阅读更多
1 history
1960s - Integrated Data Store, IDS
Network data model:见下图Tuple-at-a-time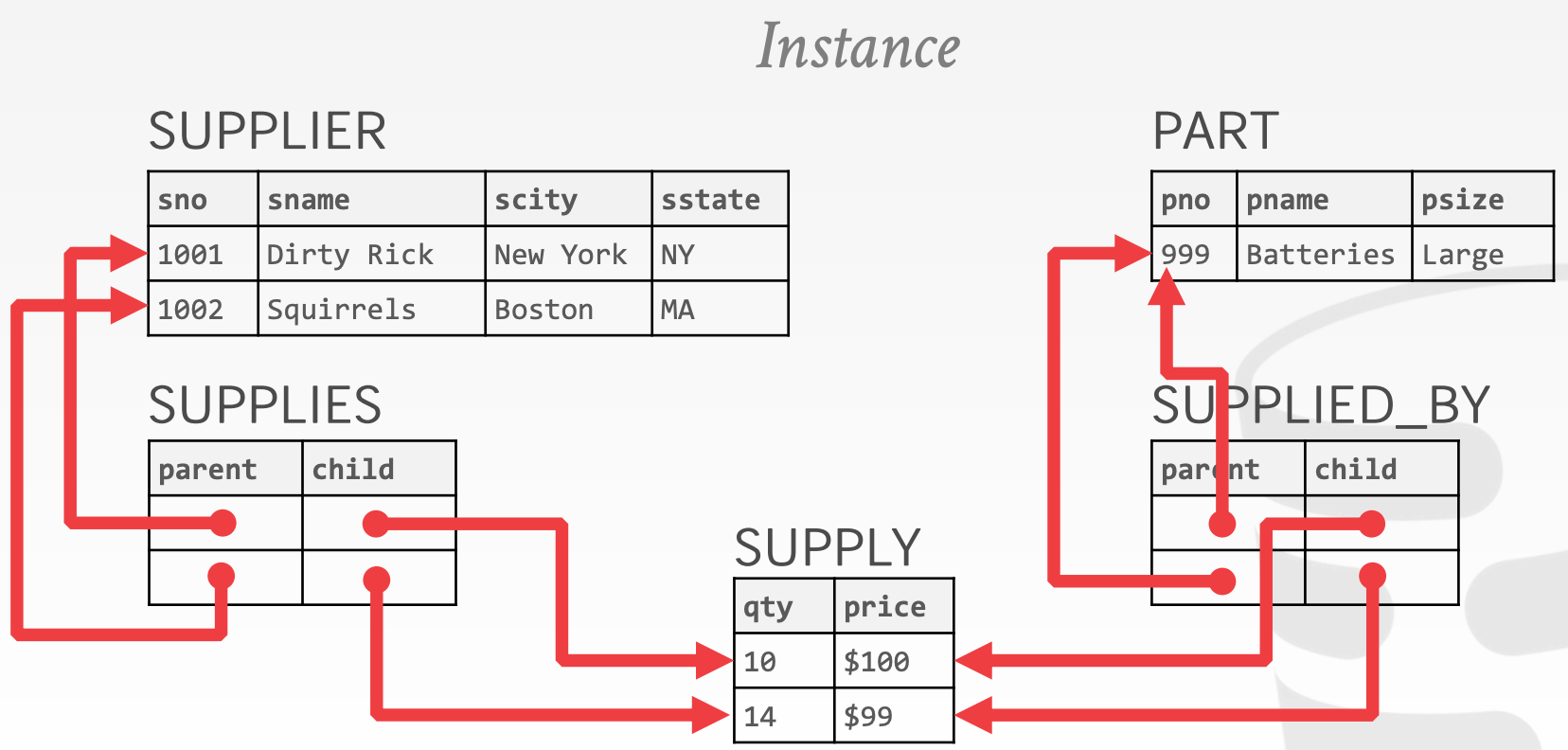
1960s - Information Management System, IMS
Hierarchical data model:见下图Programmer-defined physical storage formatTuple-at-a-time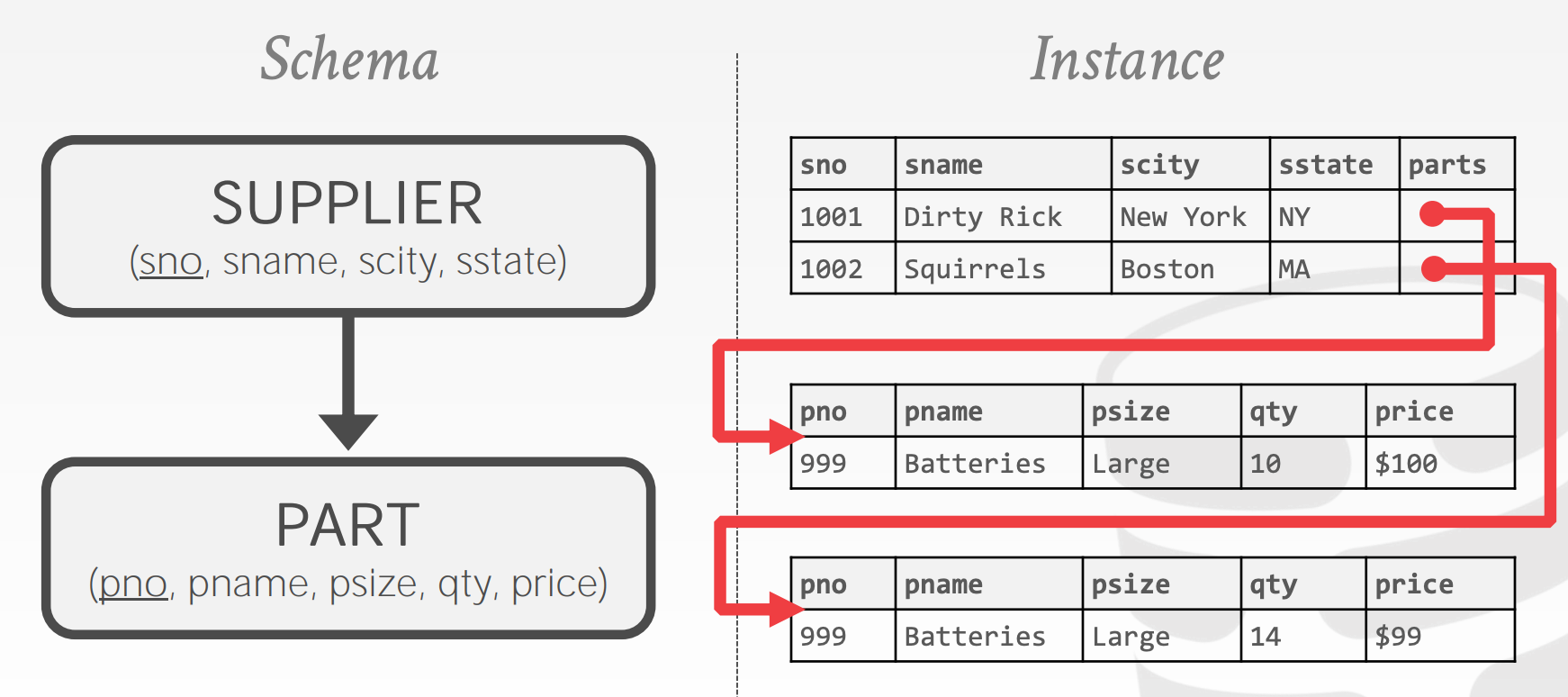
1970s - Relational Model
Store database in simple data structuresAccess data through high-level languagePhysical storage left up to implementation
- 早期的实现包括
System RINGRESOracle
1980s - Relational Model
Relation Model在角逐中胜出,SEQUEL演变成为SQLOracle在商业角逐中胜出Stonebraker创立了Postgre
1980s - Object-Oriented Databases
- 大多数这一阶段产生的
DBMS在今天都不存在了,但是这些技术以另一种方式存在,比如JSON/XML等 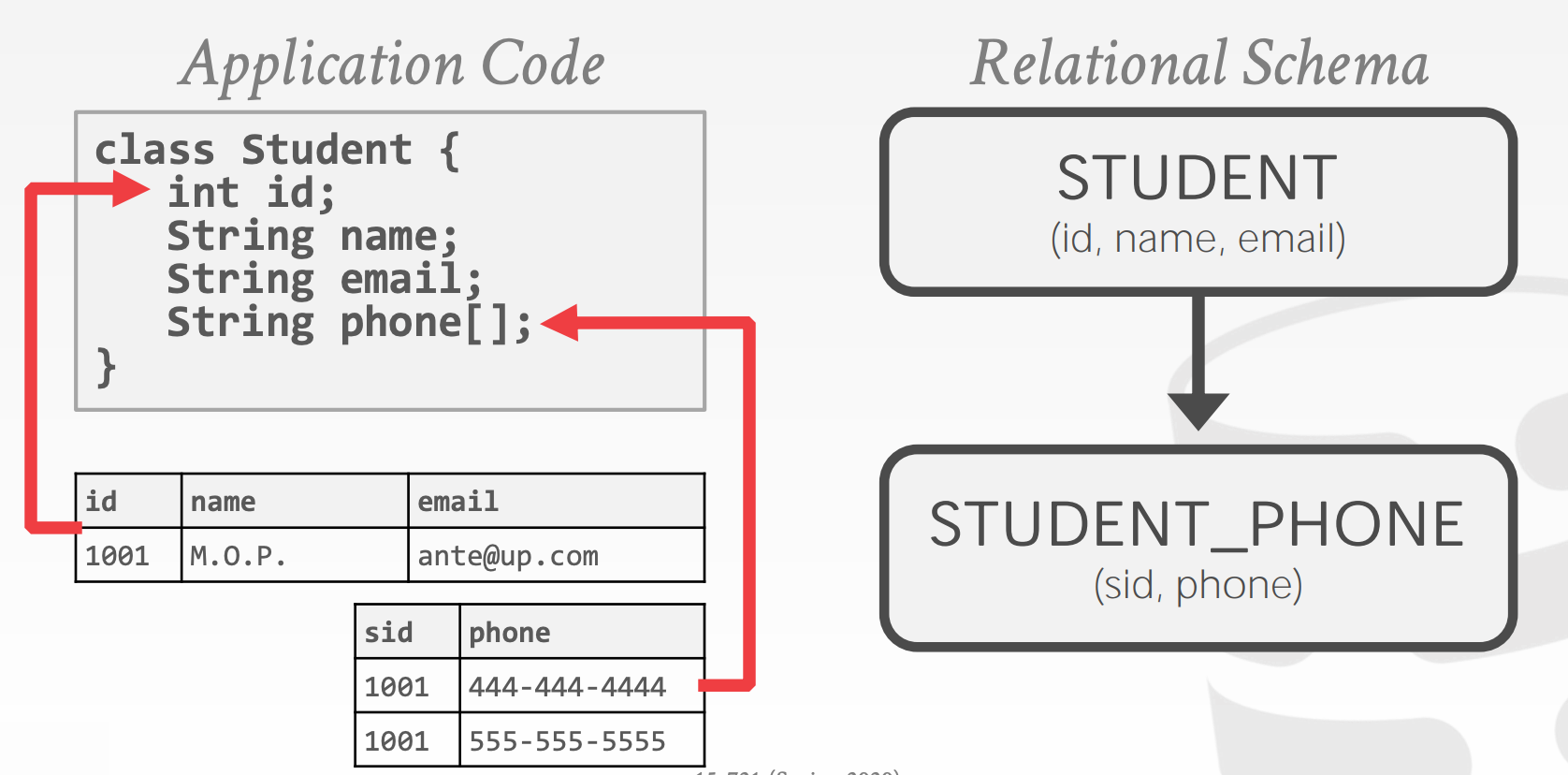

1990s - Boring Days
- 这十年中,数据库系统没有重大进步
- 微软借鉴了
Sybase,创立了SQL Server Mysql出现,作为mSQL的一种替代方案Postgres支持SQLSQLite在2000年早期出现
2000s - Internet Boom
- 网络大发展,分布式兴起
- 原有的数据库都是重量级且及其昂贵的,在分布式的场景中不再有优势
- 各大公司都独立开发中间件,用以支持
DBMS的水平伸缩
2000s - Data Warehouses
OLAP兴起Relational / SQL- 分布式、
Shared-Noting架构 - 列存大放异彩
2000s - NoSQL Systems
- 专注于高可用和高可扩展
Non-relational data model,例如键值对- 无
ACID事务 API取代了SQL
2010s - NewSQL
- 在支持
ACID事务的同时,提供与NoSQL相当的性能 Relational / SQL- 分布式
2010s - Hybrid Systems
Hybrid Transactional-Analytical Processing, HTAP- 同时提供
OLTP和OLAP的功能和性能 - 分布式、
Shared-Noting架构 Relational / SQL
2010s - Cloud Systems
DBaaS, Database-as-a-service
2010s - Shared-Disk Engines
- 存储计算分离
- 通常用于数据湖(
Data Lake)
2010s - Graph Systems
- 提供了针对图形的API
- 研究表明,尚不清楚使用以图形为中心的执行引擎和存储管理器是否有任何好处
2010s - Timeseries Systems
- 时序数据库,主要存储时序相关的数据
Andy's Thoughts
- 随着专用系统扩展其领域范围,
DBMS类别的分界线将随着时间的推移而继续模糊 - 我相信关系模型和声明式查询语言促进了更好的数据工程
2 inmemory
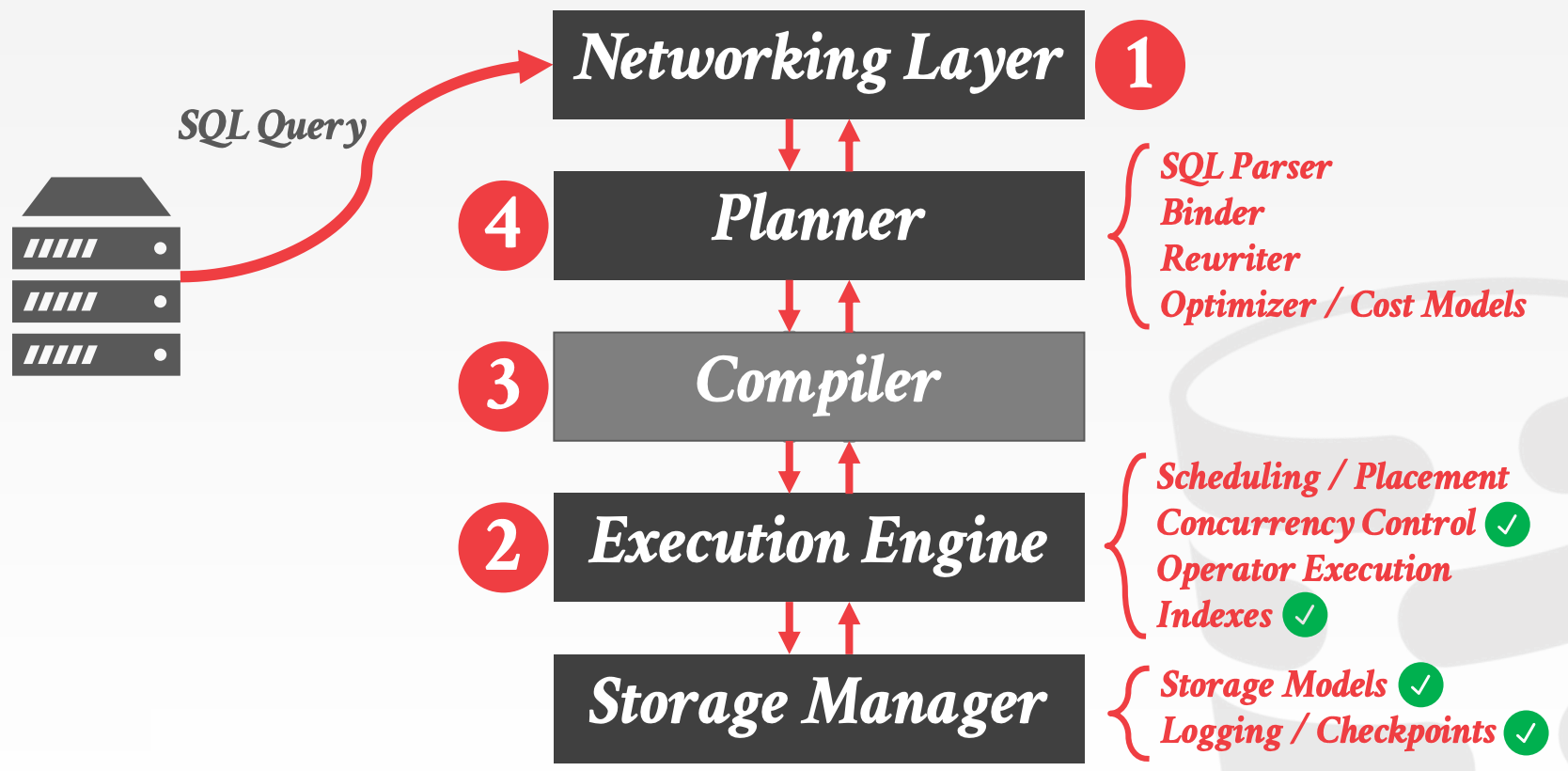
2.1 Disk-Oriented DBMSs
Buffer Pool
Steal + No-Force
示意图参考课件中的7 ~ 13页
2.2 In-Memory DBMSs
首批商用的In-Memory DBMS在1990s发布,包括:
TimesTenDataBlitzAltibase
索引:
1980s提出了专门的主存索引,当时高速缓存和内存访问速度大致相当- 但后来高速缓存的速度远远大于内存的访问速度时,内存优化索引的性能比
B+树差,因为它们不支持缓存(为啥会不支持缓存)
执行查询计划:
- 由于数据都在内存中,顺序访问不再比随机访问快
- 传统的
tuple-at-a-time的访问方式会因为函数调用的开销而变得很慢。这一情况在OLAP中更加突出
Logging & Recovery
In-Memory DBMS也需要将WAL写入非易失性存储上,因为系统可能随时崩溃- 由于不存在
Dirty Page,因此无需追踪整个系统中的LSN
性能瓶颈:对于In-Memory DBMS来说,I/O不再是性能瓶颈,同时其他开销也会被放大:
Locking/LatchingCache-line missesPointer chasingPredicate evaluationsData movement & copyingNetworking
2.3 Concurrency Control Bottlenecks
对于In-Memory DBMS而言,事务获取锁的开销和访问数据的开销相当
DBMS可以将Lock Information与数据存储在一起,提高CPU Cache Locality- 需要用
CAS替代Mutex
Concurrency Control Schemes
Two-Phase Locking, 2PLDeadLock DetectionDeadLock Prevention- 示意图参考课件中的
30 ~ 37页
Timestamp Ordering, T/OBasic T/OOptimistic Concurrency Control, OCC- 示意图参考课件中的
40 ~ 63页
仿真结果参考课件中的71 ~ 75页
SchemesDL_DETECT:2PL w/ DeadLock DetectionNO_WAIT:2PL w/ Non-waiting PreventionWAIT_DIE``2PL w/ Wait-and-Die PreventionTIMESTAMP:Basic T/O AlgorithmMVCC:Multi-Version T/OOCC:Optimistic Concurrency Control
BottlenecksLock Thrashing:DL_DETECT、WAIT_DIE- 按照
primary key的顺序来获取锁,彻底消除死锁
- 按照
Timestamp Allocation:WAIT_DIE、All T/O AlgorithmMutexAtomic AdditionBatched Atomic AdditionHardware ClockHardware Counter
Memory Allocations:OCC、MVCC- 不要使用默认的
malloc
- 不要使用默认的
3 mvcc1
DBMS对每个逻辑对象维护了多个物理版本
- 当事务写某个对象时,会创建该对象的一个新的物理版本
- 当事务读某个对象时,会读取事物开始时该对象的最新版本。用时间戳来判断可见性
- 写操作不阻塞读操作
- 读操作不阻塞写操作
Snapshot Isolation, SI:
- 若两个事务同时更新同一个对象,那么时间上较早写入的事务获胜
- 会产生
Write Skew Anomaly,示意图参考课件中的5 ~ 9页
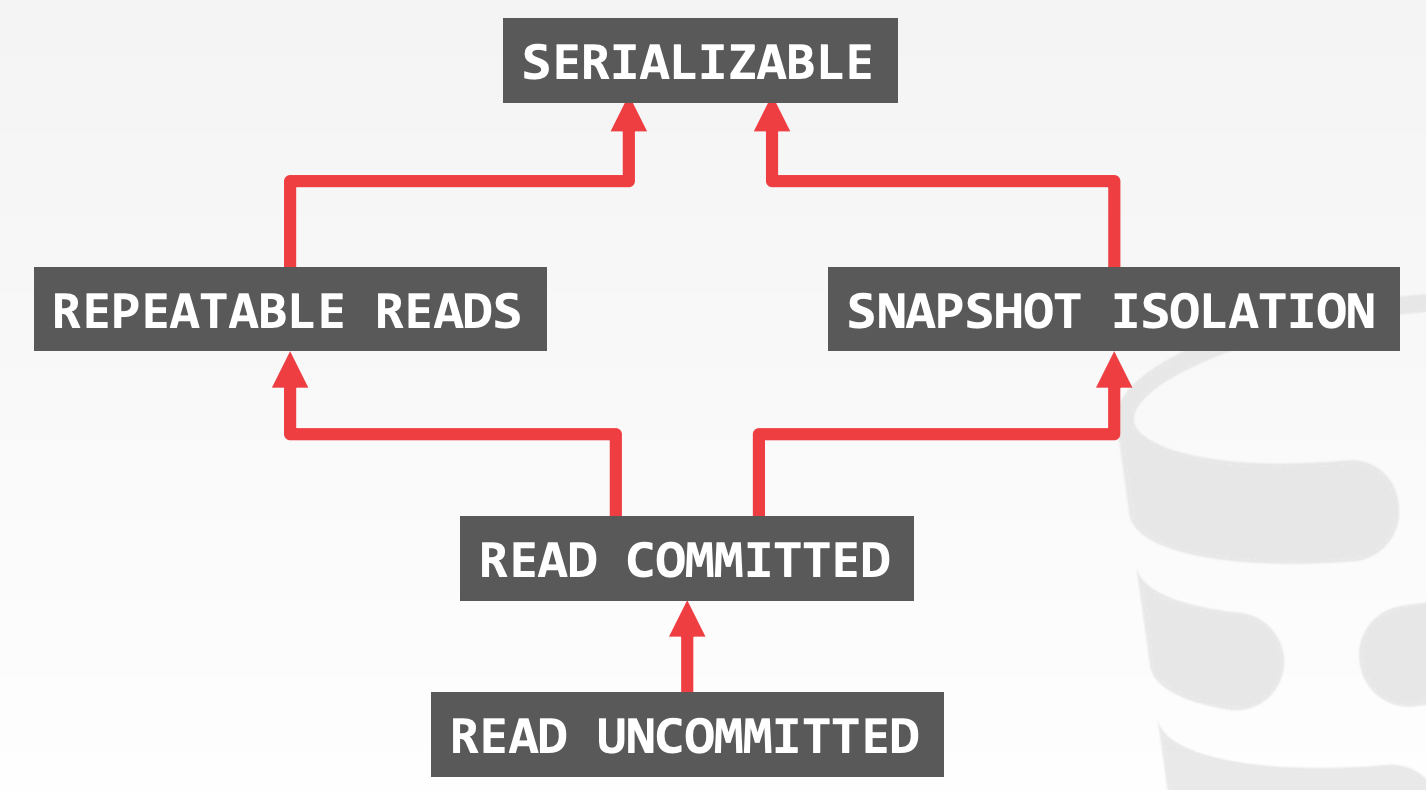
MVCC主要设计点:
Concurrency Control Protocol
Timestamp Orderingread-ts:用于记录最近一次读取的时间- 若
Latch未被其他事务持有,且Tid介于begin-ts和end-ts之间,那么该记录对事务T可见 - 若
Latch未被其他事务持有,且Tid > read-ts,那么事务T可以创建当前记录的一个新版本
Optimistic Concurrency ControlTwo-Phase Locking- 使用
read-cnt作为Shared Lock;使用txn-id以及read-cnt作为Exclusive Lock - 若
txn-id = 0,那么递增read-cnt字段来表示获取Shared Lock - 若
txn-id = 0 && read-cnt == 0,那么将txn-id设置成当前事务的Tid,且递增read-cnt字段来表示获取Exclusive Lock
- 使用
- 示意图参考课件中的
15 ~ 40页
Version StorageAppend-Only Storage- 新版本会追加到
table所在的同一个存储空间 Version Chain OrderingOldest-to-Newest(O2N)- 新版本追加到链的尾部
- 查找时,需要遍历整个链
Newest-to-Oldest(N2O)- 新版本插入到链的首部,有额外的更新指针的操作
- 查找时,无需遍历整个链
- 新版本会追加到
Time-Travel Storage- 维护两个数据表,一个叫做
Main Table,另一个叫做Time-Travel Table - 每次更新时,都会将当前记录移动到
Time-Travel Table - 同一记录的所有版本以
Newest-to-Oldest的方式关联起来
- 维护两个数据表,一个叫做
Delta Storage- 维护两个数据表,一个叫做
Main Table,另一个叫做Delta Storage Segment - 每次更新时,将数值的变化表达式记录到
Delta Storage Segment中 - 可以通过重放
Delta Storage Segment来重建老的版本
- 维护两个数据表,一个叫做
Non-Inline Attributes- 维护两个数据表,一个叫做
Main Table,另一个叫做Variable-Length Data - 通过指针复用那些在多个版本间没有变化的属性
- 需要额外维护计数器
- 内存分配复杂
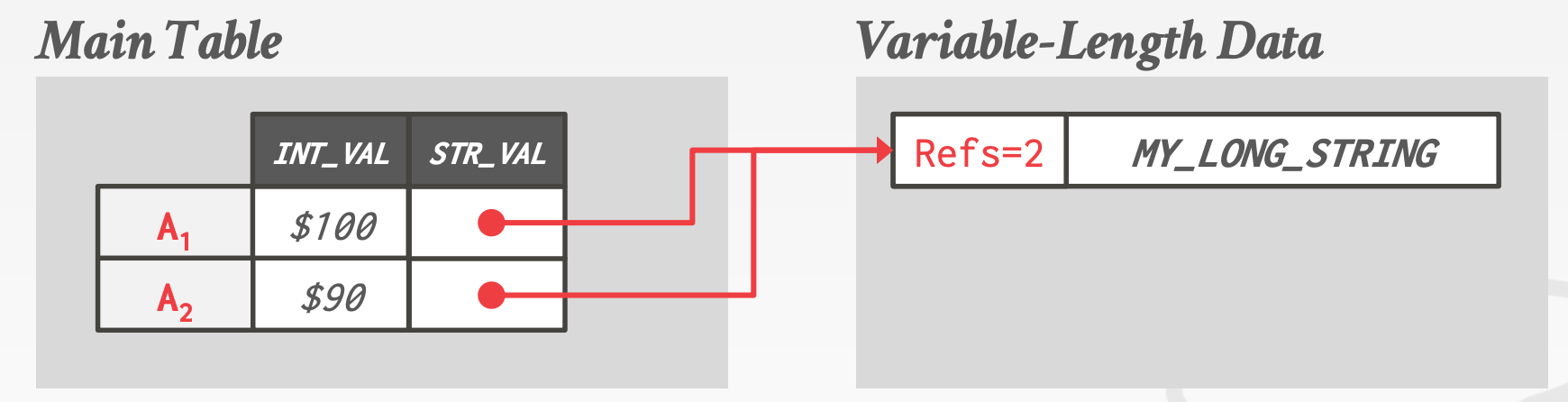
