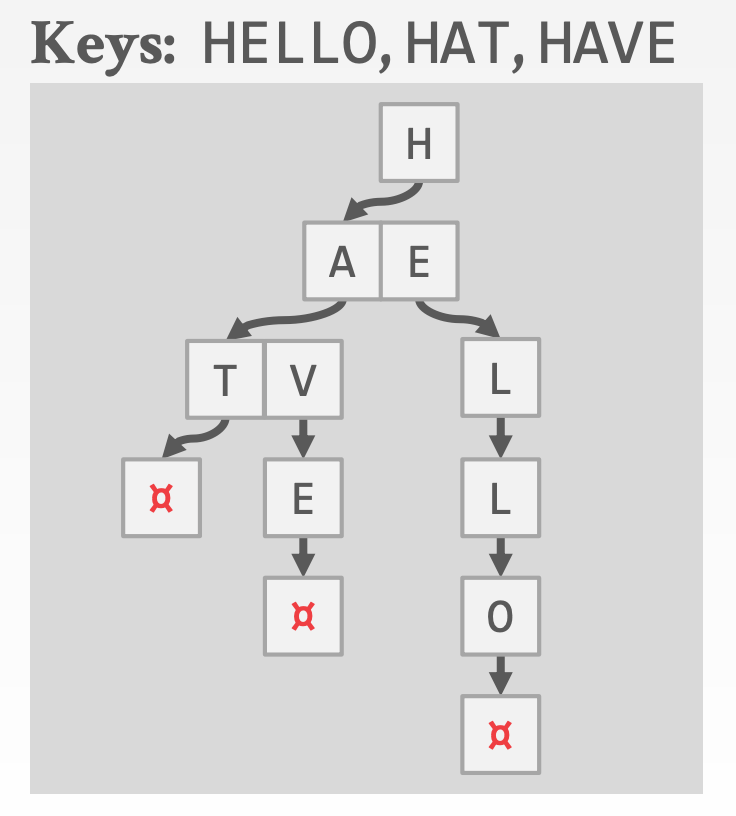
属性:
- 树形结构仅依赖于键空间(
Key Space)以及键长(Key Length),而不依赖于已有的Key以及插入顺序,且不需要平衡操作 - 所有的操作的复杂度都是
O(k),其中k是键值的长度 - 键值是隐式存储的(从根到叶的整条路径就是
Key)
Key Span:
- 当某个字符存在于某一层时,存储一个指向下一层的指针,否则存储
null 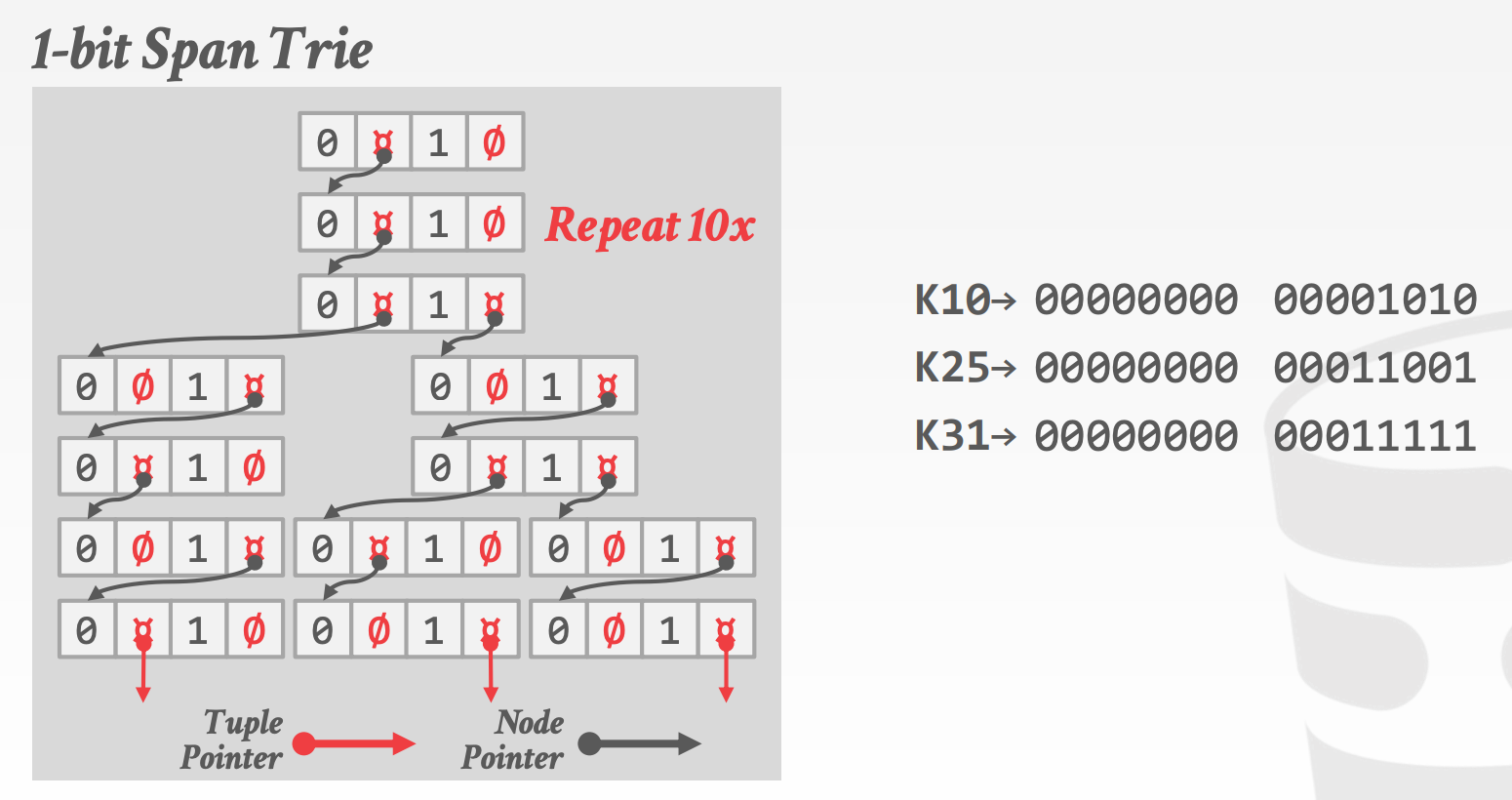
- 示意图参考课件中的
39 ~ 47页
8.4 Radix Tree
Radix Tree在Tries Tree基础上,做了如下调整:
- 每个节点如果有孩子,那么至少要有2个孩子,否则就合并到上一层(当分布较为稀疏时,可以大大降低层级)
- 示意图参考课件中的
49 ~ 56页
Binary Comparable Keys:并非所有属性类型都可以分解为基数树的二进制可比数字
Unsigned Integers:小端机器的字节顺序必须翻转Signed Integers:翻转二进制补码,使负数小于正数Floats:分类(neg vs. pos,归一化vs.非规范化),然后存储为无符号整数Compound:分别转换每个属性- 示意图参考课件中的
58 ~ 60页
Observation:
- 到目前位置,我们讨论的索引仅能有效地进行点查和范围查询
- 并不是用于「在Wikipedia文章中查找包含
Pavlo的所有文章」这种类型的查询
8.5 Inverted Indexe
倒排索引存储「单词」到「包含目标属性中这些单词的记录」的映射,又称为全文索引(Full-text Search Index)
这部分内容包含在CMU 11-442
8.6 Geo-Spatial Tree Indexes
包括R-Tree、Quad-Tree、KD-Tree,这部分内容包含在CMU 15-826
9 Index Concurrency
到目前为止,讨论的数据结构都是在单线程模型下。因此,我们必须允许多个线程安全,高效地访问共享数据,这样才能充分利用多个CPU的计算资源
9.1 Latches Overviews
| Locks | Latches | |
|---|---|---|
| 粒度 | 事务 | 线程 |
| 保护对象 | 用户数据 | 内存中的内部数据结构 |
| 作用范围 | 整个事务 | 部分重要的片段 |
| 模式 | Shared、Exclusive、Update、Intention | Read,Write |
| 死锁 | 检测&解决 | 避免 |
Latches的两种模式:
Read Mode- 多个线程可以同时获取同一个共享对象的
Read Latch - 在其他线程持有同一个共享对象的
Write Latch时,无法获取该对象Read Latch
- 多个线程可以同时获取同一个共享对象的
Write Mode- 仅有一个线程可以获取同一个共享对象的
Write Latch - 在其他线程持有同一个共享对象的
Read Latch或Write Latch时,无法获取该对象Write Latch
- 仅有一个线程可以获取同一个共享对象的
Latches的三种实现方式:
Blocking OS Mutex,例如std::mutexTest-and-Set Spin Latch(TAS),例如std::atomic<T>Reader-Writer Latch
9.2 Hash Table Latching
由于访问数据结构的方式有限,因此Hash Table易于支持并发访问。但是,在进行扩缩容时,需要在整个Hash Table上加一个全局的Latch,该全局的Latch有两种实现方式
Page Latches- 每个
Page都有一个Read-Write Latch用于保护该Page中的所有数据 - 线程必须获取
Read Latch或Write Latch之后才能访问一个Page
- 每个
Slot Latches- 每个
Slot都有一个锁,粒度更细 - 可以使用一个单模式的
Latch,来降低元数据以及计算的开销
- 每个
- 示意图参考课件中的
18 ~ 37页
9.3 B+Tree Latching
为了能能够并发地访问B+Tree,必须解决如下两个问题:
- 不同线程同时修改节点中的内容
- 当一个线程遍历
B+Tree时,另一个线程在做Split/Merge节点的操作
实现的基本思路:
- 获取父节点的
Latch - 获取子节点的
Latch - 当节点
Safe时,释放父节点的Latch- 当一个节点不会发生
Split或者Merge操作时,称其为Safe Node
- 当一个节点不会发生
Find流程,从根节点开始往下查找,重复如下过程:
- 获取子节点的
R-Latch - 释放父节点的
R-Latch
Insert/Delete流程,从根节点开始往下查找,重复如下过程:
- 获取子节点的
W-Latch,成功获取后,检查它是否是Safe的- 如果是
Safe的,那么释放所有祖先的W-Latch(因为插入或删除操作引发的Split和Merge动作不会扩散到该节点的祖先) Insert与Delete对Safe的判断条件是不同的Insert只需要考虑Split,孩子Split时,父节点会增加一个孩子,因此父节点只有非满时,Split操作才不会向上扩散Delete只需要考虑Merge,孩子Merge时,父节点会减少一个孩子,因此父节点的孩子数量比一半多时,Merge操作才不会向上扩散
- 如果是
示意图参考课件中的50 ~ 73页
9.3.1 优化算法1
算法思路:
- 假设叶节点是
Safe的 - 在
R-Latch保护下(同Find过程),访问叶节点(叶节点获取W-Latch),检查它是否是Safe的 - 如果叶节点是
Safe的,那么继续Insert/Delete的操作 - 如果叶节点不是
Safe的,那么退化成原先的算法
示意图参考课件中的77 ~ 84页
9.4 LeafNode Scans
上面介绍的算法仅针对查找、插入、删除。但是如果要将一个叶节点上的数据移动到另一个叶节点上应该怎么操作呢?
示意图参考课件中的86 ~ 101页
89、90为啥要释放节点C上的R-Latch呢?这个时候C节点的数据已经读完了,然后就可以释放了?
由于Latch没有死锁检测或者避免的机制,只能依靠编码原则来规避死锁,因此最好能提供no-wait模式
9.5 Delayed Parent Updates
在B+Truee中,当叶节点Overflow时,会操作至少三个节点:
- 当前叶节点
Split出来的新节点- 当前叶节点的父节点
Blink-Tree优化思路:
- 当一个叶节点
Overflow时,延迟更新其父节点,进行标记- 当父节点获取
W-Latch时,才执行更新操作
- 当父节点获取
- 于是,在执行插入或者删除操作时,从根节点开始直至叶节点,除了叶节点之外只需要获取
R-Latch- 当发现一个节点被标记后,原本只需要获取
R-Latch,需要改成获取W-Latch,然后进行更新操作
- 当发现一个节点被标记后,原本只需要获取
10 Sorting & Aggregate
查询计划:
- 查询计划中的算子会被组织成一棵树
- 数据流从叶节点流向根节点
- 根节点的输出就是查询结果
Disk-Oriented DBMS:
- 就像我们无法假设整个表中的数据可以放入内存一样,我们同样无法假设查询的结果可以全部放入内存
- 需要依赖
Buffer Pool来实现溢出到磁盘(spill to disk)的算法 - 需要可以最大化顺序查询性能的算法
10.1 External Merge Sort
如果全部数据可以放在内存中,那么可以利用一些标准的排序算法,比如快排。如果数据无法全部放在内存中,那么排序算法必须考虑到磁盘I/O的开销
External Merge Sort算法大致可以分为两步:
Sorting:将多个数据块中的数据加载到内存中(数据块小于主存大小)排序后写回到文件中Merging:将多个有序的文件合并成一个大文件
2-Way External Merge Sort:
n-Way指的是合并n个子序列- 算法需要3个
Buffer Pool,两个用于Input,一个用于Output - 示意图参考课件中的
11 ~ 18页
Double Buffering Optimization:
- 优化思路:提前将下次合并需要的
Page加载到缓存中来,这样可以减少I/O等待时间
General External Merge Sort:
- 使用
B个Buffer Pool,B-1个用于Input,一个用于Output,一次合并B-1个子序列
Using B+Tree For Sorting:
- 如果数据存储在
B+Tree中,那么只需要遍历叶子节点就可以得到排序的数据 - 这里仍然需要区分两种情况
Clustered B+Tree- 直接从左深叶节点(或者指定叶节点)遍历后续叶节点即可得到有序的结果,无排序的计算开销,且所有的磁盘
I/O都是顺序的
- 直接从左深叶节点(或者指定叶节点)遍历后续叶节点即可得到有序的结果,无排序的计算开销,且所有的磁盘
Unclustered B+Tree- 由于叶节点存存储的是指向包含数据的
Page的内容(指针、引用、id) - 昂贵的磁盘
I/O,几乎每次I/O都只读取一个Page
- 由于叶节点存存储的是指向包含数据的
10.2 Aggregations
可以利用排序来实现Distinct(排序后,相同元素一定相邻,便于去重),但是更好的做法是Hash,这样可以避免排序
External Hashing Aggregate算法大致可以分为两步:
- 将数据
Hash到不同的分区中(分区处理,内存放不下所有数据)。当分区满了之后,将数据溢出到磁盘- 使用哈希函数
h1 - 假设我们有
B个Buffer Pool,其中B-1个用于Partition,一个用于Input Data
- 使用哈希函数
- 对于每个分区,在内存中构建
Hash Table,并通过聚合函数计算聚合属性- 使用哈希函数
h2
- 使用哈希函数
- 示意图参考课件中的
37 ~ 45页
11 Joins
我们通常会将业务数据根据不同的数据模型,存放在多张不同的数据表中,从而避免存储重复的数据。于是,当我们需要的信息分散在不同的数据表中时,我们需要Join操作来合并这些信息
通常来说,我们将数据规模更小的那张表称为Left Table或者Outer Table(在Starrocks中,更倾向于右表更小,这样可以构建出一个较小的Hash Table)
示意图参考课件中的4 ~ 11页
Join Algorithms:
Nested Loop Join- 简单而愚蠢的做法
Sort-Merge JoinHash Join
下面的分析都针对如下查询:
1 | SELECT R.id, S.cdate |
这里涉及的代价计算,只考虑I/O开销,且有如下假设:
R中有M个Page,m个tupleS中有N个Page,n个tuple
11.1 Simple Nested Loop Join
为啥这个算法很愚蠢?因为对于R中的每个tuple都要扫描一遍S,因此开销是Cost = M + (m * N)
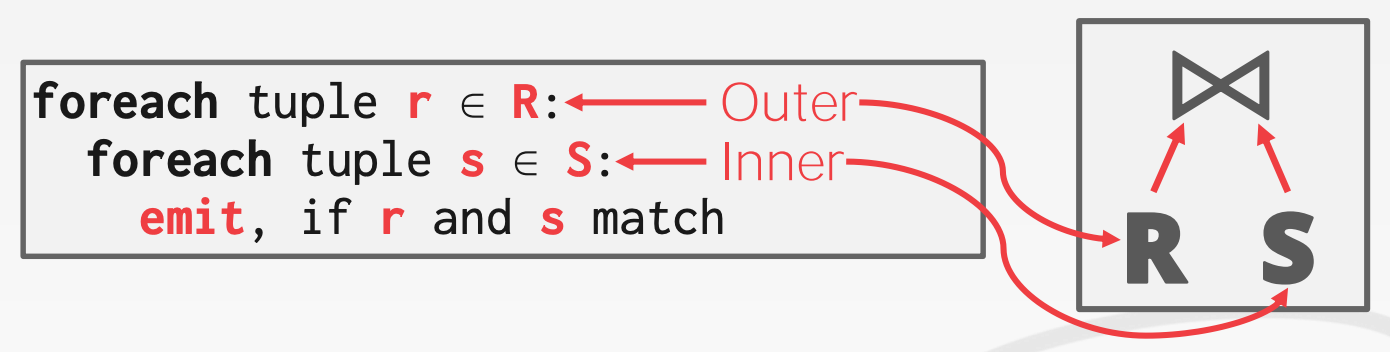
11.2 Block Nested Loop Join
Block Nested Loop Join该算法在Nested Loop Join之上做了进一步的改进,以Block为单位进行循环。对于R中的每个Blcok,扫描一遍S,这样可以减小磁盘访问的频率,开销是Cost = M + (M * N)
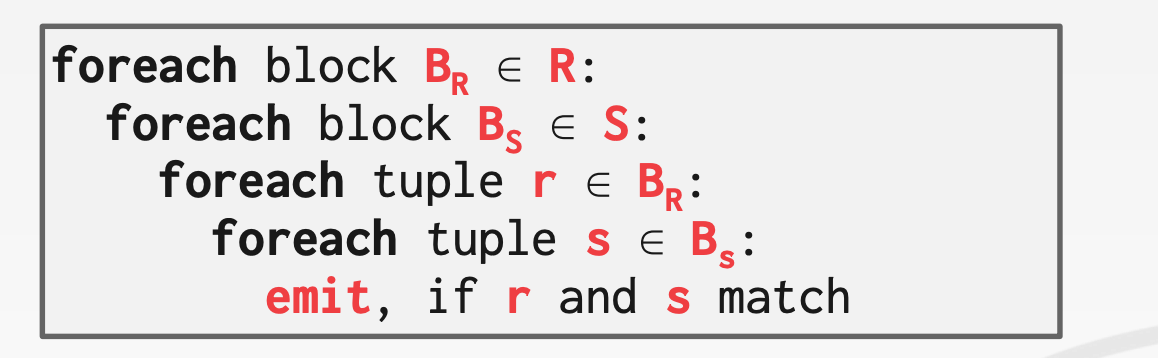
更进一步,当我们有B个Buffer Pool时,对于R中每B-2个Block,扫描一遍S,这样可以进一步减小磁盘访问的频率,此时开销为Cost = M + (⌈ M / (B-2) ⌉ * N)
B-2个用于扫描Left Table- 1个用于扫描
Right Table - 1个用于输出
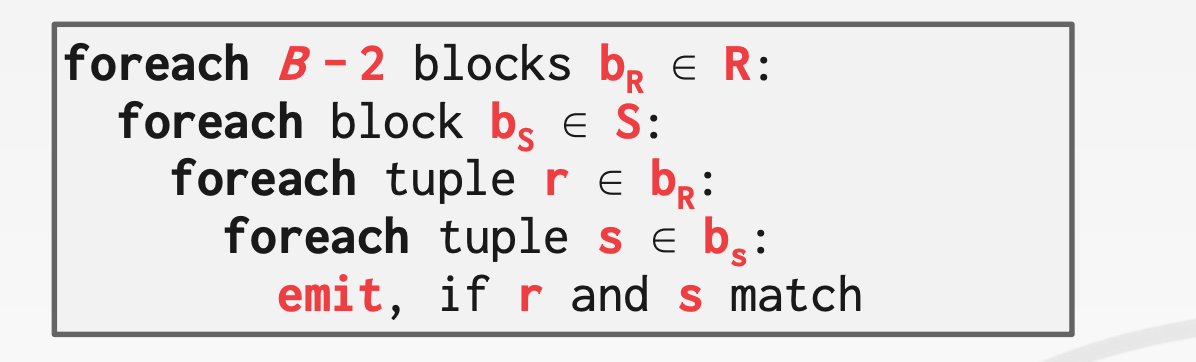
11.3 Index Nested Loop Join
为什么Nested Loop Join方法很糟糕?因为需要顺序扫描S。我们可以借助索引来快速查找S中的匹配项
- 使用现有的索引
- 构建实时索引,比如
Hash Table、B+Tree等

假设索引访问的开销是C,那么整体的开销是Cost = M + (m * C)
11.4 Sort Merge Join
Sort Merge Join算法的大体思路如下:
- 首先,对两张表按照
Join列进行排序 - 然后,合并两张排序后的表,在合并的过程中,过滤出匹配项
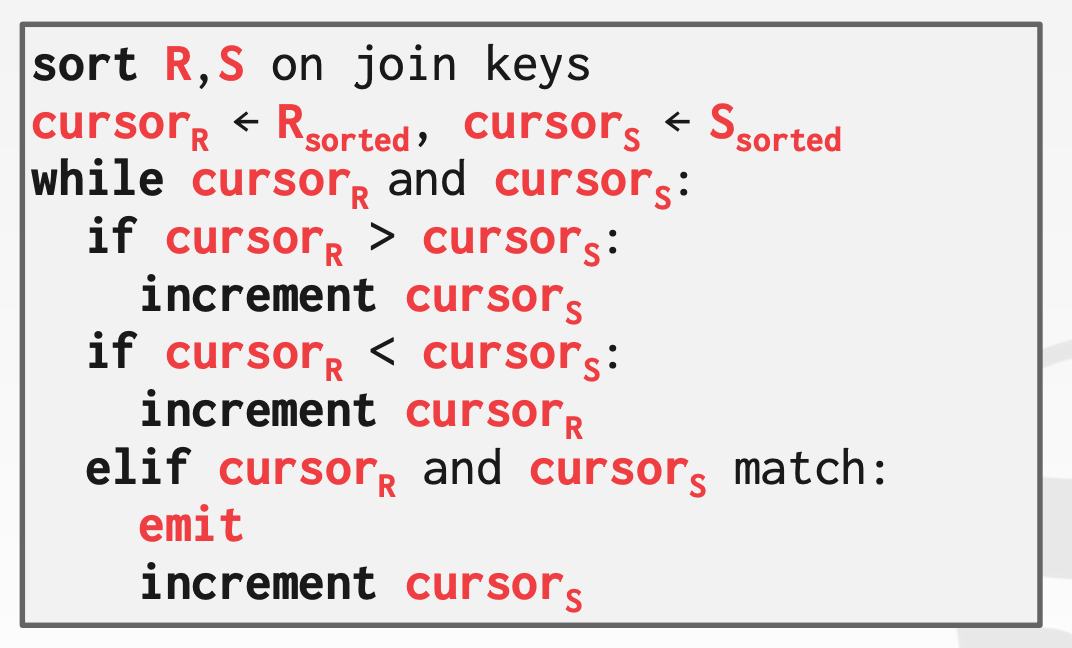
示意图参考课件中的31 ~ 48页
开销计算:
- $Sort\ Cost(R) = 2M * (1 + \lceil log_{B-1}{\lceil \frac{M}{B} \rceil} \rceil)$
- $Sort\ Cost(S) = 2N * (1 + \lceil log_{B-1}{\lceil \frac{N}{B} \rceil} \rceil)$
Merge Cost = M + NCost = Sort Cost(R) + Sort Cost(S) + Merge Cost- 当
R.id与S.id存在重复时,M + N <= Merge Cost <= M * N - 当
R.id与S.id全部一样时,退化成最差的情况,此时Merge Cost = M * N
什么时候使用Sort Merge Join:
- 当
join左右两路输入都已经按join列排序时 - 当
join的结果需要排序时
11.5 Hash Join
如果r ∈ R中的元组和s ∈ S中的元组满足join的条件,那么也就是说join列取值相同。当某个元组r被哈希到某个分区i时,那么S中对应的元组s也会被哈希到同一个分区。于是只需要在各自分区内进行匹配即可,大大缩减了复杂度
Hash Join算法的大体思路如下:
Build Phase:扫描左表的数据,用哈希函数h1构建Hash TableProbe Phase:扫描右表的数据,对每个元组,用同一个哈希函数h1找到对应的分桶,然后在分桶内找匹配项
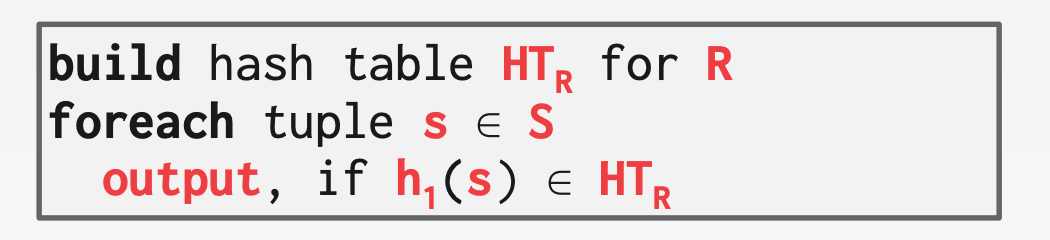
示意图参考课件中的55 ~ 59页
优化:
- 在
Build Phase构建一个Bloom Filter - 在
Probe Phase用Bloom Filter来快速判断元素是否存在于Hash Table中 - 这种方式也被称为
Sideways Information Passing
示意图参考课件中的63 ~ 66页
11.6 Grace Hash Join
如果没存不足以存放整个Hash Table时,而且不想用Buffer Pool,该怎么办?Grace Hash Join就是为解决这个问题而提出来的
Grace Hash Join的大体思路:
Build Phase:将左右两张表哈希到不同的分区中Probe Phase:在每个分区中查询匹配项
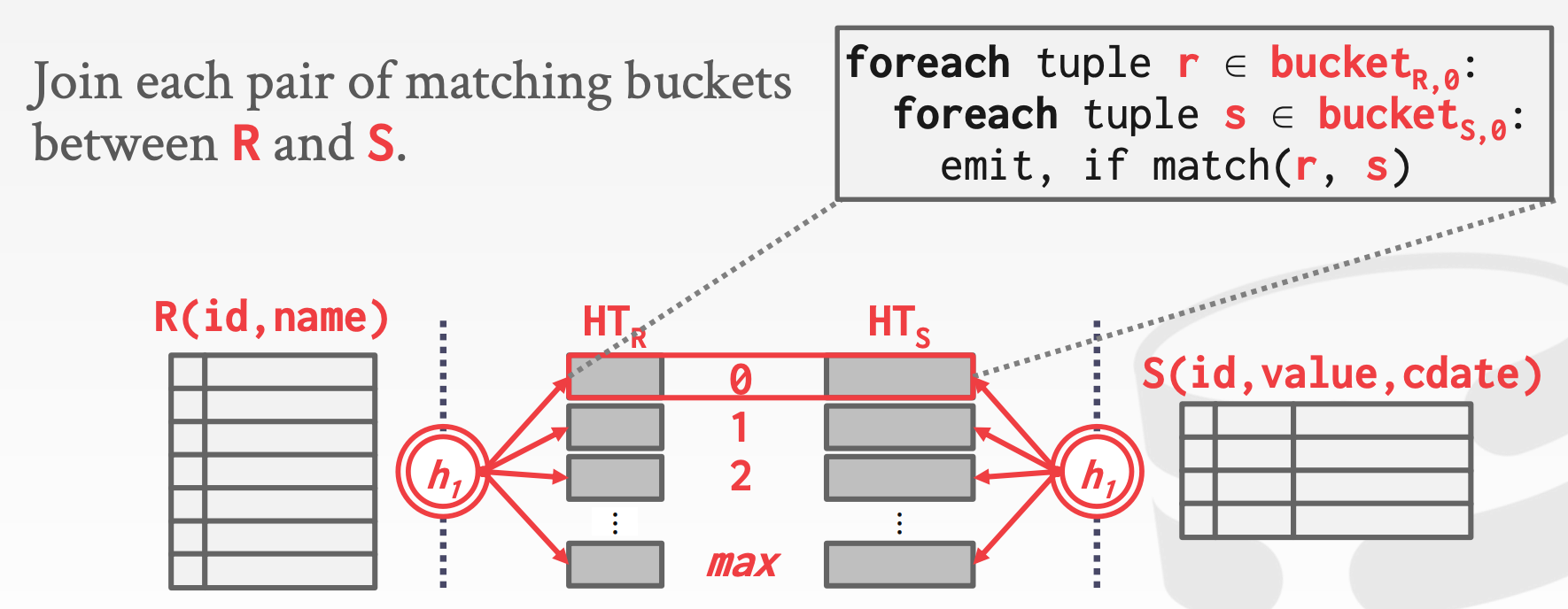
示意图参考课件中的73 ~ 75页
如果分桶的大小仍然大于内存,那么可以使用Recursive Partitioning进行二次分区
- 使用哈希函数
h2(h2 ≠ h1)对$Bucket_{R,i}$构建Hash Table - 对$Bucket_{S,i}$使用同一个哈希函数
h2,在上一步构建的Hash Table中查找匹配项
示意图参考课件中的77 ~ 82页
开销计算:
Partitioning Phase = 2(M + N):左右表分别两次哈希,各扫描两次Probing Phase = M + N:左右表各扫描一次Cost = Partitioning Phase + Probing Phase = 3(M + N)
11.7 总结
假设:
M = 1000, m = 100,000N = 500, n = 40,000Single I/O Cost = 0.1ms
| Algorighm | IO Cost | Example |
|---|---|---|
Simple Nested Loop Join |
M + (m * N) |
1.3 hours |
Block Nested Loop Join |
M + (M * N) |
50 seconds |
Index Nested Loop Join |
M + (m * C) |
20 seconds |
Sort-Merge Join |
M + N + (Sort Cost) |
0.59 seconds |
Hash Join |
3(M + N) |
0.45 seconds |
12 Query Execution 1
12.1 Processing Models
DBMS的Processing Model决定了系统如何执行一个查询计划。不同的Processing Model有不同的工作负载
Iterator ModelMaterialization ModelVectorized / Batch Model
12.1.1 Iterator Model
每个算子都要实现Next方法
- 每次触发该方法,都会返回一个
Tuple或者返回一个标记表示没有可返回的Tuple - 每个算子的
Next方法都通过调用孩子节点的Next方法来获取输入数据(1个Tuple),并进行处理,然后返回给上一级节点
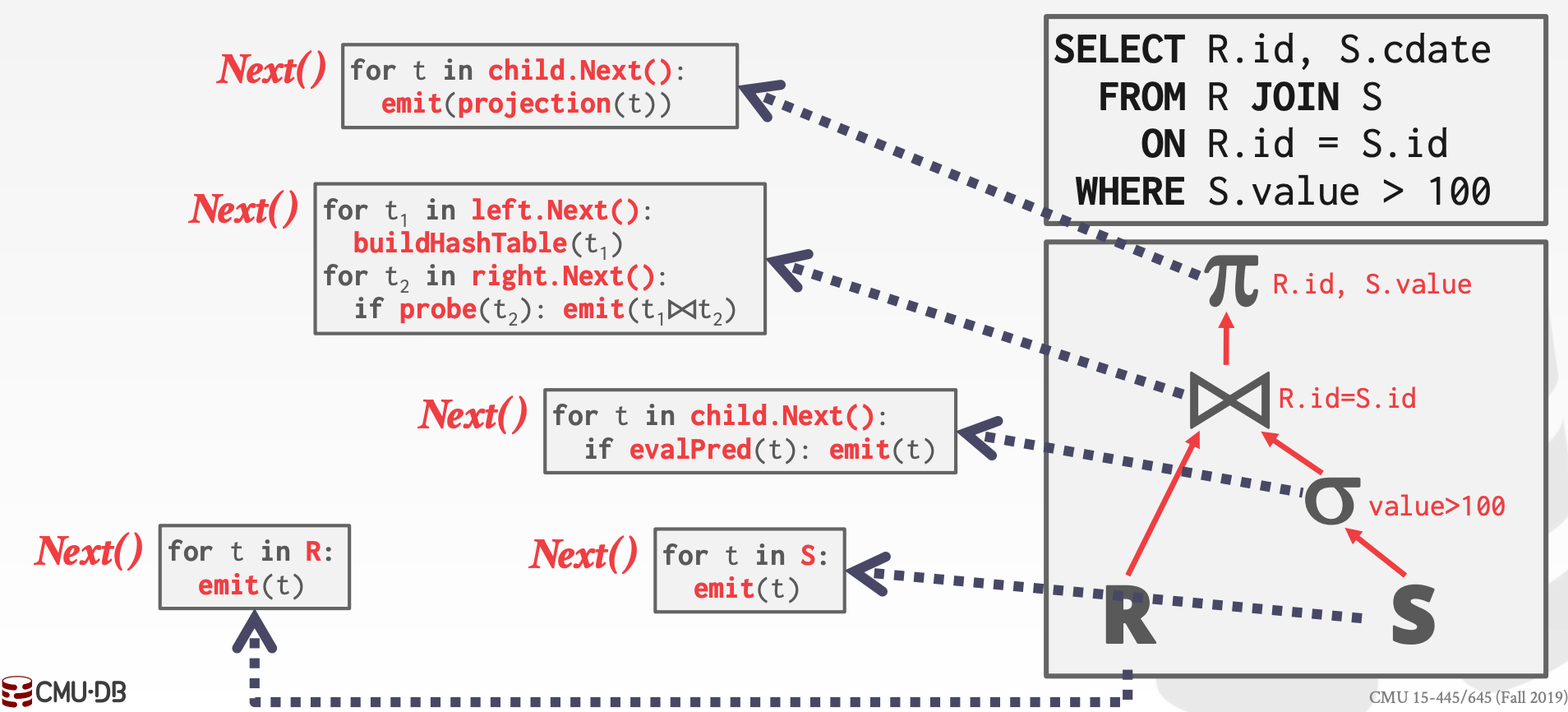
也称为Volcano或者Pipeline模型
示意图参考课件中的7 ~ 12页
特点:
- 易于进行输出控制,比如
limit算子发现输出Tuple数量已经够了,非常容易实现提前结束
12.1.2 Materialization Model
每个算子都要实现Next方法
- 每个算子一次处理所有的输入,并产生最终结果
Next方法拿到孩子节点的所有数据后,才会返回DBMS通常需要进行谓词下推,以免扫描太多数据
示意图参考课件中的15 ~ 18页
特点:
- 更少的函数调用次数
- 适用于
OLTP,因为每次查询一小部分数据 - 不适用于
OLAP,因为在查询中会产生非常大的中间结果
12.1.3 Vectorized / Batch Model
每个算子都要实现Next方法
Next方法一次最多返回Batch个TupleBatch可以动态调整
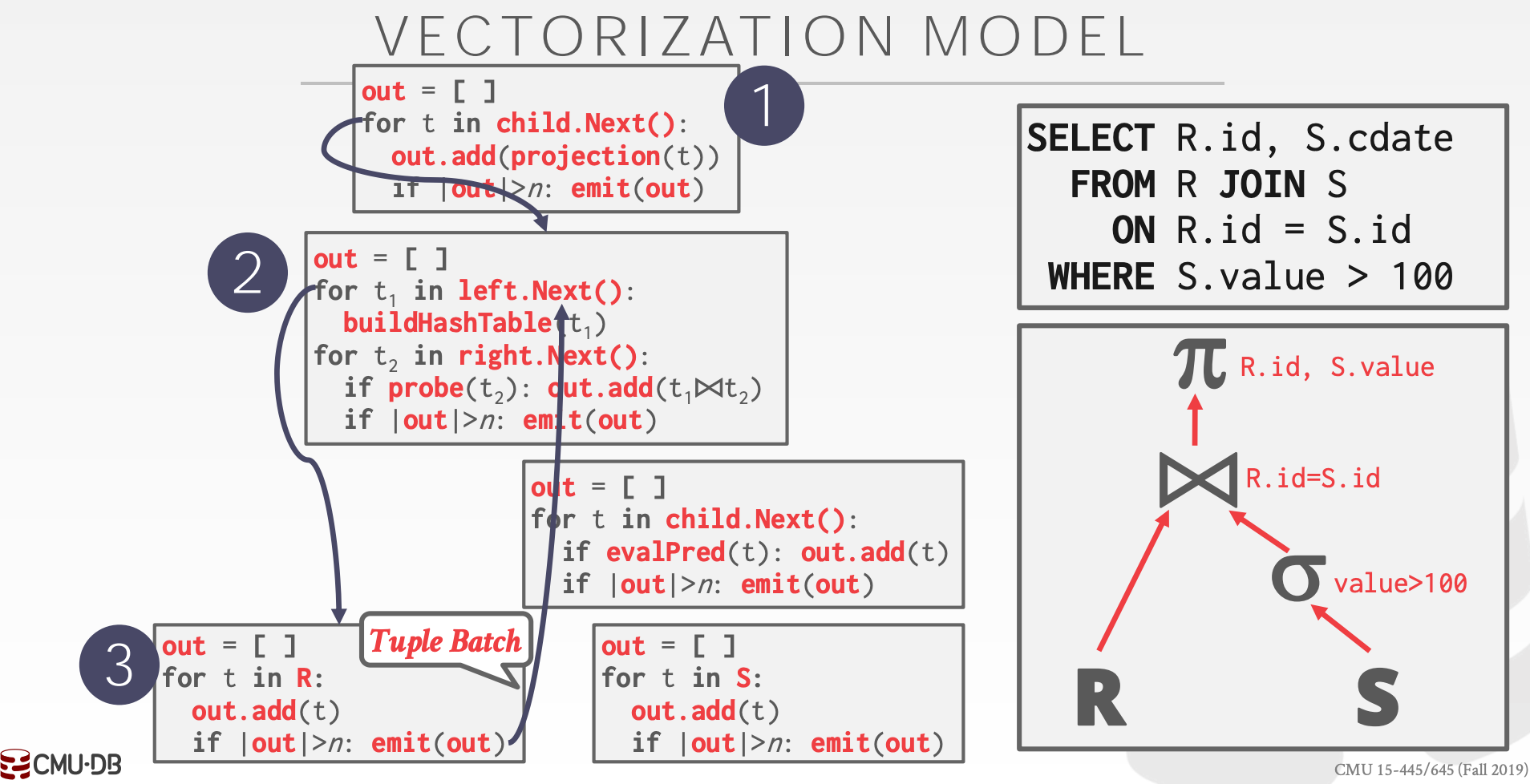
示意图参考课件中的21 ~ 22页
特点:
- 较少的函数调用次数
- 适用于
OLAP,且更有利于使用SIMD指令
12.1.4 Plan Processing Direction
执行方向(Plan Processing Direction)有两种:
- 自顶向下,
Pull模型 - 自底向上,
Push模型
12.2 Access Methods
Access Method是指DBMS如何访问表中的数据。该内容没有定义在关系型代数中
通常来说有三种方式:
Sequential ScanIndex ScanMulti-Index/Bitmap Scan
12.2.1 Sequential Scan
对于表中的每个Page:
- 从
Buffer Pool获取该Page - 遍历
Page,检查是否满足条件
这种方式是效率最差,通常来说有如下几种优化方向:
PrefetchingBuffer Pool BypassParallelizationZone MapsLate MaterializationHeap Clustering
12.2.1.1 Zone Maps
提前计算好每个Page中的聚合信息,于是,在某些情况下,只需要先检查Zone Map中的数据,就可以判断出是否需要进一步扫描该Page
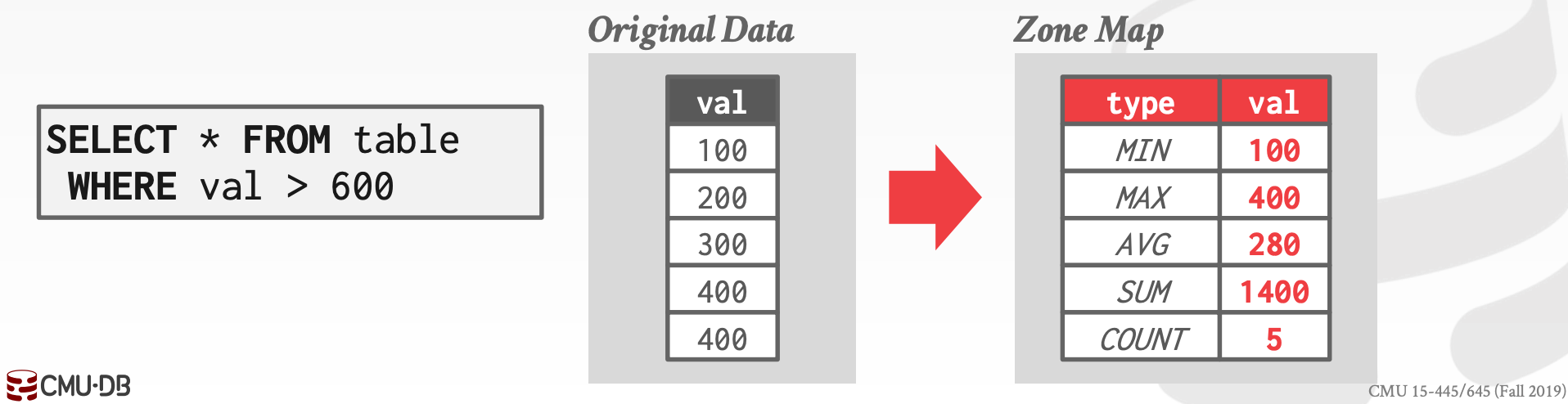
12.2.1.2 Late Materialization
其核心思路是,可以延迟将Tuple拼接在一起
示意图参考课件中的29 ~ 32页
12.2.2 Index Scan
DBMS使用某个索引来查找所需的Tuple,使用哪个索引,取决于:
- 索引包含哪些属性
- 查询需要哪些属性
- 属性的值域空间
- 谓词构成
- 索引键是否唯一
如果选择的是非聚簇索引,即获取的Tuple以该索引排序,那么按这种顺序从Page中读取数据,效率会比较低。因此,通常会先按照Page Id进行排序,然后进行磁盘访问
- 示意图参考课件中的
41 ~ 44页
12.2.3 Multi-Index/Bitmap Scan
如果针对某个查询,有多个可用索引时:
- 用每个索引获取匹配集合
- 合并这些集合,取交集
示意图参考课件中的38 ~ 40页
集合如何取交集?可以通过Bitmap、Hash Table、Bloom Filter
12.3 Expression Evaluation
DBMS将Where子句表示为一颗Expression Tree,通常包含如下类型:
Comparisons:包括=, <, >, !=等Conjunction:包括AndDisjunction:包括OrArithmetic Operators:包括+, -, *, /, %等Const ValuesTuple Attribute References
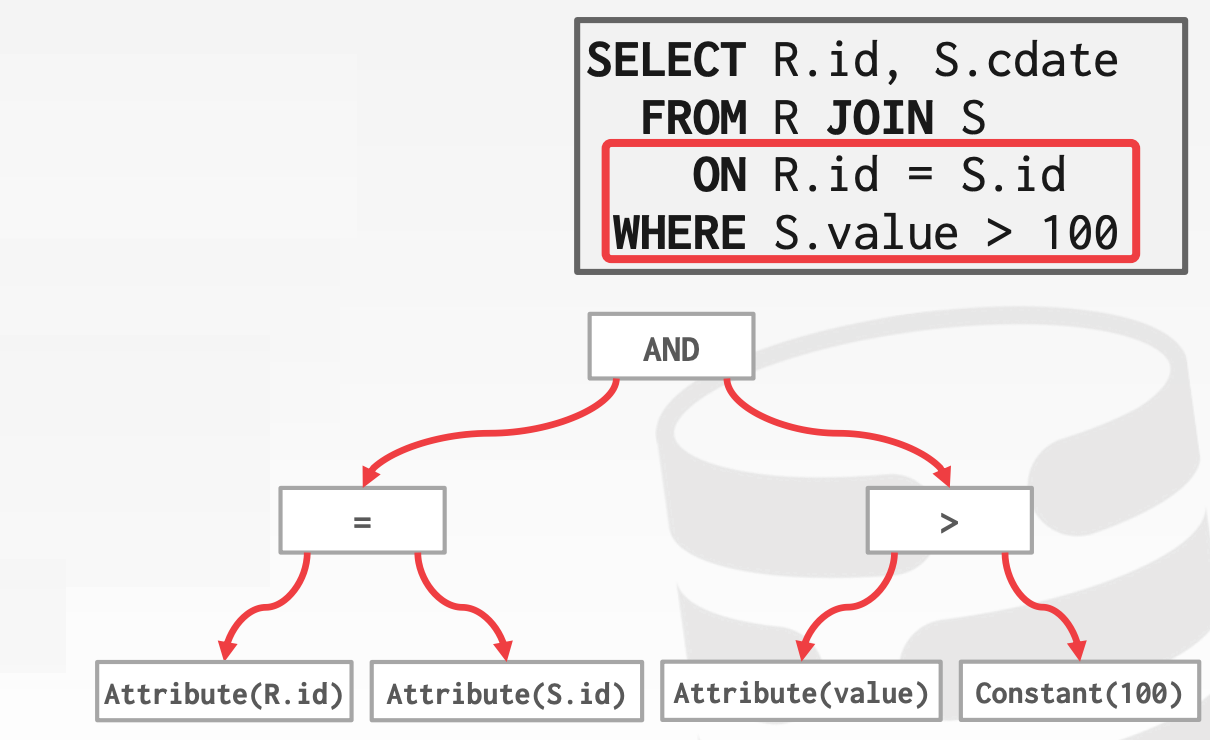
示意图参考课件中的46 ~ 53页
示意图这种方式的效率会比较低:
DBMS会遍历整棵树,然后每个节点都需要计算一次- 如果表达式是
WHERE 1=1,其实可以提前计算
常用优化手段:
- 常量部分,在
SQL解析阶段直接计算 - 提取公共表达式
- 即时编译(
JIT)
13 Query Execution 2
Parallel DBMSs:
- 共享物理资源
- 线程间通信非常高效
- 通信廉价且可靠
Distributed DBMSs:
- 资源分布在不同的节点
- 通信效率比较低
- 通信昂贵,且伴随着衍生问题(网络通信是不可靠的)
13.1 Process Models
Process Model定义了如何构建系统以支持来自多用户应用程序的并发请求。其中,Worker是DBMS的组件,负责代表客户端执行任务并返回结果
13.1.1 Process per DBMS Worker
在这种架构下,每个Worker就是一个独立的OS Process:
- 依赖于操作系统的调度
- 需要利用
Shared Memory来共享一些全局的数据结构 - 一个进程崩溃,不会导致系统不可用
- 例子:
IBM DB2、Postgres、Oracle
13.1.2 Process Pool
在这种架构下,DBMS管理了一个进程池,Work可以使用该进程池中的空闲进程来处理客户端的请求:
- 仍然依赖于操作系统的调度,以及
Shared Memory Cache Locality较差- 例子:
IBM DB2、Postgres(2015)
13.1.3 Thread per DBMS Worker
在这种架构下,DBMS只有一个进程,但是包含了多个工作线程:
- 自行实现调度
- 线程切换开销较小,无需管理
Shared Memory - 一个线程崩溃,会导致整个进程崩溃,从而导致整个系统不可用
- 例子:
IBM DB2、MSSQL、MySQL、Oracle(2014)
注意,该架构并不意味着一个请求的执行可以并行化
13.1.4 Scheduling
对于每个查询,DBMS需要决定Where/When/How to execute:
- 需要产生多少个任务?
- 需要使用多少个核?