- 维护两个数据表,一个叫做
Garbage CollectionDBMS需要持续移除那些可回收的版本- 对任何事务都不可见的版本
- 终止的事务创建的版本
- 主要设计要点包括
- 如何查找过期版本
- 如何判断版本是否可回收
- 到哪查找过期版本
- 实现方式
Tuple-Level- 直接检查每个元组
Background Vacuuming:周期性地扫描数据表,由额外的线程池完成Cooperative Cleaning:在事务查找最新的可见版本时,进行清理。由事务线程完成,只能用于O2N
Transaction-Level- 事务记录了数据修改前的版本,因此可以通过事务查找这些过期版本
Index ManagementPrimary Key Indexes:总是指向Version Chain HeaderSecondary Indexes:更加复杂Logical Pointers- 每个
Tuple需要维护一个固定的标识符(不同版本中,该标识符保持一致) - 需要一个中间层,来做标识符到物理地址的转换(物理地址指向
Version Chain Header) - 标识符可以是
Primary Key或者Tuple Id
- 每个
Physical Pointers- 维护一个指向
Version Chain Header的指针
- 维护一个指向
MVCC Indexes
MVCC DBMS通常不在索引上直接存储版本信息- 索引需要支持
Duplicate Key,同一个Key可能指向不同的Logical Tuple Snapshot - 示意图参考课件中的
87 ~ 93页
4 mvcc2
4.1 Microsoft Hekaton (SQL Server)
Hekaton MVCC:
- 记录的每个版本都维护了两个时间戳
BEGIN-TS:活跃事务的BeginTS,或者是已提交事务的CommitTSEND-TS:Infinity,或者是已提交事务的CommitTS- 示意图参考课件中的
6 ~ 24页
- 维护了一个全局的
Transaction state mapACTIVE:事务进行中VALIDATING:事务触发了Commit,且DBMS正在校验合法性COMMITTED:事务已经结束,但是尚未修改由该事务创建的所有版本的时间戳TERMINATED:事务已经结束,且已经修改由该事务创建的所有版本的时间戳

- 只使用
Lock-Free的数据结构- 唯一的串行点是时间戳的分配
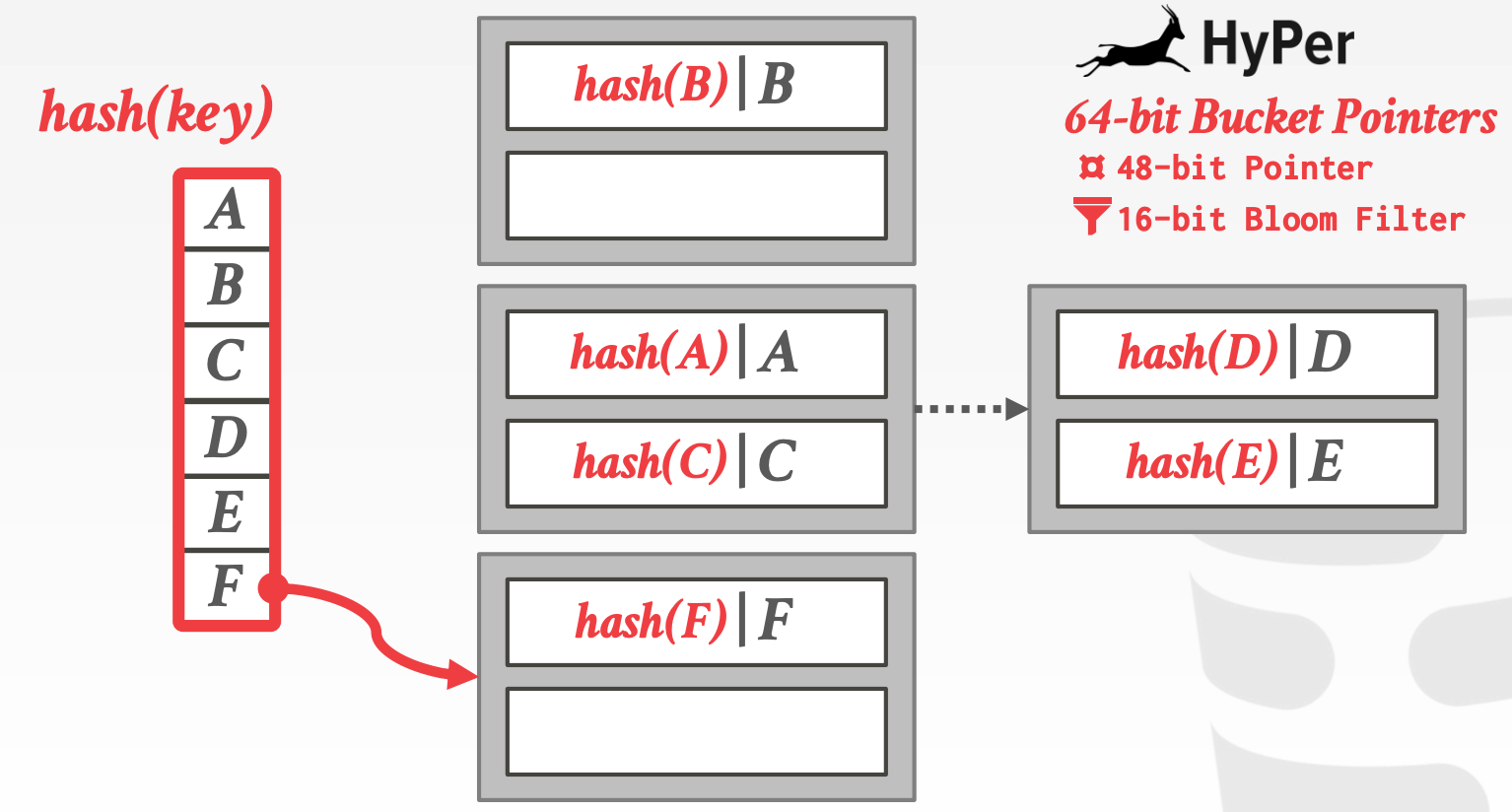
4.2 TUM HyPer
HyPer MVCC:
Delta Storage以及Column Storage- 非索引字段可以原地更新
- 插入、删除操作会更新索引
N2O Version ChainNo Predicate Locks、No Scan Checks
- 通过直接终止那些试图修改未提交记录的事务,来避免写冲突
- 示意图参考课件中的
33 ~ 37页(完全没看懂)
4.3 SAP HANA
SAP HANA MVCC:
Time-Travel Storage(N2O)Main Data Table中存储的是最老的版本- 每个
Tuple维护一个标识位,用于表示Version Space中是否有新版本 - 维护一个
Hash Table,用于映射Record Identifier和Version Chain Header 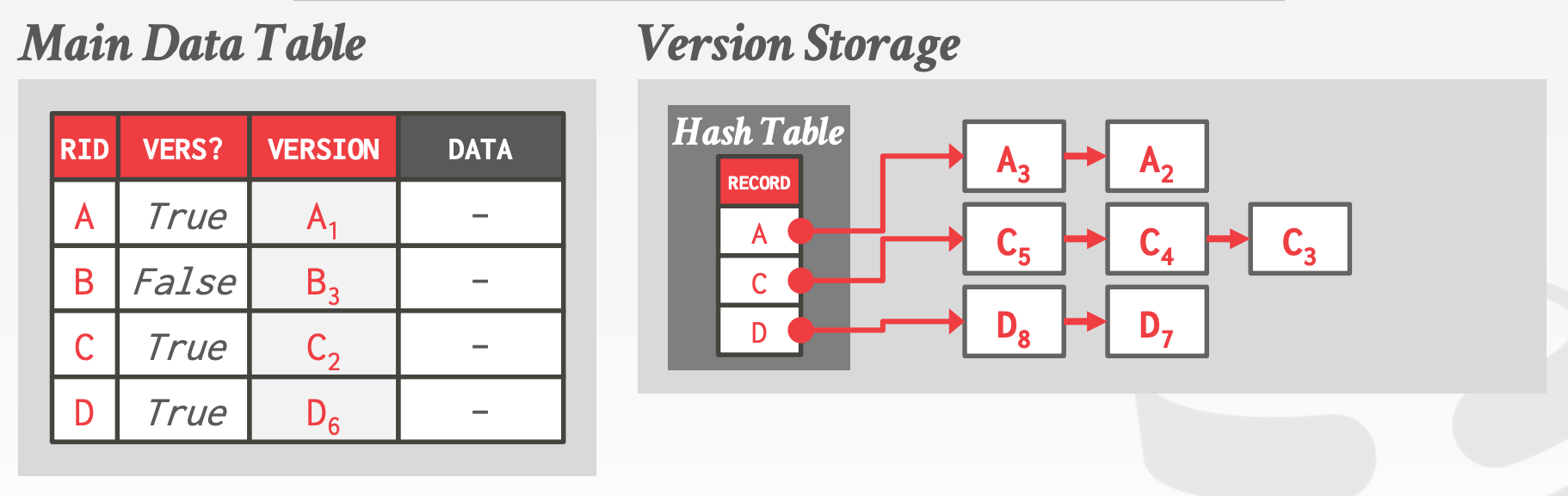
4.4 CMU Cicada
CMU Cicada MVCC:
In-Memory DBMSAppend-Only-Storage(N2O)Best-effort Inlining
4.5 Summary
MVCC Limitations:
Computation & Storage Overhead- 大多数
MVCC方案都会使用间接的方式来搜索Version Chain,这会增加CPU Cache Miss - 需要频繁的垃圾回收,来减小版本搜索的开销
- 大多数
Shared Memory Writes- 大多数
MVCC方案将版本信息存储在全局的内存中,而没有考虑局部性(CPU Cache Miss)
- 大多数
Timestamp Allocation- 所有线程访问同一个
Counter
- 所有线程访问同一个
OCC LIMITATIONS:
Frequent Aborts- 频繁地终止事务,尤其是高并发场景下
Extra Reads & Writes- 事务需要将记录拷贝到私有的空间,来保证可重复度
- 同时,提交时需要检查读是否满足一致性
Index Contention
5 mvcc3
5.1 MVCC Deletes
当一个Tuple的所有版本都逻辑删除后,DBMS才会对其进行物理删除
如何表示逻辑删除?有如下两种方式:
Deleted Flag- 在最新的版本后面增加一个标志位,用于表示逻辑删除
Tombstone Tuple- 创建一个空的物理版本来表示逻辑删除
- 用一个独立的
Pool来存储这些Tombstone Tuple,每个Tombstone Tuple只需要1-bit的存储空间
5.2 Garbage Collection
设计要点:
Index Clean-upVersion Tracking LevelTuple-LevelBackground VacuumingCooperative Cleaning
Transaction-LevelEpochs
Frequency:Trade-off,过于频繁,浪费CPU资源,且降低事务的效率;过于不频繁,浪费存储空间,降低版本查找的效率Periodically:定期触发,或者某些指标达到阈值后触发Continuously:将清理过程作为事务处理的一部分
GranularitySingle Version- 单独追踪每个版本的可见性,单独回收
- 控制粒度更细,但是开销大
Group Version- 以分组的方式管理版本,且以分组为单位进行回收。每个分组包含多个版本
- 开销较低,但是会延迟回收(分组中的所有版本都可以回收时,才能回收整个分组)
Table(P29,没懂)
Comparison UnitTimestamp- 用一个全局最小的时间戳来判断版本是否可以回收
- 实现简单
Interval- 用区间来判断可见性
- 实现复杂
5.3 Block Compaction
DBMS需要将那些未满的块合并成更少的块,以减少内存使用量
6 oltpindexes1
6.1 In-Memory T-Tree
B+ Tree是为了提高在速度较低的存储介质上的访问速度。而T-Tree是针对内存数据库的一种替代方案,它基于AVL Tree
T-Tree的节点包含如下属性
Data Pointers:指向数据的指针Parent Pointer:指向父节点的指针Left Child Pointer:指向左孩子的指针Right Child Pointer:指向右孩子的指针Max-K:当前节点指向的数据中的最大值。若Key > Max-K,那么Key可能存在于右孩子中Min-K:当前节点指向的数据中的最小值。若Key < Min-K,那么Key可能存在于左孩子中
优势:
- 由于其不直接存储节点数据,因此占用内存更少
劣势:
- 难以平衡
- 难以实现并发安全
示意图参考课件中的7 ~ 22页
6.2 Latch-Free Bw-Tree
A new form of B tree, Bw-tree achieves its very high performance via a latch-free approach that effectively exploits the processor caches of modern multi-core chips.
6.2.1 Delta Updates
更新时,生成对应的Delta,Delta指向原链表头,然后通过CAS操作替换Mapping Table中的指针,使其指向自己。若失败,则终止或重试
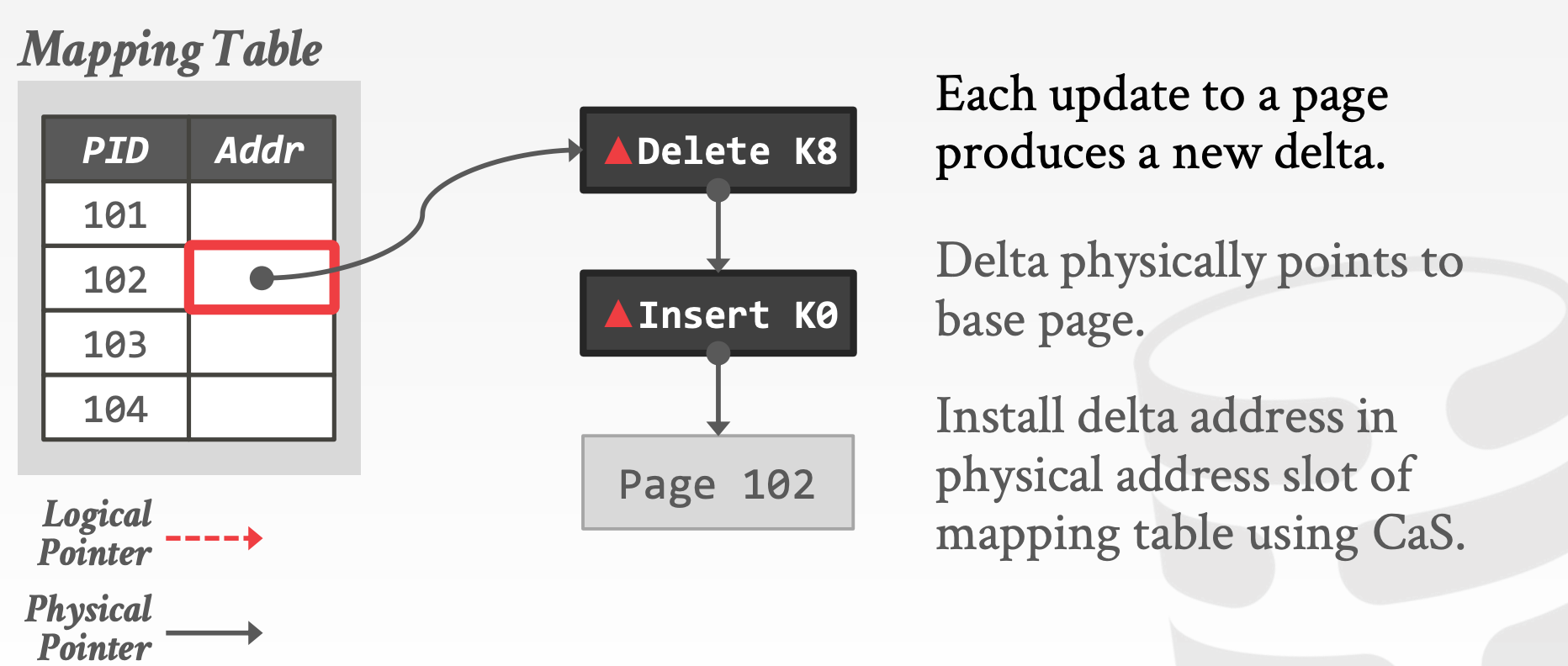
示意图参考课件中的23 ~ 40页
6.2.2 Garbage Collection
我们需要知道何时可以安全地为Latch-Free Index中的已删除节点回收内存
Reference Counting- 计数为
0时,可以删除 - 在多核CPU上,并发性能较差。因为递增递减计数器,会导致大量的缓存一致性流量
- 我们其实并不关心计数器的大小是多少,而只是希望在计数值为
0的时候可以进行回收(允许延迟,不必立即回收)
- 计数为
Epoch-based Reclamation(没懂)- 维护一个全局的
Epoch Counter,并对其进行周期性地更新- 跟踪在一个
Epoch期间哪些线程进入索引以及它们何时离开
- 跟踪在一个
- 标记删除节点时标记节点的当前
Epoch- 一旦所有线程都离开该
Epoch,就可以回收该节点
- 一旦所有线程都离开该
- 操作用一个
Epoch进行标记- 每个
Epoch都会跟踪属于它的线程以及可以回收的对象 - 线程在每个操作之前加入一个
Epoch,并发布可以为当前Epoch回收的对象(不一定是它加入的那个)
- 每个
- 示意图参考课件中的
49 ~ 57页
- 维护一个全局的
Hazard Pointers
6.2.3 Structure Modifications
Split Delta Record:
- 标记
Page的某个Key Range现在位于另一个Page - 使用
Logical Pointer指向New Page
Separator Delta Record:
- 在修改
Page的Parent中记录New Page的搜索范围
示意图参考课件中的59 ~ 70页
6.3 B+ Tree Optimistic Latching
优化1:Pre-Allocated Delta Records
- 在
Page中预先分配空间,用于存放Delta
优化2:Mapping Table Expansion
- 最高效的内存数据结构就是数组。但是为每个索引都分配一个完整的数组会比较浪费
- 使用虚拟内存分配整个数组。仅在访问对应偏移量的时候,才分配对应的物理内存(如何实现???)