- 任务需要在哪个核上执行
- 任务如何存储其结果
13.2 Execution Parallelism
Inter VS. Intra Query Parallelism:
Inter-Query:重点在于,不同的查询可以并行执行,可以提高吞吐量以及降低时延Intra-Query:重点在于,同一个查询可以分成多个子任务然后并行执行(或者说算子并行执行),可以降低复杂查询的时延
13.2.1 Intra-Query Parallelism
Parallel Grace Hash Join:
- 对于每个
Bucket中的R和S的子集,使用一个独立的线程来进行Join运算 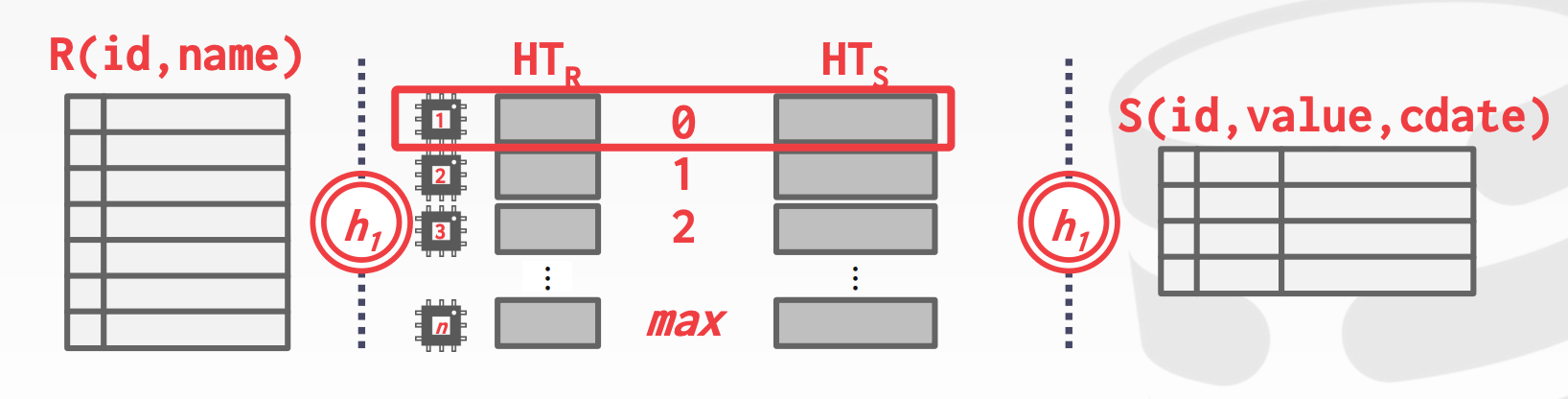
13.2.1.1 Intra-Operator (Horizontal)
核心思想:将算子并行化,这些算子对不同的数据子集执行相同的操作。此外,需要额外增加Exchange算子,来合并孩子节点的数据
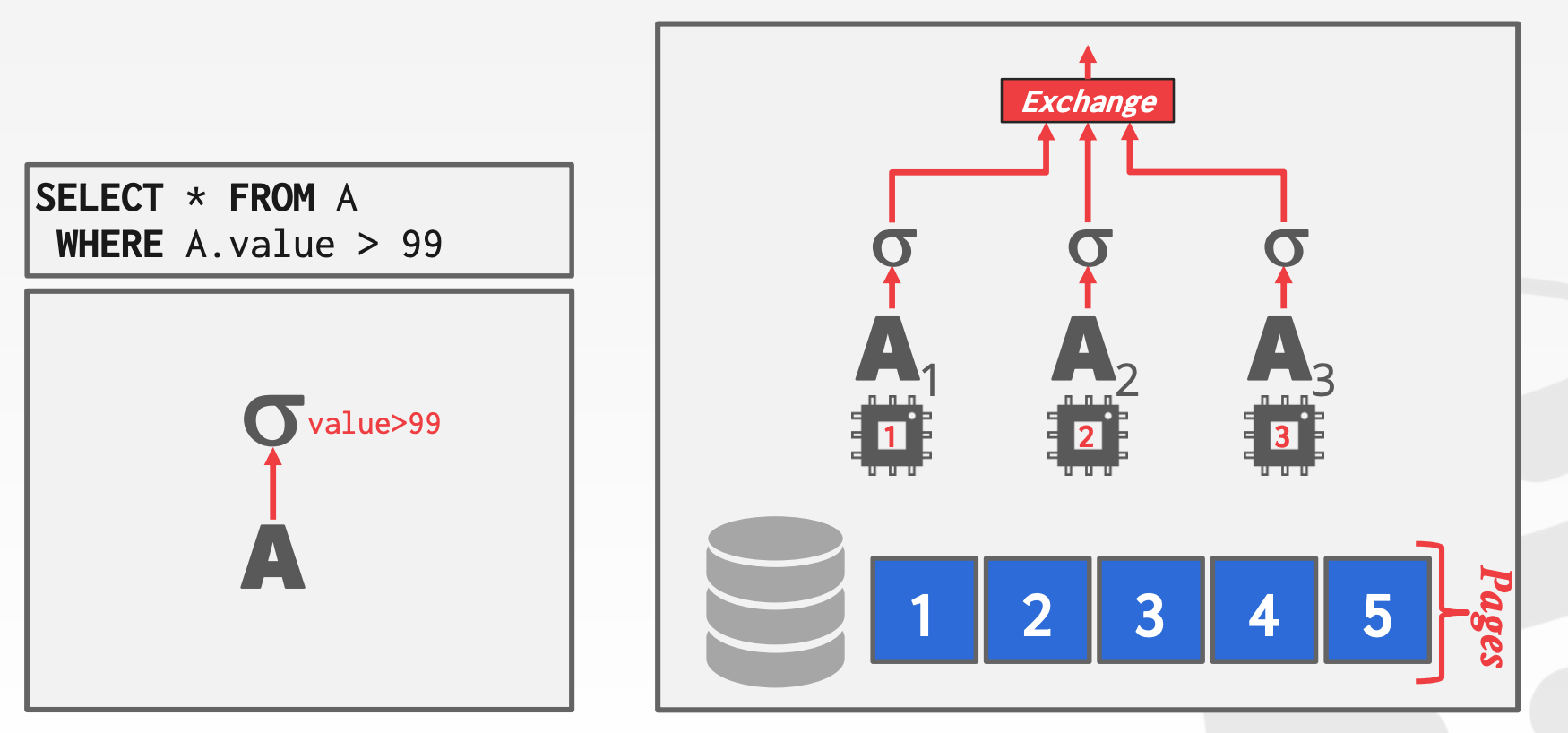
示意图参考课件中的22 ~ 27页
Exchange算子有如下三种类型:
Gather:将多路输入合并成一路输出Repartition:将多路输入,重新组织成多路输出Distribute:将一路输入,重新组织成多路输出- 示意图参考课件中的
29 ~ 36页
13.2.1.2 Inter-Operator (Vertical)
每种算子使用一个线程
示意图参考课件中的38 ~ 40页(没太看明白)
13.2.1.3 Bushy
Inter-Operator的扩展,多个算子组成一个算子组,每种算子组使用一个线程,不同算子组之间需要通过Exchange来交互数据
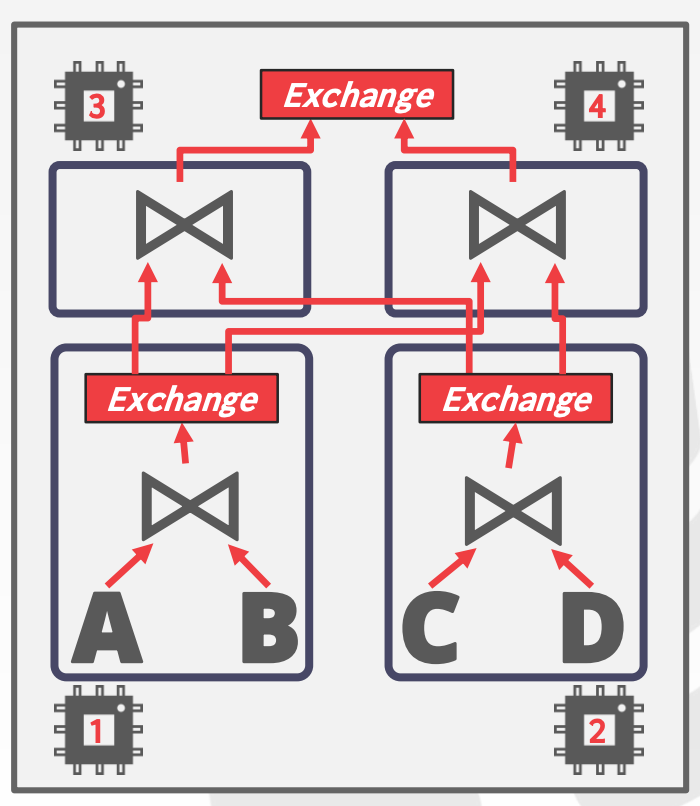
13.3 I/O Parallelism
在磁盘I/O成为性能瓶颈时,增加并行度不会提升效率,反而有可能降低效率,因为增大了磁盘读写的乱序程度
DBMS安装在不同的磁盘上,可以实现I/O Parallelism:
- 一个
Database分布在一个Disk - 一个
Database分布在多个Disk - 一个
Table分布在一个Disk - 一个
Table分布在多个Disk
13.3.1 Multi-Disk Parallelism
通过配置操作系统或者硬件,使得DBMS安装在多块不同的磁盘上。这对于DBMS是透明的
LVMRAID
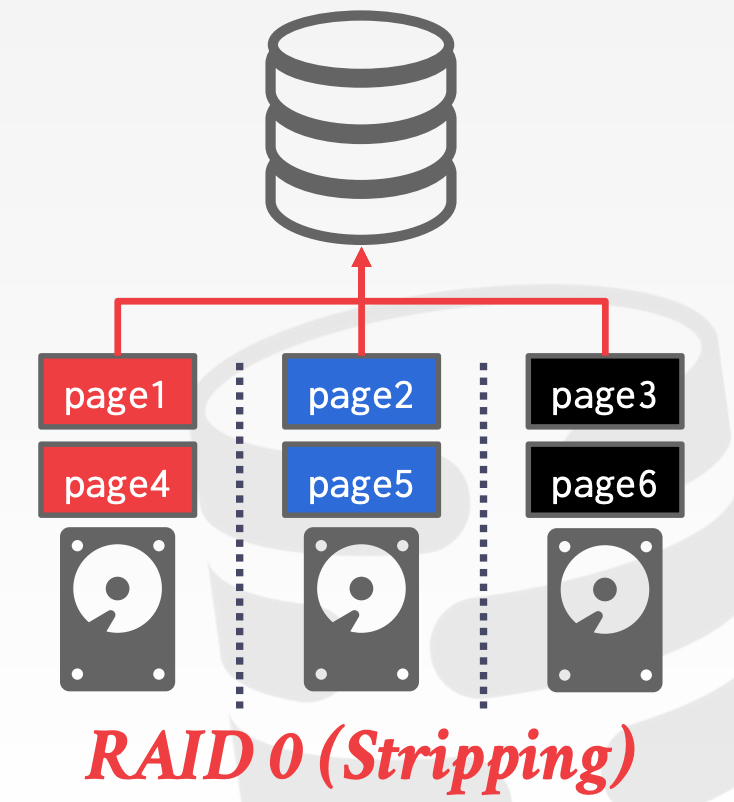
13.3.2 Database Partitioning
有些DBMS允许在创建Database时指定存储的路径
13.3.3 Table Partitioning
将单个逻辑表拆分为不相交的物理段,分别存储和管理
Vertical Partitioning:将逻辑表按列进行进行切分,分别存储Horizontal Partitioning:将逻辑表按行进行切分,分别存储
14 Optimization 1
由于SQL是声明式的语言,只表达想要获取什么数据,而没有指定如何获取。不同的执行计划的效率千差万别
查询优化包含如下两种方式:
Heuristics/Rules:即启发式的- 重写SQL,去除冗余部分,精简表达式
- 可能需要检查
Catalog
Cost-based Search- 使用模型来评估给定查询计划的开销
- 在多种不同的等价查询计划中,找出开销最小的那个
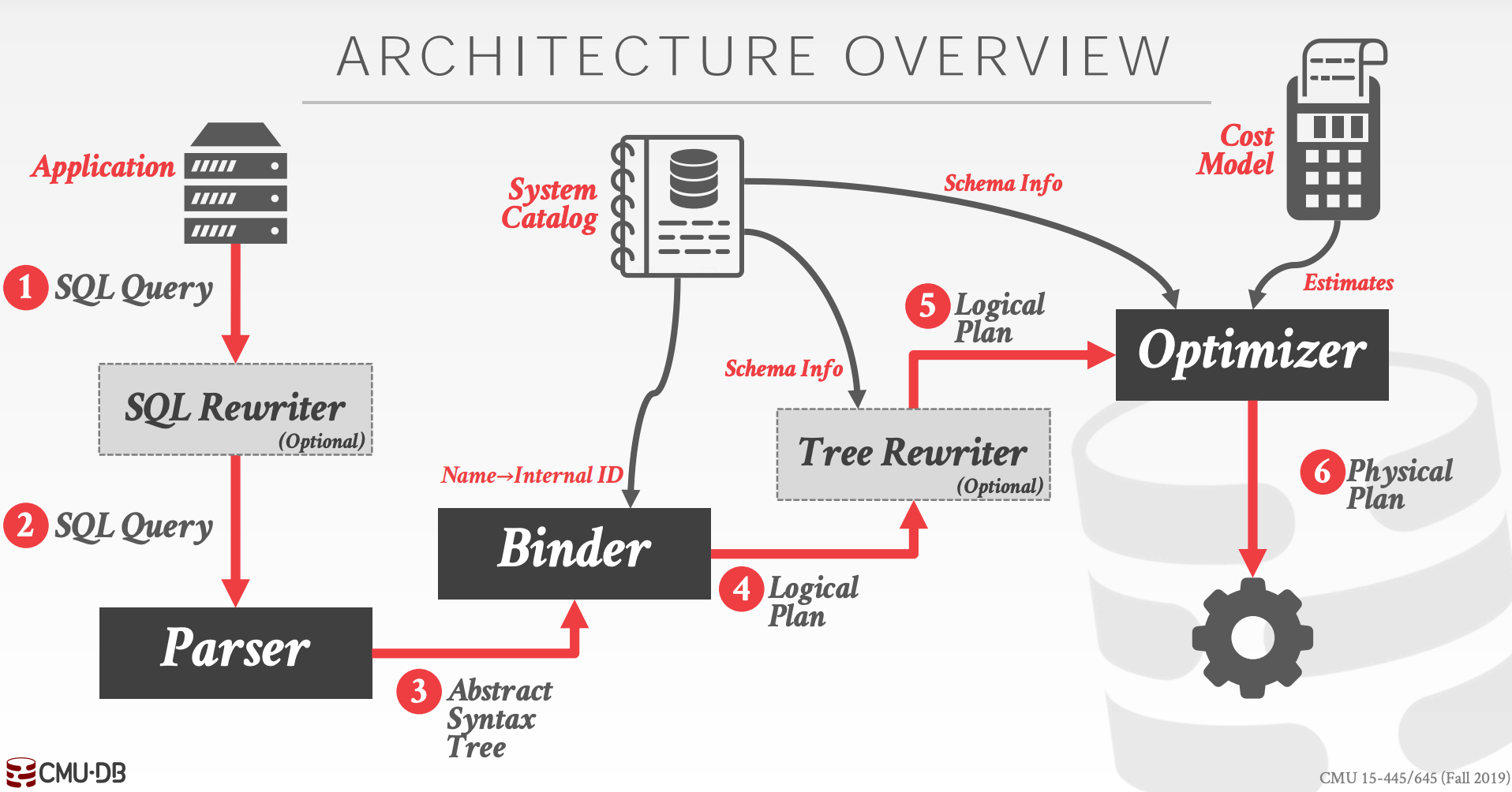
查询优化是NP-Hard问题,也是构建DBMS中最重要的部分
14.1 Relational Algebra Equivalences
如果两个代数表达式(Algebra Expression)能产生相同的结果,那么就认为它俩是等价的
即便DBMS不借助Cost Model也可以识别哪个查询计划更优,这种方式叫做Query Rewriting
14.1.1 Predicate Pushdown
谓词下推(Predicate Pushdown)的核心思想是,尽可能地让数据过滤在更下层的算子中执行,这样在算子之间流转的数据量就可能大大减小
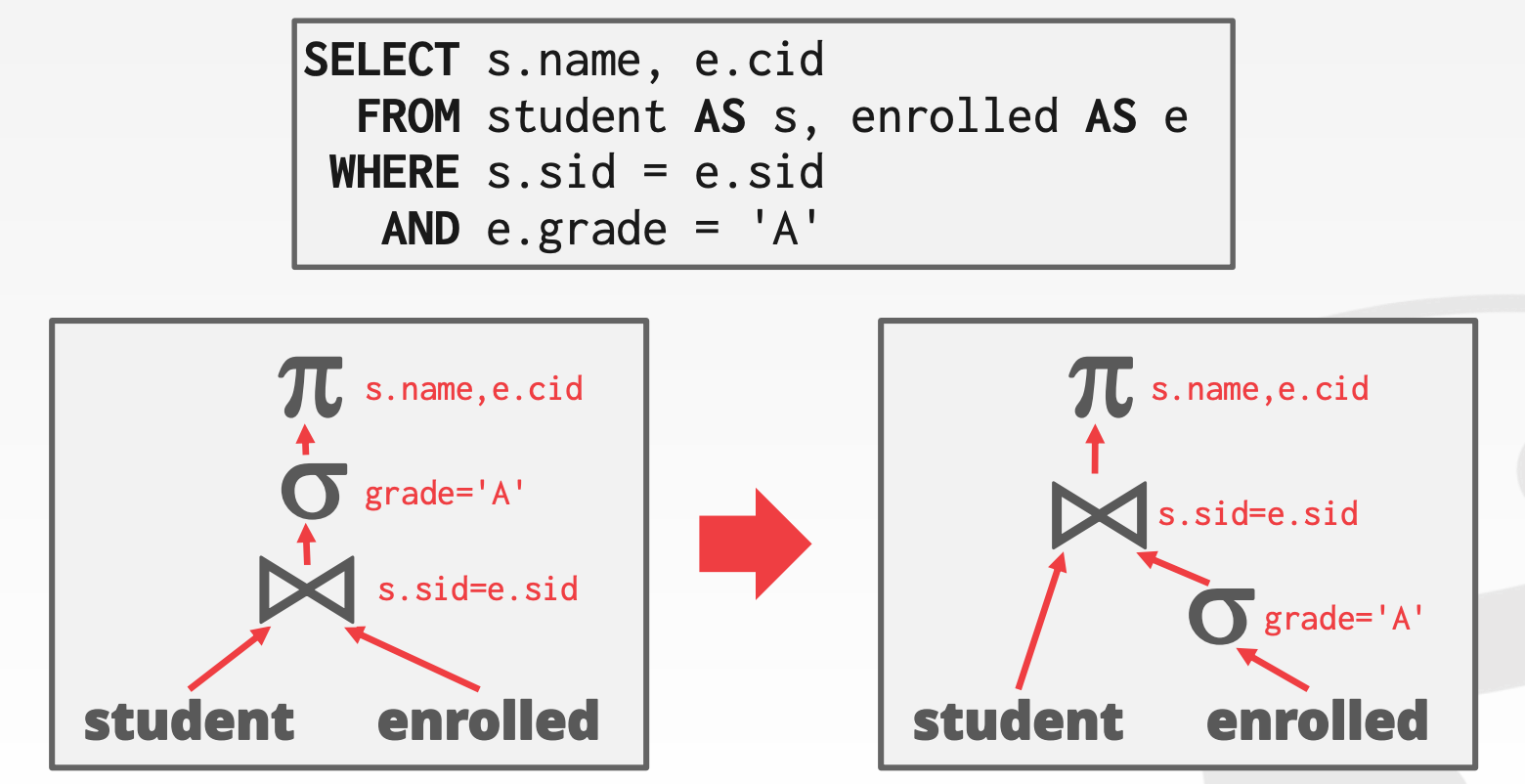
此时,以下两个代数表达式就是等价的
- $\pi_{name,cid}(\sigma_{grade='A'}(student \bowtie enrolled))$
- $\pi_{name,cid}(student \bowtie (\sigma_{grade='A'}(enrolled))$
14.1.2 Projections
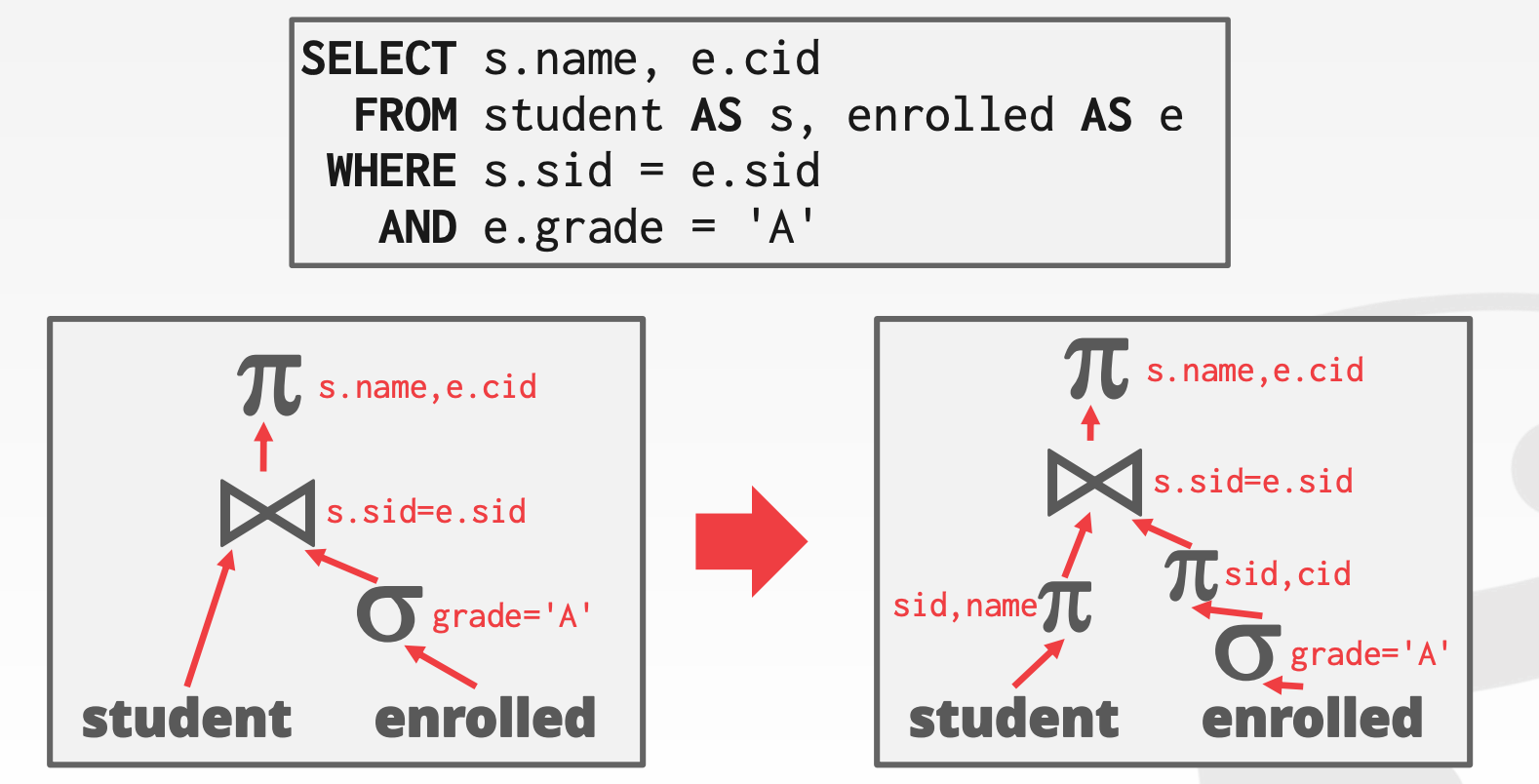
尽可能早的进行物化操作(Projection),这样可以减少中间结果的产生。同时仅物化必须的列。对于列存系统,这种方式没有太大的意义
14.1.3 Join
对于Join算子,左右表的顺序可以任何兑换,例如:
- $R \bowtie S = S \bowtie R$
- $(R \bowtie S ) \bowtie T = R \bowtie (S \bowtie T)$
当join算子很多时,查询计划的空间会变得异常的庞大,遍历并计算每一种可能的查询计划的开销也非常耗时,因此,我们必须在有限的空间中找出相对最优的查询计划
14.2 Static Rules
我们可以对原始SQL按照某些既定的规则进行重写,以达到去除冗余部分或者简化SQL的目的
示例1:谓词恒为真或恒为假
1 | SELECT * FROM A |
示例2:Join可以消除
1 | SELECT A1.* FROM A AS A1 |
示例3:谓词恒为真
1 | SELECT * FROM A AS A1 |
示例4:谓词合并
1 | SELECT * FROM A |
15 Optimization 2
15.1 Plan Cost Estimation
可能影响执行效率的因素:
- CPU
- 磁盘
- 内存
- 网络
对于给定数据表R,DBMS通常会存储如下元数据:
- $N_{R}$:表的行数
- $V(A, R)$:属性`A`的不同取值的个数(基数)
15.1.1 Selectivity
于是Selection Cardinality就表示了某个属性的每个不同值的平均行数,即$SC(A, R) = \frac{N_R}{V(A, R)}$。即包含一个假设:分布是均匀的
谓词(Predicate)P的选择性(Selectivity, sel)可以表示为:符合条件的元组所占的比例。且不同的谓词有不同的计算方式
Equality Predicate:例如,A = constant- $sel(A=constant) = \frac{SC(P)}{N_R}$
Range Predicate:例如,A >= a- $sel(A \ge a) = \frac{A_{max} - a}{A_{max} - A_{min}}$
Negation Predicate:例如,not P- $sel(not\ P) = 1 - sel(P)$
Conjunction:例如,P1 ∩ P2- $sel(P1 \cap P2) = sel(P1) * sel(P2)$
- 包含假设:2个谓词是相互独立的
Disjunction:例如,P1 ∪ P2- $sel(P1 \cup P2) = sel(P1) + sel(P2)- sel(P1 \cap P2)$
- 包含假设:2个谓词是相互独立的
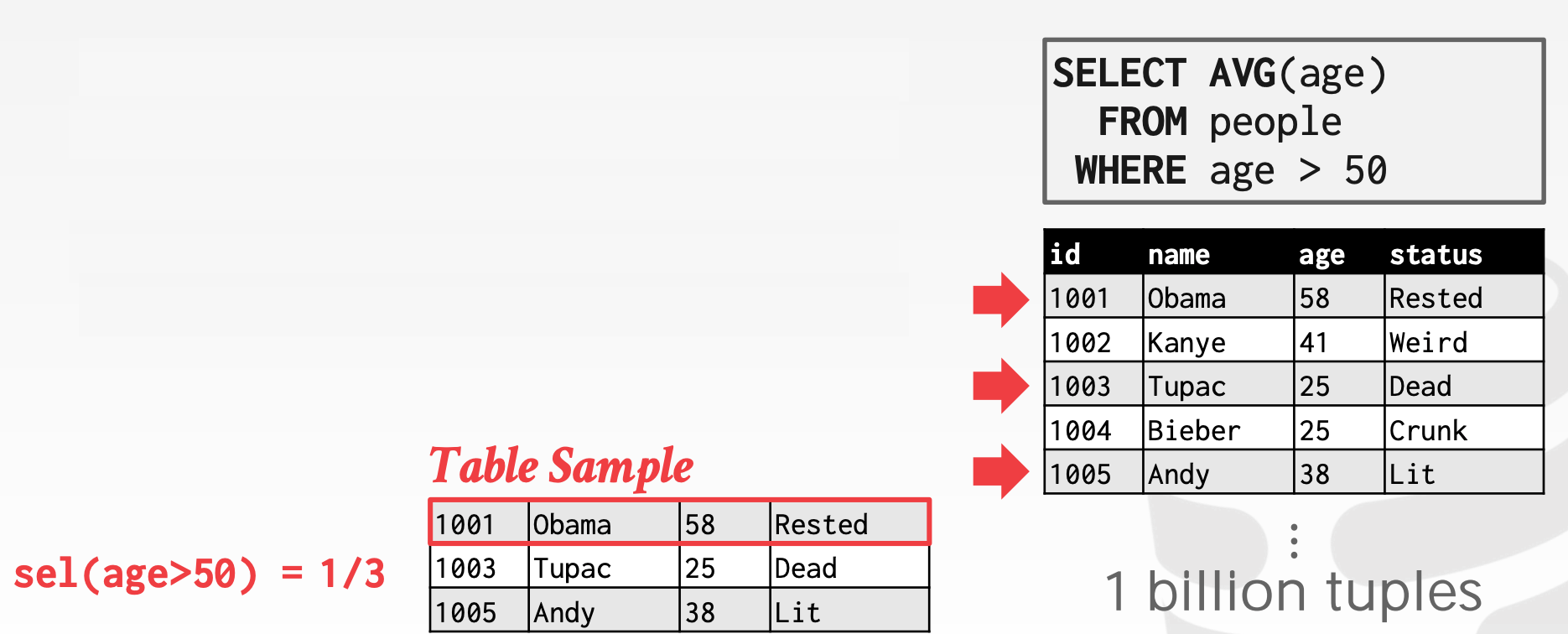
15.1.2 Sampling
现代的DBMS会存储一个表结构的采样数据集(在数据表发生重大变更时,会更新该采样数据级)。DBMS会利用采样数据来对Selectivity进行预测
例如,对于Range Predicate,借助采样就可以比较准确地进行预估
15.2 Plan Enumeration
DBMS在根据既定规则对原始SQL进行重写后,就会列举出一系列的等价查询计划,并且计算这些查询计划的开销,并从中选出最优的查询计划
15.2.1 Single-Relation Query Planning
首先,选择最优的访问方式:
- 顺序扫描
- 二分查找
- 索引查找
其次,计算各个谓词的选择性,并对其进行排序
对OLTP而言,启发式方法已经足够了(OLTP的查询一般来说非常简单)
- 选择最优的索引
- join一般会建立在
foreign key上 - 几个启发式的可选
plan
15.2.2 Multi-Relation Query Planning
当join的数量上升时,查询计划空间会迅速膨胀。为了简化这一问题,通常只考虑左深树(现代的DBMS可能不再使用这一假设)
- 基于这一假设,更容易生成全流水化的查询计划
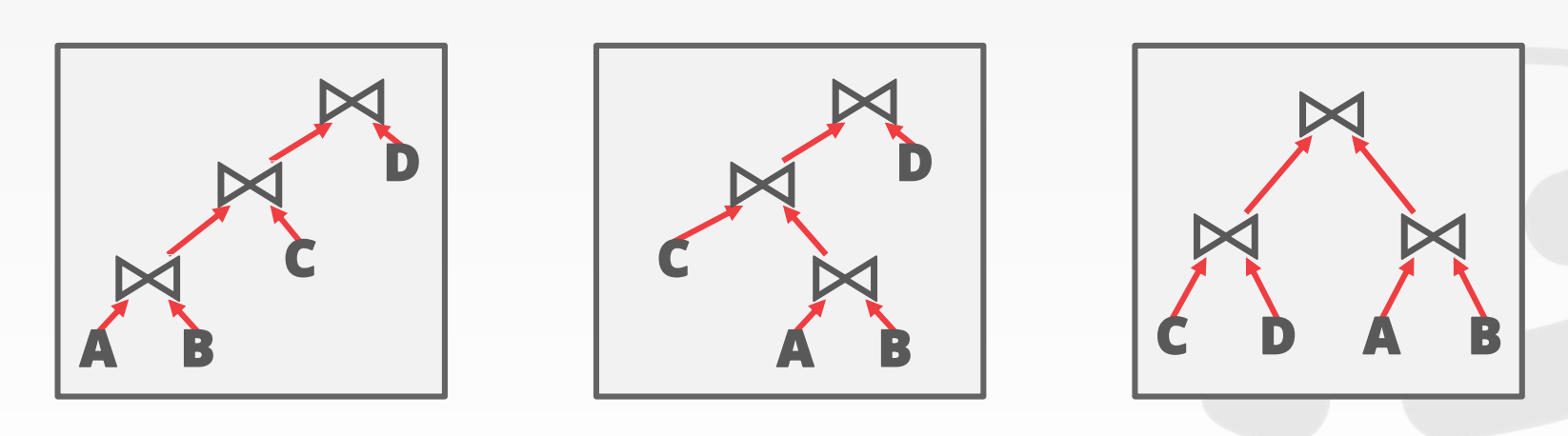
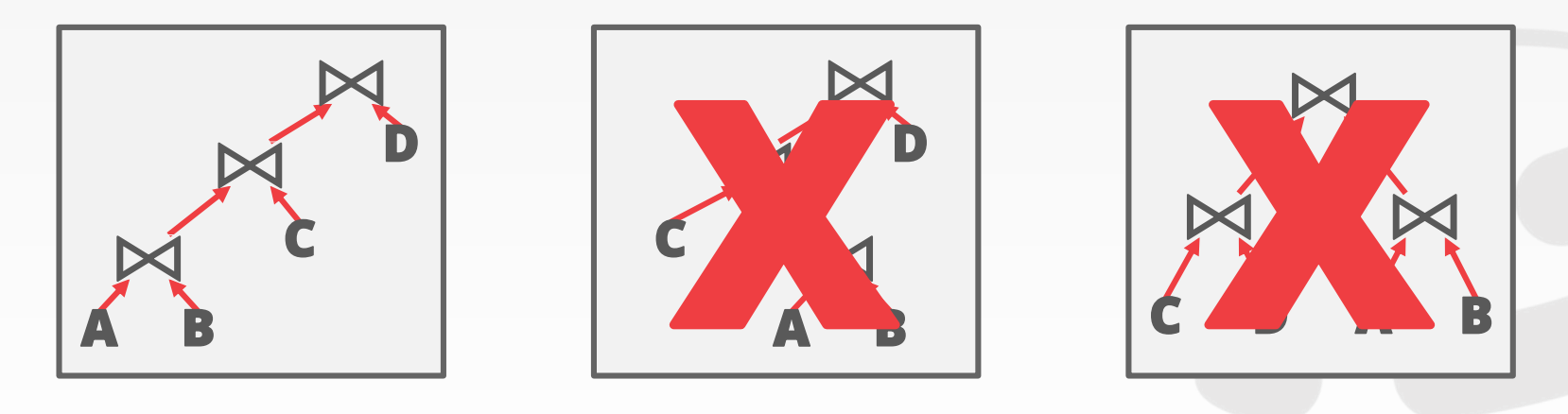
列出所有可能的查询计划,维度包括:
- 枚举左深树的顺序。比如是
T1 -> T2 -> T3还是T2 -> T1 -> T3等等 - 枚举
Join的实现方式。比如用Hash还是Merge Sort还是Nested Loop - 枚举数据表的访问方式。比如用索引(哪个索引?)还是顺序访问
这样会得到一个非常庞大的查询计划集,我们通常使用动态规划(Dynamic Programming)来选择最优解。示意图参考课件中的40 ~ 44页
15.2.3 Postgre Optimizer
Postgre的优化器会评估所有可能的Join树,包括左深树、右深树以及bushy
Postgre包含了2个优化器:
- 使用动态规划的传统的优化器(当表的数量小于12时,用这个优化器)
- 使用遗传查询优化器
Genetic Query Optimizer, GEQO(当表的数量大于等于12时,用这个优化器)
示意图参考课件中的52 ~ 57页
15.3 Nested Sub-Queries
DBMS处理子查询(Sub-Queries),通常有两种处理方式:
- 重写:将查询改写成普通查询
- 解耦:将子查询的结果存储到临时表中,临时表在查询结束后就会丢弃


对于复杂查询,优化器通常会将查询拆分成多个逻辑块,每次只关注一个逻辑块
示意图参考课件中的59 ~ 66页
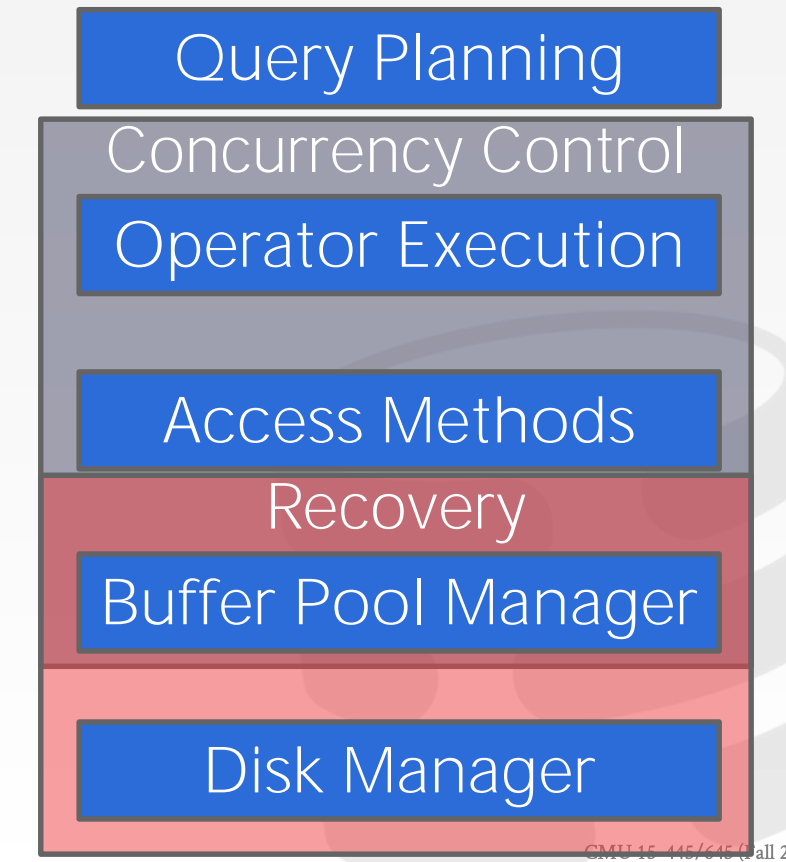
16 Concurrency Control
并发控制和恢复渗透到了整个DBMS的架构中
16.1 Transactions
事务是DBMS中变更的最小单元
从用户程序的视角来看,Database和Transaction的定义分别为:
Database:一组固定的命名数据对象Transaction:一系列的读写操作
正确性标准:ACID
Atomicity:整个事务要么整体生效,要么整体不生效Consistency:如果事务本身满足一致性,且开始事务前DB满足一致性,那么事务结束后(提交或者终止)DB也满足一致性(一致性的具体含义是由业务定义的)Isolation:不同事务之间相互隔离Durability:如果事务提交了,那么所有改动均已持久化
16.2 Atomicity
通常来说,有如下机制可以实现Atomicity
Logging:DBMS将所有操作以日志的形式保存下来,这样在事务终止后可以通过日志进行回滚- 内存和磁盘均会存储
undo records - 大多数系统都会采用这种做法,因为它便于进行审计追踪、且效率较高
- 内存和磁盘均会存储
Shadow Paging:DBMS会将事务涉及到的Page进行拷贝,然后对拷贝进行修改操作。当事务提交后,这些拷贝才对外可见- 由
System R率先采用。CouchDB以及LMDB也采用
- 由
16.3 Consistency
一致性(Consistency)具体是指DB是否在逻辑上正确(业务定义),具体可分为:
Database Consistency:数据库模型准确地描述了现实世界,且遵循了完整性约束- 只要应用保证
Transaction Consistency,那么DBMS会保证Database Consistency
- 只要应用保证
Transaction Consistency:未来的事务会看到过去在数据库内部提交的事务所造成的影响Transaction Consistency是上层应用的责任。举个例子,A给B转钱100,包含两个操作:若A减少100,B只增加50,这就不满足一致性(钱的总数变少了)
16.4 Isolation of Transactions
通常来说,DBMS会将多个事务的操作交织在一起执行,但是从每个事务各自的视角来看,它会认为整个事务的执行是独立的,不受其他事务影响的。并发控制模型(Concurrency Model)定义了DMBS以何种方式,来交织这些操作
Pessimistic:悲观的做法是,把问题扼杀在摇篮中Optimistic:乐观的做法是,假设冲突不发生
两个操作冲突的条件:
- 两个操作属于不同的事务
- 两个操作都针对同一个对象,且至少有一个写操作
冲突的种类包括:
Read-Write Conflicts (R-W)Unrepeatable Reads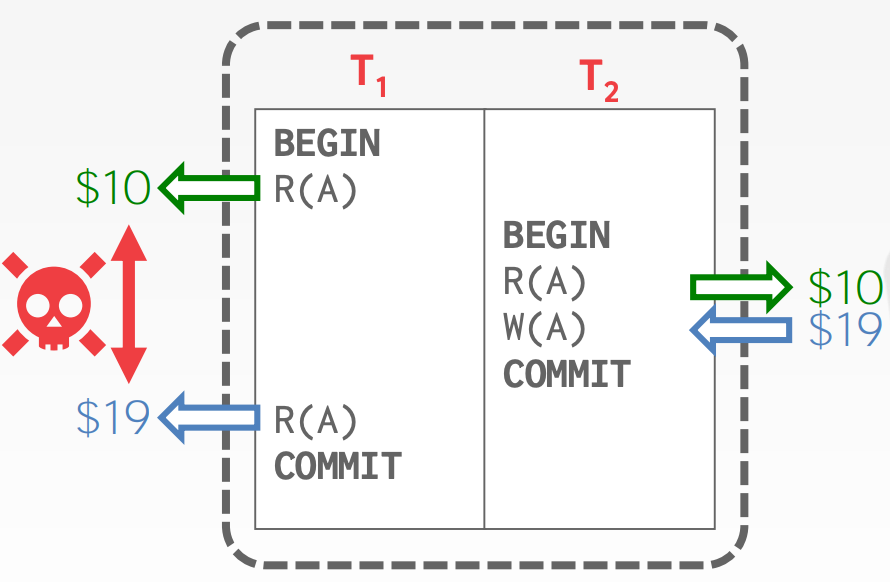
Write-Read Conflicts (W-R)Reading Uncommitted Data ("Dirty Reads")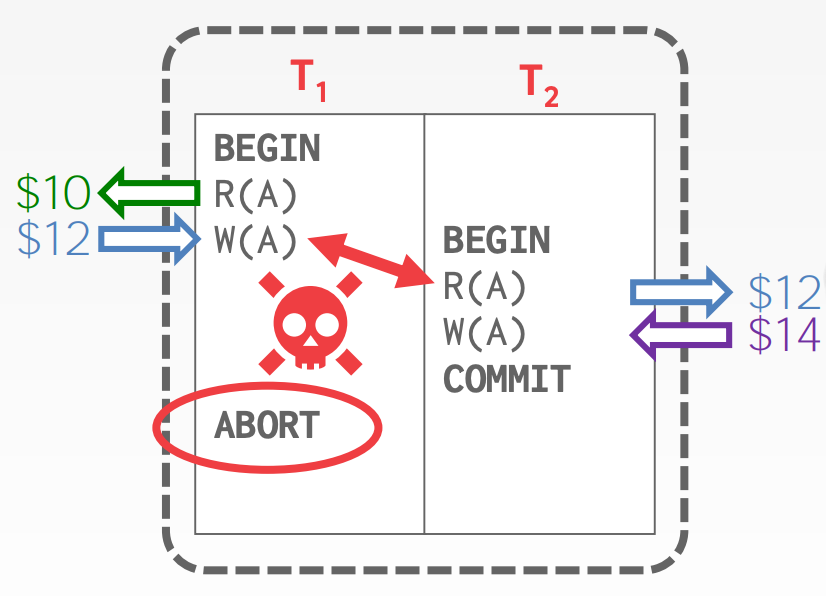
Write-Write Conflicts (W-W)Overwriting Uncommitted Data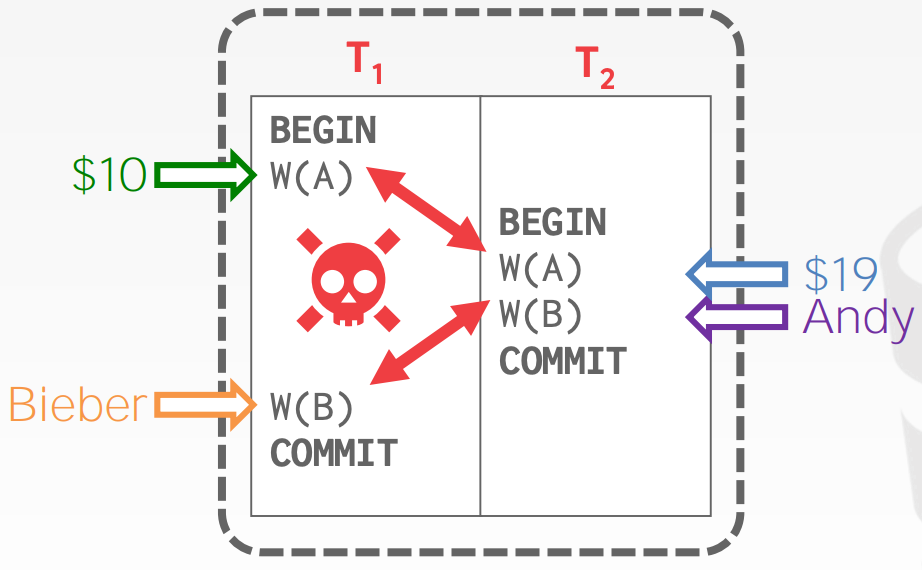
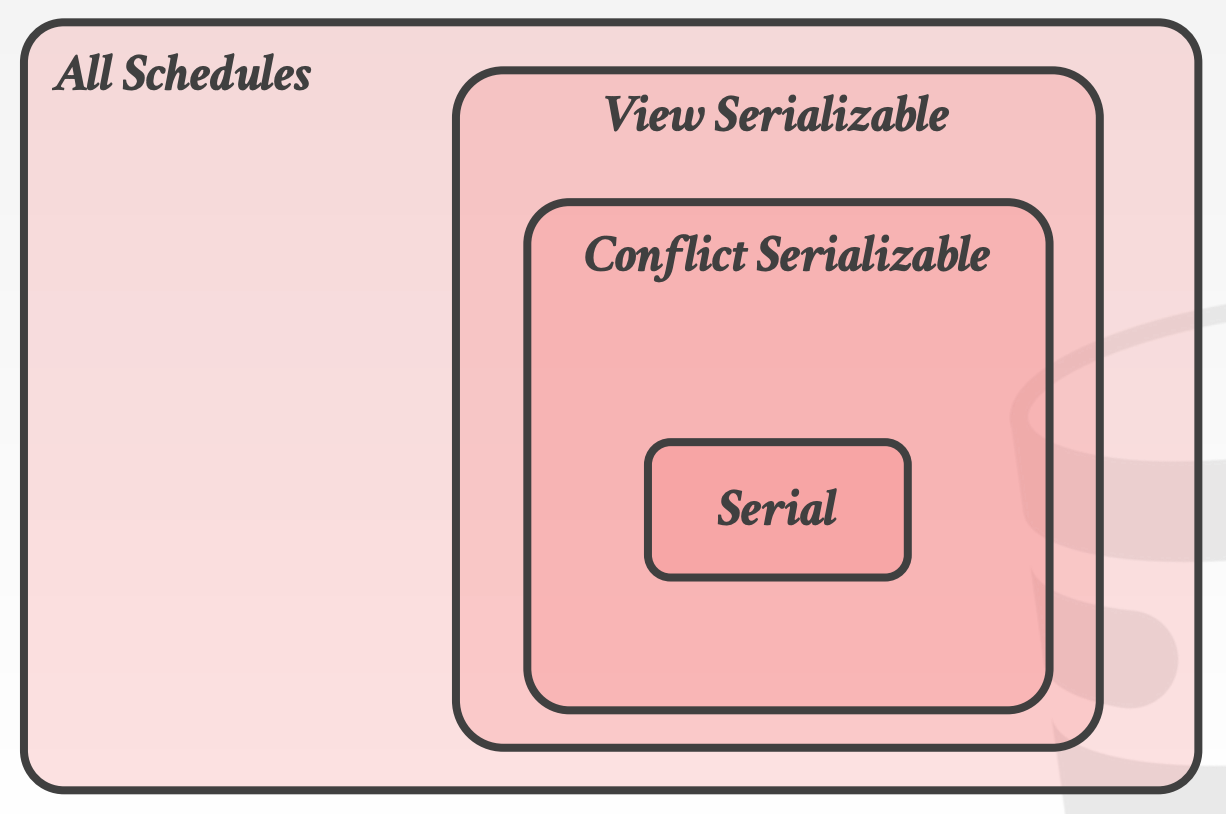
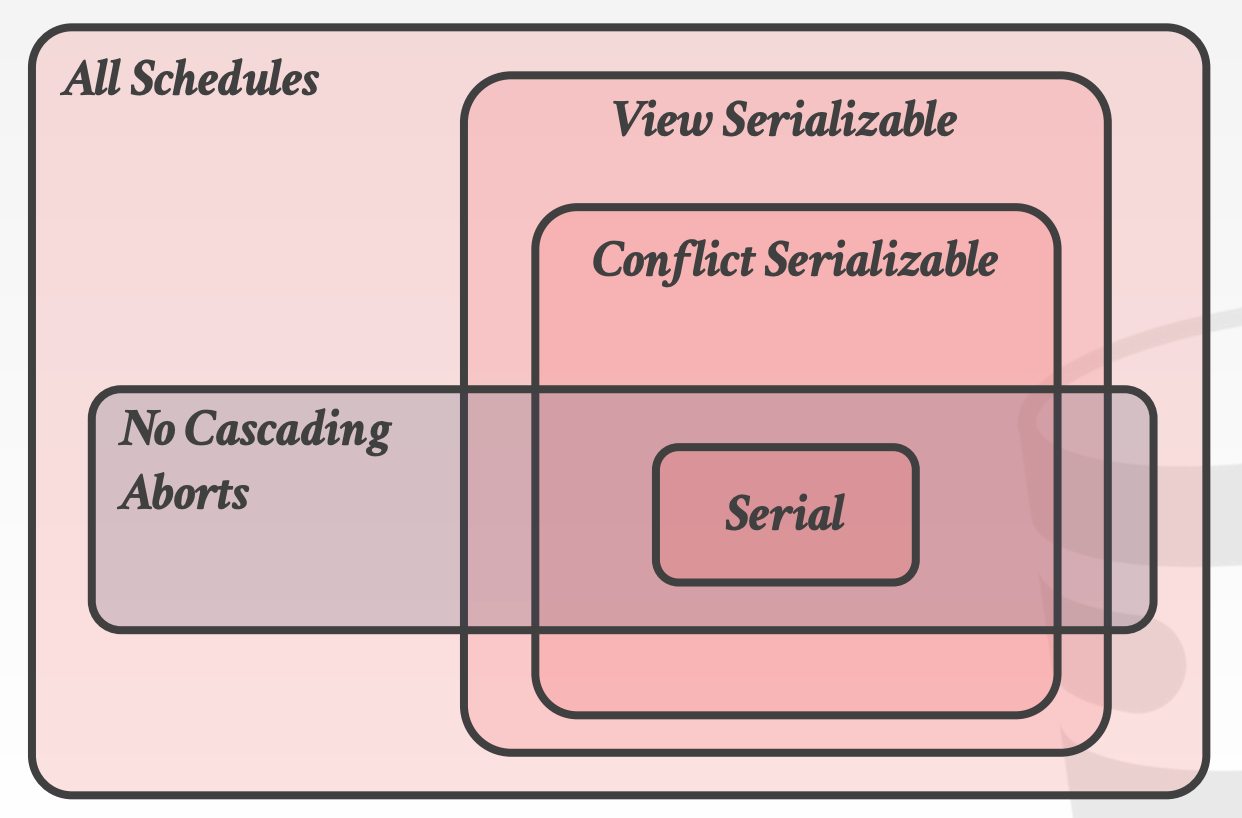
可串行化(Serializability)也存在两种维度:
Conflict Serializability- 大多数
DBMS支持 - 效率高
- 大多数
View Serializability- 大多数
DBMS不支持 - 效率低
- 大多数
16.4.1 Conflict Serializable Schedules
如果两个Schedule是Conflict Equivalent的 ,意味着:
- 它们包含了相同的操作
- 任意两个冲突操作之间的顺序是相同的
如果Schedule S与其中一个Serial Schedule是Conflict Equivalent的,那么我们就称Schedule S是Conflict Serializable
- 我们可以通过交换
Schedule S中相邻的非冲突操作,来将其转换成Serial Schedule - 示意图参考课件中的
51 ~ 60页
当只有两个事务时,交换相邻的非冲突操作还是比较容易的,当事务变多时,这种方法的可行性就变差了。此时我们可以采用另一种算法,叫做优先图(precedence graph),当Schedule S对应的优先图不包含循环时,就称Schedule S是Conflict Serializable
- 示意图参考课件中的
63 ~ 76页
16.4.2 View Serializability
视图可串行化(View Serializability)是可串行化的替代(较弱)概念
如果Schedule S1和Schedule S2满足如下条件,我们就称它们是View Serializability的:
- 在
S1中,T1读取到了初始值A;在S2中,T1读取到的初始值也是A - 在
S1中,T1读取到了由T2写入的值;在S2中,T1读取到的同样是由T2写入的值 - 在
S1中,T1写入的最终值是A;在S2中,T1写入的最终值也是A
示意图参考课件中的78 ~ 84页
16.5 Durability
DBMS需要保证所有提交的事务的改动都要被持久化,所有取消的事务的改动都不会持久化
DBMS可以采用日志或者Shadow Paging来实现这一约束
17 Two Phase Locking
17.1 Lock Types
我们必须在无法得知整体Schedule的情况下,确保所有的Schedule都能正确执行(可串行化)。因此,最直接的解决方式就是加锁
| Locks | Latches | |
|---|---|---|
| Separate | User Transactions | Threads |
| Protect | Database Contents | In-Memory Data Structures |
| During | Entire Transactions | Critical Sections |
| Modes | Shared, Exclusive, Update, Intention | Read, Write |
| Deadlock | Detection & Resolution | Avoidance |
| Avoid Deadlock By | Waits-for, Timeout, Aborts | Coding Discipline |
| Kept In | Lock Manager | Protected Data Structure |
简单来说,Lock Type可以分为如下两种:
S-Lock:共享锁,用于实现共享读X-Lock:独占锁,用于实现排他写
事务的执行过程:
- 事务获取或更新锁,向
Lock Manager发起请求 Lock Manager批准或者阻塞请求- 事务释放锁
Lock Manager维护了一个Lock Table,用于记录事务获取了哪些锁,以及哪些事务阻塞在哪些锁上
示意图参考课件中的14 ~ 18页
17.2 Two Phase Locking
Two-phase locking, 2PL是一种并发控制协议,用于决定当前事务是否可以访问数据库中的某个对象。该协议无需知道事务包含的所有操作
阶段1:Growing- 事务向
Lock Manager请求获取锁 Lock Manager批准或者拒绝请求
- 事务向
阶段2:Shrinking- 事务释放锁(前提是必须成功获取)
- 一旦
Growing阶段完成(或者说进入到Shrinking阶段),在已获取的锁全部释放完之后,不允许再次请求获取锁 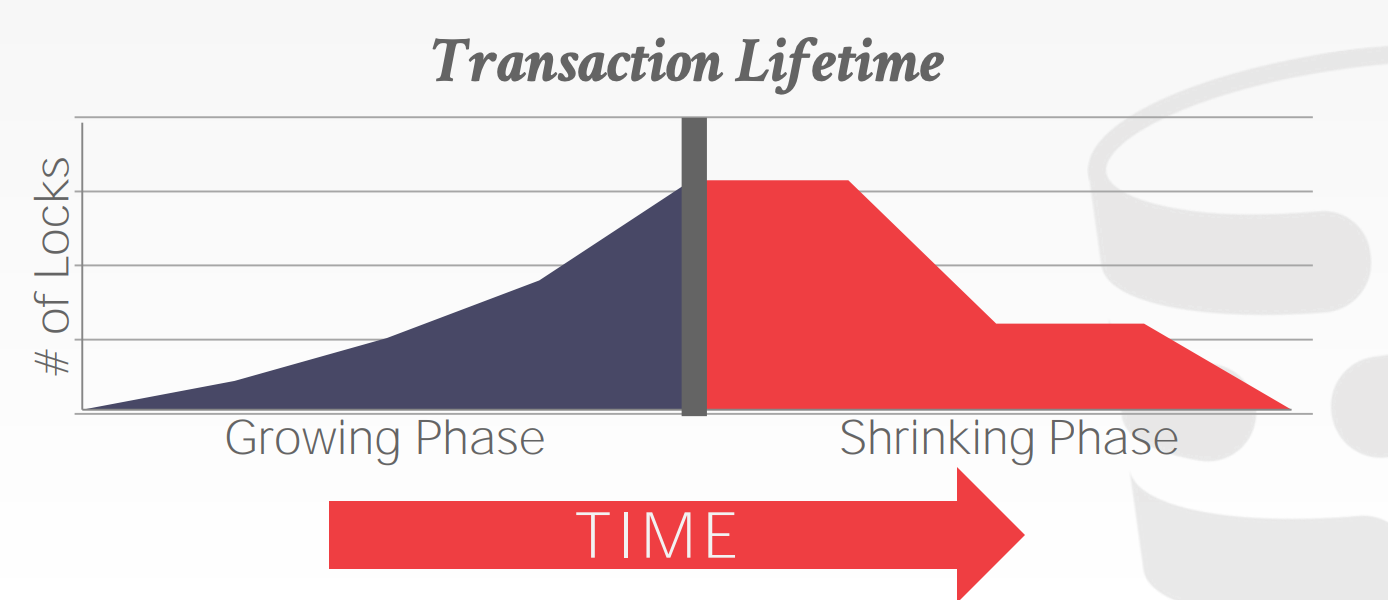
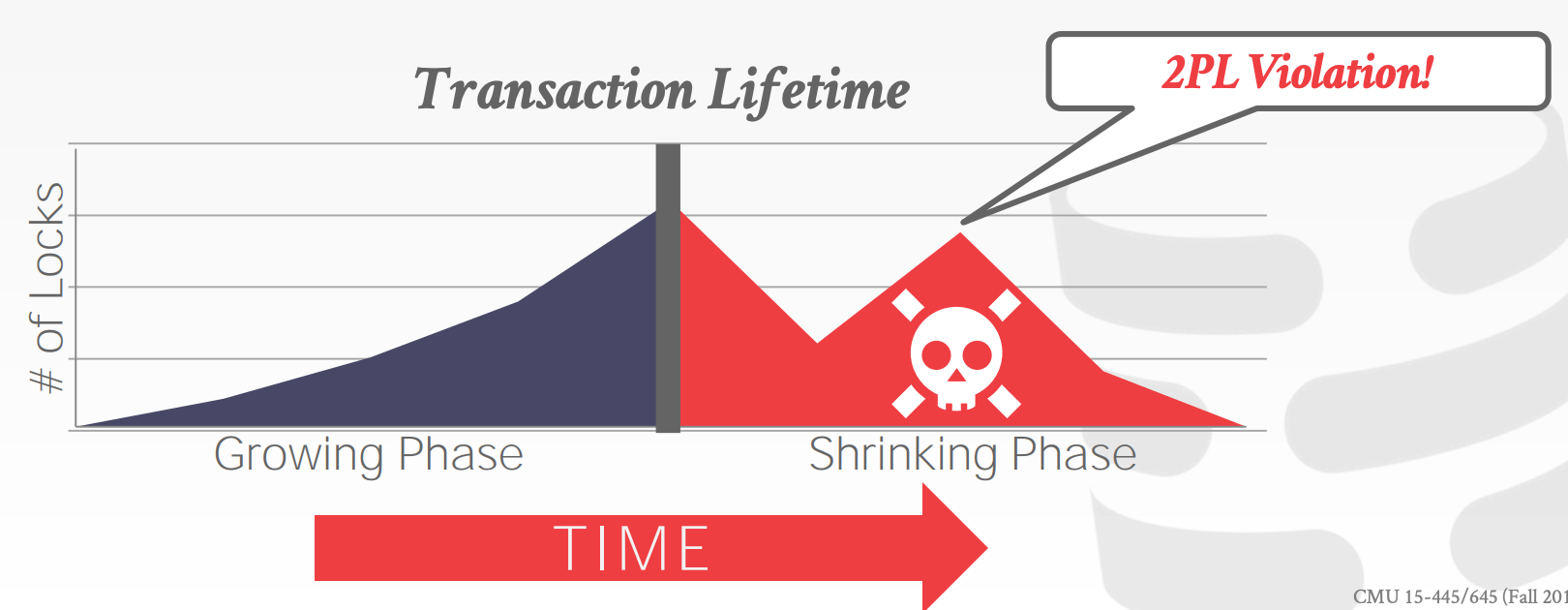
示意图参考课件中的23 ~ 26页
2PL本身能够有效地保证Conflict Serializability,但是它也容易受到Cascading Aborts的影响
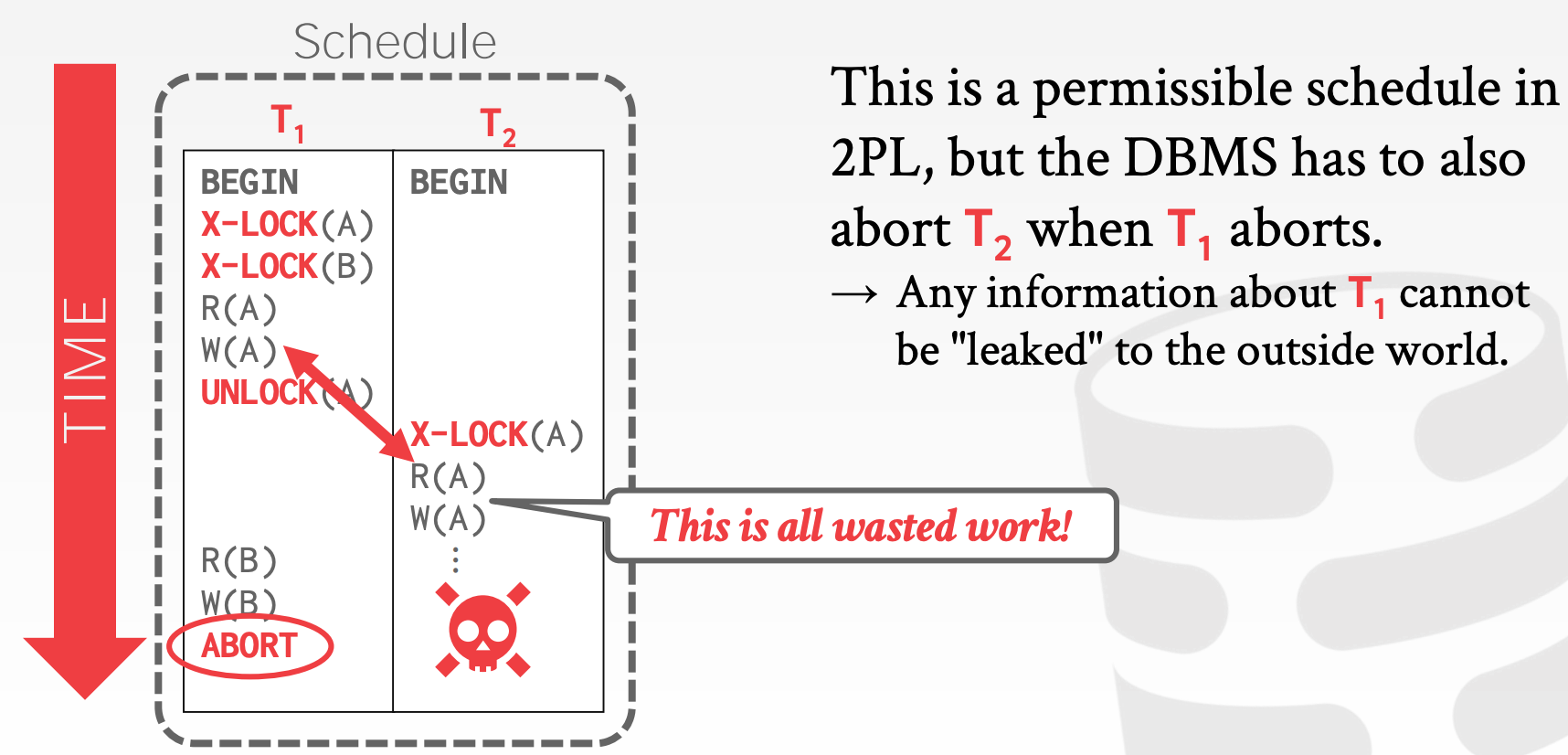
2PL的限制:
2PL会限制并发性,因为部分Schedule不满足2PL的约束- 仍然会出现
Dirty Read,解决方式:Strong Strict 2PL, aka Rigorous 2PL - 仍然会出现死锁,解决方式:检测或预防
Strong Strict 2PL:
阶段1:Growing- 同
2PL
- 同
阶段2:Shrinking- 仅在在事务结束时释放锁

如果Schedule是strict,意味着:当前事务写的值不能被其他事务读取或者重写
- 可以避免
Cascading Aborts Aborts实现简单,只需恢复修改前的值即可