7 oltpindexes2
7.1 Latches
Latch方案的目标:
- 更小的内存占用
- 执行效率更高(无冲突)
- 当前线程等待时间过长时,取消调度线程
Latch的实现方案:
Test-and-Set Spinlock- 高效(指令简单)
- 扩展性差,
Cache不友好,OS不优化(在最坏的情况下,可能浪费大量CPU资源) std::atomic<T>
Blocking OS Mutex- 使用简单
- 扩展性差(每个
lock/unlock大约花费25ns) std::mutex
Adaptive Spinlock- 在用户态自旋一段时间
- 若在自旋期间无法获取锁,就会让出
CPU,并记录到Parking Lot中 - 线程在进入自旋期间,看下是否有其他线程位于
Parking Lot中,若是,择直接将自己挂起,避免无效自旋 - 苹果的
WTF::ParkingLot
Queue-based Spinlock- 比
Mutex更高效,且具有更好的Cache Locality std::atomic<Latch*>
- 比
Reader-Writer Locks- 允许并发读
- 需要分别管理
Read Queue、Write Queue,以防止饿死 - 可以基于
Spinlock实现
7.2 B+ Tree
B+ Tree是一种平衡树,其访问、插入、删除的复杂度都是O(log n)
在访问一颗B+ Tree的过程中,需要获取或者释放Latch
- 当某个节点的孩子节点都被认为是安全时,可以释放该节点的
Latch- 安全意味着,不会发生
Split以及Merge操作
- 安全意味着,不会发生
Search:从根节点开始,向下重复执行如下过程- 获取孩子节点的
Read Latch - 释放父节点的
Read Latch
- 获取孩子节点的
Insert/Delete:从根节点开始,向下重复执行如下过程- 获取孩子节点的
Write Latch - 若孩子是安全的,那么释放该孩子节点的所有祖先节点的
Write Latch
- 获取孩子节点的
- 示意图参考课件中的
35 ~ 49页
对于Insert/Delete的访问流程,由于直接沿路径加了Write Latch,这样很容易导致整个流程串行化,一个优化方式是:
- 假设目标的
Leaf Node是安全的,先用Read Latch访问,如果在访问路径中发现任何不安全的节点,再退回到上面这个版本 - 示意图参考课件中的
51 ~ 54页
Versioned Latch
- 每个节点维护一个版本信息(
Counter) - 写操作获取
Latch时,会递增该版本信息(释放不会递减) - 读操作查看
Latch是否可用,但是不获取它,只是记录当时的版本信息。在读操作找到目标叶子节点后,再检查版本信息是否发生过变化。若发生过变化,那么终止或者重试读操作 -
- 示意图参考课件中的
56 ~ 69页(没看懂)
- 示意图参考课件中的
7.3 Trie Index
Trie Index又称为字典树或者前缀树
- 其形状只依赖于
Key Space以及其长度 - 不需要平衡操作
- 所有操作的复杂度是
O(k),其中k是Key的长度 Key是隐式存储的,从根到叶节点的整条路径,表示了某个Key- 示意图参考课件中的
75 ~ 83页
Radix Tree
- 作为唯一孩子节点的每个节点都与其父节点合并
- 又称为
Patricia Tree - 会产生假阳性(
False Positive),所以DBMS需要再次校验Key是否匹配
7.3.1 Judy Array
Judy Array是256-Way Radix Tree的变体,是第一种已知的能够实现自适应节点表示的Radix Tree:
- 支持下三种类型:
Judy1:将Integer Key映射成单个bit, true or falseJudyL:将Integer Key映射成Integer ValueJudySL:将Variable-Length Key映射成Integer Value
- 节点的元数据被打包成一个
128-bit的Judy Pointers,存储在父节点中Node TypeLinear Node:稀疏- 分为左右两部分,左边存储排序后的
Key,右边存储对应于Key的指向孩子的指针 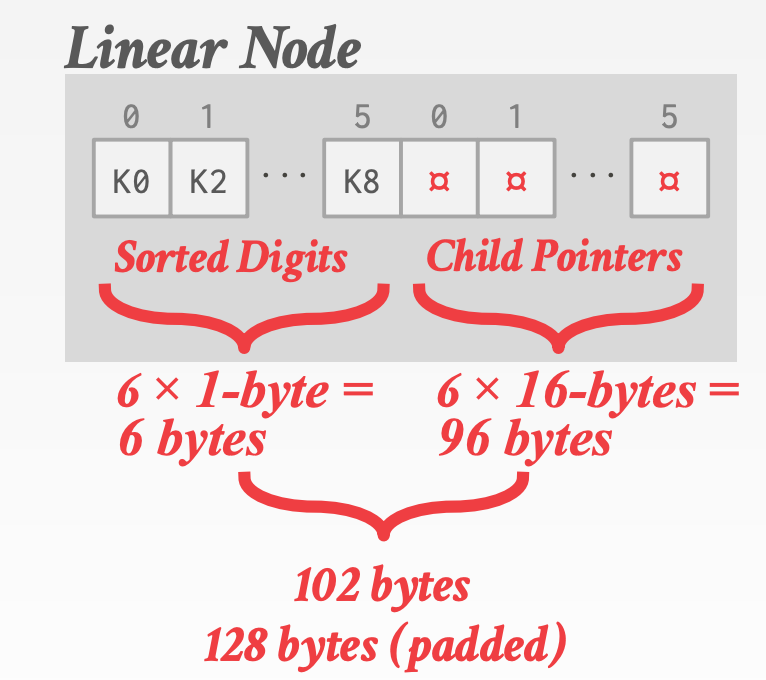
- 分为左右两部分,左边存储排序后的
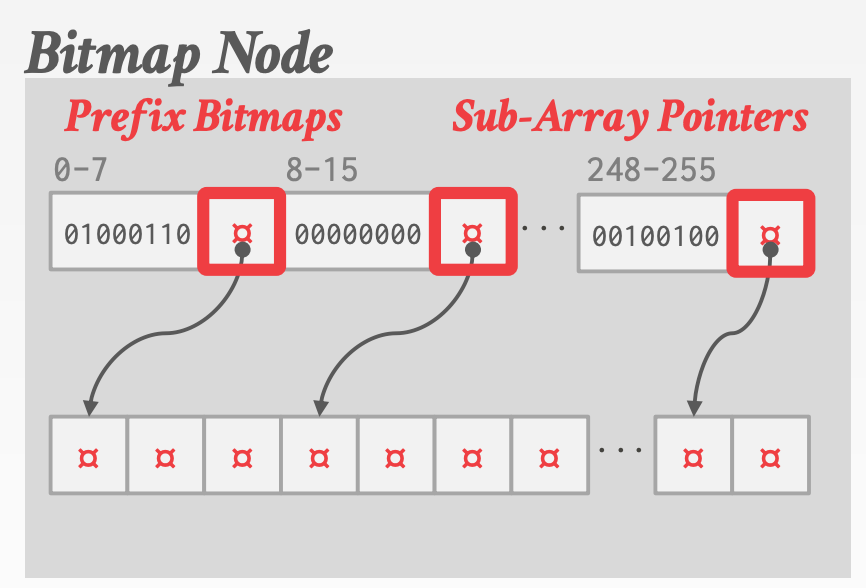
Bitmap Node:常规(好像理解的不太对)- 包含一个长度为256的
Bitmap,用于表示某个Key是否存在(Key大小为1-byte,范围是0-255,正好作为Bitmap数组的下标) - 每
8-bit一组,总共分为32组,可以隐式存储32个Key 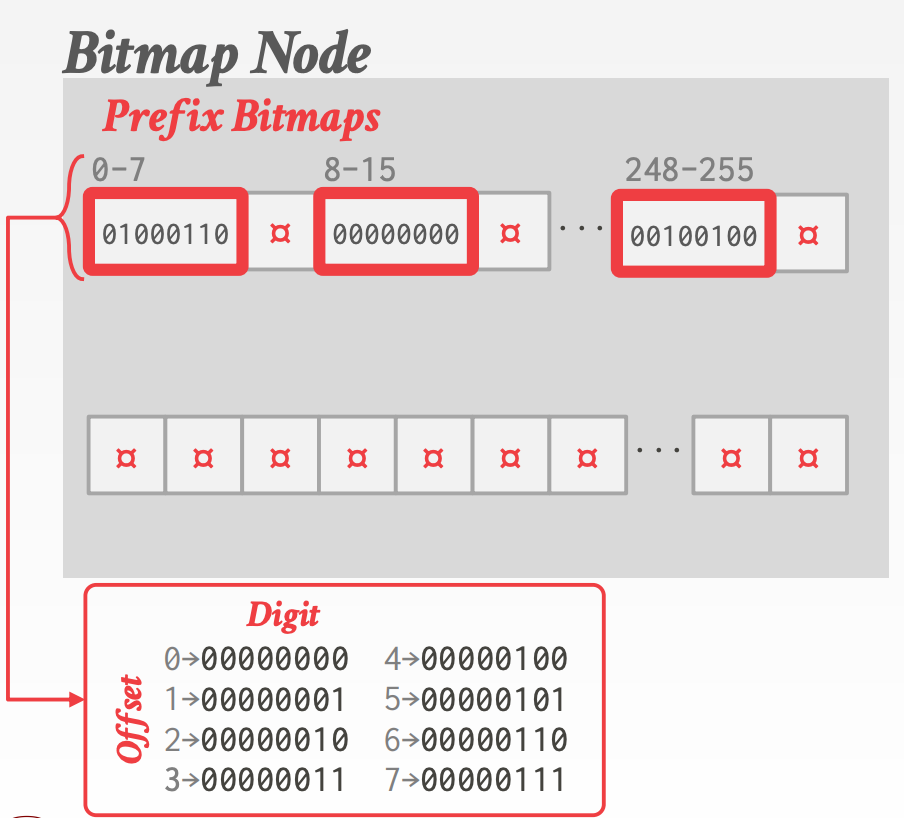
- 包含一个长度为256的
Uncompressed Node:密集- 类似于下面要介绍的
ART-Node256
- 类似于下面要介绍的
Population CountChild Key Prefix / Value64-bit Child Pointer
7.3.2 ART
Adapative Radix Tree, ART
- ART-Paper
- 被应用于
TUM HyPer DBMS 256-Way Radix Tree,基于分布,支持不同的节点类型- 每个节点的元数据存储在其
Header中
ART vs. Judy
Judy有3中不同的节点类型。ART有4种不同的的节点类型(基于孩子的数量)Judy是一个通用的关联数组。它拥有键和值。ART是表索引,不需要覆盖完整的键,其值是指向元组的指针
ART的节点类型:
Node4Node4包含两个最大长度为4的数组,一个数组用于存储Key(1-byte),另一个用于存储Pointer(8-byte)。Key和Pointer一一对应。总大小是1byte * 4 + 8byte * 4 = 36 byte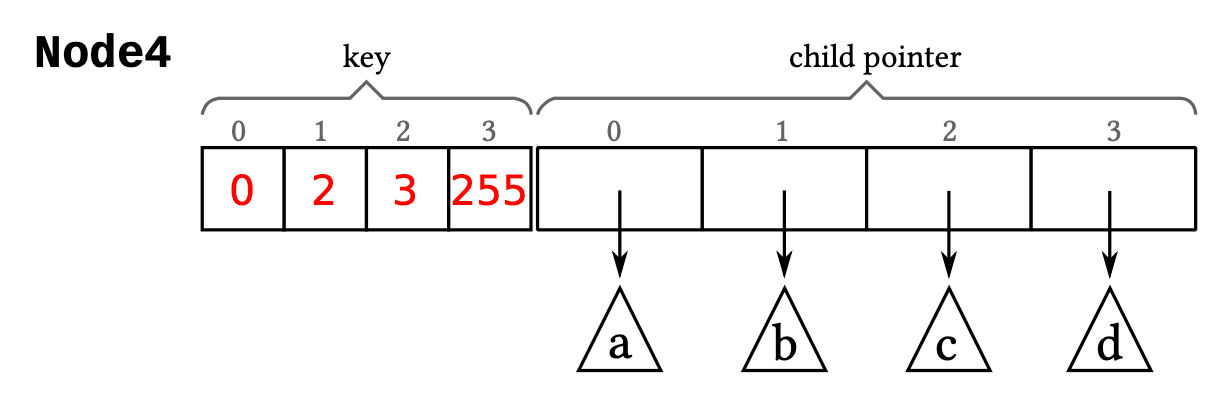
Node16Node16,其结构与Node4类似,包含两个最大长度为8的数组,一个数组用于存储Key(1-byte),另一个用于存储Pointer(8-byte)。Key和Pointer一一对应。总大小是1byte * 16 + 8byte * 16 = 144 byte- 搜索时,可以采用二分查找,或者直接利用
SIMD指令 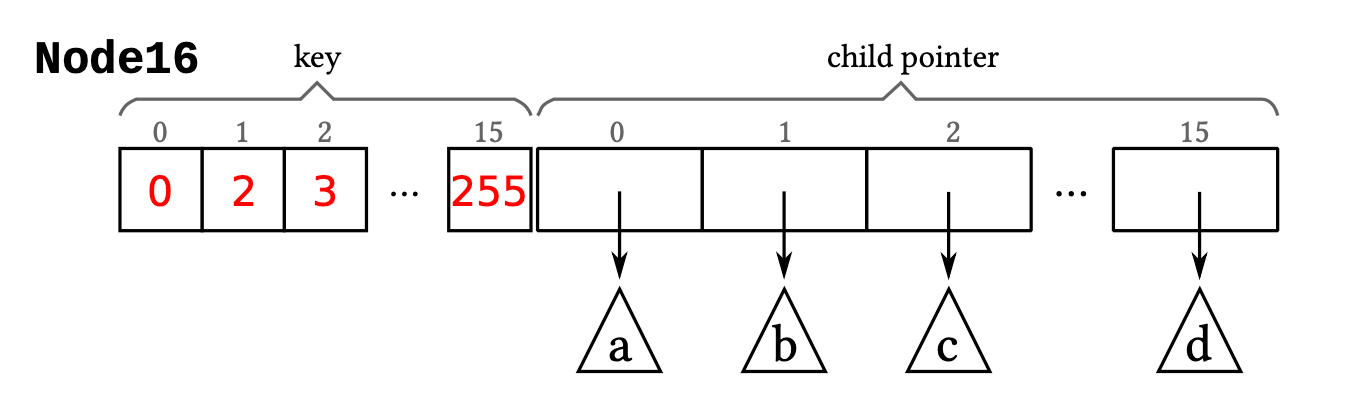
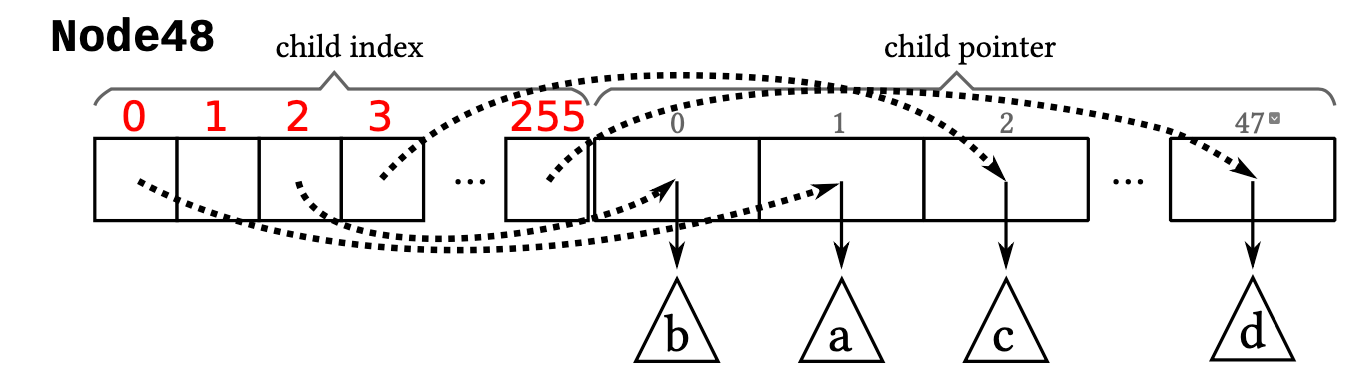
Node48Node48结构上和Node4、Node16有所不同,包含两个长度不同的数组,一个数组长度是256,每个元素1-byte,另一个数组长度48,每个元素8-byte,用于存储Pointer。总大小是1byte * 256 + 8byte * 48 = 640 byte- 该结构隐式存储了48个
Key。由于Key的大小是1-byte,其数值刚好是0-255,正好作为第一个数组的下标,第一个数组中存储的值,同时作为第二个数组的下标(由于第二个数组的长度是48,因此1-byte完全可以表示)