示意图参考课件中的34 ~ 42页
17.3 Deadlock Detection
简单来说,死锁就是存在相互持有锁,并相互等待对方的锁,形成一个环形结构
DBMS会使用Wait-for Graph来跟踪锁的状态
- 每个事务都是图中的一个节点
- $T_i$指向$T_j$的有向线段表示$T_i$在等待$T_j$释放锁
- 周期性的检查图中是否存在环形结构,并试图破坏它
示意图参考课件中的52 ~ 54页
当DBMS发现死锁时,它会选择一个事务(Victim Txn),并让其回滚,以此来破坏环形结构。该事务可能会重新执行或者直接终止,这取决于触发方式
如何选择Victim Txn,需要考虑许多因素,包括:
- 事务存活时间
- 事务执行频率
- 事务已经获取的锁的数量
- 需要回滚的事务数量,以及事务被回滚的次数(避免被饿死)
当选定了需要回滚的事务,回滚的幅度是什么:
- 方案1:整体回滚
- 方案2:部分回滚
17.4 Deadlock Prevention
当一个事务尝试获取的锁被其他事务持有时,DBMS会杀掉其中一个,以此来破坏死锁的状态。该方法不需要依赖Waits-for Graph
那么如何选择该杀掉哪个事务呢?依据的是时间戳,时间戳越早,优先级越高
- 事务被杀掉并重启后,会沿用初始的时间戳,避免被饿死
17.5 Hierarchical Locking
为了尽可能地降低冲突,DBMS通常会将锁的粒度进行进一步细分,包括Attribute、Tuple、Page、Table等。每个事务获取满足要求的最小粒度的锁即可
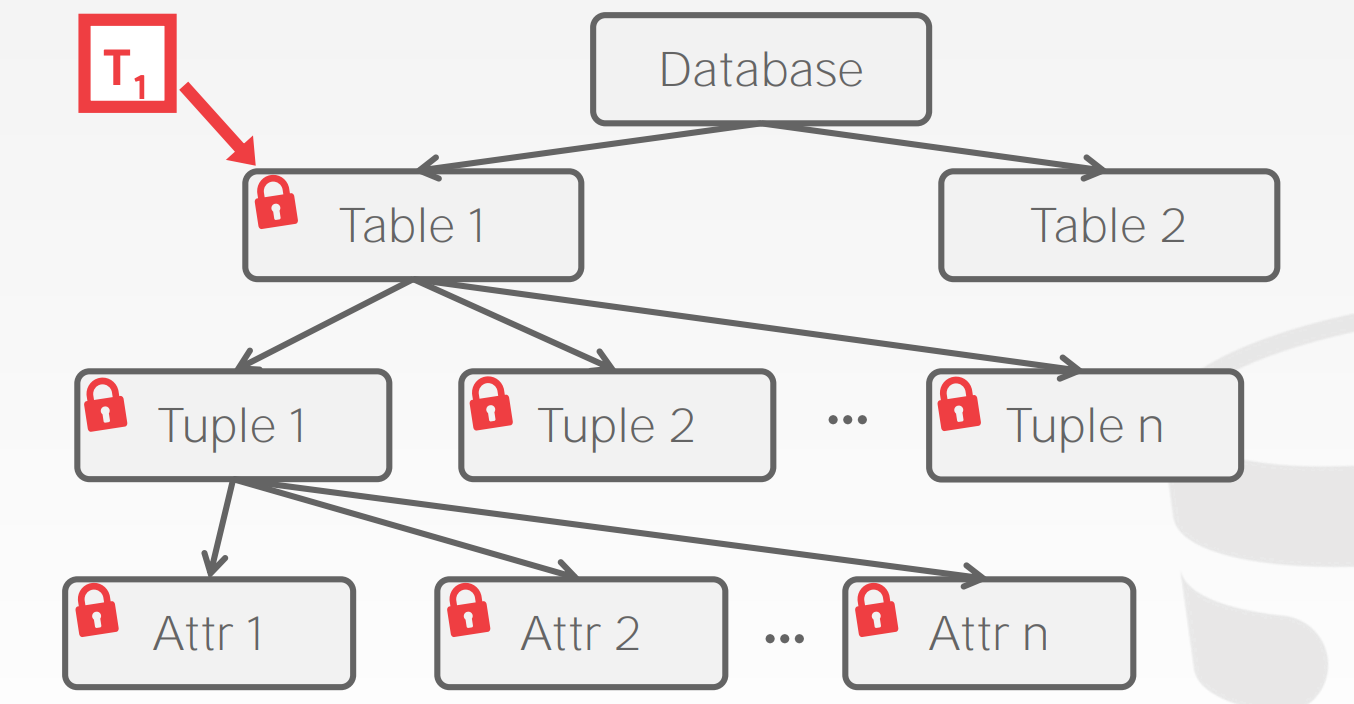
17.5.1 Intention Locks
表锁锁定了整张表,而行锁是锁定表中的某条记录,它们俩锁定的范围有交集,因此表锁和行锁之间是有冲突的。譬如某个表有10000条记录,其中有一条记录加了X锁,如果这个时候系统需要对该表加表锁,为了判断是否能加这个表锁,系统需要遍历表中的所有10000条记录,看看是不是某条记录被加锁,如果有锁,则不允许加表锁,显然这是很低效的一种方法,为了方便检测表锁和行锁的冲突,从而引入了意向锁
意向锁为表级锁,也可分为读意向锁(IS锁)和写意向锁(IX锁)。当事务试图读或写某一条记录时,会先在表上加上意向锁,然后才在要操作的记录上加上读锁或写锁。这样判断表中是否有记录加锁就很简单了,只要看下表上是否有意向锁就行了。意向锁之间是不会产生冲突的,它只会阻塞表级读锁或表级写锁,另外,意向锁也不会和行锁冲突,行锁只会和行锁冲突
加锁策略:
- 若事务
T要获取某节点的S或者IS锁,那么事务必须先获取其父节点的IS锁 - 若事务
T要获取某节点的X、IX或者SIX锁,那么事务必须先获取其父节点的IX锁
各锁之间的冲突关系:
| IS | IX | S | SIX | X | |
|---|---|---|---|---|---|
| IS | ✅ | ✅ | ✅ | ✅ | ❌ |
| IX | ✅ | ✅ | ❌ | ❌ | ❌ |
| S | ✅ | ❌ | ✅ | ❌ | ❌ |
| SIX | ✅ | ❌ | ❌ | ❌ | ❌ |
| X | ❌ | ❌ | ❌ | ❌ | ❌ |
示意图参考课件中的73 ~ 85页
17.5.2 Lock Escalation
当事务获取获取了非常多同一层级的锁时,可能会将锁的粒度升级,转而获取更高层级的锁,以减小锁管理的复杂度(一定程度上牺牲了并发性)
18 Timestamp Ordering
解决并发冲突的另一种方式是,使用时间戳来决定事务执行的顺序
- 时间戳必须是单调递增的
- 如果
TS(Ti) < TS(Tj),那么DBMS会保证执行计划与先执行Ti再执行Tj等价
18.1 Basic Timestamp Ordering Protocol
Basic T/O的具体过程如下:
- 事务读写对象时,不需要加锁
- 每个对象(
X)会记录最近一次成功读写的时间戳,分别记为W-TS(X)和R-TS(X) - 事务执行操作时,若发现对象
X的读写时间比当前事务的时间戳要更大,那么终止并重启当前事务。具体来说- 读
- 若
TS(Ti) < W-TS(X),那么终止并重启事务Ti - 否则
- 允许事务
Ti读取对象X - 将
R-TS(X)更新为max(R-TS(X), TS(Ti) - 备份对象
X,来保证当前事务的repeatable性质
- 允许事务
- 若
- 写
- 若
TS(Ti) < R-TS(X)或TS(Ti) < W-TS(X),那么终止并重启事务Ti - 否则
- 允许事务
Ti跟新对象X,并更新W-TS(X) - 备份对象
X,来保证当前事务的repeatable性质
- 允许事务
- 若
- 读
Thomas Write Rule在Basic T/O协议的基础之上做了调整,差异如下:
- 写
- 若
TS(Ti) < R-TS(X),那么终止并重启事务Ti - 若
TS(Ti) < W-TS(X),那么忽略写操作,并继续事务
- 若
示意图参考课件中的9 ~ 28页
Basic T/O小结:
- 可以生成
Conflict Serializable的计划(前提是不用Thomas Write Rule)- 无死锁,因为根本没有锁
- 允许
Not Recoverable的ScheduleRecoverable:若某个事务Ti读取了某些事务Tj, Tk, Tl ...修改的值,那么该事务Ti在Tj, Tk, Tl ...提交之后再提交,那么就称该Schedule是Recoverable的
- 大事务可能会被饿死(假设大事务会读取很多内容,但是同时系统又通过一些小事务不断更新这些内容)
- 对于那些很少产生冲突,且事务通常较小的系统更友好
18.2 Optimistic Concurrency Control
OCC的主要流程如下:
Read Phase:DBMS会为每个事务创建一个私有的空间- 读取的内容会以副本的形式放到这个空间中
- 修改后的内容也会存在于这个空间中
Validation Phase:当事务提交后,DBMS会比较修改的内容是否与其他事务产生了冲突Write Phase- 若
Validation Phase没有冲突,则会写入全局空间 - 若
Validation Phase有冲突,则终止并重启事务
- 若
示意图参考课件中的38 ~ 50页
OCC的性能:
- 数据拷贝的开销较大
Validation/Write Phase是瓶颈- 频繁终止事务相比于
2PL而言浪费更多资源,因为终止必定发生在事务执行后,而2PL可以在事执行前终止
18.3 Partition-based Timestamp Ordering
将数据库分成多个不相交的子集,子集称为Horizontal Partitions或者Shards。这样一来,冲突校验只需要在各自分区内完成即可
- 每个分区都由一个队列,所有依赖于这个分区的事务会在该队列中排队
- 每个分区都有一把锁,队列中时间戳最小的事务将会获取分区的锁
- 当一个事务获取了所有依赖分区的锁之后,才会开始执行
- 所有的更新在原地发生,因此内存中维护了一个
buffer,用于记录undo日志,以便于事务终止后的回滚(事务执行到一半,改动已经发生,然后断电怎么办?)
Partition-based T/O的性能:
- 在满足以下条件时,
Partition-based T/O性能较好DBMS在事务开始前,就可以知道事务需要读写哪些分区的数据- 大部分事务只访问单个分区的数据
- 多分区事务在执行时会导致部分分区空闲(锁占用着)
18.4 Isolation Levels
到目前为止,我们讨论的事务仅限于读写数据,但是还有其他操作例如插入、删除等,因此还会出现新的问题,比如幻读(The Phantom Problem):
- 为何产生幻读?事务仅对已有数据加锁,而无法阻止新数据的插入
如何解决幻读?使用谓词锁(Predicate Locking)
- 例如对满足
status='lit'的所有记录加锁(包括可能新插入的) - 通常来说,谓词锁的开销非常大
- 索引锁(
Index Locking)是一种特殊的谓词锁,它的开销较小- 或者称为间隙锁(
Gap Locking)、范围锁?
- 或者称为间隙锁(
有索引时,解决幻读问题:
- 对满足
status='lit'这一条件的数据所在的Page加锁 - 若没有满足
status='lit'这一条件的数据,那么需要将这些记录可能会存在的Page加锁
无索引时,解决幻读问题(方法1):
- 锁住表中的所有
Page,避免满足status='lit'这一条件的数据被修改 - 锁住表本身,避免插入或删除数据
无索引时,解决幻读问题(方法2):
- 在提交事务前,重新扫描一遍数据表看结果是否相同(效率太低了)
- 除了
Silo之外,没有其他DBMS使用这个方案
我们可以通过降低一致性来提高DBMS处理事务的并发性能,通常可以分为如下几个等级:
Serializable:加所有的锁Repeatable Reads:加除了索引锁之外的所有锁Read Committed:读加S锁Read Uncommitted:读不加锁
| Dirty Read | Unrepeatable Read | Phantom | |
|---|---|---|---|
| Serializable | No | No | No |
| Repeatable Reads | No | No | Maybe |
| Read Committed | No | Maybe | Maybe |
| Read Uncommitted | Maybe | Maybe | Maybe |
19 Multiversoning
19.1 Multi-version Concurrency Control