- 该结构隐式存储了48个
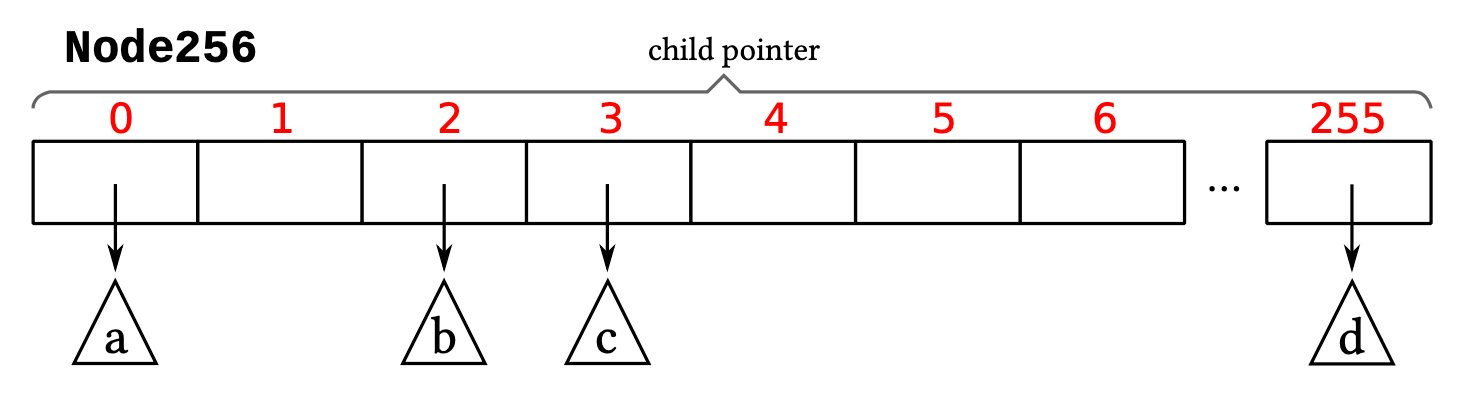
Node256Node256只有一个长度为256的数组,用于存储Pointer(8-byte)。总大小是8byte * 256 = 2048 byte- 该结构同样隐式存储了256个
Key,由于Key的大小是1-byte,其数值刚好是0-255,正好作为数组的下标 - 正因为
Node48的Pointer数组只有48个元素,无法用Key Byte直接索引,于是才引入了一个长度为256,大小为1-byte的数组,充当第一级索引
- 该结构同样隐式存储了256个
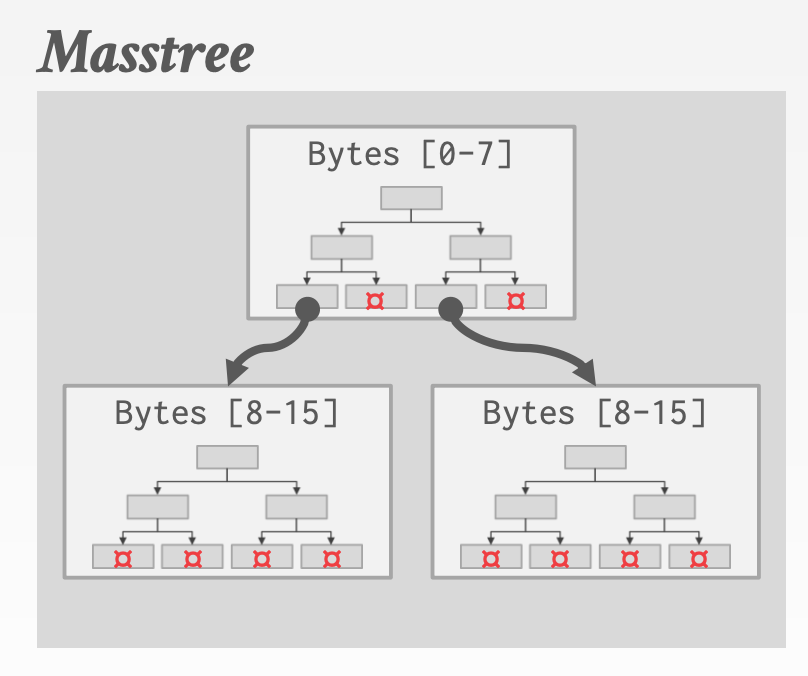
7.3.3 Masstree
Masstree的每个节点都是一颗B+ Tree
8 storage
8.1 Type Representation
int/bigint/smallint/tinyint:直接用C++基本类型表示float/real/numeric:IEEE-754 Standard- 可变精度,存在精度损失
- 计算效率高
decimal:Fixed-point Decimalstime/date/timestamp:32/64-bit intvarchar/varbinary/text/blob- 指针
- 包含当前长度和下一个位置的指针的
Header
8.2 Data Layout / Alignment
以字对齐(Word-Aligned)的方式存储,能够显著提高吞吐率
No AlignmentAlignment With PaddingAlignment With Padding + Sorting
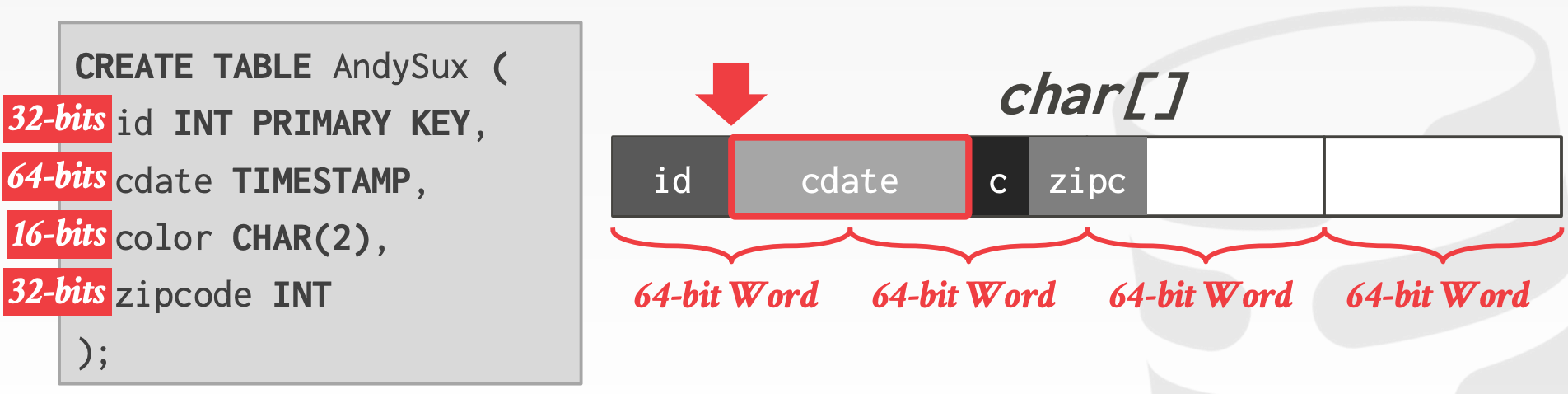


8.3 Storage Models
N-ary Storage Model, NSM:
- 连续存储单个
Tuple的所有属性 OLTP的理想存储模型,因为OLTP通常读写单个Tuple,且经常会有批量插入操作- 使用
tuple-at-a-time的迭代模型 - 优势:
- 插入、删除、更新操作快
- 对于需要获取
Tuple所有属性的查询更友好 - 可以使用面向索引的存储
- 劣势:
- 对于扫描全表的操作不友好
- 对于需要获取
Tuple部分属性的查询不友好
Decomposition Storage Model, DSM:
- 单独存储
Tuple的每个属性 OLAP的理想存储模型,因为OLTP通常会对某几个属性进行大范围或全表扫描- 优势:
- 无需读取不需要的属性
- 更好的压缩性能
- 劣势:
- 插入、删除、更新、点查较慢
Tuple IdentificationFixed-length Offsets:Tuple中的每个属性的偏移量都是相同的Embedded Tuple Ids:Tuple中的每个属性额外存储其Tuple Id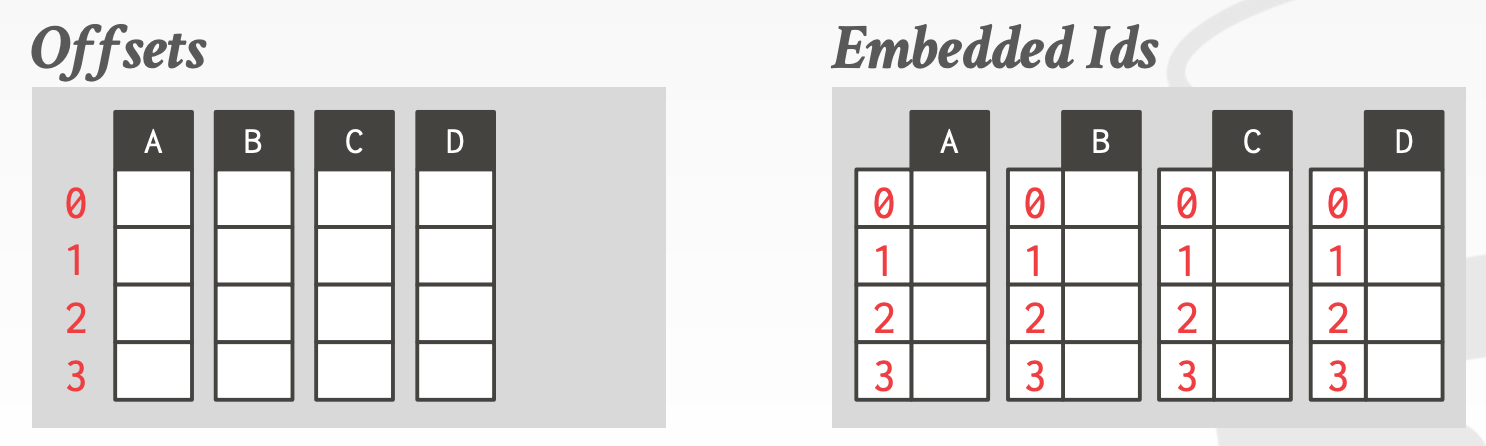
Data OrganizationInsertion OrderSorted OrderPartitioned
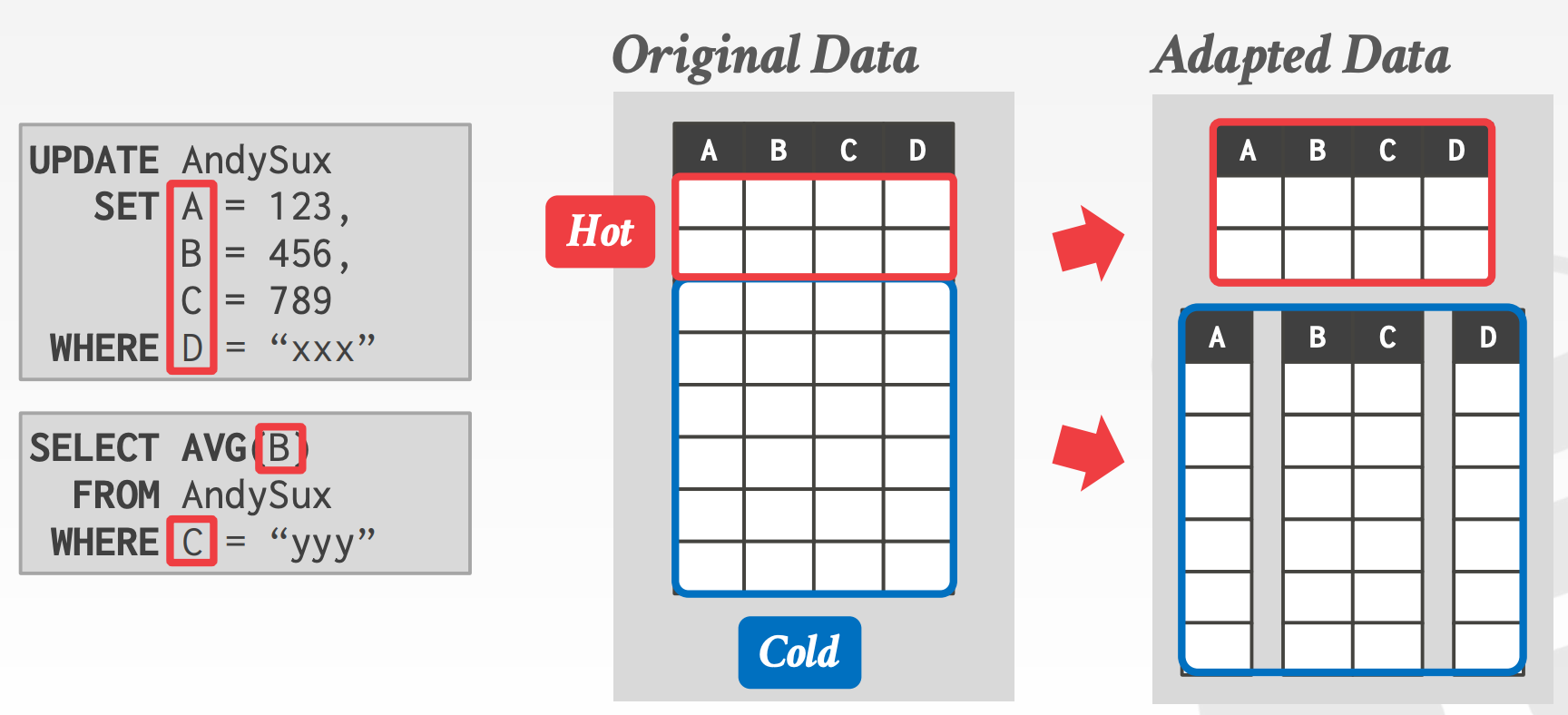
Hybrid Storage Model:
Hot Data vs. Cold Data- 数据插入后,有很大概率会被再次更新
- 经过一段时间后,数据大概率只会被读取
Execution EngineSeparate Execution Engines:针对NSM以及DSM两种存储模型,使用两个独立的Execution Engine- 需要合并来自两个引擎的结果
- 需要事务跨两个引擎,那需要使用
2PC - 实现方式有2种
Fractured Mirrors:Oracle, IBMDelta Store:SAP HANA
Single, Flexible Architecture:使用一个能够兼容处理NSM以及DSM两种存储模型的Execution Engine- 不需要存储数据库的两个副本
- 不需要同步
Database Segments - 实现方式
Peloton Ataptive Storage


8.4 System Catalogs
几乎所有的DBMS以存储普通数据的方式存储Cagalogs。但由于Catalogs的特殊性,需要有专门的引导代码。DDL同样需要保证ACID
Schema Change:
Add ColumnsNSM:将元组复制到新区域DSM:只需创建新的列
Drop ColumnsNSM:- 将元组复制到新区域
- 标记为删除,后面再清理
DSM:只需删除列
Change Columns
Indexes:
Create Index- 扫描全表,并填充索引
- 记录在扫描期间,由其他事务引起的变更
- 扫描结束后,锁表,将扫描期间记录的变更更新到索引上
Drop Index- 逻辑删除索引
- 仅当删除索引的事务提交时,它才会变得不可见。在此之前,所有活跃的事务仍然需要更新它
8.5 小结
Hybrid Storage Model已被抛弃,原因如下:
- 工程实现的难度太大
Delta Version Storage + Column Store与之等价Catalog实现难度大
9 compression
9.1 Compression Background
I/O是DBMS的瓶颈之一,它需要权衡速度与压缩率- 在现实场景中,数据倾斜普遍存在
- 同一个数据表中的不同列,存在很大的数据相关性
Compression的目标:
- 产生定长的输出
- 尽可能地推迟解压缩的时机,这样可以使得处理的数据尽可能的小。也称为延迟物化(
Late Meterialization) - 无损压缩
Data Skipping:
Approximate Queries:仅查询采样数据级,来产生近似的结果Zone Map:提前计算每个数据块的元数据,比如最大值、最小值等。这样在查询的时候,可以检查这些元数据来决定是否跳过当前块
Compression Granularity:
Block-LevelTuple-Level- 仅适用于
NSM
- 仅适用于
Attribute-LevelColumn-Level- 仅适用于
DSM
- 仅适用于
9.2 Naive Compression
Naive Compression即采用一种通用算法对数据进行压缩,常用的算法包括:
- LZO(1996)
- LZ4(2011)
- Snappy(2011)
- Brotli(2013)
- Oracle OZIP(2014)
- Zstd(2015)
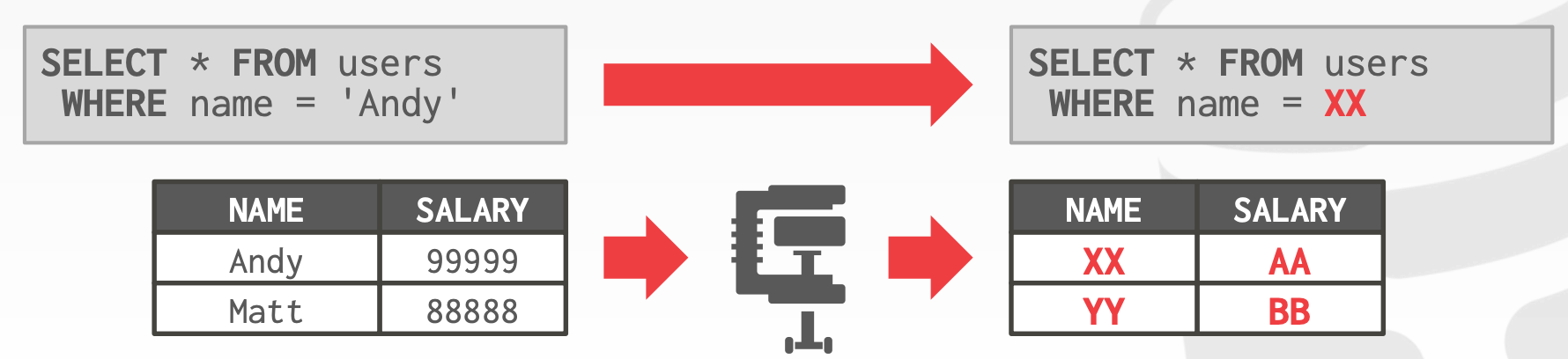
在这种方案下:
DBMS必须先对数据进行解压缩,然后才能对其进行读写操作- 不考虑数据的高级含义以及语义
- 相等性比较可以在压缩的状态下进行(前提是,数据以相同的方式压缩)
9.3 OLAP Columnar Compression
常用的Columnar Compression算法如下:
Null Supression- 对连续的零值、空值或者空白进行压缩,将其替换成出现位置以及数量的描述信息(类似于游程编码)