Multi-version Concurrency Control, MVCC:DBMS会给逻辑对象维护多个物理版本
- 当事务更新对象时,
DBMS会创建一个新的版本 - 当事务读取对象时,它读取到的是,事务开始时就已经存在的所有版本中,最新的那个版本
- 写操作不会阻塞读操作
- 读操作不会阻塞写操作
示意图参考课件中的6 ~ 22页
19.2 MVCC Design Decisions
MVCC不仅仅只是一个并发控制协议,它深刻影响到DBMS如何管理事务以及Database,包含如下几个方面:
Concurrency Control Protocol,实现方式有如下三种:Timestamp OrderingOptimistic Concurrency ControlTwo-Phase Locking
Version StorageGarbage CollectionIndex Management
19.2.1 Version Storage
Version Storage的特点
- 每个
Logical Tuple都存储这一个指向Version Chain的指针 DBMS通过Version Chain来确定哪些版本对当前事务可见,哪些不可见- 索引包含一个指向
Version Chain的头部的指针
不同的存储方案决定了如何存储同一记录的多个版本,通常来说有如下三种存储方案:
Append-Only Storage- 同一记录的所有版本都存在同一个数据表中,当更新时,在数据表的空闲位置插入一条新的记录
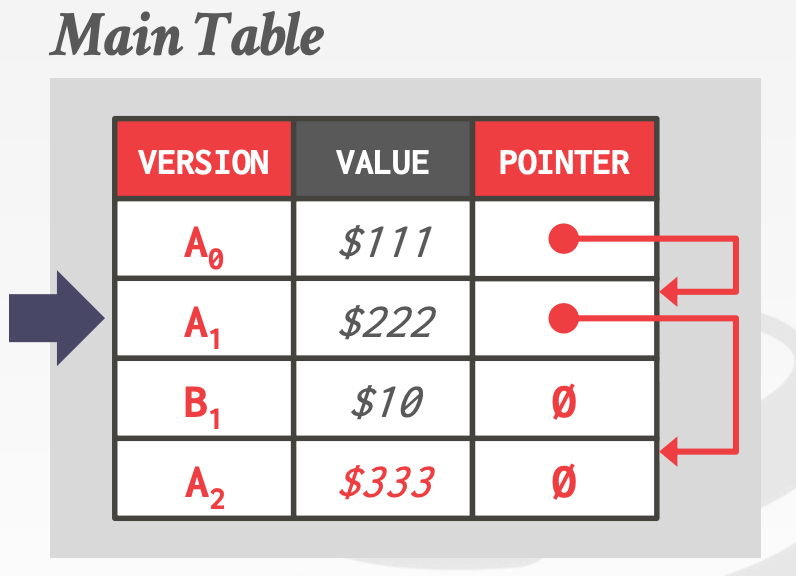
- 此外,
Version Chain是个单链表,链接的方向也有两种Oldest-to-Newest, O2N- 插入开销低,加入到链表尾部即可
- 查找开销高,需要反转链表
Newest-to-Oldest, N2O- 插入开销高,每加入一个新版本,索引就需要更新指针(索引永远指向链表头)
- 查找开销低,无需反转链表
Time-Travel Storage- 维护两个数据表,一个叫做
Main Table,另一个叫做Time-Travel Table - 每次更新时,将
Main Table中的数据拷贝到Time-Travel Table 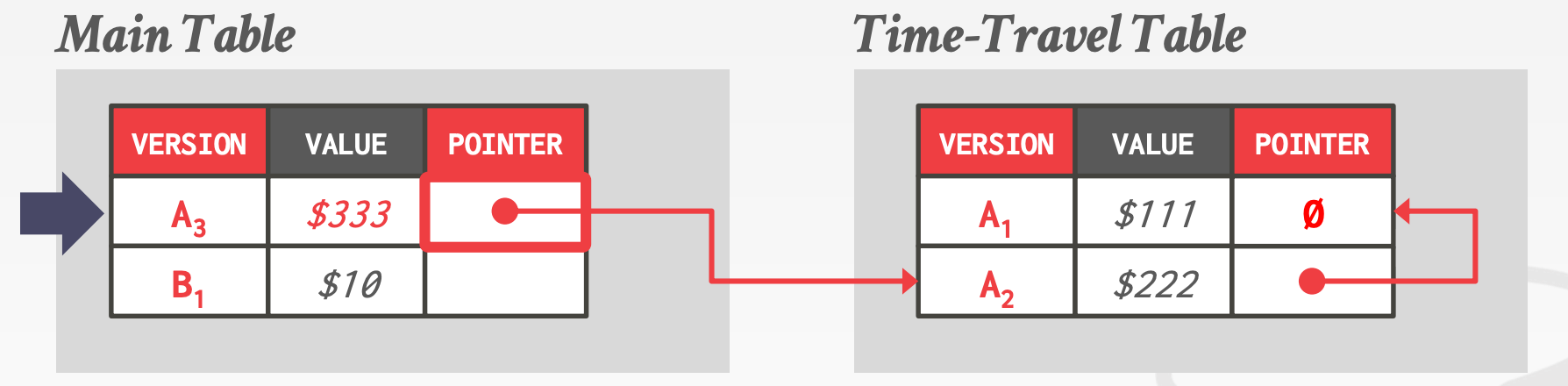
- 维护两个数据表,一个叫做
Delta Storage- 维护两个数据表,一个叫做
Main Table,另一个叫做Delta Storage Segment - 每次更新时,将数值的变化表达式记录到
Delta Storage Segment中 - 可以通过重放
Delta Storage Segment来重建老的版本 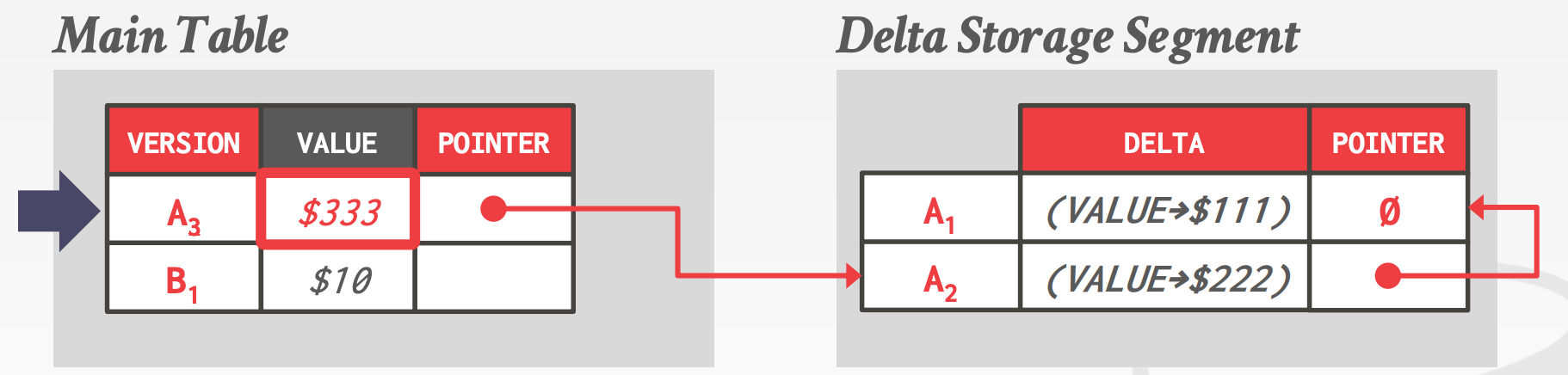
- 维护两个数据表,一个叫做
19.3 Garbage Collection
DBMS需要移除那些失效的物理版本
- 存活的事务中,任何事务都不再会读取这个版本(一定有比该版本新的版本存在)
- 这个版本是由一个已经被终止的事务创建的
这里又引入了两个额外的设计点:
- 如何查找失效版本
- 如何安全的回收内存
Garbage Collection有如下两种实现方式:
Tuple Level:需要通过检查Tuple来查找失效版本Background Vacuuming- 独立的后台线程,周期性地扫描数据表,来查找失效版本
Cooperative Cleaning- 工作线程,在查找可见版本时,如果遇到了失效版本,那就地清理(只能用于
O2N)
- 工作线程,在查找可见版本时,如果遇到了失效版本,那就地清理(只能用于
- 示意图参考课件中的
46 ~ 57页
Transaction-level:每个事务独立记录其读写数据的版本信息,当事务完成后,DBMS将会决定由该事务创建的所有版本何时不可见
19.4 Index Management
对于Primary Key Index
- 存储指向
Version Chain的指针 - 索引是否更新取决于更新时是否创建新的版本
- 数据更新会用先
DELETE再INSERT的方式来实现
对于Secondary indexe,有如下两种实现方式:
Logical Pointers- 每个
Tuple存储一个固定的标识符,存储的是Tuple Id或者是Primary Key - 需要一个额外的间接层
- 每个
Physical Pointers- 存储指向
Version Chain的指针
- 存储指向
示意图参考课件中的61 ~ 66页
19.5 MVCC Deletes
删除存在两个阶段,逻辑删除(Logical Delete)以及物理删除(Physical Delete)
- 删除数据时,首先将该记录标记为逻辑删除
- 标记为逻辑删除后,不能再创建新的版本
- 当且仅当被标记为逻辑删除的记录的所有版本都不可见时,才会执行物理删除
如何表示逻辑删除?有如下两种方式:
Deleted Flag- 在最新的版本后面增加一个标志位,用于表示逻辑删除
Tombstone Tuple- 创建一个空的物理版本来表示逻辑删除
- 用一个独立的
Pool来存储这些Tombstone Tuple,每个Tombstone Tuple只需要1-bit的存储空间
19.6 MVCC Indexs
MVCC Indexs的特点如下:
- 通常不存储元组的版本信息
- 每个索引都需要支持不同的快照
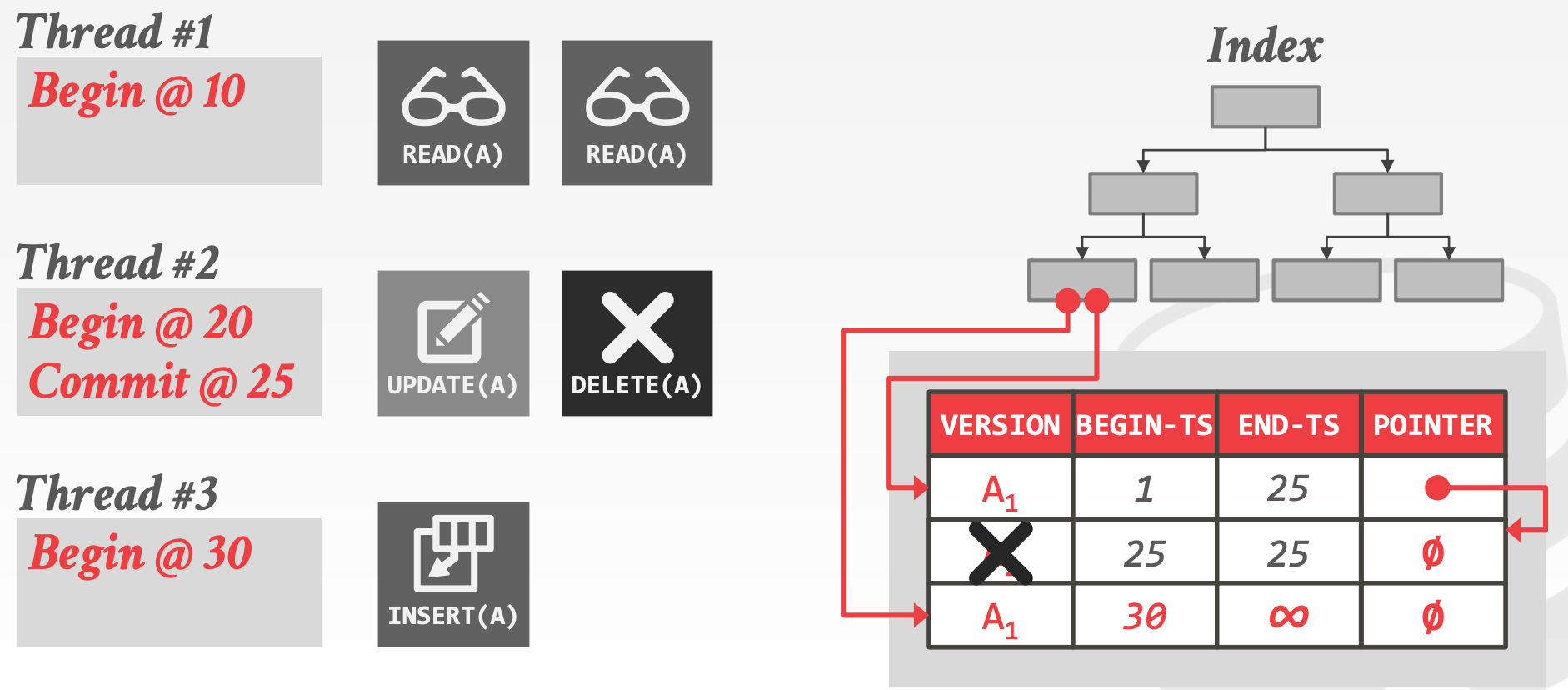
示意图参考课件中的73 ~ 81页
20 Logging
恢复算法(Recovery Algorithms)是保证数据库一致性、事务原子性以及持久性的关键因素。包含两大块内容:
- 在事务正常执行时需要执行的操作,这些操作用于协助
DBMS从错误中恢复(本小节) - 在数据库从错误中进行恢复时需要执行的动作
20.1 Failure Classification
错误可以分为如下几类:
Transaction FailureLogical Errors:逻辑错误,例如违反完整性约束Internal State Errors:内部状态错误,例如死锁
System FailureSoftware Failure:DBMS是实现上的漏洞,例如没有捕获除零异常Hardware Failure:计算机宕机(电源被拔了)
Storage Media Failures:无法恢复Non-Repairable Hardware Failure:硬盘故障
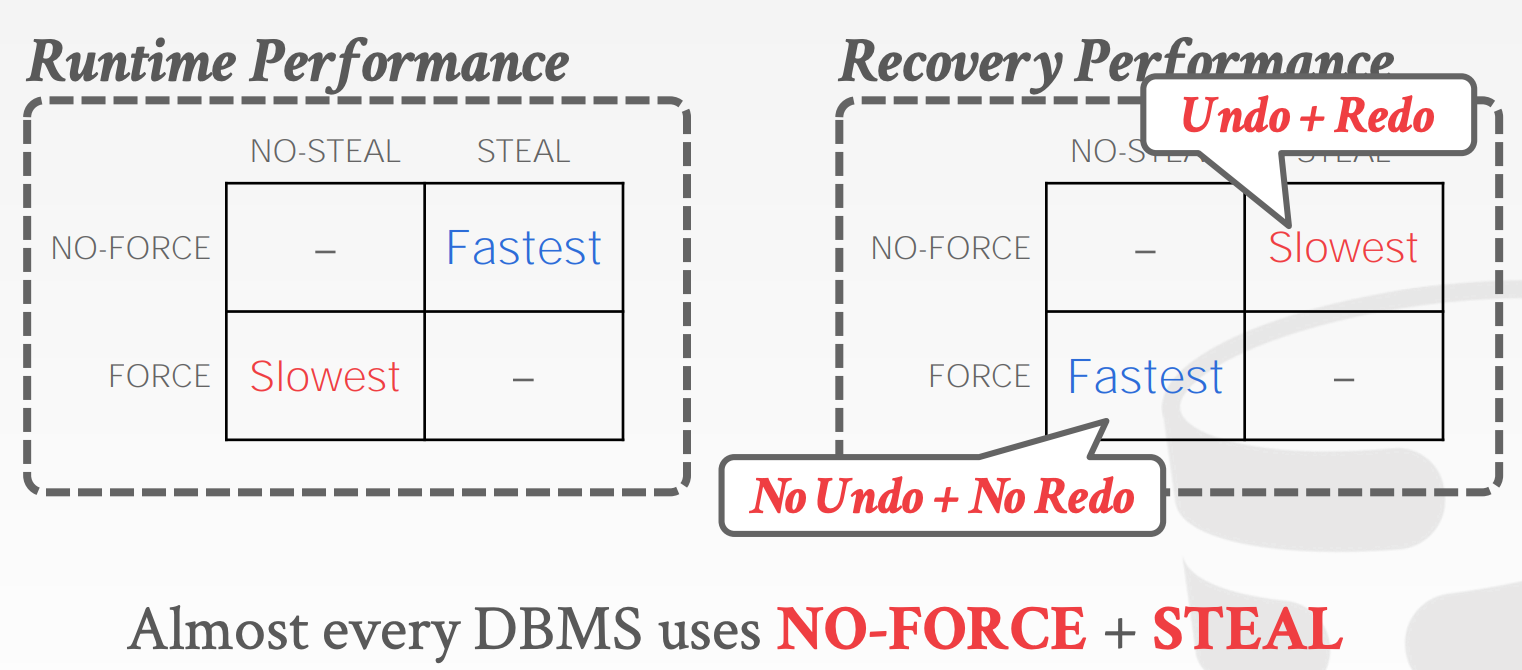
20.2 Buffer Pool Policies
Undo vs. Redo
Undo:用于回滚未正常提交的事务Redo:用于从某个点重放已提交事务的操作,以实现持久性
DBMS如何实现Undo以及Redo取决于其如何管理Buffer Pool
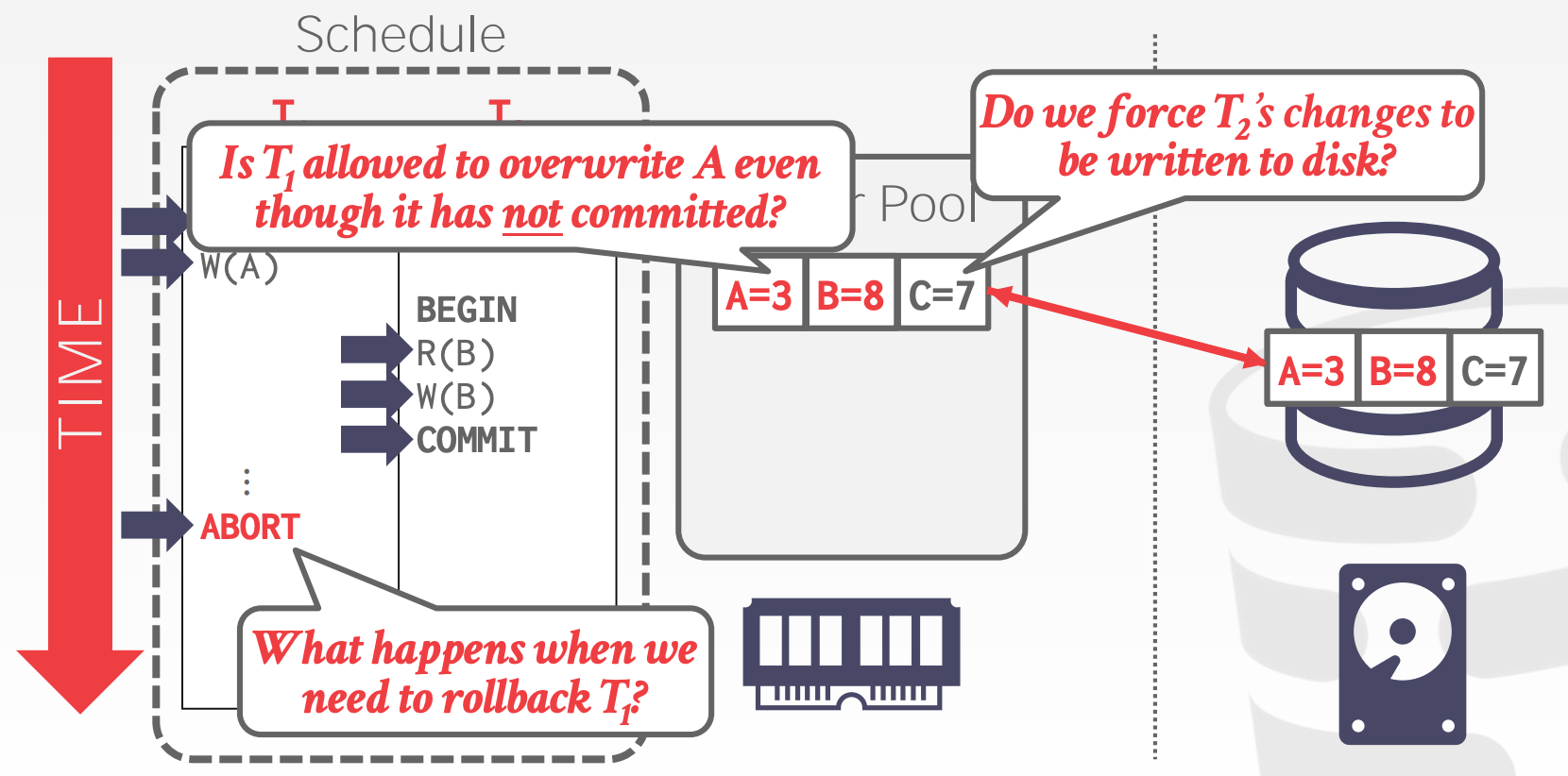
Buffer Pool存在如下几种策略(策略之间可以相互组合):
Steal Policy:Steal是指DBMS是否允许未提交的事务覆盖非易失性存储中对象的最新提交值Force Policy:Force是指DBMS是否要求在事务提交前,该事务所有的变更已经写入到非易失性存储
No-Steal + Force:
- 这种策略组合方式,易于实现
- 无需实现
Undo,因为未提交的事务没有写入到磁盘中 - 无需实现
Redo,因为已提交的事务的数据一定已经写入到磁盘中
- 无需实现
- 无法支持超过物理内存大小的写入集(比如一个大事务,持续写100G数据)
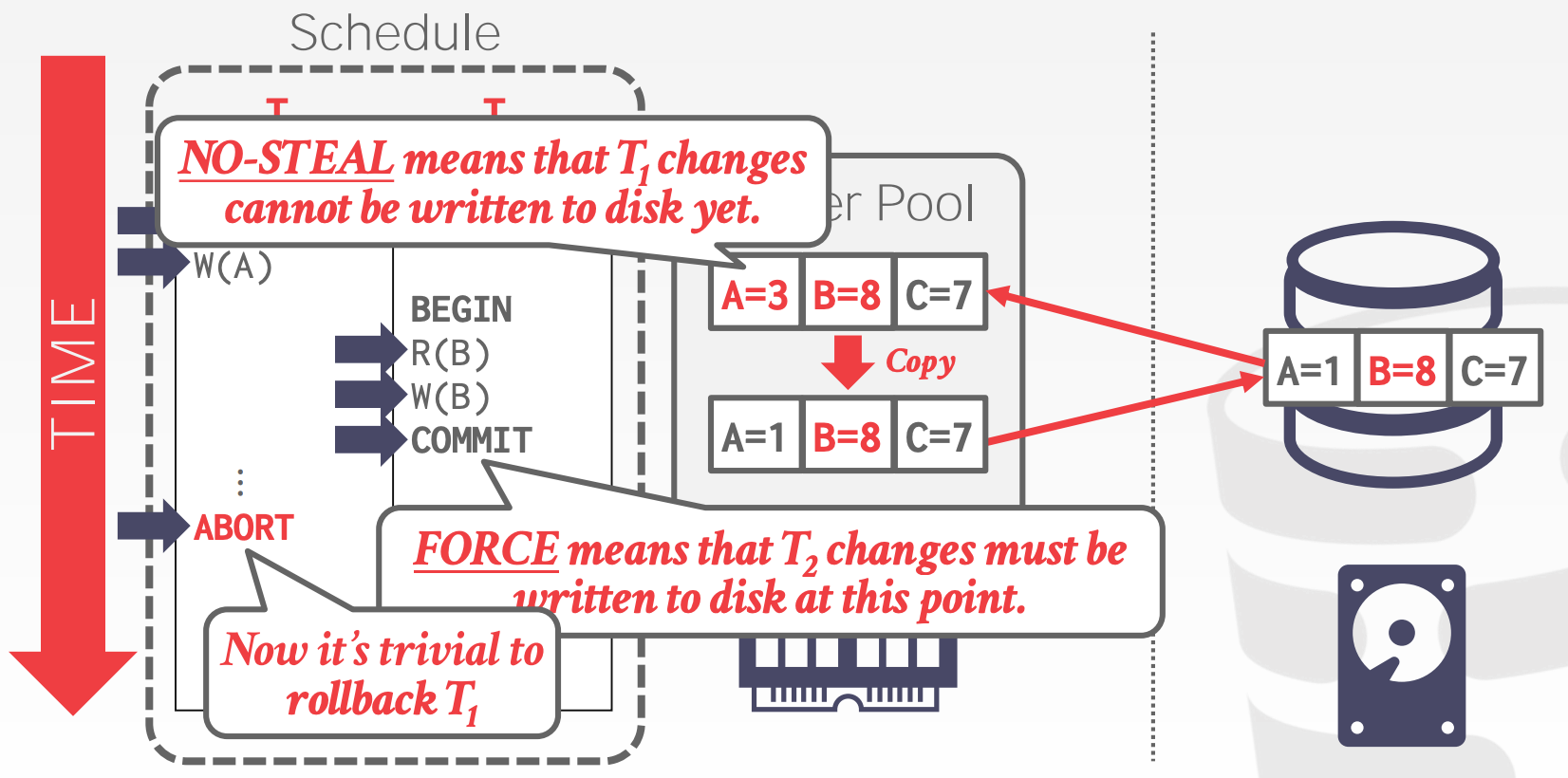
20.3 Shadow Paging
Shadow Paging维护了两份数据:
Master:包含所有已提交事务的变更Shadow:Master的副本,存储所有未提交事务的变更- 当事务提交时,
Shadow替换原有的Master成为新的Master
- 当事务提交时,
示意图参考课件中的21 ~ 23页
Shadow Paging使用的Buffer Pool Policy是No-Steal + Force
Shadow Paging的缺点:
- 拷贝整个
Page Table代价昂贵- 使用
B+ Truee - 无需拷贝整棵树,只需要拷贝涉及到变更的路径集合(从根到叶)
- 使用
- 提交的开销很高
- 刷新每个更新的
Page、Page Table以及Root - 造成数据分区
- 需要垃圾回收
- 同一时间只支持一个事务进行写操作
- 刷新每个更新的
20.4 Write-Ahead Log
维护一个与数据文件独立的日志文件,用于保存事务的变更
- 日志需要存储在非易失性存储上
- 日志需要保存足够多的信息,用于执行
Undo以及Redo动作来进行数据恢复
Write-Ahead Log使用的Buffer Pool Policy是Steal + No-Force
WAL Protocol:
DBMS在内存中存储事务的日志- 在
Data Page本身被覆盖到非易失性存储之前,与更新页面有关的所有日志记录都被写入非易失性存储 - 在事务的所有日志被写入到非易失性存储之前,事务不能提交
BEGIN和COMMIT需要记录日志- 日志至少包含如下内容
Transaction Id:事务idObject Id:对象idBefore Value:旧值,用于UndoAfter Value:新值,用于Redo
WAL-Implementation需要考虑的设计点:
DBMS何时将日志写入磁盘- 事务提交时
- 可以使用组提交将多个日志刷新批处理在一起以分摊开销
DBMS何时将未提交的脏数据写入磁盘- 每次事务更新数据时