- 适用于数据稀疏的场景
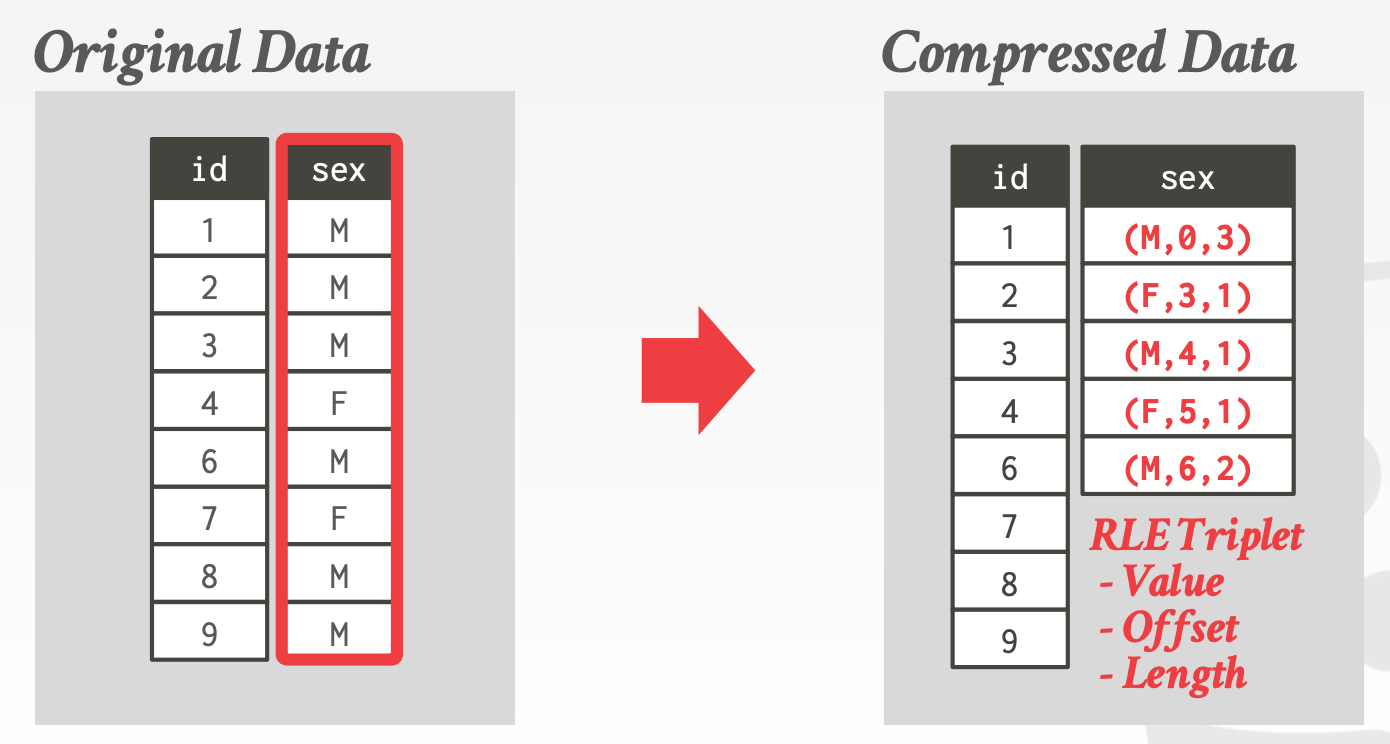
Run-length Encoding- 将连续相同的值编码成一个三元组,即值,起始偏移量,长度
Bitmap Encoding- 额外存储一个
Bitmap用于映射属性的每个值 - 仅适用于基数较低的场景
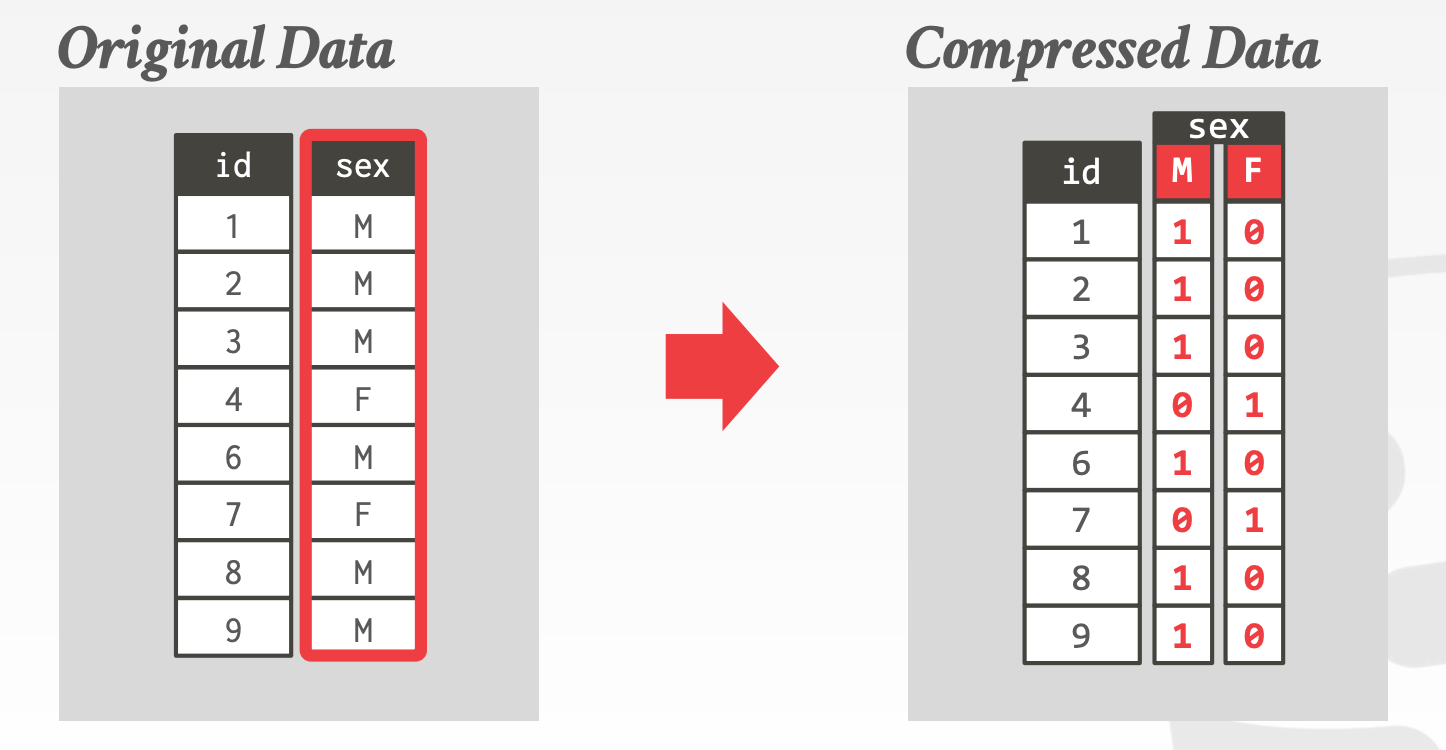
- 上述
Bitmap存在两种压缩方式General Purpose Compression- 例如
LZ4、Snappy - 必须解码后才能进行数据处理
- 对内存数据库不友好
- 例如
Oracle Byte-Aligned Bitmap Codes- 对
Bitmap进行分类Gap Byte:所有bit都是0Tail Byte:部分bit是1
- 对包含
Gap Bytes以及Tail Bytes的数据进行压缩Gap Byte使用RLE进行压缩Tail Bytes- 若仅包含
1,或者只有一个1的情况,进行压缩 - 否则不压缩,直接存储
- 若仅包含
- 示意图参考课件中的
31 ~ 40页 - 这种方式已被淘汰。虽然它提供了很好的压缩性能,但是效率较低。
Word-Aligned Hybrid, WAH作为一种替代方案,提供了更好的性能- 这两种方式都不支持随机访问
- 对
- 额外存储一个
Delta Encoding- 存储的不是值本身,而是变化
- 配合
RLE可以达到更好的压缩效果 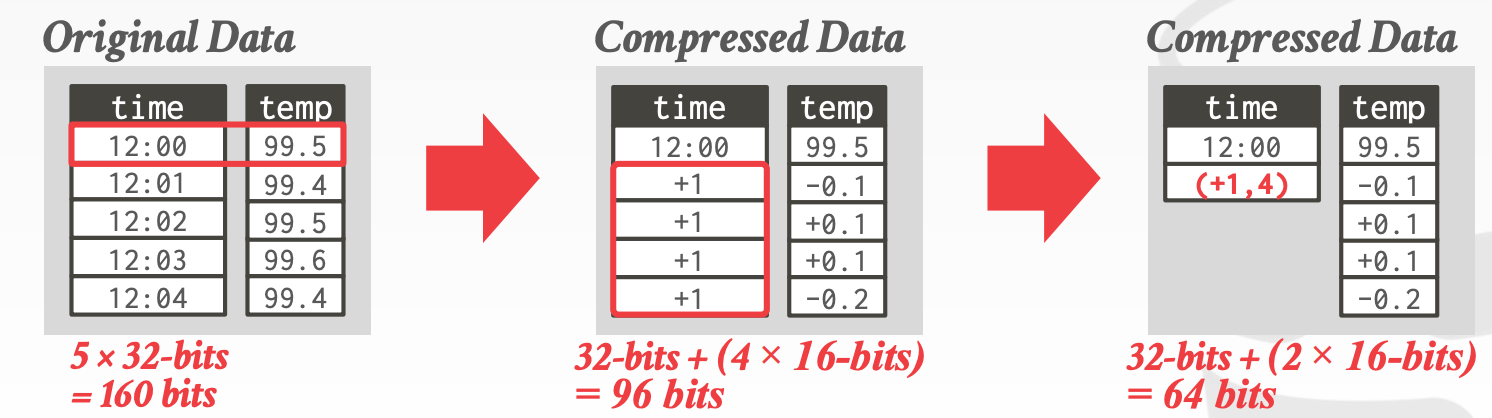
Incremental Encoding- 类似于
Delta Encoding的思路,Incremental Encoding避免存储相同的前缀 - 在数据有序时,压缩效率更高
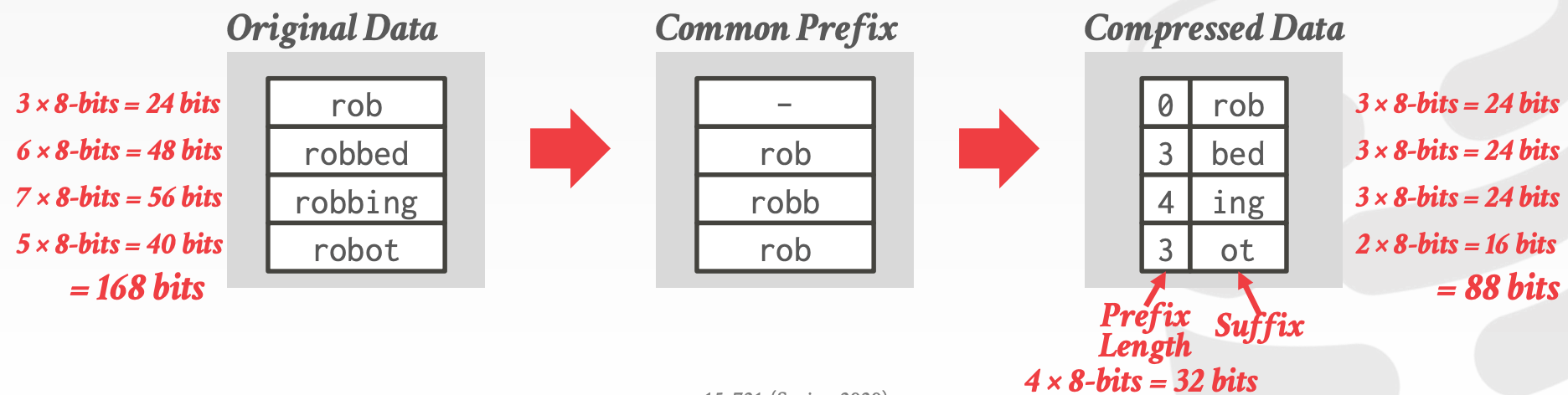
- 类似于
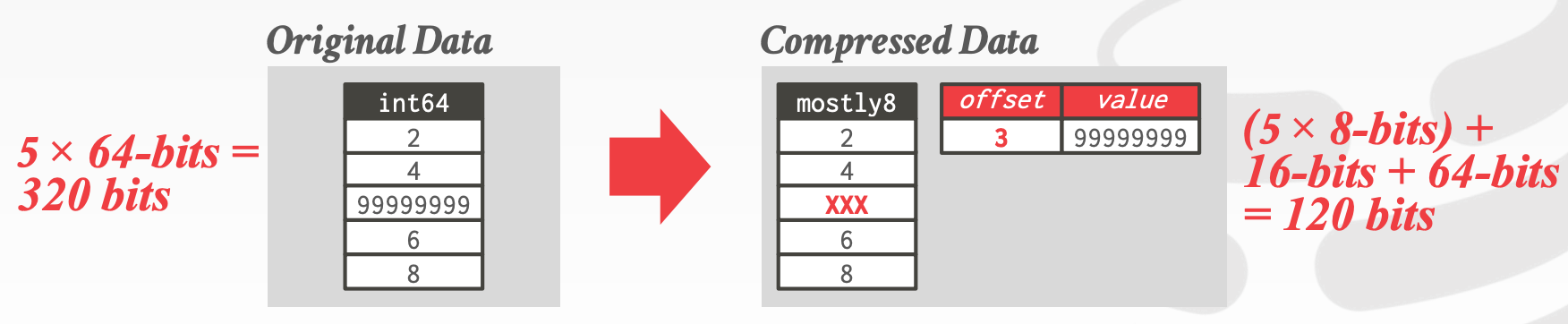
Mostly Encoding- 当大部分数据小于该类型的最大值时,可以用更小的类型来存储。剩下无法用更小类型存储的数据还是保留原先的类型
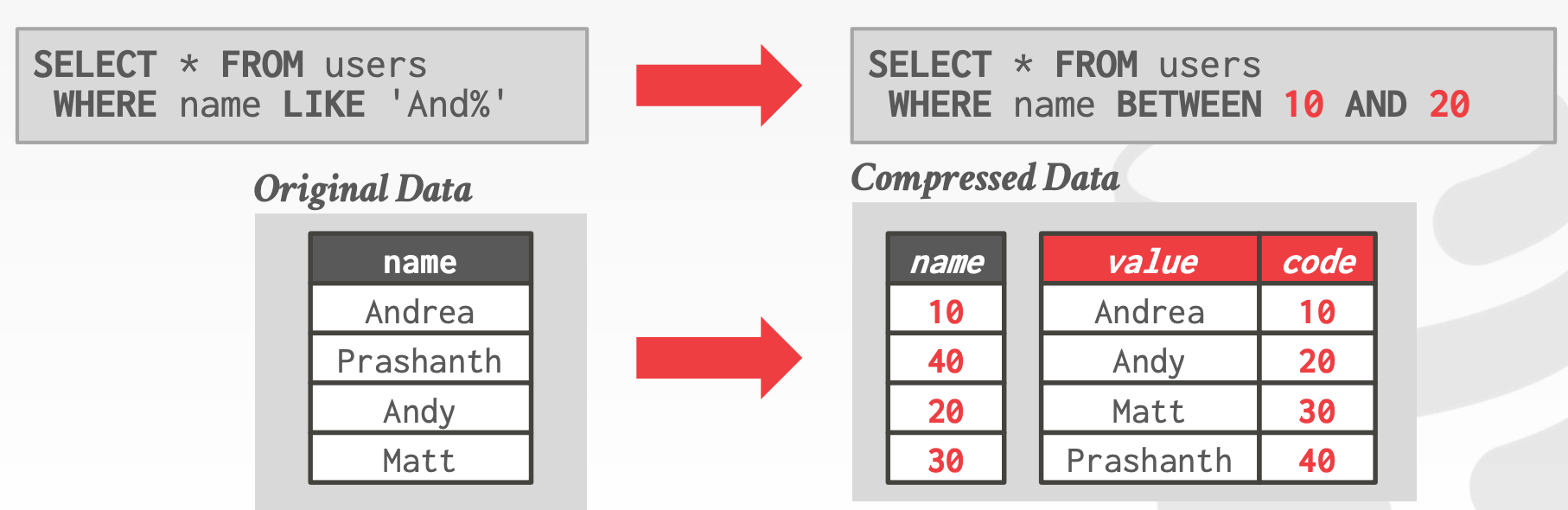
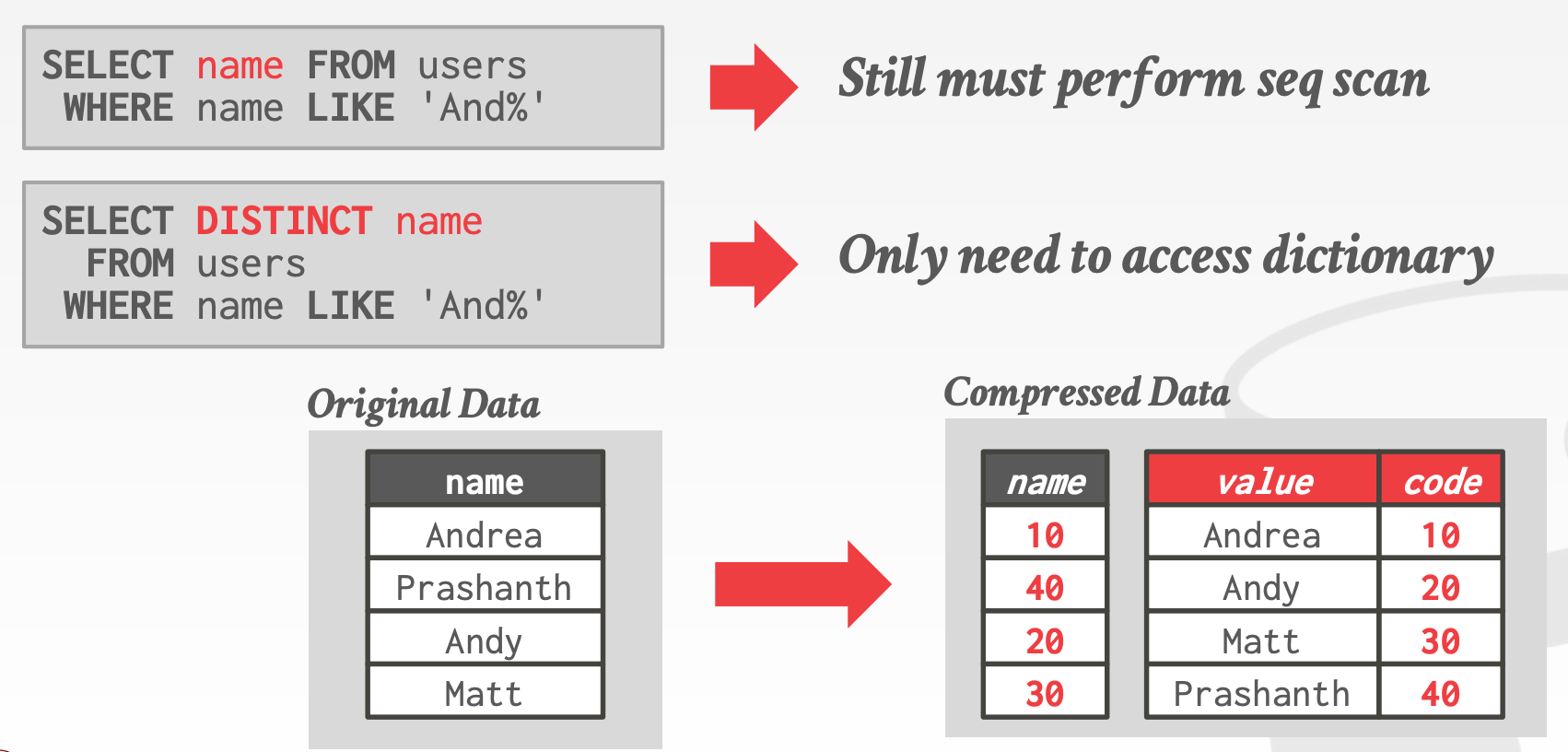
Dictionary Encoding- 何时构建字典
All At Once- 扫描所有数据,构建字典
- 对于新插入的数据,使用额外的字典,或者重新计算
Incremental- 将新插入的数据合并到已有的字典中
ScopeBlock-Level- 仅包含一个数据表中的部分数据
- 压缩率较低,更新效率高
Table-Level- 压缩率较高,更新效率低
Multi-Level- 可能包含多个表的部分数据或者全量数据
- 有时用于
Join操作
Multi-Aggribute Encoding- 字典可以横跨多个属性

Order-Preserving Encoding- 编码后的值要保持与原有值相同的顺序
Dictionary Data StructuresArray- 两个数组,一个数组包含变长的数据,另一个数组存储数据的偏移量
- 更新成本高
Hash Table- 快速,紧凑
- 不支持范围、前缀查找
B+ Tree- 比
Hash Table慢,且需要更多内存 - 支持范围、前缀查找
- 比
- 何时构建字典
9.4 OLTP Index Compression
OLTP无法使用OLAP的压缩技术,因为它需要支持Tuple的快速随机访问。即时进行压缩、解压缩操作会大大降低性能。同时,OLTP中的索引会占用很多内存资源
10 recovery
Recovery用于在发生故障时,确保数据库的原子性、一致性和持久性。它包含两个部分:
- 在事务正常进行时所执行的一系列操作(写
WAL日志),来确保DBMS能从故障中恢复 - 在
DBMS进入异常状态时锁执行的一系列恢复操作,用于保证数据库的原子性、一致性和持久性
异常在数据库中是非常常见的,它不光指机器崩溃,还可能是如下场景:
OS更新- 硬件更新
DBMS更新
10.1 Logging Schemes
日志方案:
Physical Logging- 直接记录更新的值
Logical Logging- 记录的是高层级的操作,比如
UPDATE、DELETE、INSERT等
- 记录的是高层级的操作,比如
刷新方式:
All-at-Once Flushing- 直到事务提交之前,才将日志刷到磁盘
Incremental Flushing- 允许在事务提交之前,将日志刷到磁盘
Early Lock Release:在事务的Commit Log刷入磁盘后,事务的锁便可以释放了,无需等到将结果传回客户端。因为从DBMS的视角来看,此时事务已经结束了
MSSQL Constant Time Recovery:属于Physical Logging,且直接将MVCC的Time-Travel表作为Recovery Log。因此无需再打印WAL
- 详细内容参考课件中的
12 ~ 21页
SILO,详细内容参考课件中的22 ~ 40页
10.2 Checkpoint Protocols
理想的Checkpoint应该具备以下特性:
- 不能影响正常事务的处理效率
- 不能引入较大的延迟
- 内存开销要小
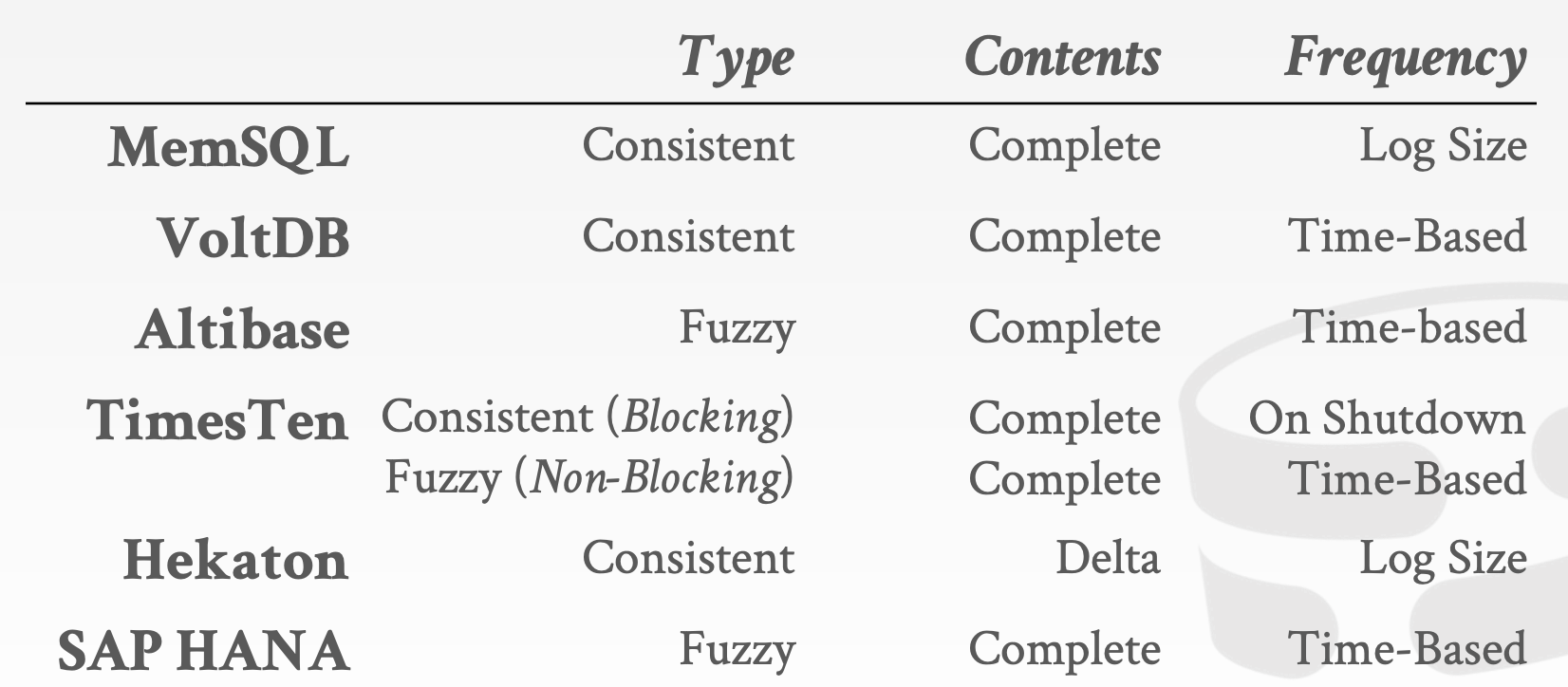
Consistent vs. Fuzzy Checkpoints
Consistent Checkpoints- 表示数据库在某个时间点的一致性快照。不包含未提交的更改
- 恢复时,无其他额外操作
Fuzzy Checkpoints- 会包含
Checkpoint启动后才提交的事务的更改 - 需要确保
Checkpoint包含上述已提交事务的更改
- 会包含
Checkpoint Mechanism
Do It Yourself- 同一个进程完成,可以利用
MVCC来确定快照
- 同一个进程完成,可以利用
OS Fork SnapshotsFork一个子进程,拷贝父进程的内存,因此子进程的内存中包含快照所需的所有内容- 需要额外的操作来除去那些未提交的记录(利用Undo Log)
Checkpoint Contents
Complete Checkpoint- 包含所有数据,包括从上个
Checkpoint以来未发生改变的Tuple
- 包含所有数据,包括从上个
Delta Checkpoint- 仅包含从上个
Checkpoint以来发生改变的Tuple - 在后台可以对多个
Checkpoint进行合并
- 仅包含从上个
Frequency
Time-basedLog File Size ThresholdOn Shutdown
10.3 Restart Protocols
Shared Memory Restarts:
Shared Memory HeapsCopy On Shutdown
11 networking
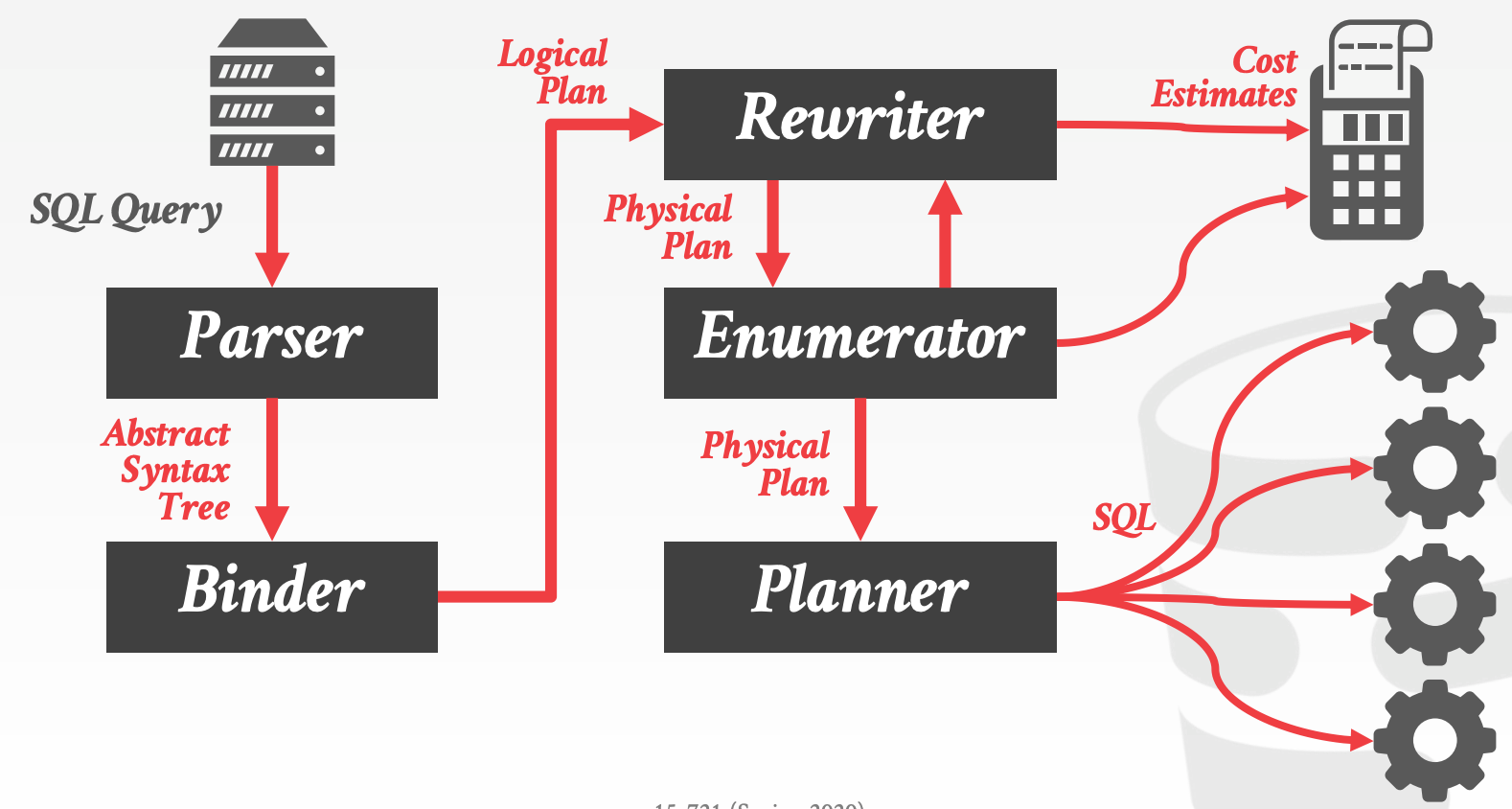
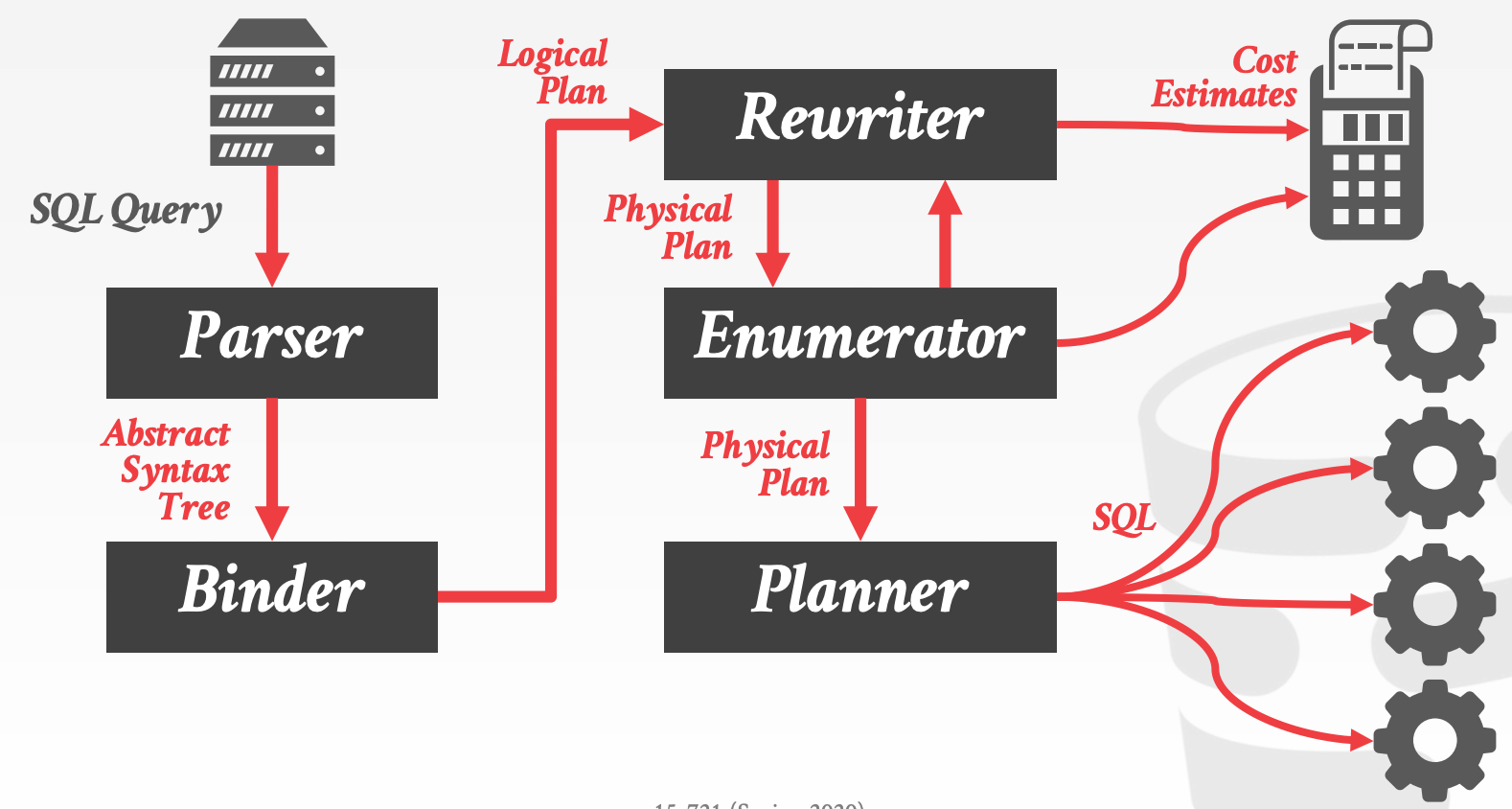