- 事务提交时
20.5 Logging Schemes
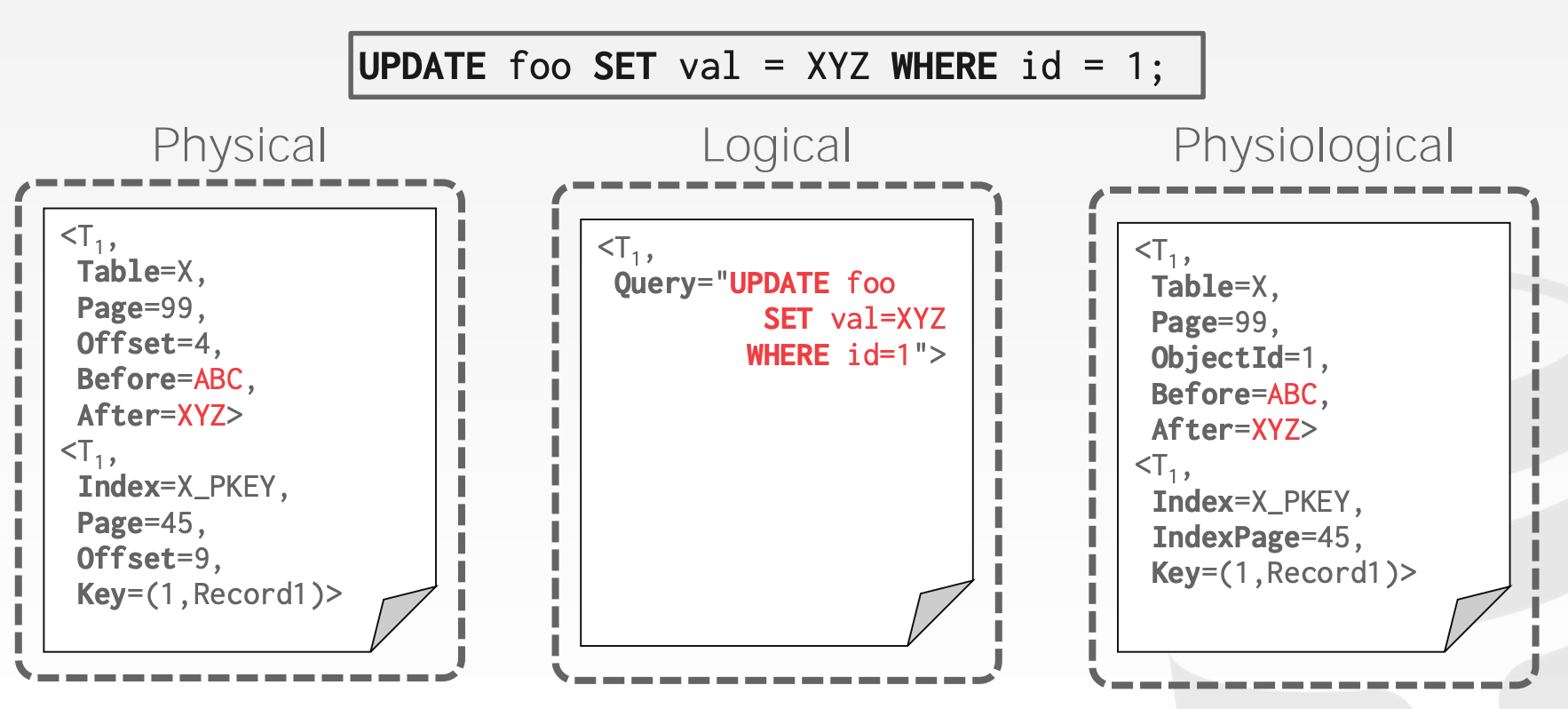
Physical Logging:记录的是数据本身
- 记录数据量大
- 恢复时间短
Logical Logging:记录的是造成数据变化的操作
- 记录数据量小
- 恢复时间长,因为需要重放操作来重建数据
- 实现复杂,特别是并发场景下的数据恢复
- 很难确定数据库的哪些部分在崩溃之前可能已被查询修改
Physiological Logging:
Physical Logging以及Logical Logging的结合- 日志记录针对单个页面但不指定页面的数据组织
- 这是最常用的策略
20.6 Checkpoints
WAL会随着时间不断膨胀。当从异常汇总进行恢复时,重放的时间会非常久。因此DBMS会周期性地构建Checkpoint,其流程如下:
- 将当前驻留在主内存中的所有日志记录输出到稳定存储
- 将所有修改的块输出到磁盘
- 将
Checkpoint条目写入日志并刷新到稳定存储
Checkpoints面临的挑战:
- 当进行
Checkpoint时,需要阻塞所有的事务,来获取一个满足一致性的快照 - 通过扫描日志来查询所有未提交的事务,会花费很长时间
- 每过多久进行一次
Checkpoint目前没有定论
21 Recovery
恢复算法(Recovery Algorithms)是保证数据库一致性、事务原子性以及持久性的关键因素。包含两大块内容:
- 在事务正常执行时需要执行的操作,这些操作用于协助
DBMS从错误中恢复 - 在数据库从错误中进行恢复时需要执行的动作(本小节)
21.1 Aries
Aries是一种利用语义来进行恢复和隔离的算法,其主要思想如下:
Write-Ahead Logging- 任何变更都是先写日志再写数据
- 必须使用
Steal + No-Force的策略
Repeating History During Redo- 重启时,通过
Redo来将数据库恢复到崩溃前的状态
- 重启时,通过
Logging Changes During Undo- 将撤消操作记录到日志中,以确保在重复失败的情况下不会重复操作
21.2 Log Sequence Numbers
每条日志都包含了一个全局唯一的Log Sequence Number, LSN,并且系统中的其他组件都会使用到LSN
| Name | Where | Definition |
|---|---|---|
flushedLSN |
Memory |
最近一次写入磁盘的日志的LSN |
pageLSN |
Pagex |
Pagex中最近一次的更新日志 |
recLSN |
Pagex |
第一条未刷写入磁盘的日志 |
lastLSN |
Ti |
事务Ti的最近一条日志 |
MasterRecord |
Disk |
最近一次CheckPoint的日志 |
- 在
Pagex允许被写入磁盘前,我们必须保证flushedLSN >= pageLSN(x) - 每当事务更新某个
Page中的记录时,就需要更新该Page的pageLSN DBMS将WAL Buffer刷写入磁盘后,需要更新flushedLSN
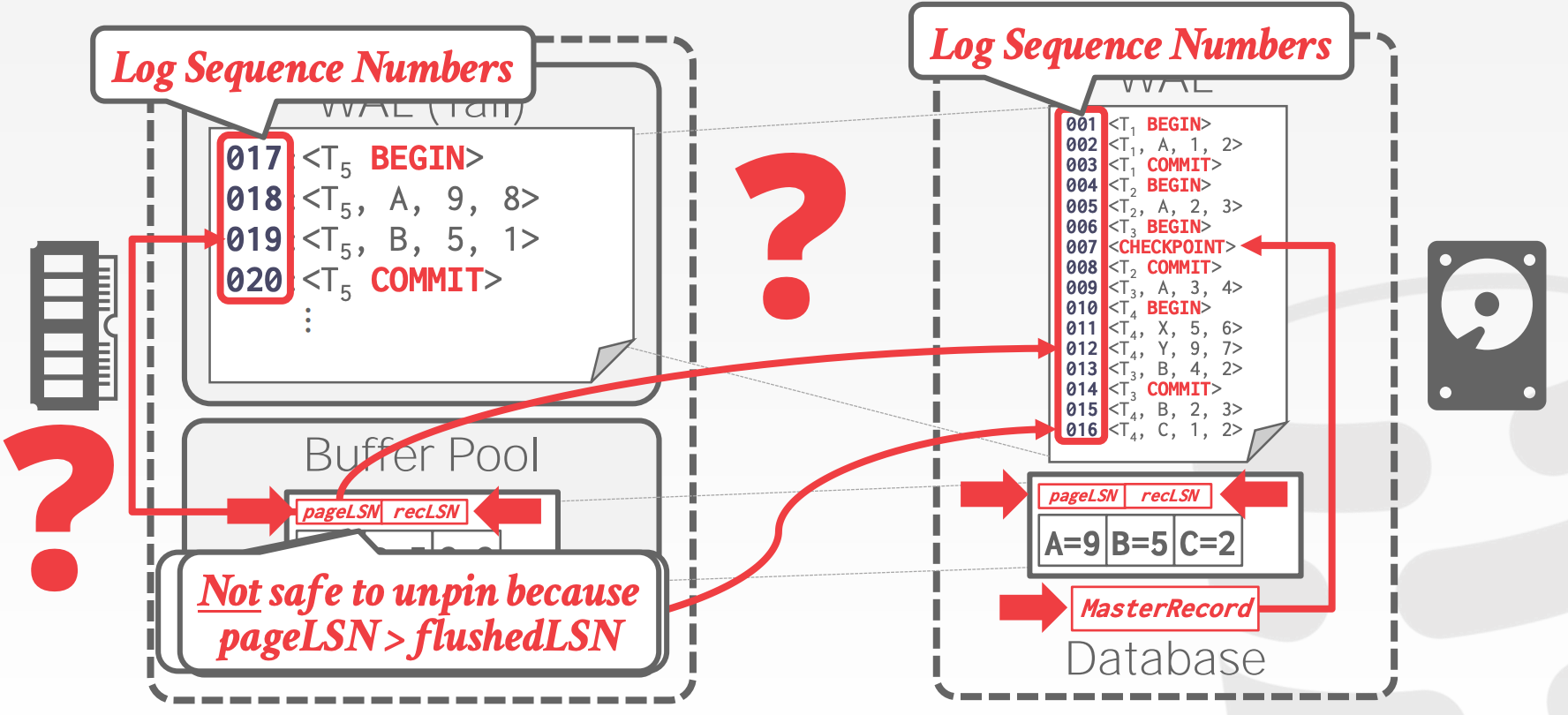
21.3 Normal Commit & Abort Operations
本小节的讨论基于以下前提:
- 所有日志的大小总和小于一个
Page - 写磁盘是原子的
- 使用
Strict 2PL的加锁策略 - 使用
Steal + No-Force的缓存策略
事务正常提交的流程:
- 增加一条
COMMIT日志 - 将当前事务中,所有
LSN小于Commit LSN的日志刷入磁盘- 日志的写入是批量的、顺序的
- 增加一条
TXN-END日志- 这个日志不需要立刻写入磁盘
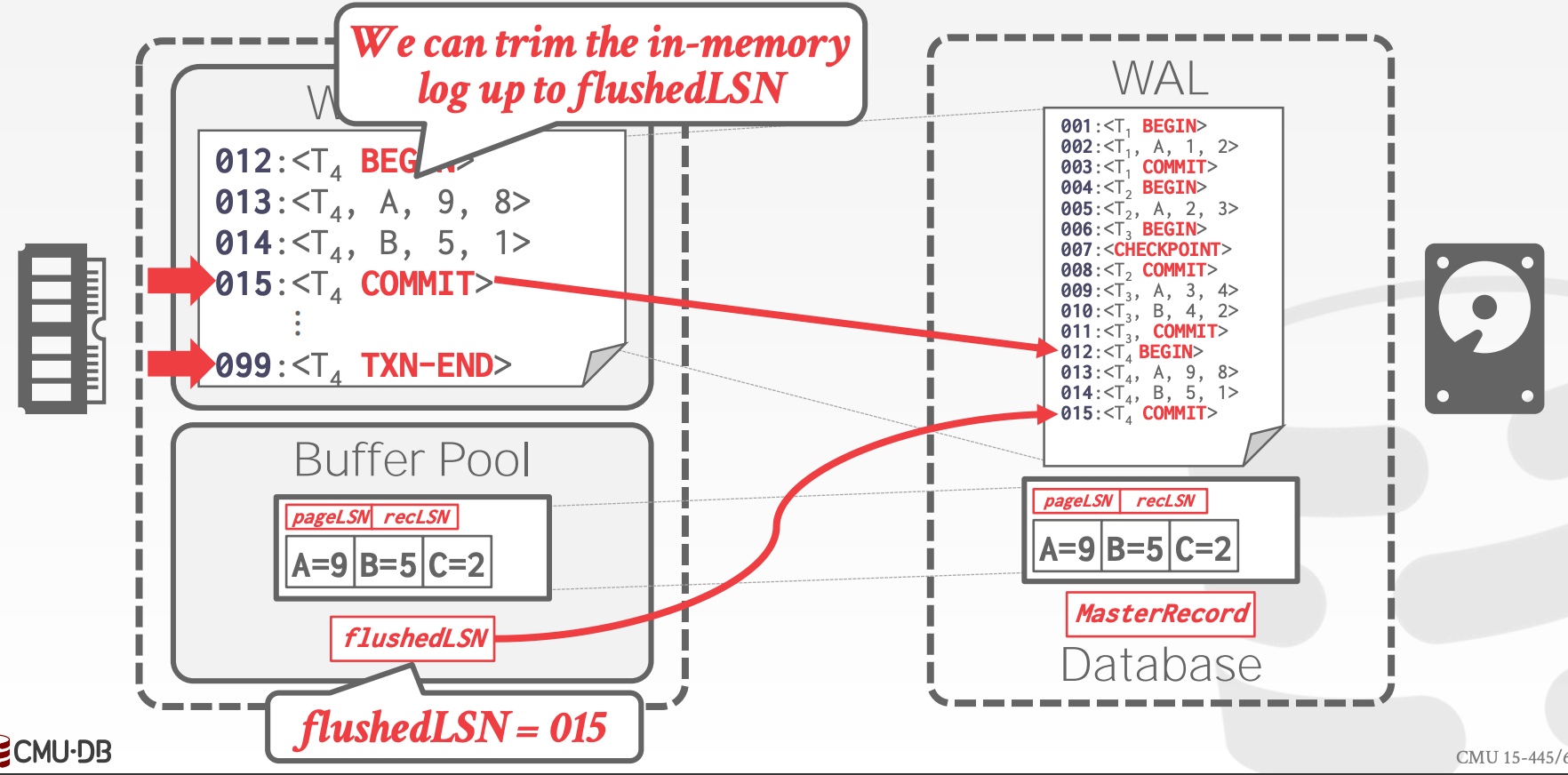
为了实现事务的异常终止,需要对日志进行调整:
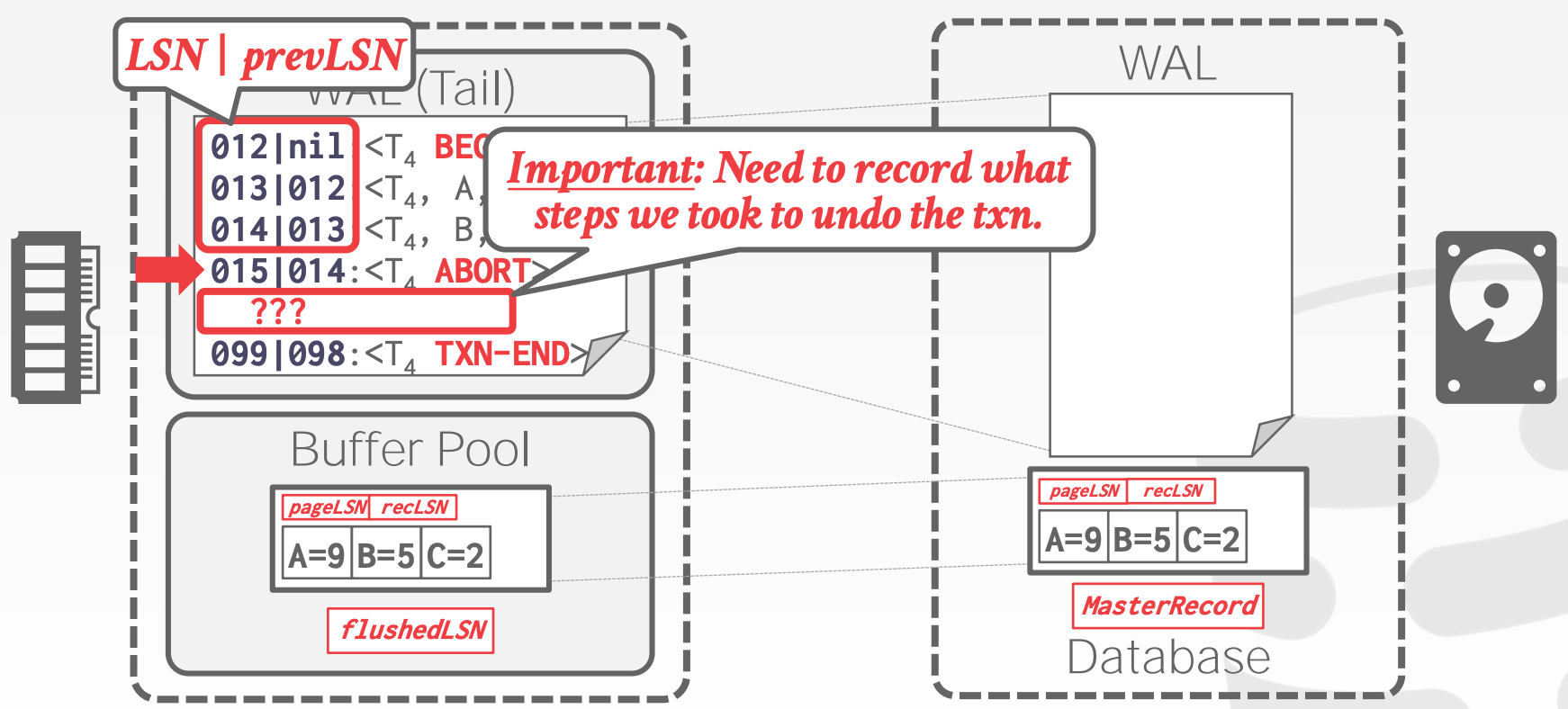
- 需要在日志记录中额外增加一个字段
prevLSN,方便从后往前遍历 - 需要在日志中记录
CLR, Compensation Log RecordsCLR记录的是回滚需要执行的动作CLR记录额外包含了undoNext字段,该字段存储了下一个需要被Undo的日志
- 示意图参考课件中的
17 ~ 19页
事务异常终止:
- 增加一条
ABORT日志 - 从后往前遍历当前事务的所有日志,对于每条
Update日志- 增加一条
CLR日志 - 恢复原始值
CLR日志和包含恢复数据的Page,其写入磁盘的顺序是?
- 增加一条
- 增加一条
TXN-END日志
- 注意,
CLR本身不需要Undo
21.4 Fuzzy Checkpointing
Non-Fuzzy Checkpoints:DBMS在进行Checkpoint的时候,会停止所有事务的操作,以此来得到一个一致性的快照(这种方式显然是低效的)
- 阻塞新事务的启动
- 等待所有活跃事务结束
- 将脏页刷新到磁盘
Slightly Better Checkpoints:
DMBS在进行Checkpoint的时候,停止更新事务- 阻止查询获取
Table/Index Page的Write Latch - 不需要等待所有事务结束
- 阻止查询获取
- 必须记录额外的状态,包括
Active Transaction Table, ATT- 每个事务对应一条记录,包括如下字段:
txnId:事务idstatus:事务的状态,所有可能的状态如下:R, RunningC, CommittingU, Candidate for Undo
lastLSN:最新的日志的LSN
- 事务结束(提交或终止)后,该记录被移除
- 每个事务对应一条记录,包括如下字段:
Dirty Page Table, DPT- 用于记录哪些
Page中包含未提交事务的变更 Buffer Pool中的每个Page对应一条记录,包括如下字段:recLSN:第一条未刷写入磁盘的日志的LSN
- 用于记录哪些
Fuzzy Checkpoints:
DMBS在进行Checkpoint的时候,允许事务继续执行- 需要引入额外的日志来描述
Checkpoint的边界CHECKPOINT-BEGINCHECKPOINT-END:包含ATT和DPT
- 当
Checkpoint成功执行后,CHECKPOINT-BEGIN日志将会被写入到MasterRecord中 - 所有在
CHECKPOINT-BEGIN之后开始的事务被记录在CHECKPOINT-END日志的DTP中 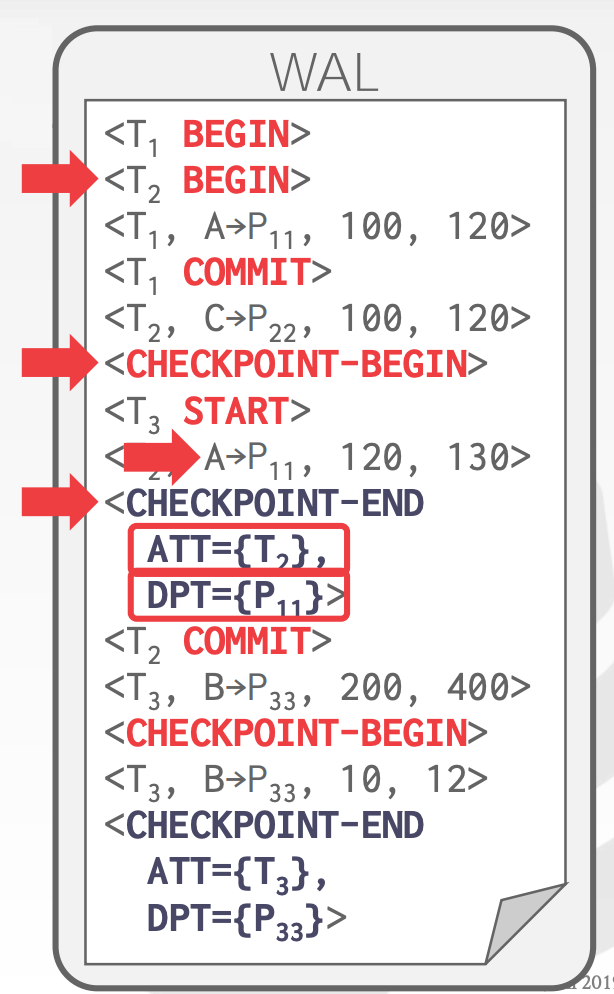
21.5 Recovery Algorithm
Aries Recovery算法包含如下步骤:
Analysis:读取从上一个Checkpoint之后的所有WAL来获取崩溃时的脏页以及活跃事务信息- 从上一个成功的
Checkpoint开始往后遍历日志- 如果找到了
TXN-END日志,那么将其从ATT中移除 - 否则,将其放入
ATT中,并设置状态UNDO- 若找到
COMMIT日志,则将状态修改为COMMIT
- 若找到
- 对于
UPDATE日志- 如果
Page p不在DPT中,那么将Page p加入到DPT中,并设置recLSN=LSN - 如果
Page p在DPT中,无操作
- 如果
- 如果找到了
- 遍历结束后
ATT包含了崩溃时的所有活跃事务DTP包含了崩溃时所有脏页
- 从上一个成功的
Redo:重放所有操作(包括提交和终止的事务),以及CLRs- 从
DTP中最小的recLSN开始,往后遍历日志- 对于每个
Update日志或者CLR,递归执行Redo操作,直至:- 相关的
Page不在DPT中 - 或者,相关的
Page在DPT中,但是日志的LSN小于Page的recLSN
- 相关的
Redo操作如下:- 重放日志记录的动作
- 将
pageLSN作为日志的LSN - 无新增的日志,不需要刷新磁盘
- 对于每个
- 遍历结束后,对所有状态是
COMMIT的事务,增加一条TXN-END日志,并将其从ATT中移除
- 从
Undo:回滚未提交的事务的操作- 其操作的对象是,
ATT中所有状态是UNDO的事务 - 从
lastLSN开始,往前遍历日志- 对于每个修改,增加一条
CLR日志
- 对于每个修改,增加一条
- 其操作的对象是,
- 示意图参考课件中的
38 ~ 40页
恢复时发生崩溃:
- 如果在
Analysis阶段崩溃了,那么重新开始恢复即可,无其他额外操作 - 如果在
Redo阶段崩溃了,那么重新开始恢复即可,无其他额外操作 - 如果在
Undo阶段崩溃了,由于每次执行Undo操作会记录CLR日志,因此只需要执行那些没有CLR日志的操作
22 Distributed
22.1 System Architectures
DMBS的系统架构明确了,哪些共享资源是CPU可以直接访问的。这决定了CPU如何与其他CPU协作,以及如何存储和获取对象
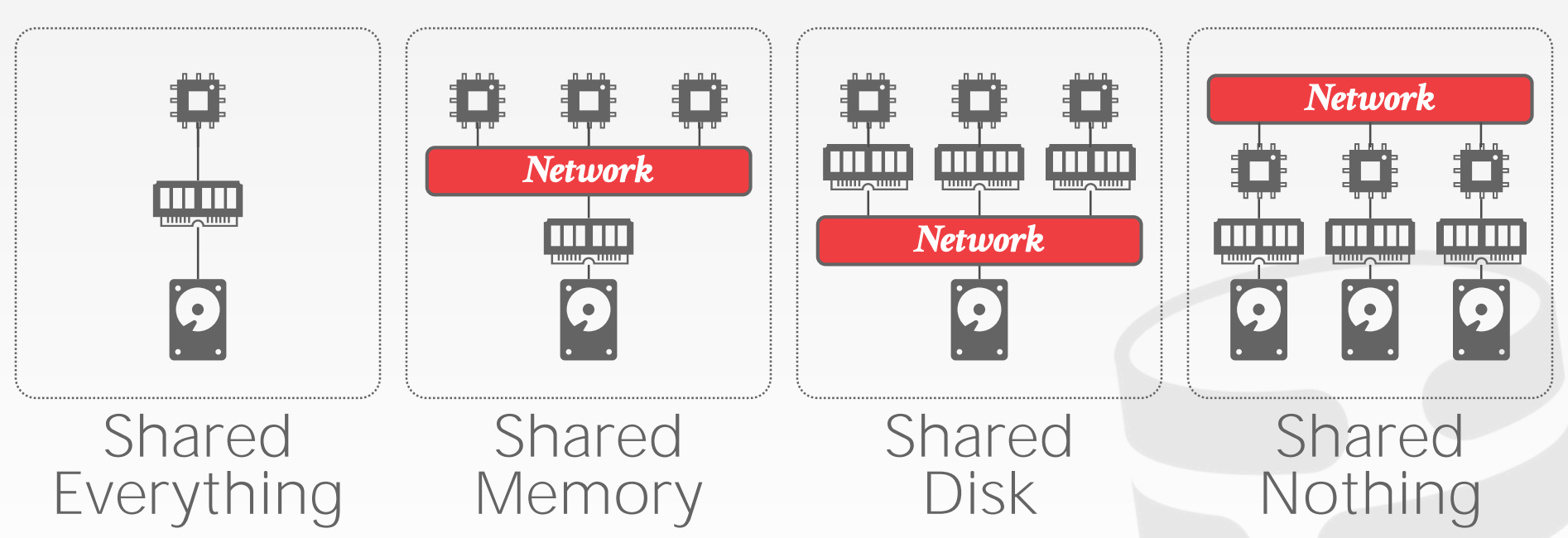
- 注意,图中标注的
Network,在不同架构下,其通信方式是不同的
Shared Memory:单进程多线程?
- 多个
CPU共享一个内存空间 CPU之间可以通过内存直接通信
Shared Disk:单机多进程,或者多机共享存储?
- 每个
CPU独享一个内存空间 - 多个
CPU共享一块逻辑磁盘 - 执行层和存储层可以各自扩缩容
CPU之间需要通过消息来进行沟通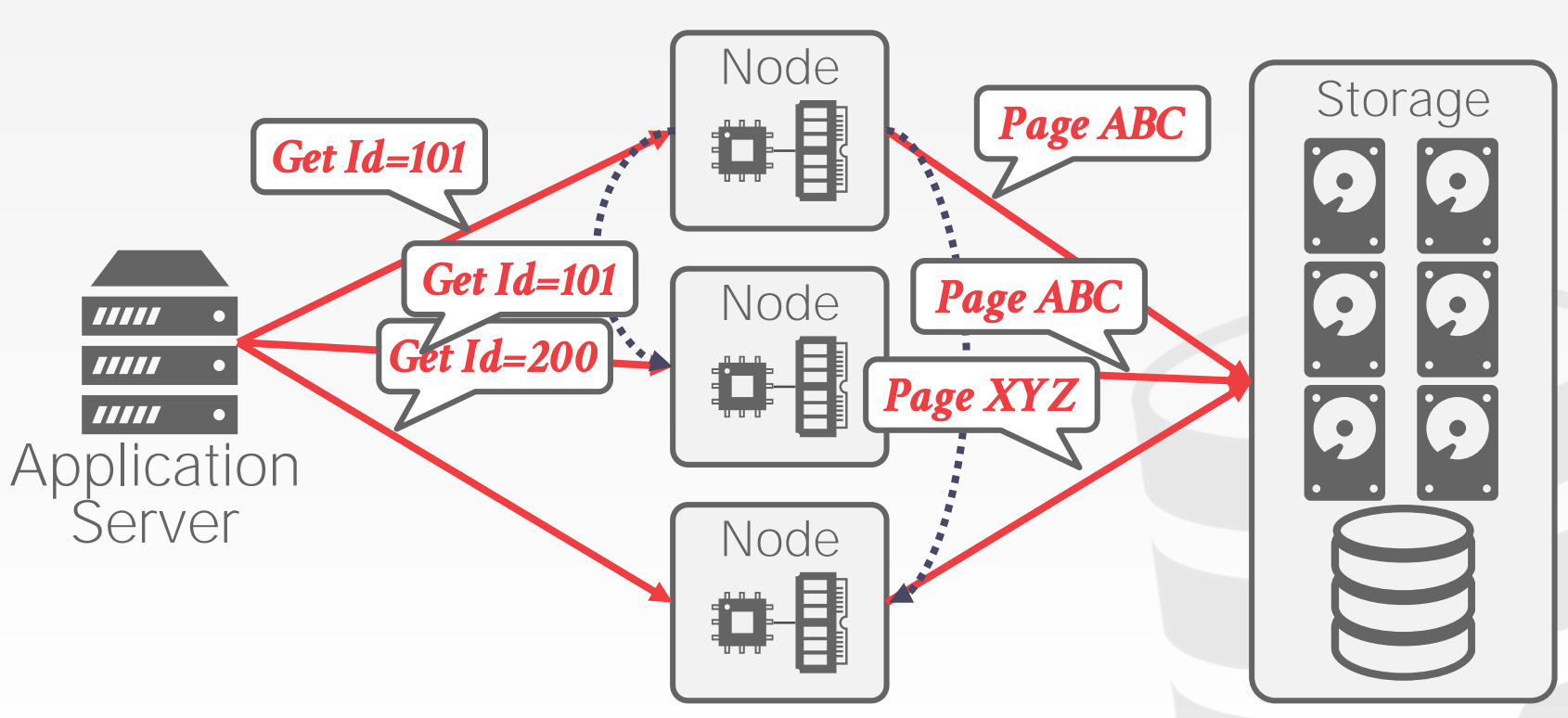
Shared Nothing:多副本,主从模式?
- 每个实例独享
CPU、内存、磁盘 - 各个实例只能通过网络通信
- 难以提升容量(每个机器都包含全量数据)
- 难以保证一致性(如果多台机器同时更新数据的话,就会很复杂,需要一致性协议来保证)
- 更好的性能和效率
22.2 Design Issues
设计需要考虑的问题:
- 应用如何查询数据
- 如何在分布的节点上执行查询计划
- 如何保证正确性
Homogenous vs. Heterogenous
Homogenous Nodes- 集群中每个节点都可以执行相同的任务(同一套代码)
- 配置和故障恢复更简单
Heterogenous Nodes- 集群中每个节点执行不同的任务(大概率是多套代码)
Data Transparency:
- 不应该要求用户感知数据存放在哪里,以及数据是如何存储、如何分区、副本数量
- 在单机
DBMS上能够正常执行的查询也应该在分布式的DBMS中正常获取结果
22.3 Partitioning Schemes
22.3.1 Naive Table Partitioning
Naive Table Partitioning是指每个节点存储部分数据表,每个数据表包含了完整的内容
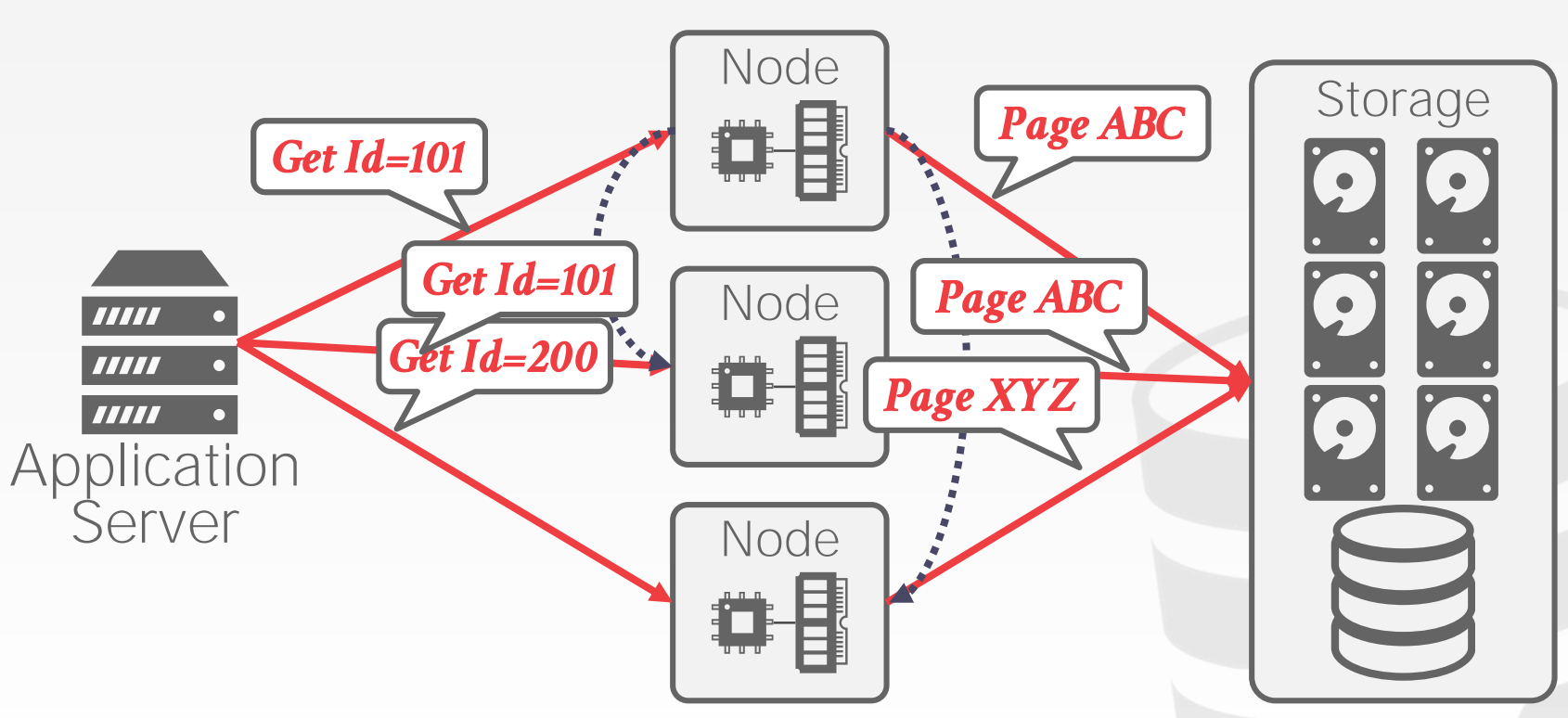
22.3.2 Horizontal Partitioning
Horizontal Partitioning是指将每个数据表水平拆分成多个部分,分别放置到不同的节点上
常见的拆分手段包括:
Hash Partitioning:会用到一致性HashRage Partitioning
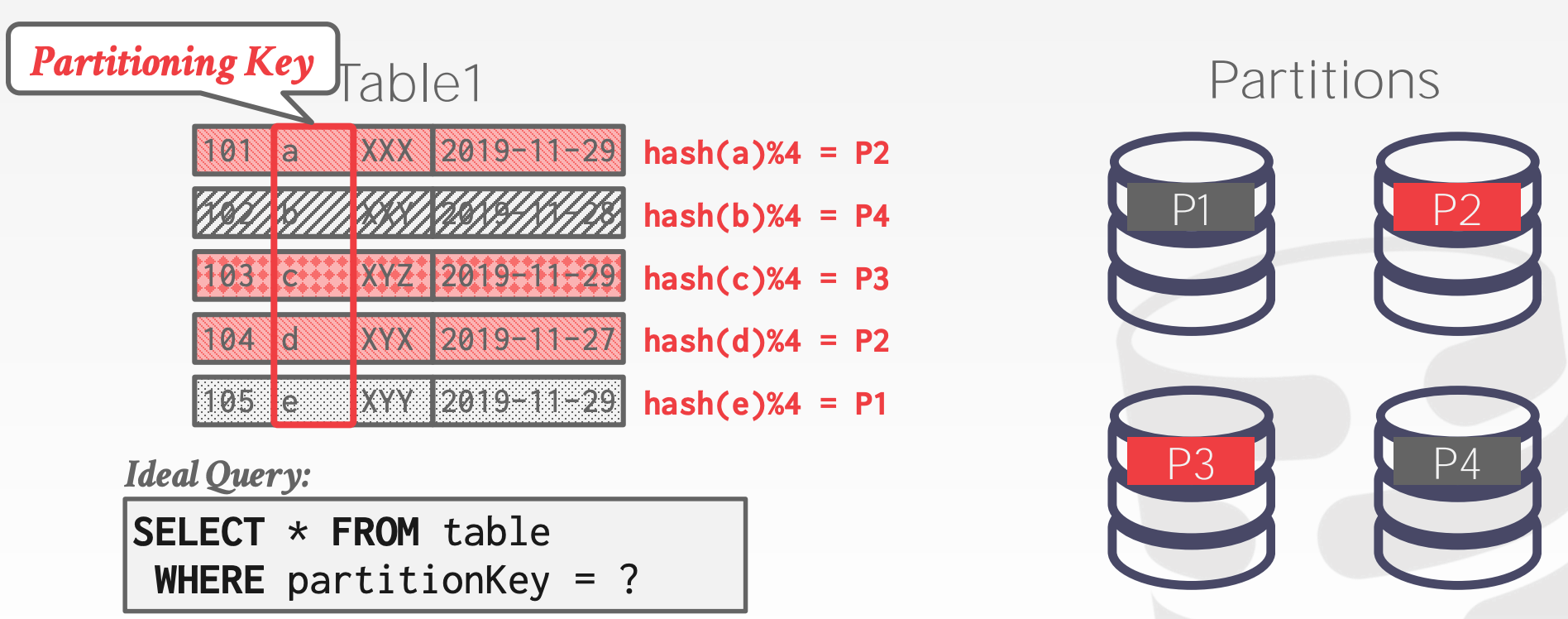
22.4 Transaction Coordination
Single Node Transaction只会访问本地分区中的数据
Distributed Transaction会访问不同机器上的多个分区中的数据,需要额外的通信,通信方式主要有以下两种:
Centralized:中心化的Decentralized:非中心化的
22.5 Distributed Concurrency Control
为了允许在不同节点上同时执行多个事务,许多工作在单节点上的事务并发控制协议可以应用在分布式的场景中,但同时,这是极具挑战的:
- 副本
- 网络开销
- 节点异常
- 时钟偏差
23 Distributed OLTP
23.1 Atomic Commit Protocols
当一个分布式的事务完成时,DBMS需要询问事务相关的所有节点是否可以提交
可以用于支持分布式事务的协议包括:
Two-Phase Commit- 示意图参考课件中的
12 ~ 30页 - 优化手段:
Prepare Voting:如果Coordinator知道某个节点是最后执行的,那么该节点可以在返回结果的时候同时带上Prepare阶段的投票Early Acknowledgement After Prepare:如果prepare阶段已经通过/或否决了,此时Coordinator可以提前告知客户端事务已经成功/或失败了- 如何处理在
commit阶段节点宕机的问题
- 如何处理在
- 示意图参考课件中的
Three-Phase CommitPaxos- 示意图参考课件中的
33 ~ 48页
- 示意图参考课件中的
RaftZABViewstamped Replication
23.2 Replication
DBMS可以通过增加冗余数据来提高整体的可用性
设计时需要考虑以下几个维度:
Replica ConfigurationPropagation SchemePropagation TimingUpdate Method
Replica Configuration:
Master-Replica- 每个对象存储多份
Master将更新传播到其副本上,无需一致性协议Master可以支持读写事务,副本可以支持只读事务- 如果
Master宕机了,需要选举出一个新的Master
Multi-Master- 每个对象存储多份
- 任意副本都支持读写事务
- 副本之间需要通过一致性协议来同步数据
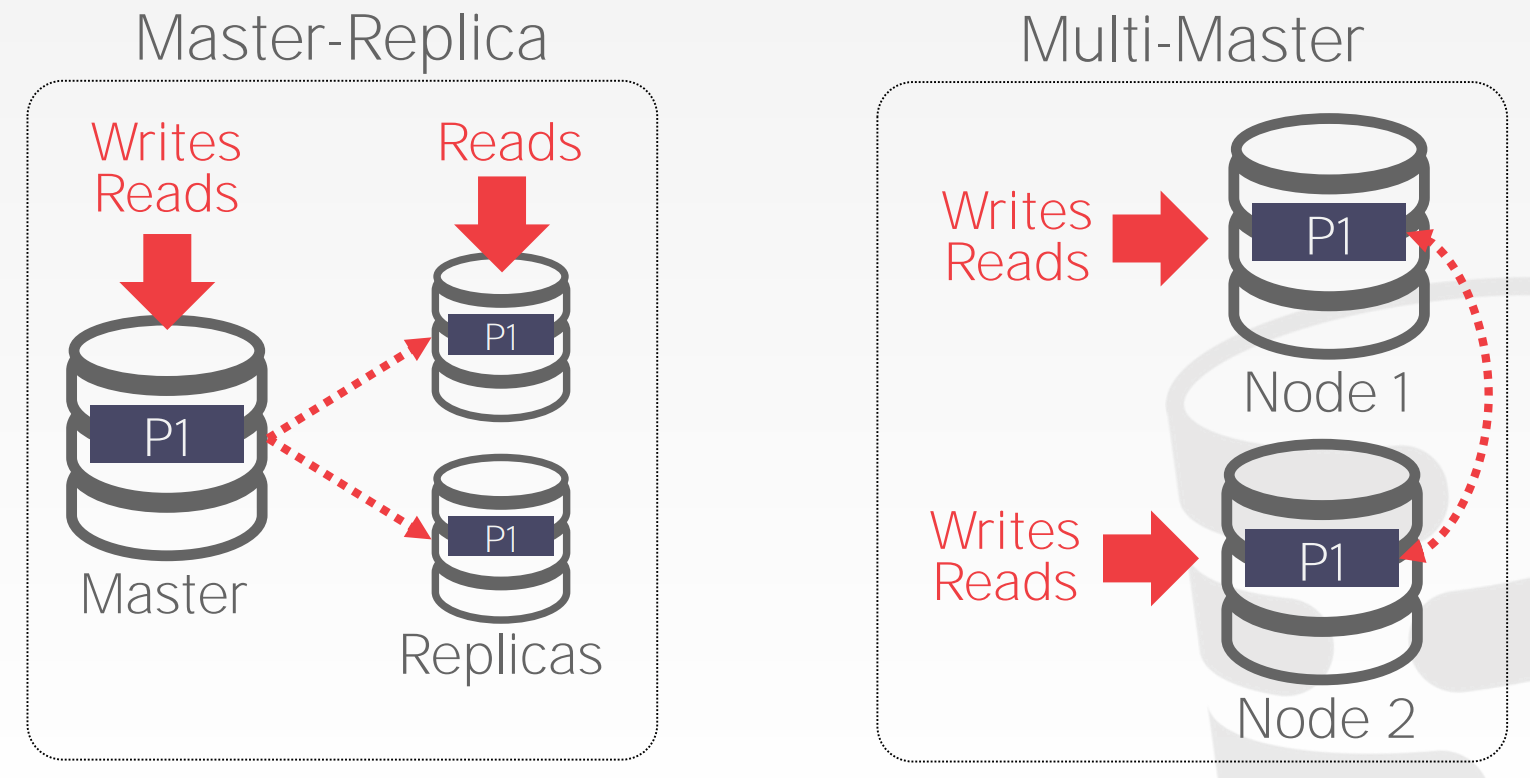
Propagation Scheme:
Synchronous (Strong Consistency)Master将更新发送给其他节点,并阻塞等待副本的回复。最后再通知应用更新成功
Asynchronous (Eventual Consistency)Master将更新发送给其他节点的同时,立即通知应用更新成功
Propagation Timing:
Continuous- 在生成
WAL的时候,立即将日志同步给副本节点
- 在生成
On Commit- 只有在事务提交时,才将该事务的所有
WAL日志同步给其他副本节点 - 如果事务终止的话,就不同步任何信息了
- 只有在事务提交时,才将该事务的所有
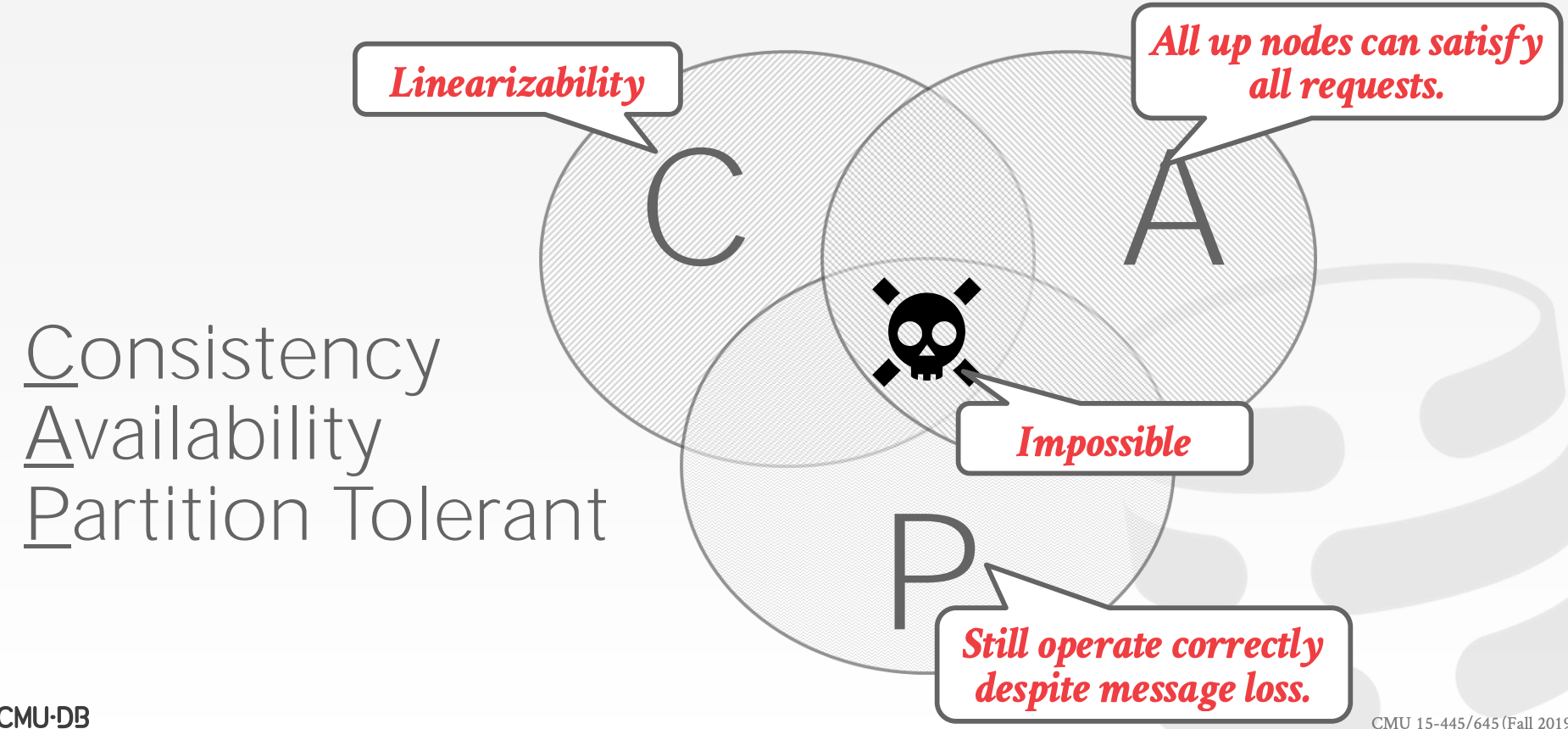
23.3 Consistency Issues (CAP)
Eric Brewer提出,对于一个分布式系统,不可能同时满足以下三点
ConsistentAlways AvailableNetwork Partition Tolerant
示意图参考课件中的63 ~ 80页
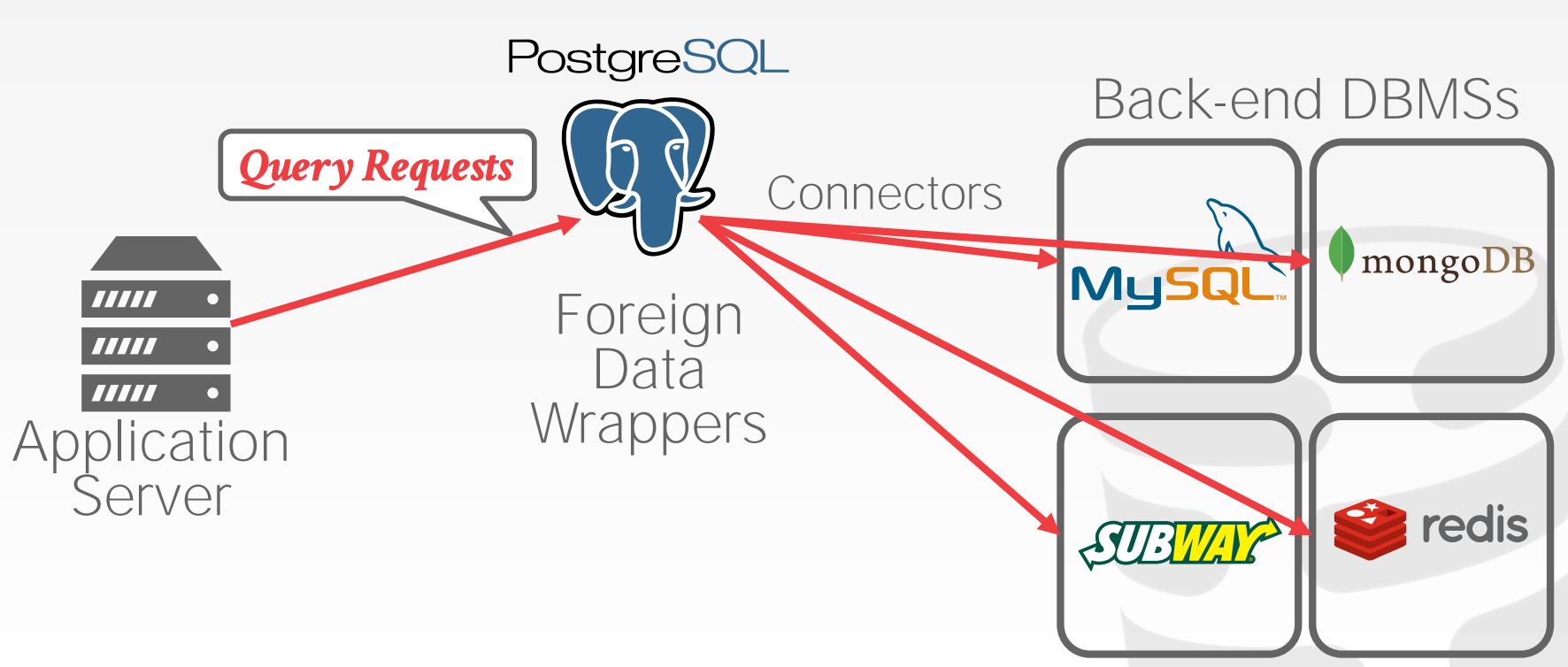
23.4 Federated Databases
Federated是一种分布式架构,允许DBMS通过Connector连接不同的数据源。这种方式非常复杂,且目前做的并不理想,主要有以下挑战:
- 需要兼容不同的数据模型、查询语言,以及相关限制
- 不易进行优化
- 大量的数据拷贝
24 Distributed OLAP
24.1 Execution Models
执行模型主要有两种:
Push- 对
filter友好 - 对
limit不友好,需要增加短路操作提前结束执行
- 对
Pull- 对
filter不友好 - 对
limit友好
- 对
24.2 Query Planning
查询计划的生成方式有如下两种:
Physical Operator:生成一个查询计划,将其拆分成多个不同的分区相关的Fragment,分发到对应的机器上执行- 大部分系统使用这种方式
SQL:将原SQL重写成多个分区相关的子查询,然后每个子查询在对应机器上分别执行- 只有
MemSQL使用这种方式
- 只有
24.3 Distributed Join Algorithms
1 | SELECT * FROM R JOIN S |
场景1:
- 其中有一张表在所有节点上都存在副本(图中的表
S) - 于是可以在每台机器独立进行
Join操作,然后进行汇总 - 示意图参考课件中的
28 ~ 29页 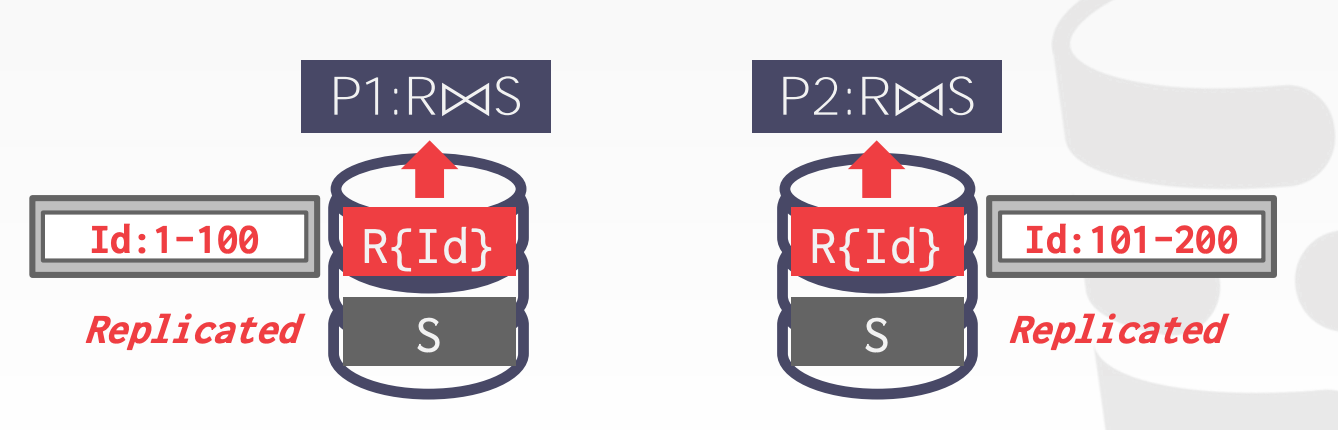
场景2:
- 两张表正好按照
Join列进行分区 - 于是可以在每台机器独立进行
Join操作,然后进行汇总 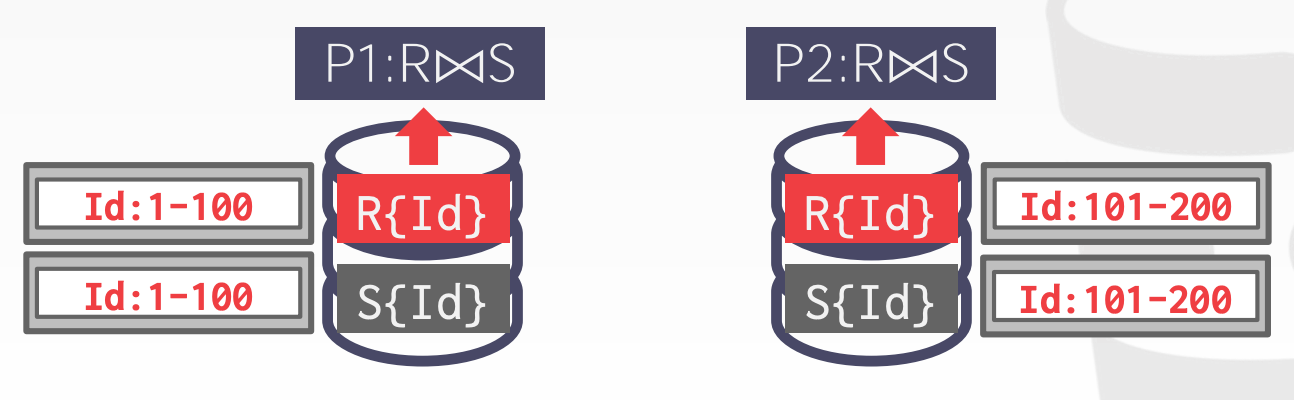
- 示意图参考课件中的
30 ~ 31页
场景3:
- 两张表按照不同的列进行分区,且有一种表较小
- 每个节点将小表
Broadcast到其他节点,这样一来每个节点都会拥有小表的所有数据,转换成了场景1 - 示意图参考课件中的
37 ~ 43页
场景4:
- 两张表按照不同的列进行分区,且两张表都比较大
- 两张表需要进行
Shuffle操作,把Join列相同的数据重新分发到同一台机器上
24.4 Cloud Systems
Managed DBMSs:
- 不需要太多改动,只是把
DBMS跑在云上,DBMS自身并不感知自己运行在云上 - 大多数数据库厂商的做法
Cloud-Native DBMS:
- 数据库就是面向云来设计的
- 通常使用
Shared-Disk架构 - 相关产品包括:
Snowflake、Goog BigQuery、Amazon Redshift、Microsoft SQL Azure
大多数数据库都有自己的存储格式,但是要实现在不同数据库之间进行数据交换,那么必须使用一种通用的数据格式:
Apache Parquet:压缩式列存储(Cloudera/Twitter)Apache ORC:压缩式列存储(Apache Hive)Apache CarbonData:压缩式列存储(华为)Apache Iceberg:一种灵活的数据结构,用于支撑Netflix的模式演进HDF5:多维数组,常用语科学领域Apache Arrow:内存的压缩式列存储(Pandas/Dremio)
25 Oracle
26 Potpourri
27 缩写表
| 缩写 | 全称 |
|---|---|
DBMS |
Database Management System |
DML |
Data Manipulation Language |
DDL |
Data Definition Language |
DCL |
Data Control Language |
CTE |
Common Table Expressions |
HDD |
Hard Disk Drive |
JIT |
Just-In-Time |
SSD |
Solid-state Drive |
OLTP |
On-line Transaction Processing |
OLAP |
On-line Analytical Processing |
LRU |
Least-Recently Used |
28 课件
- 01-introduction
- 02-advancedsql
- 03-storage1
- 04-storage2
- 05-bufferpool
- 06-hashtables
- 07-trees1
- 08-trees2
- 09-indexconcurrency
- 10-sorting
- 11-joins
- 12-queryexecution1
- 13-queryexecution2
- 14-optimization1
- 15-optimization2
- 16-concurrencycontrol
- 17-twophaselocking
- 18-timestampordering
- 19-multiversioning
- 20-logging
- 21-recovery
- 22-distributed
- 23-distributedoltp
- 24-distributedolap
- 25-oracle
- 26-potpourri