11.1 Database Access APIs
常见的API有如下几种:
Direct Access, DBMS-SpecificOpen Database Connectivity, ODBC- 与
OS和具体的DBMS解耦,几乎每种主流的DBMS都会有ODBC的实现 ODBC的设计采用了Device Driver的模型,其中Driver封装了将标准Standard-API转换成DBMS-Specific-API的逻辑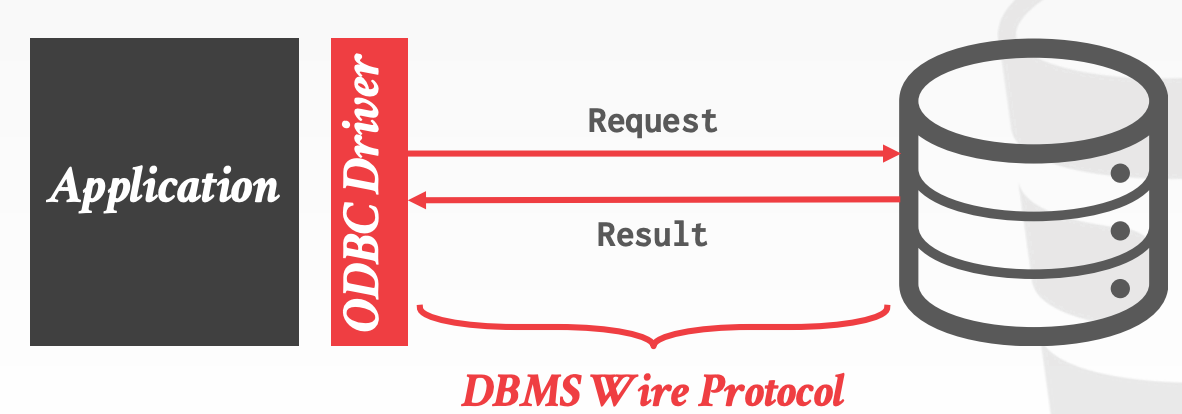
- 与
Java Database Connectivity, JDBC- 可以理解成是
ODBC的一个版本,只不过针对的是Java语言而不是C语言
- 可以理解成是
11.2 Database Network Protocols
几乎所有主流的DBMS都基于TCP/IP实现了一套通信协议,标准的C/S交互流程如下:
Client连接到DBMS,进行鉴权流程Client发送一个QueryDMBS解析并执行Query,然后将结果序列化后返回给Client
协议设计要点:
Row vs. Column LayoutODBC和JDBC是典型的Row-Oriented
CompressionNaive CompressionColumnar-Specific Encoding
Data SerializationBinary Encoding- 客户端需要进行额外的字节序列的转换
- 序列化后体积小
- 可以基于现有的框架来实现,比如
ProtoBuffers、Thrift、FlatBuffers等
Text Encoding- 将所有类型都转换成
String - 序列化后体积大
- 客户端反序列化简单
- 将所有类型都转换成
String handlingNull Termination:在末尾加\0,表示String的结束Length-Prefixes:在Header中增加长度信息Fixed Width:所有String长度固定,不足需要补白
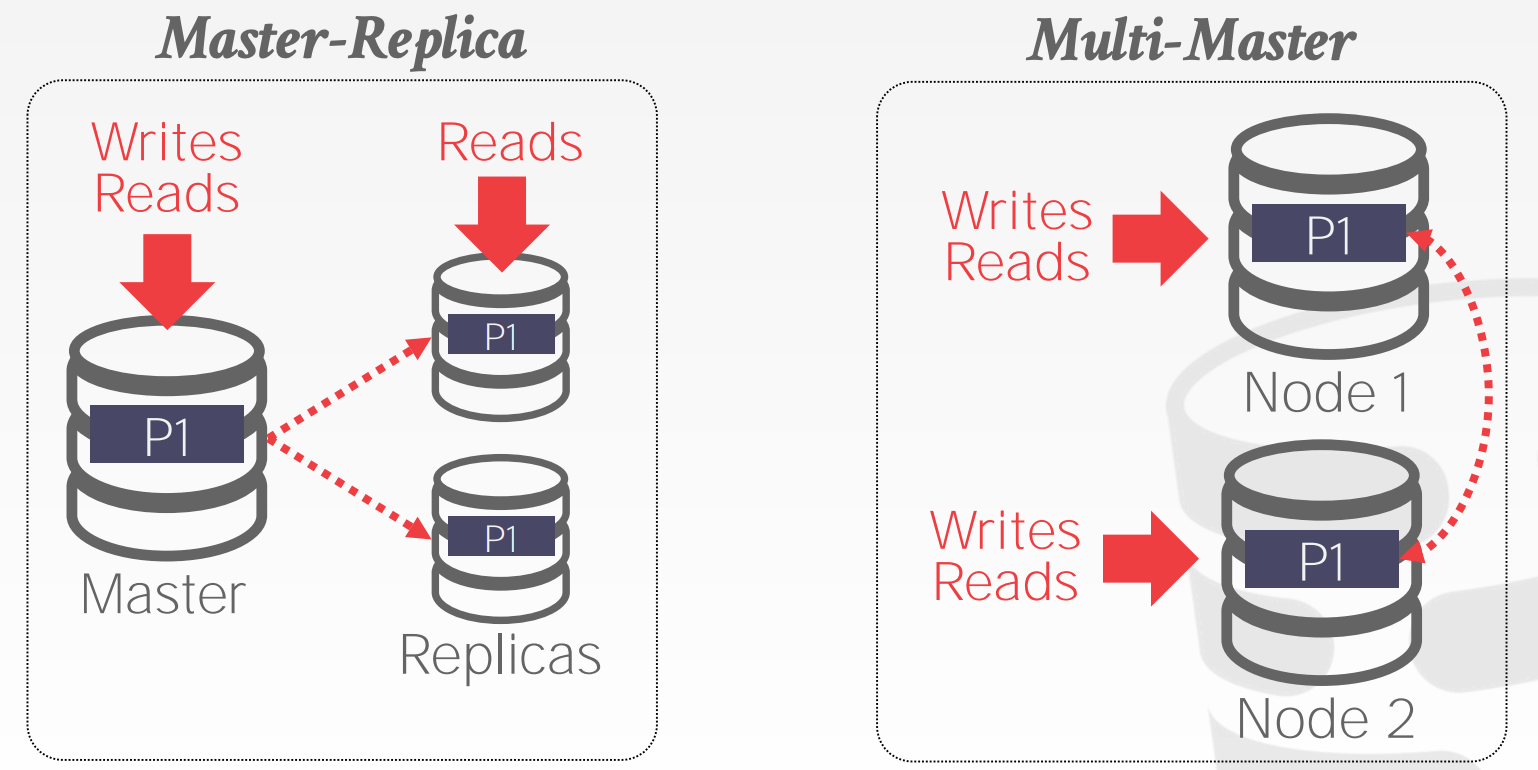
11.3 Replication Protocols
DBMS会通过网络同步各个节点之间的数据,用以提升集群的可用性
设计要点:
Replica ConfigurationMaster-Replica- 所有更新必须经过
Master节点 Master节点会将更新同步给其他Replica节点Read-Only的事务可以访问Replica节点Master如果宕机了,那么会重新选举出一个Master
- 所有更新必须经过
Multi-Master- 所有节点均支持数据更新
- 节点之间的数据同步需要使用
Atomic Commit Protocol
Propagation Scheme:当事务提交时,DBMS需要决定是否需要等到该事务的变更都同步到其他节点后,才通知客户端事务已完成Synchronous:强一致性Asynchronous:最终一致性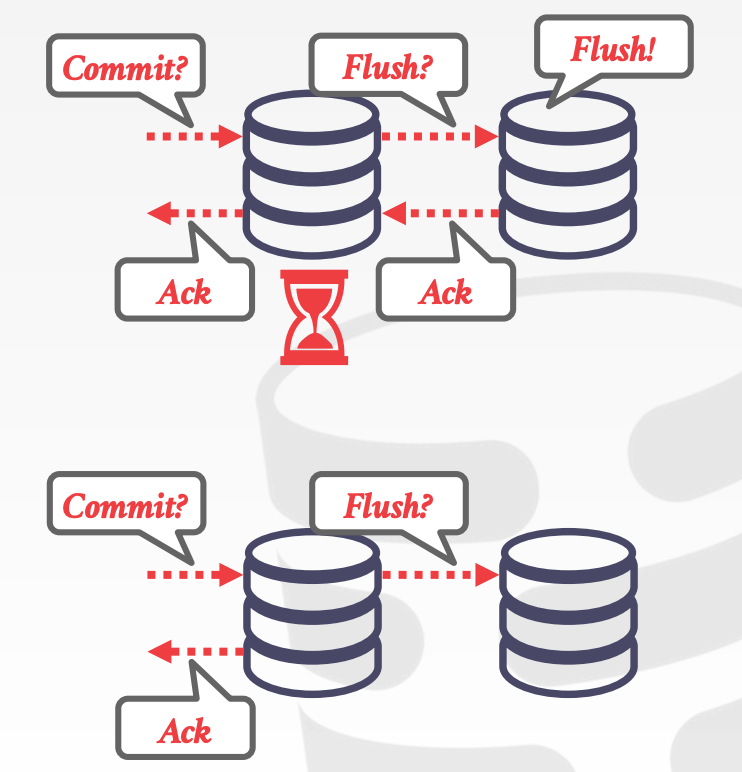
11.4 Kernel Bypass Methods
网络通信协议的实现并不是降低系统效率的唯一原因。TCP/IP协议栈本身也是原因之一,比如:
- 上下文切换、中断的开销
- 数据拷贝(内核空间和内核空间)
- 内核中大量的
Latches
Kernel Bypass Methods允许DBMS直接从Network Interface Card, NIC中获取数据
- 没有数据拷贝
- 没有
TCP/IP协议栈
Kernel Bypass Methods的实现方式有如下两种:
Data Plane Development KitRemote Direct Memory Access- 直接读写远程主机的内存,必须知道正确的地址
DBMS本身不感知这个过程
12 scheduling
对于每个查询计划,DBMS必须决定何时、何地、以及如何执行
12.1 Process Models
Process Models有以下三种
Process per DBMS Worker- 每个
Worker都是一个进程,且依赖操作系统的进程调度 - 使用共享内存来共享一些全局资源
- 一个进程挂了不影响整个系统
IBM DB2、Postgres、Oracle
- 每个
Process Pool- 维护一个进程池,当有查询时,随机挑选一个空闲的进程来进行计算
- 仍然依赖操作系统调度以及共享内存
CPU Cache不友好IBM DB2、Postgres(2015)
Thread per DBMS Worker- 维护一个线程池,
DBMS需要管理调度 - 线程挂了会导致整个系统崩溃
IBM DB2、MSSQL、MySQL、Oracle(2014)
- 维护一个线程池,
12.2 Data Placement
调度器必须感知硬件的内存布局
Uniform Memory Access, UMANon-Uniform Memory Access, NUMA
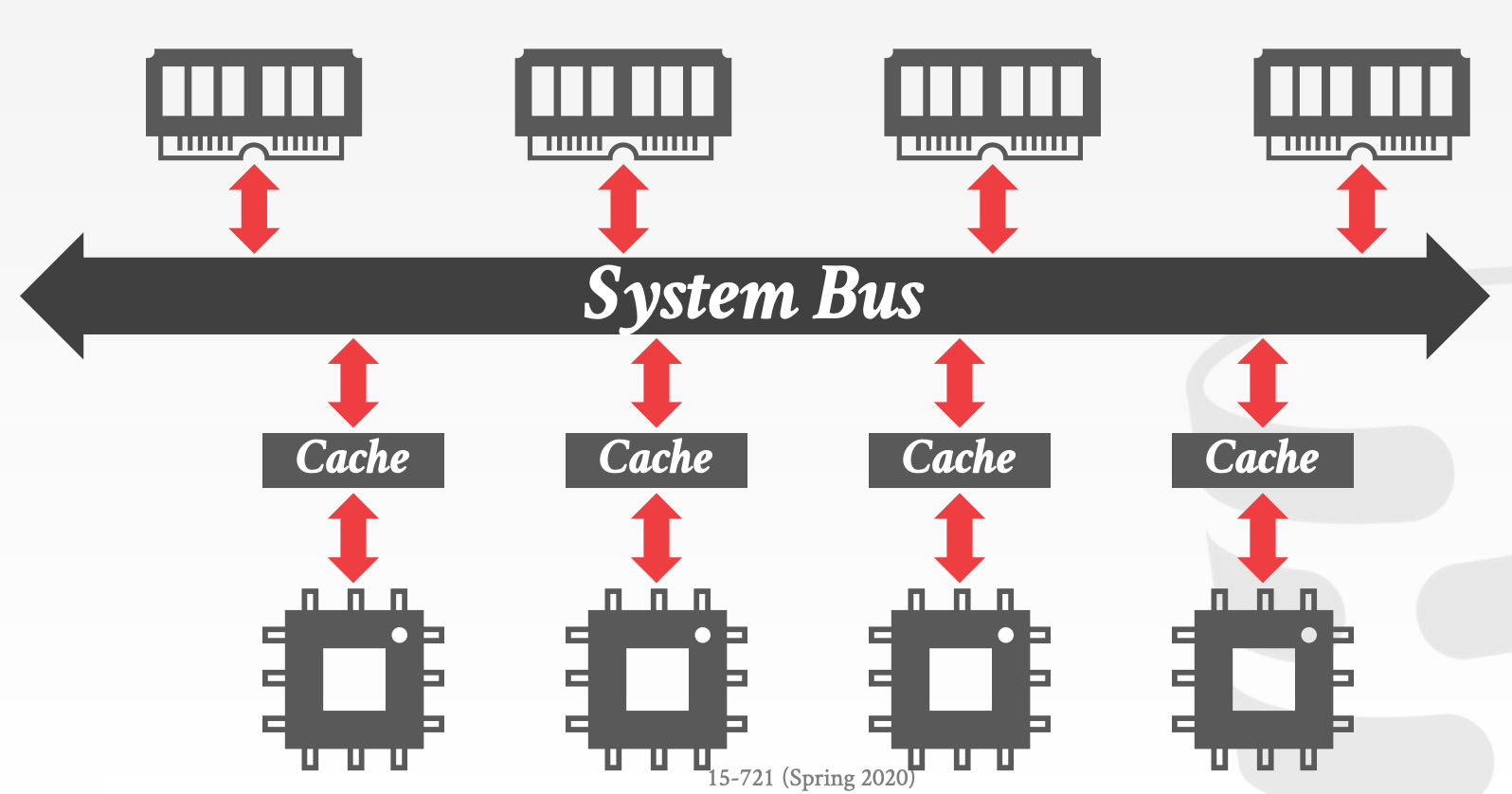
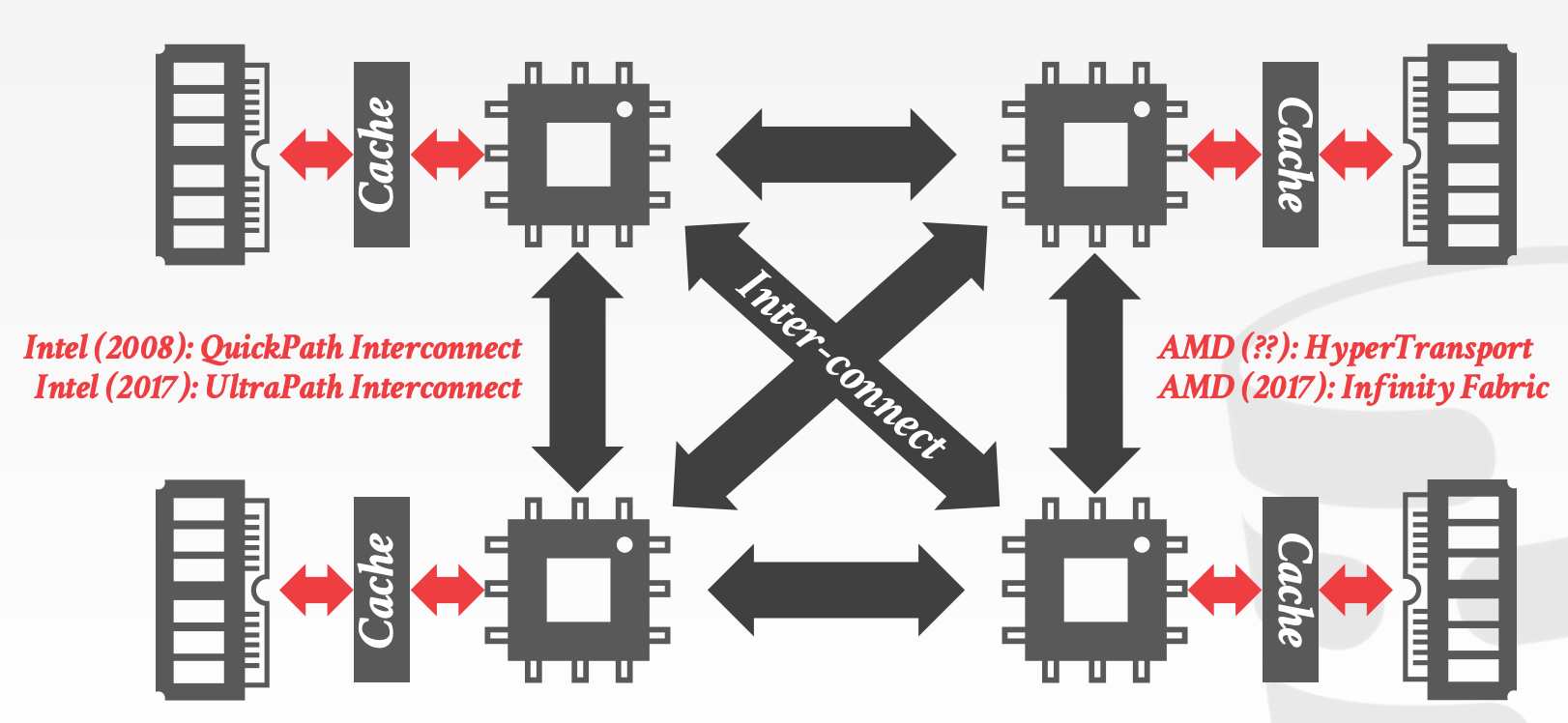
DBMS可以将内存分区,并将每个分区分配给一个CPU。通过控制和跟踪分区的位置,将算子调度到最近的CPU上执行
Memory Allocation Location
Interleaving:跨CPU均匀分布内存First-Touch:在CPU第一次访问该内存时(Page Fault)- 操作系统可以根据其观测到的访问模式,将内存移动到另一个
NUMA Region
12.3 Scheduling
Static Scheduling- 在生成查询计划时就决定使用多少个线程,且在执行过程中,不会发生改变
Morsel-Driven Scheduling:Task中数据对应的内存,分为多个区域(称为Morsel),分布在不同核上- 每个
Worker一个核(如何绑核) Pull-Based Task AssignmentRound-Robin Data Placement
- 每个
Hyper-Architecture:Worker使用队列来协助调度Worker会尽量选择那些本地的Task来执行(Cache Locality,尽量保证Task在同一个核上执行)- 当没有本地的
Task时,尝试从全局的队列中获取Task来执行(stealing) 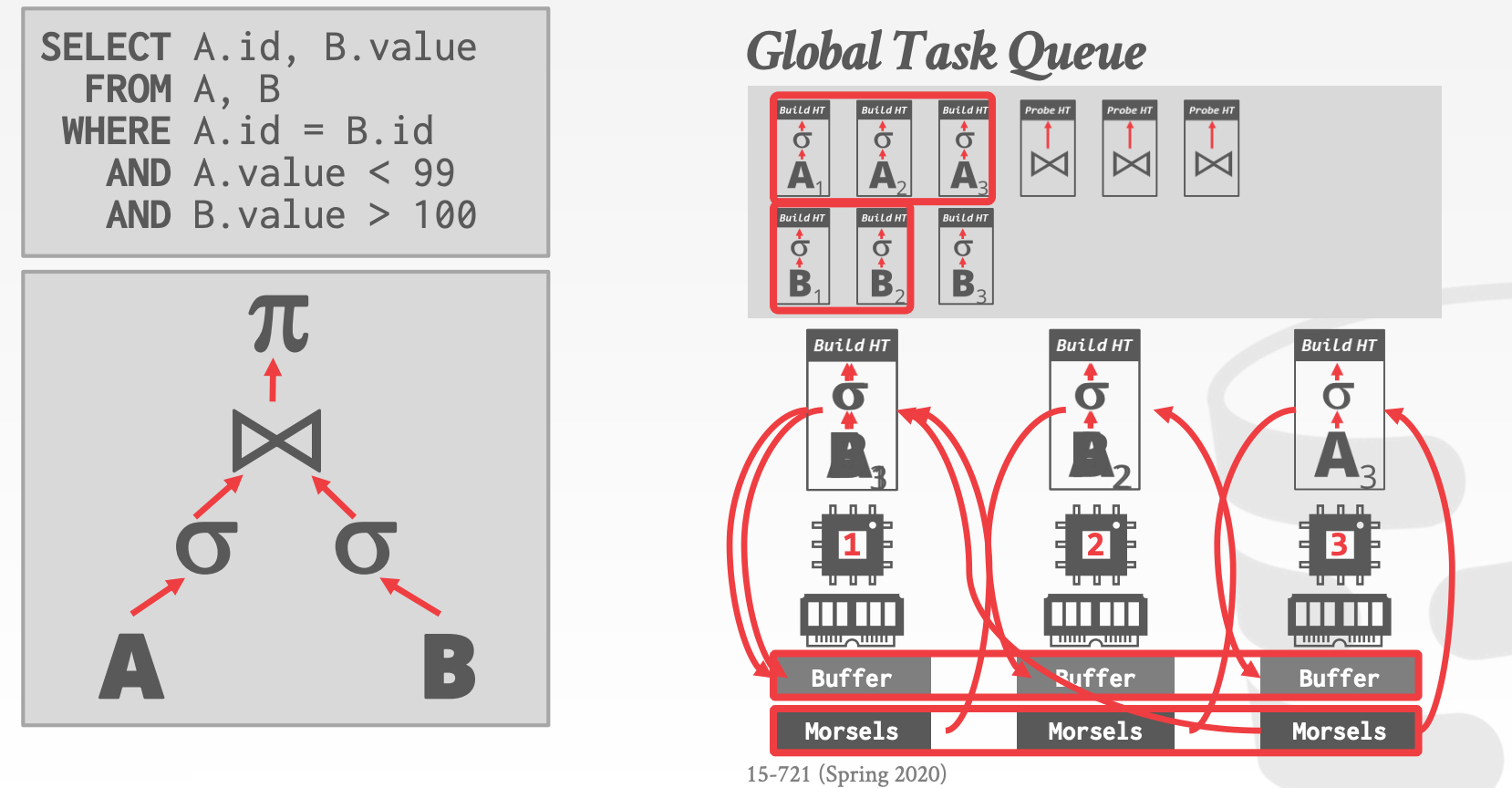
SAP HANA - NUMA-Aware Scheduler
- 线程组(
Group)- 每个
Group包含多个线程池(Pools)Working:正在执行TaskInactive:阻塞中Free:短暂地休眠后会查看是否可以获取新的TaskParked:休眠,等待操作系统唤醒
- 每个
- 每个
CPU可以拥有多个Group - 每个
Group需要有优先级队列(Hard、Soft)- 线程可以从其他
Group中的Sort队列中窃取任务
- 线程可以从其他
- 一个额外的
Watchdog Thread,用于监测Group的饱和度,并且可以动态分配任务 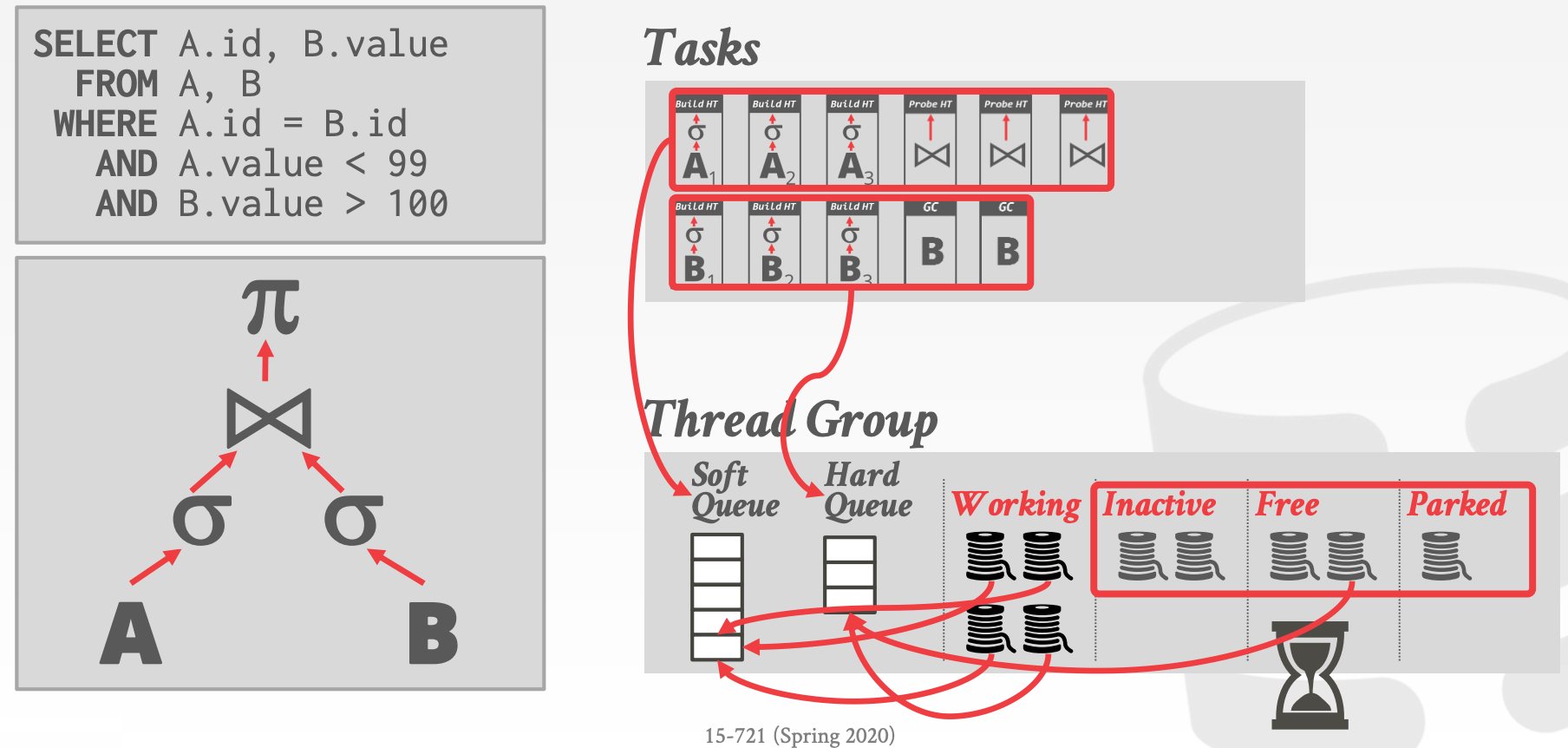
当请求到达的速度比DBMS执行的速度更快时,系统就超载了(Overload)
CPU Bound:执行非常慢Memory Bound:OOM
如何解决超载问题
Admission Control:终止新的请求Throttling:放慢响应速度
13 execution
- Query Plan Processing
- Scan Sharing
- Materialized Views
- Query Compilation
- Vectorized Operators
- Parallel Algorithms
- Application Logic Executions
13.1 System Architecture
CPU以流水线的方式执行指令,目的是充分利用CPU的每个时钟周期。部分CPU甚至可以包含多条流水线,只要指令之间无相互依赖,就可以并行执行。部分情况会导致流水线停顿,比如:
Dependencies:指令之间相互依赖,指令A依赖指令B的结果Branch Prediction:分支预测,当预测错误时,就需要回退,并重新执行另一个分支
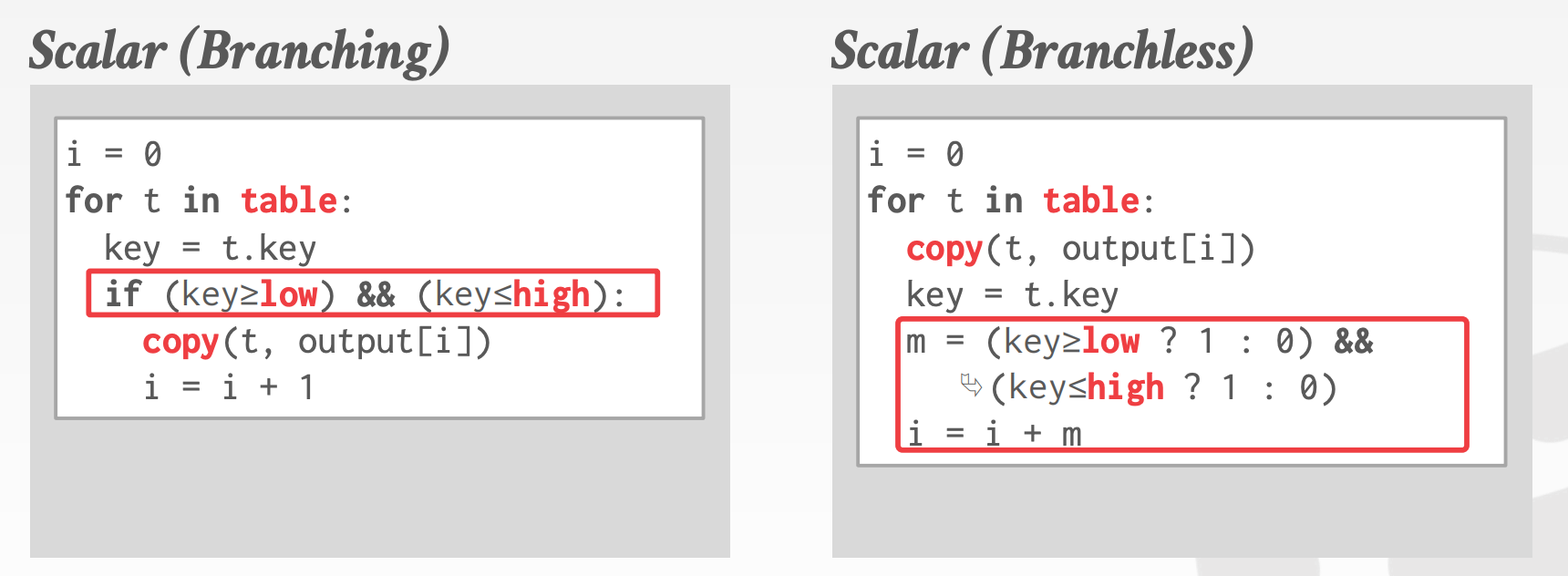
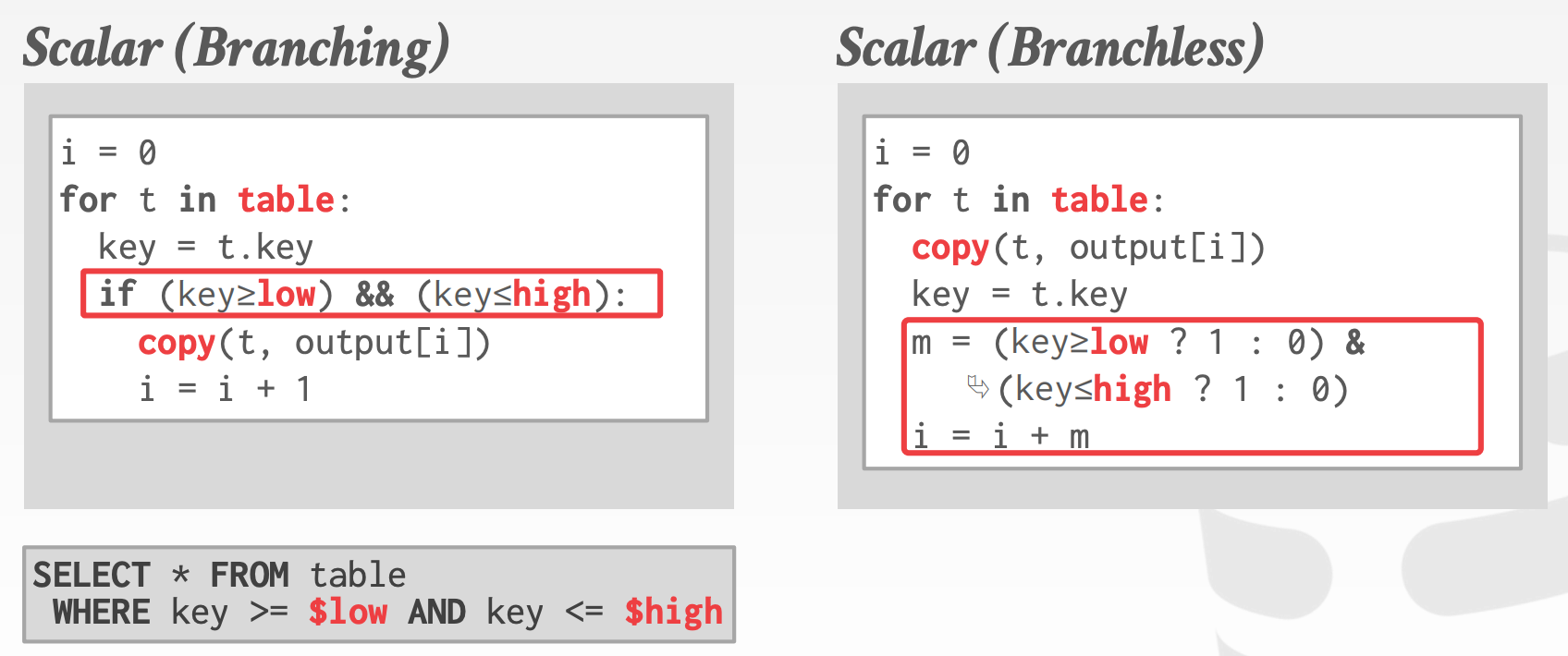
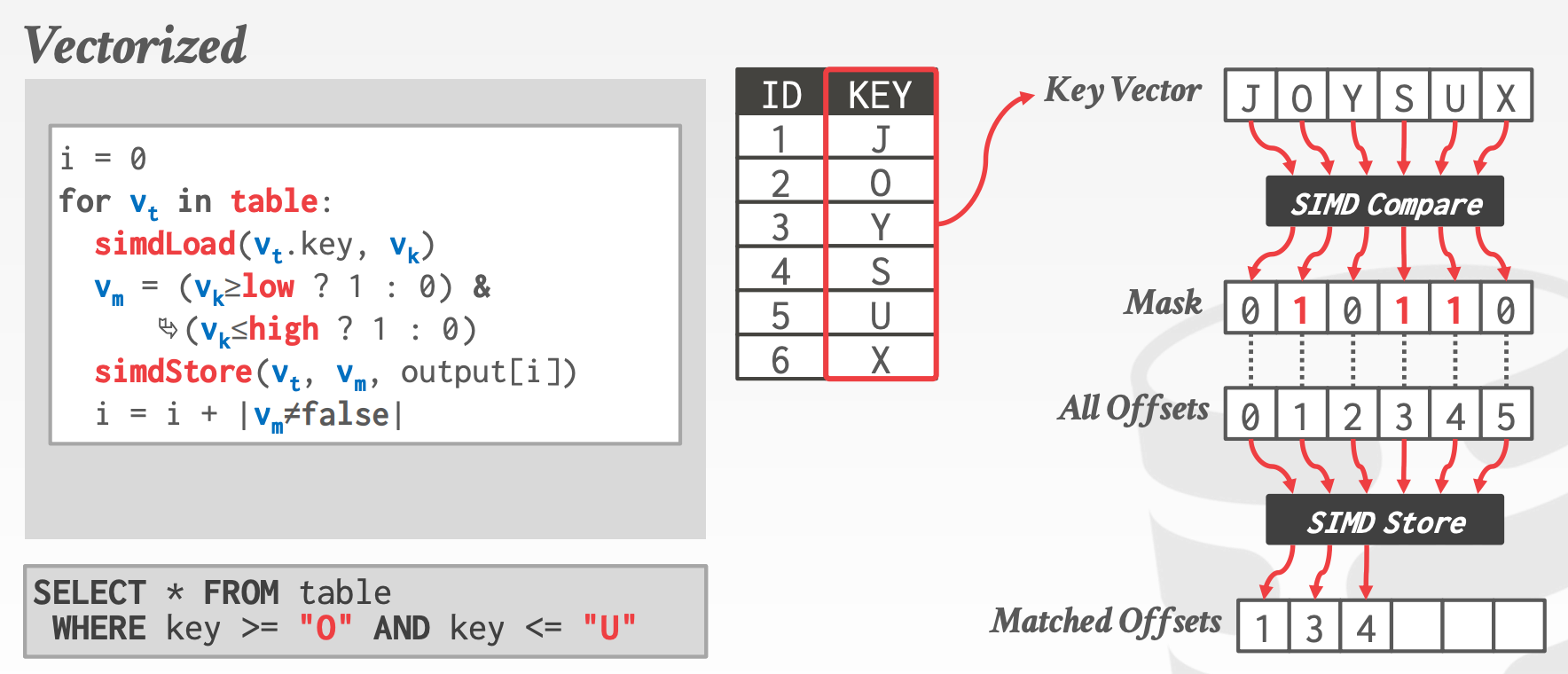
对于分支预测来说,有两个典型的场景
-
Selection Scan1
2
3SELECT * FROM table
WHERE key >= $(low)
AND key <= $(high) -
Multi-Data Types:DBMS需要支持多种类型,因此在执行操作前必须对每个类型进行校验,这就会引入非常巨大的switch语句,进一步降低CPU对分支预测的准确性
13.2 Processing Models
13.2.1 Iterator Model
特征:每个算子都实现了next方法
- 每次迭代,算子都返回一个
Tuple或者空值 - 算子会先通过循环调用孩子算子的
next获取输入 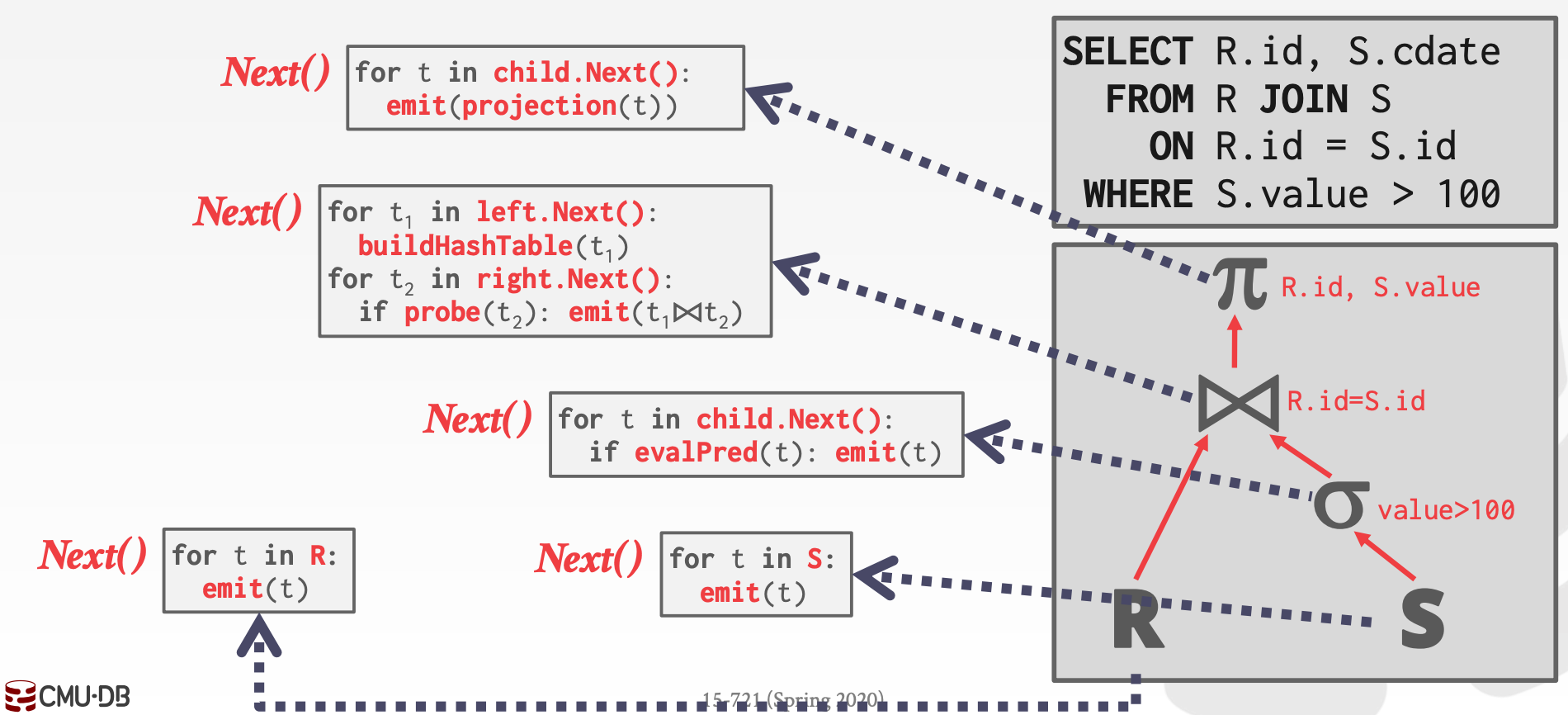
13.2.2 Materialization Model
特征:all-at-once,即算子一次性处理所有的输入,并一次性返回所有的结果
- 函数调用次数少
- 输出可以是完整的
Tuple(NSM),或者仅包含部分列(DSM) - 对
OLTP友好,对OLAP不友好 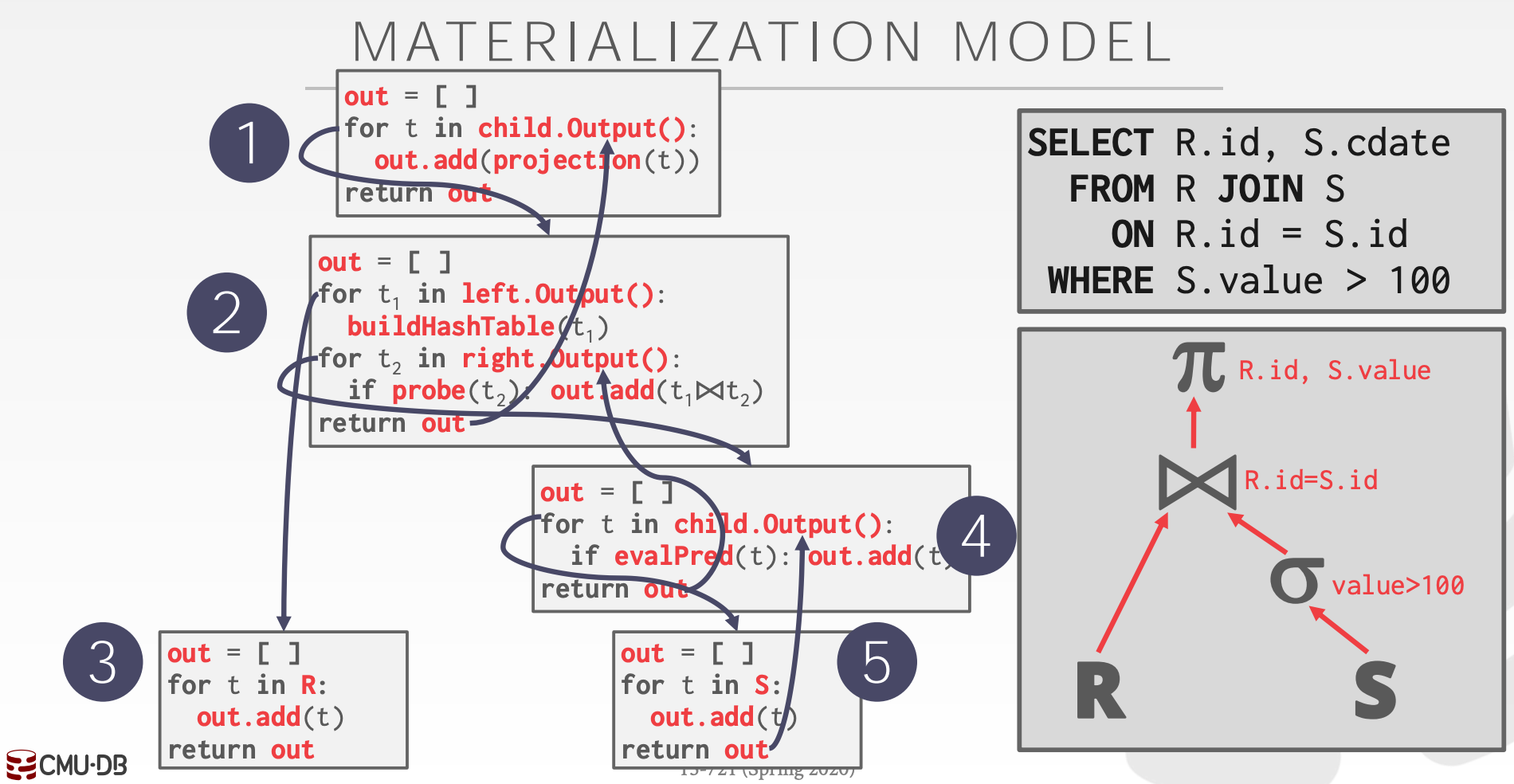
13.2.3 Vectorized / Batch Model
类似于Iterator Model,每个算子都实现了next方法,但区别是每次返回的是一批Tuple而不是一个Tuple
- 算子需要在内部实现一个循环遍历每批
Tuple - 批的大小取决于硬件(
Cache) - 对
OLAP友好,可以大幅降低函数调用次数,且可以使用SIMD指令加速处理 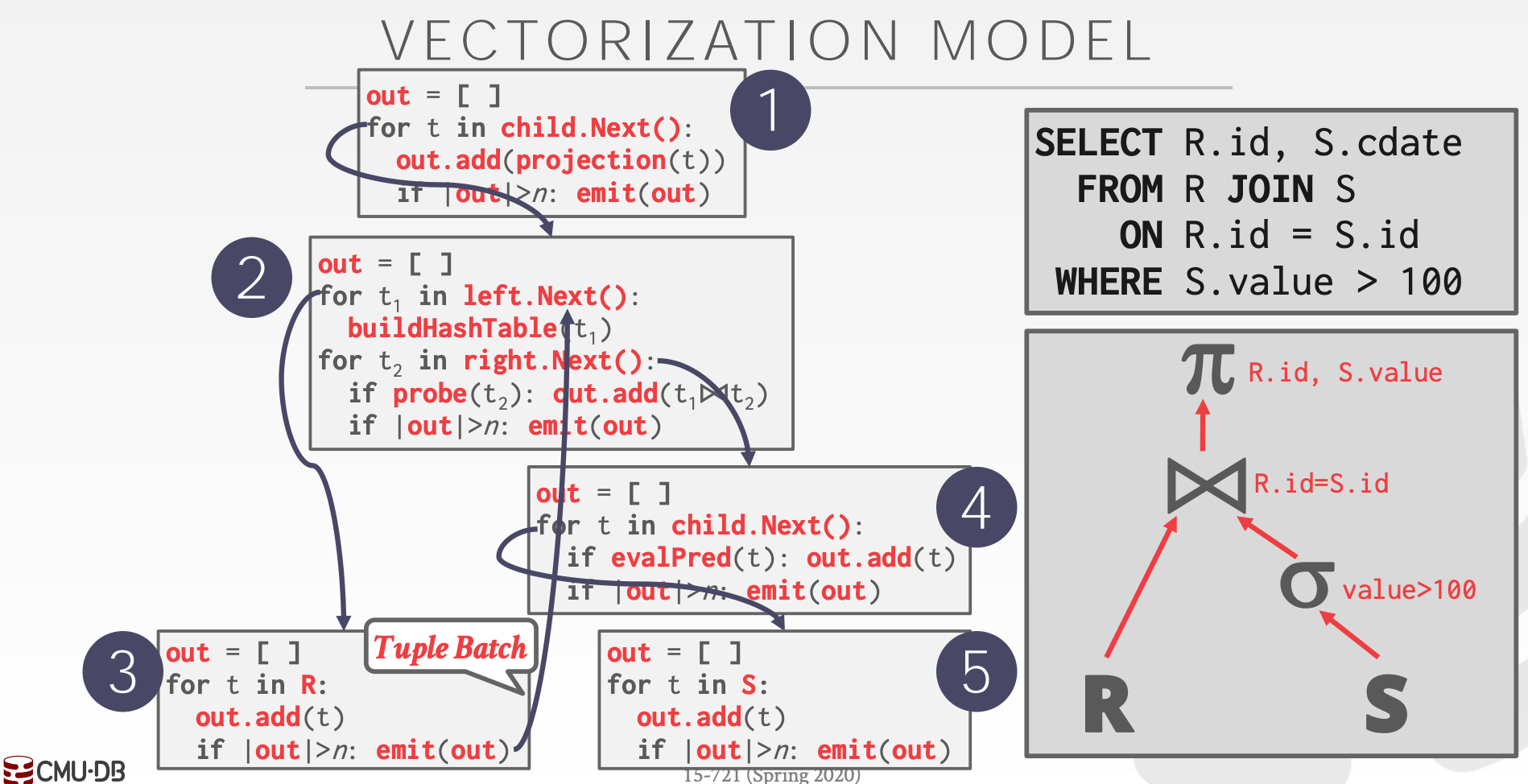
13.3 Parallel Execution
执行方向有两种:
Top-to-Bottom:从根节点开始,依次从孩子节点pull数据Bottom-to-Top:从叶节点开始,依次向父节点push数据- Allows for tighter control of caches/registers in pipelines.
通常,我们可以通过并发执行来提高整体的执行效率。且并行执行的实现难易程度与Process Model相关性不大,即比较独立
Intra-Query-ParallelismIntra-Operator- 算子实例化多份,每个实例分别处理不同的数据集
- 有时需要插入
Exchange算子来合并多路输入 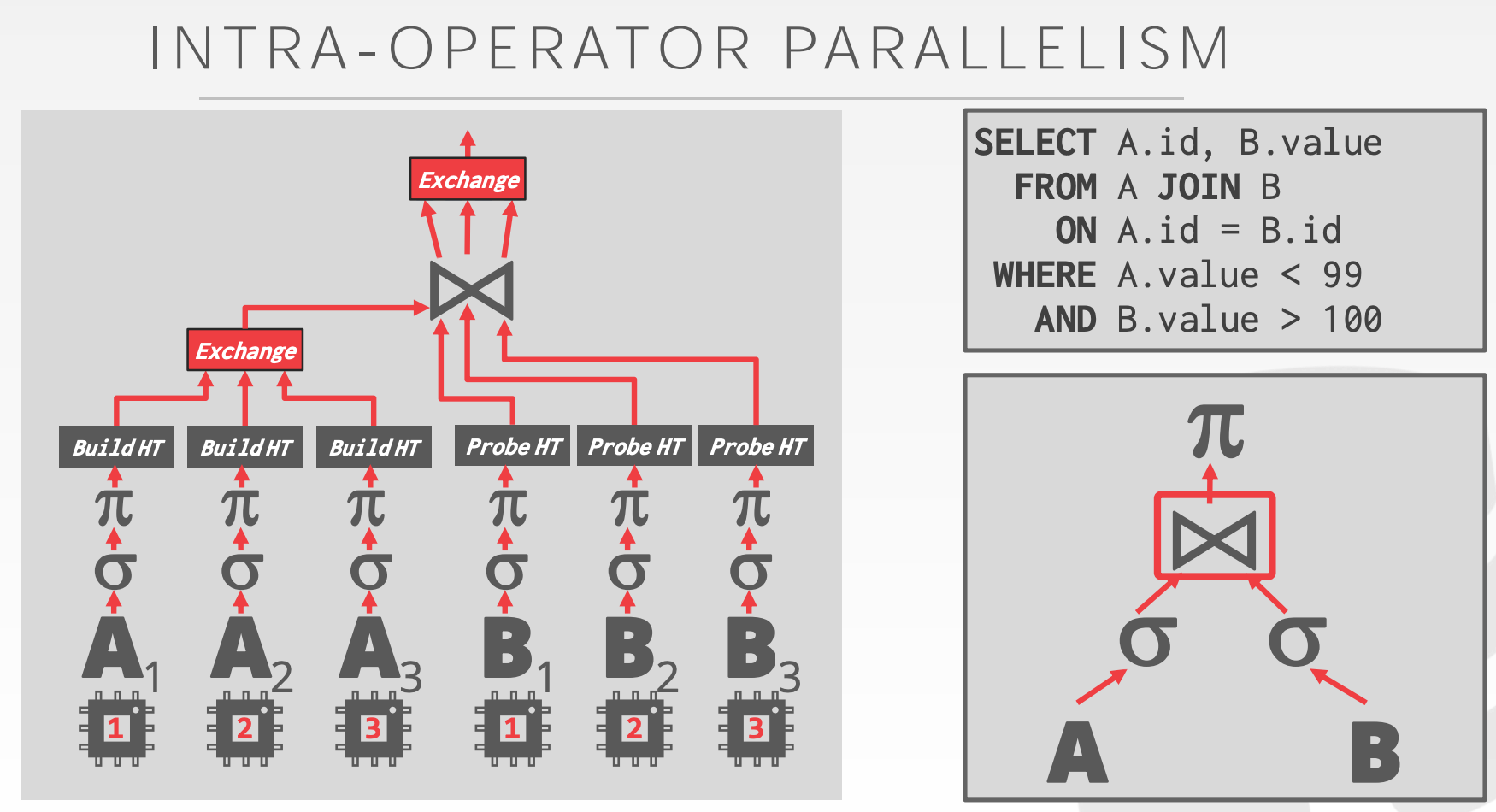
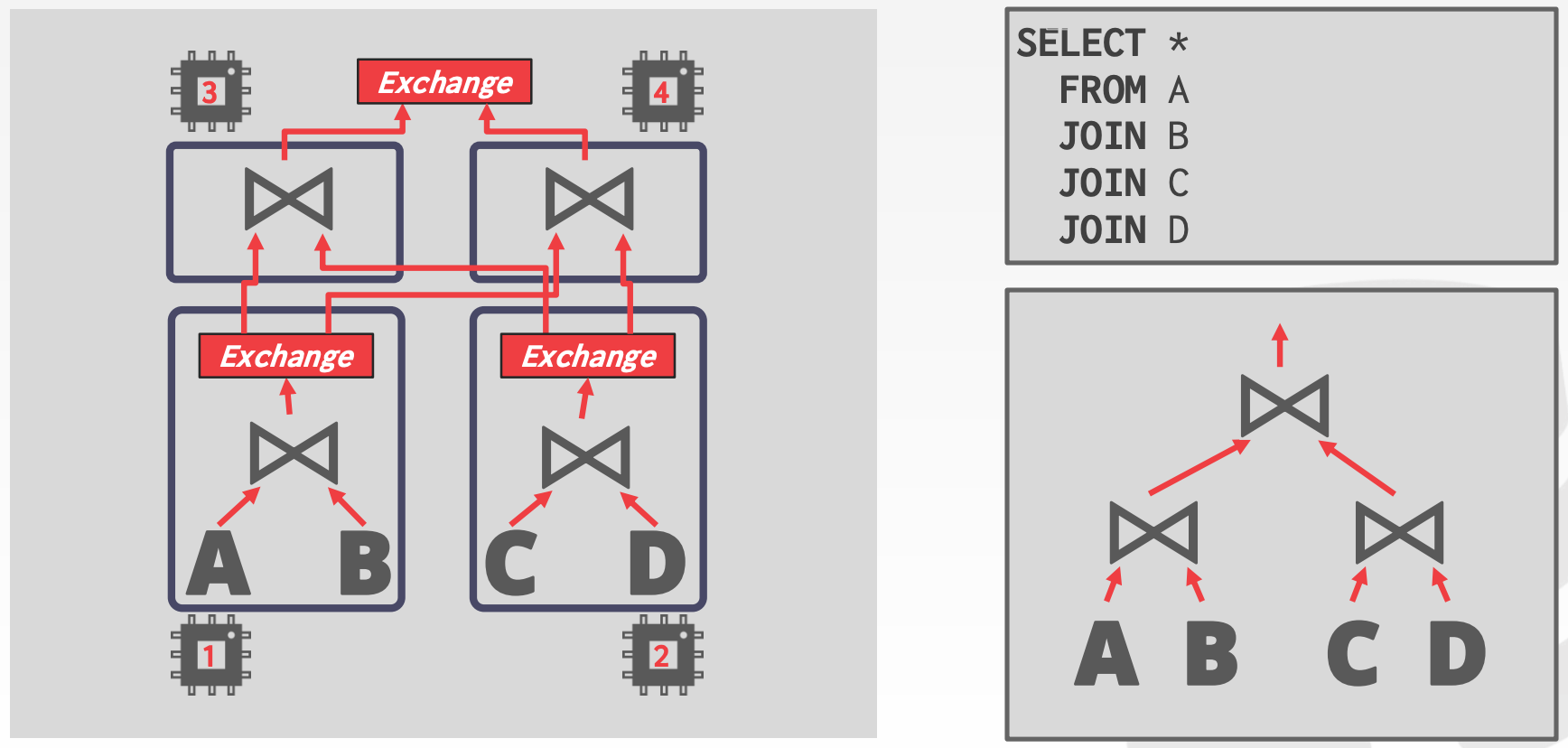
Inter-Operator
并行度的设置与CPU核数、数据大小、算子实现都相关
One Worker per Core- 工作线程与
Core绑定 - 线程不可阻塞,因为无其他线程可用
- 工作线程与
Multiple Worders per Core- 每个核关联一个线程池
- 线程可以阻塞
14 compilation
14.1 Background
如果仅考虑内存数据库,那么提升数据库的性能的唯一方式就是减少执行的指令数量
一种可以显著减少指令数量的方法叫做:Code Specialization,比如为某个查询生成特定的高效代码。绝大部分的代码都必须首先保证易读,其次再考虑性能
14.2 Gode Generation
Code Generation的两种方式
Transpilation:将查询计划翻译成某种语言的源码,然后使用该语言的编译器编译成本地代码JIT Compilation:生成代码的中间表示Intermediate Representation, IR,例如Java的.class文件、LLVM IR,然后在运行时生成本地代码
14.3 Real-Word Implementations

15 vectorization1
15.1 Background
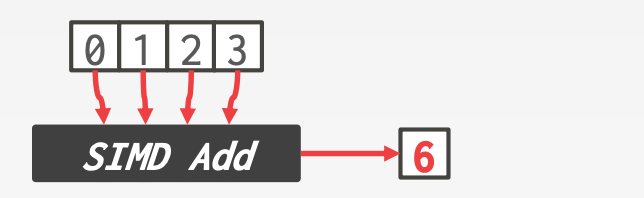
向量化指的是一次处理一组数据,需要借助Single Instruction Multiple Data, SIMD指令
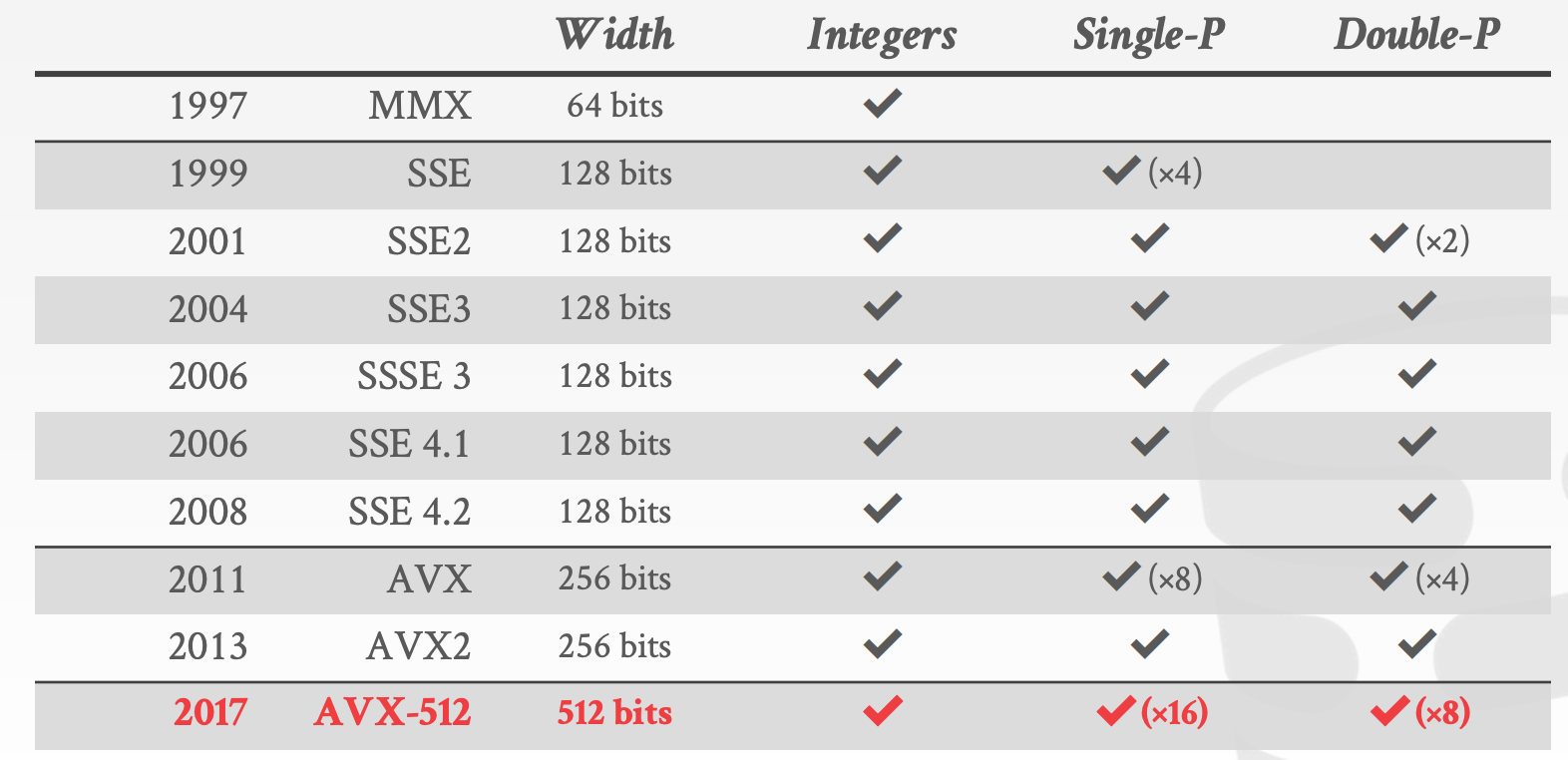
x86:MMX/SSE/SSE2/SSE3/SSE4/AVX/AVX2/AVX512PowerPC:AltivecARM:NEON/SVE- 数据可以绕过
CPU Cache直接从SIMD Registers写入内存 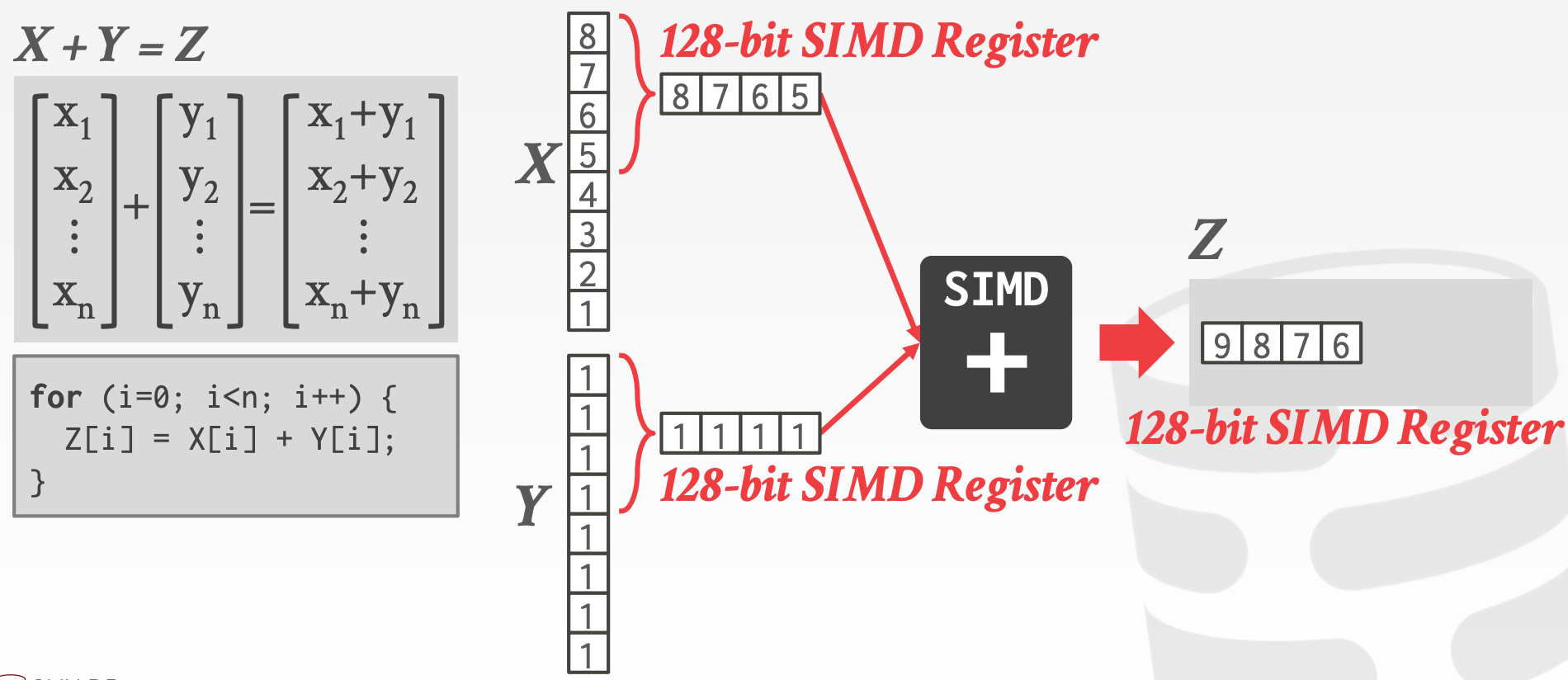
SIMD的优劣势:
- 优势:
- 成倍提升程序性能
- 劣势:
- 编写
SIMD程序比较繁琐(现在编译器可以帮你完成这个工作) - 要求数据严格对齐
- 将数据放入
SIMD Registers或者将数据从SIMD Registers放回对应的内存地址中这一过程比较tricky或者低效
- 编写
15.2 Vectorization
向量化的方式有如下三种:
Automatic Vectorization- 编译器可以自动判断位于一个循环内的指令是否能替换成
SIMD指令 - 无法对存在
Pointer Aliasing的代码进行向量化
- 编译器可以自动判断位于一个循环内的指令是否能替换成
Compiler Hints- 提供额外的信息让编译器进行向量化
- 比如,用
__restrict关键词或者#pragma ivdep可以消除Pointer Aliasing
Explicit Vectorization- 手动编写向量化代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
void add(int32_t* a, int32_t* b, int32_t* res, int32_t size) {
__m128i* vec_a = (__m128i*)a;
__m128i* vec_b = (__m128i*)b;
__m128i* vec_res = (__m128i*)res;
for (int i = 0; i < size / 4; i++) {
_mm_store_si128(vec_res++, _mm_add_epi32(*vec_a++, *vec_b++));
}
}
constexpr int32_t SIZE = 100;
int main() {
int32_t a[SIZE];
int32_t b[SIZE];
int32_t res[SIZE];
for (int i = 0; i < SIZE; i++) {
a[i] = i;
b[i] = SIZE - i;
}
add(a, b, res, SIZE);
for (auto i = 0; i < SIZE; i++) {
std::cout << i << ": " << res[i] << std::endl;
}
return 0;
}
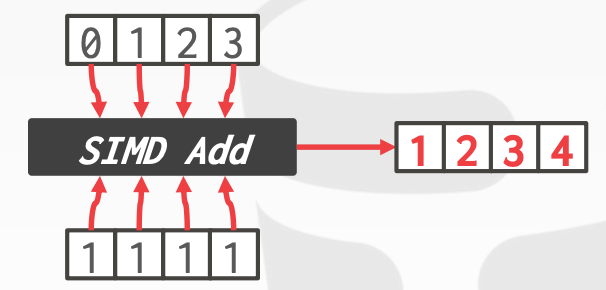
Vectorization Direction:
HorizontalVertical
15.3 Vectorized Algorithms
向量化算法是指更好地利用向量化操作来实现高级功能的方法和原则
Vertical Vectorization,要能处理不同的输入数据Maximum Lane utilization,向量寄存器中尽量填放更多的数据
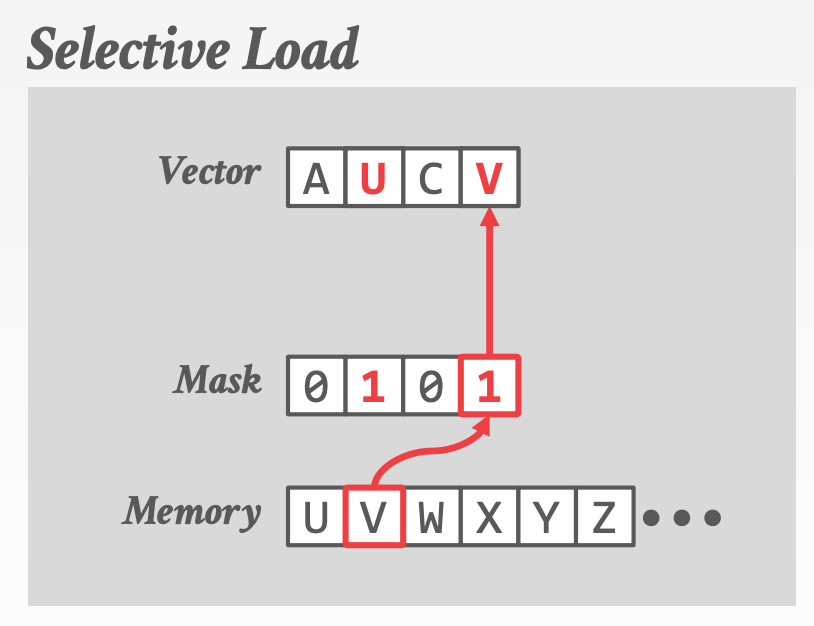
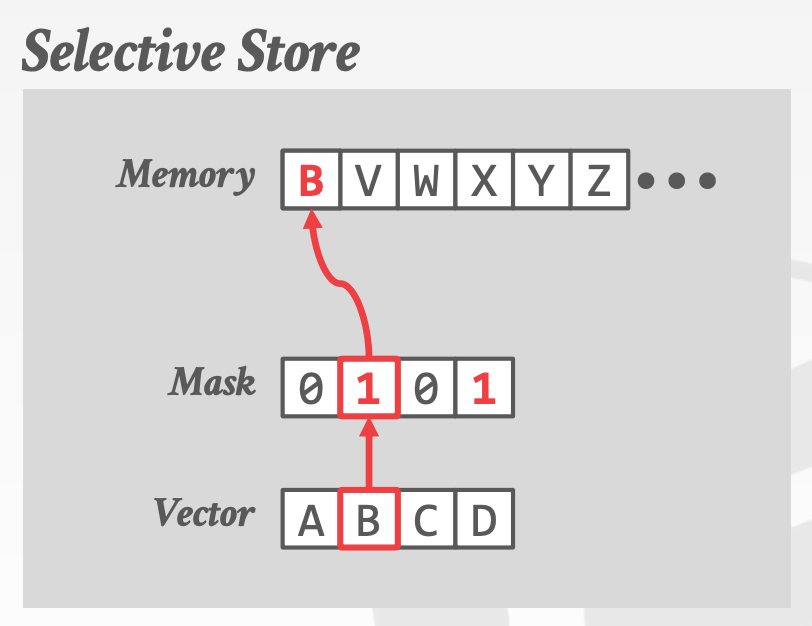
Fundamental Operations
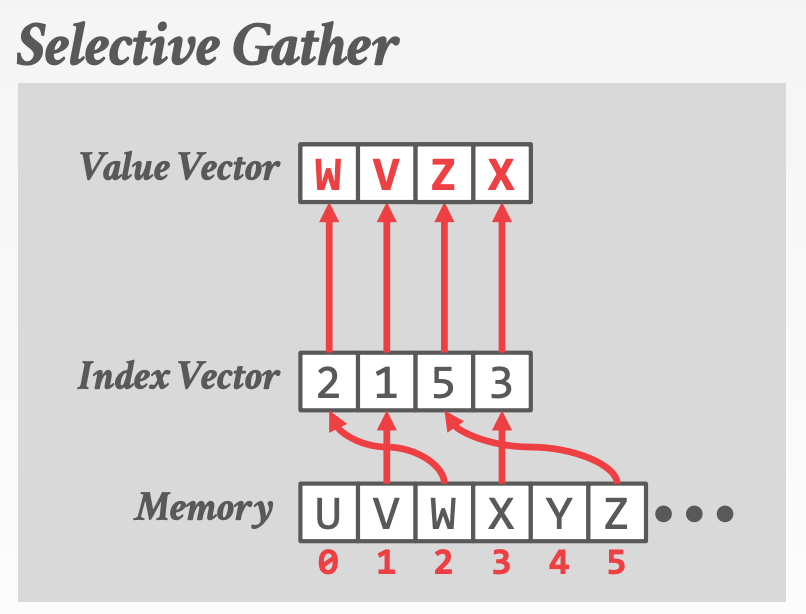
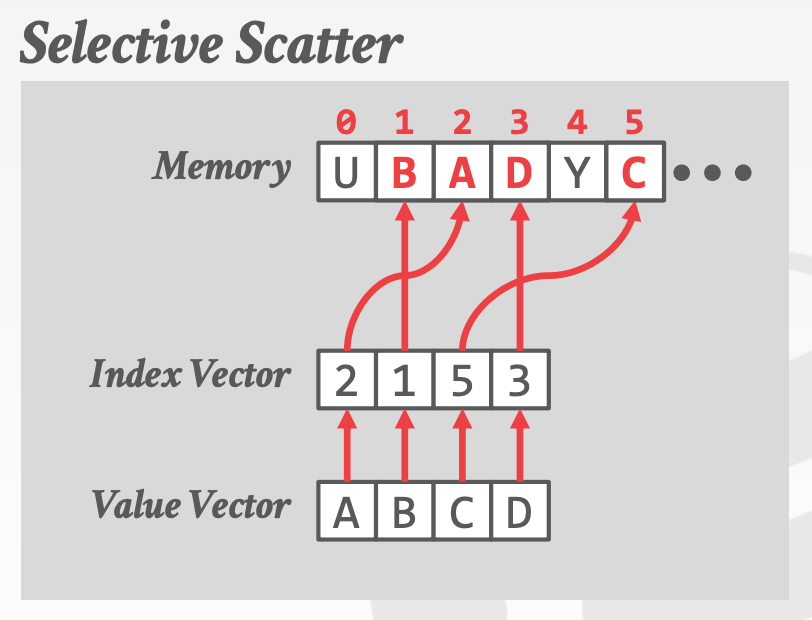
Selective LoadSelective StoreSelective GatherSelective Scatter- 注意,在当前的体系结构中,
Selective Gather和Selective Scatter可能无法实现并行,因为L1 Cache每个周期只允许一个或两个不同的访问。也许在新的CPU中能解决这个问题
Vectorized Operators:
Selection ScansHash TablesPartitioning/HistogramsJoinsSortingBloom filters
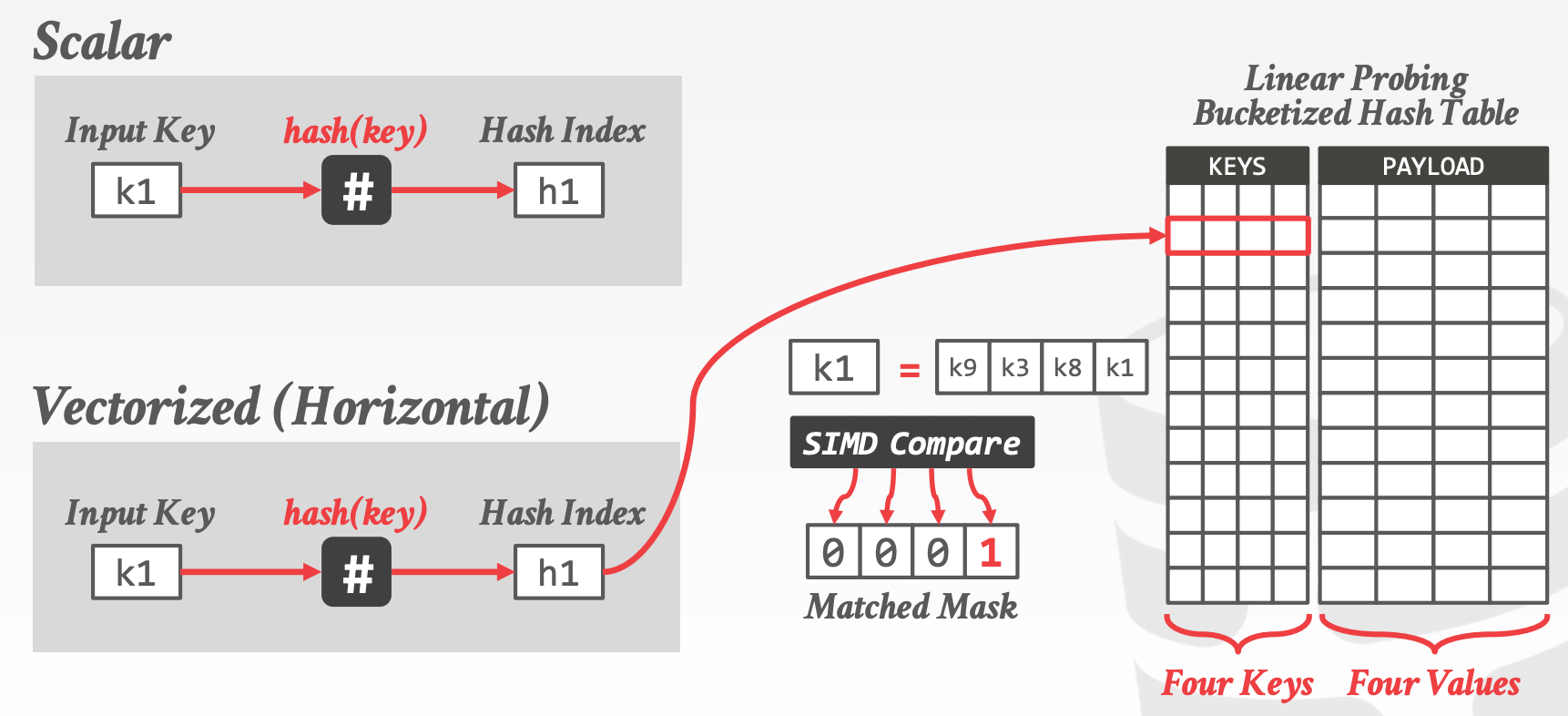
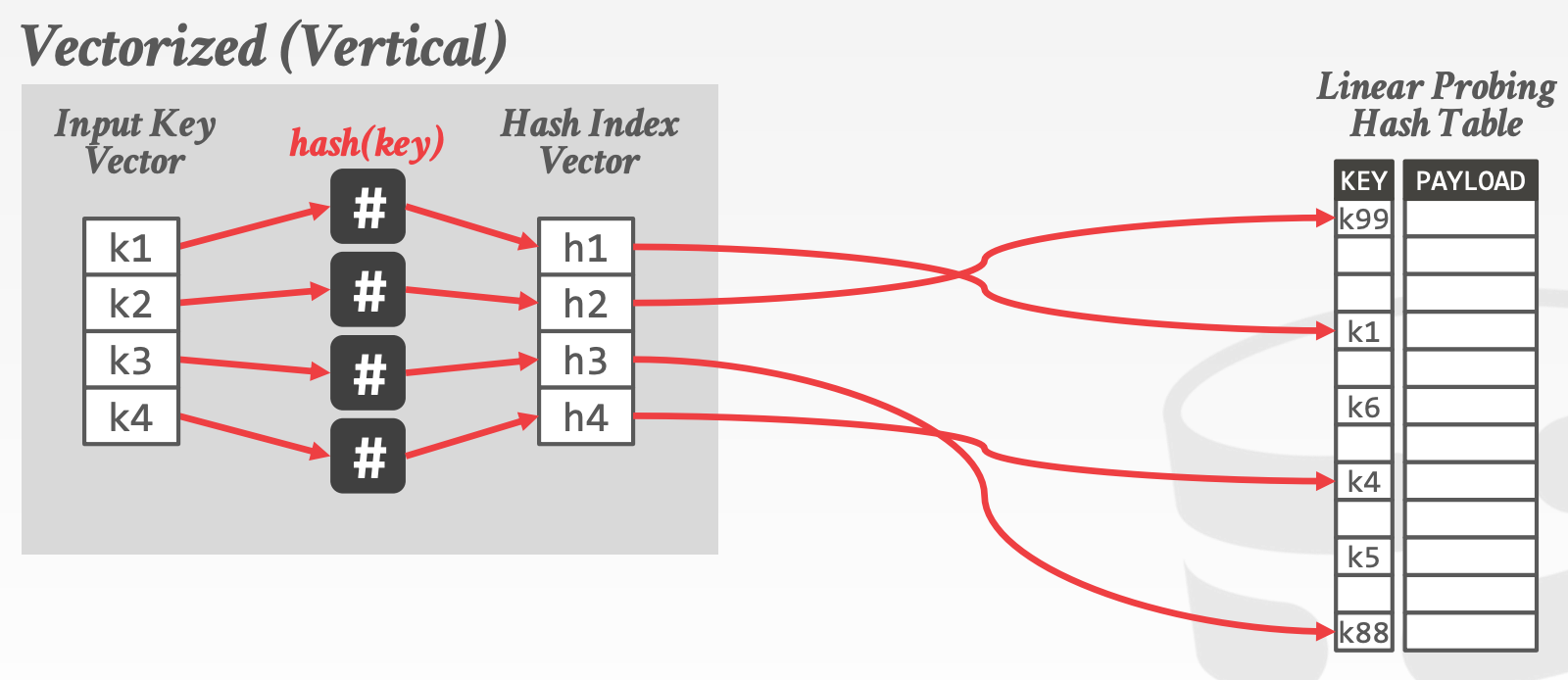

16 vectorization2
16.1 Vectorization vs. Compilation
16.2 Relaxed Operator Fusion
17 hash joins
17.1 Background
为了提高效率,我们需要对Join进行并行化,实现并行Join的方法有如下两种:
Hash JoinSort-Merge Join
设计时,考虑的因素包括:
Minimize Synchronization- 避免加锁
Minimize Memory Access Cost- 尽量保证操作的数据都在缓存中
相关学术论文:
- Sort vs. Hash Revisited Fast Join Implementation on Modern Multi-Core CPUs
- Design and Evaluation of Main Memory Hash Join Algorithms for Multi-core CPUs
- Massively Parallel Sort-Merge Joins in Main Memory Multi-Core Database Systems
- Massively Parallel NUMA-aware Hash Joins
- Main-Memory Hash Joins on Multi-Core CPUs Tuning to the Underlying Hardware
- An Experimental Comparison of Thirteen Relational Equi-Joins in Main Memory
- Efficient Implementation of Sorting on Multi-Core SIMD CPU Architecture
- Parallel Sort-Merge Join
对于OLTP来说,一般不会实现Hash Join,因为对于少量数据来说,Nested-Loop Join的效率与Hash Join的效率相当。对于OLAP来说,Hash Join是最重要的工作负载
17.2 Parallel Hash Join
Hash Join (R ⨝ S)的主要流程如下:
Partition:将R和S中的元组按照Join Key进行分区Non-Blocking PartitionShared PartitionsPrivate Partitions
Blocking Partition(Radix)Radix这里特指Hash Value某个位置(第i位)上的整数值Step1:扫描R,计算每个Hash Value对应的Tuple数量的直方图Step2:利用直方图,通过Prefix Sum计算输出的偏移量Step3:再次扫描R,利用Hash Value以及上一步计算出来的偏移量进行分区- 可以重复上述过程(用第
i+1位),在原有分区的基础上进行进一步分区 - 示意图参考课件中的
21 ~ 34页
Build:对每个分区中的R进行扫描,并创建一个Hash Table- 确保
Hash Table的每个分桶足够小,一个Cache Line能够容纳
- 确保
Probe:对每个分区中的S,利用上一步创建的Hash Table判断是否存在- 在
Build阶段创建Bloom Filter,可以利用Bloom Filter来加速Probe过程。能起到加速的原因是整个Bloom Filter都可以放在CPU Cache中
- 在
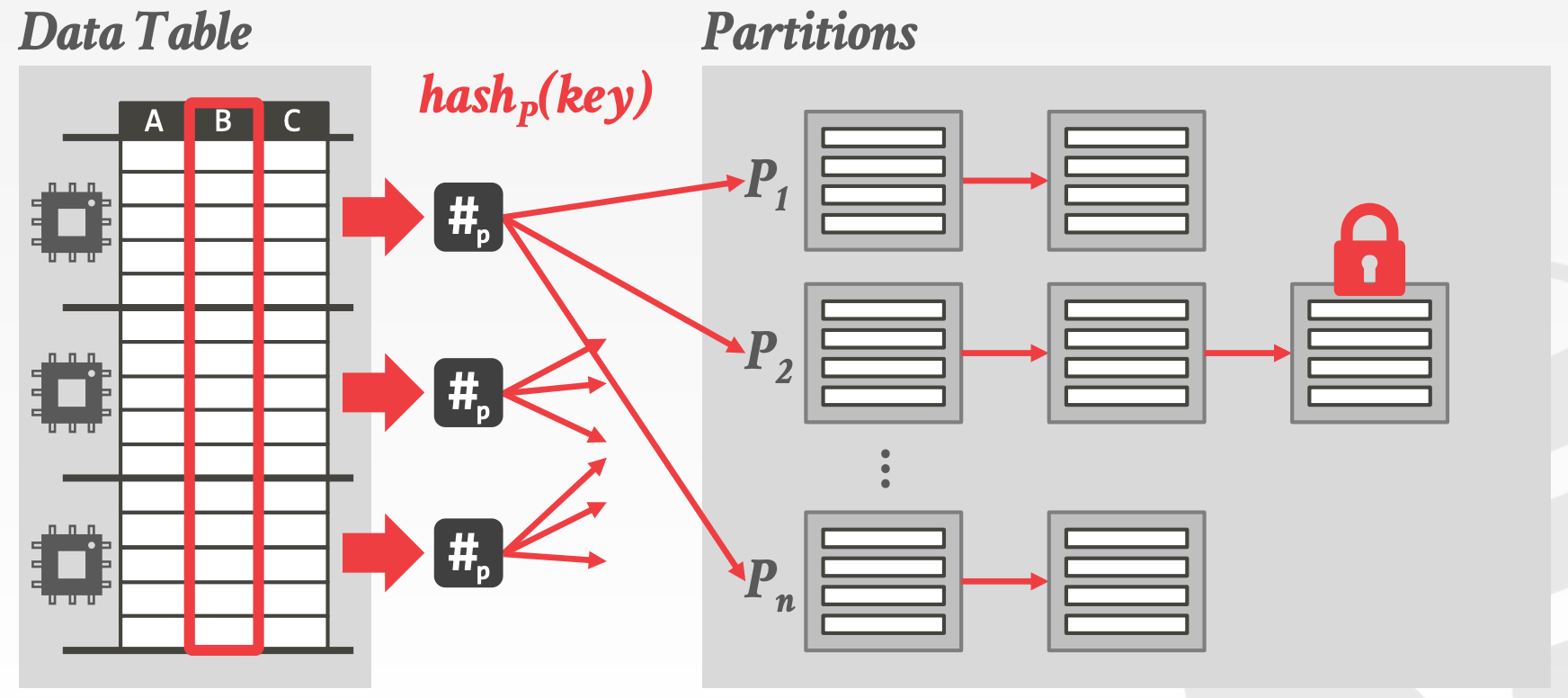

Hash Table的主要设计点
Hash Function- 如何将一个大的值空间映射到一个更小的值空间
- 需要在效率和冲突之间权衡
Hashing Scheme- 如何解决冲突
- 如何高效实现插入、查找
17.3 Hash Functions
MHasher是一个测试套件,旨在测试非加密哈希函数的分布、冲突和性能属性
常用的Hash Functions如下:
CRC-64 (1975)- 常用于网络异常校验
MurmurHash (2008)- 高效、通用的哈希函数
Google CityHash (2011)- 针对短键(<64 bytes)的哈希函数
Facebook XXHash (2012)- 由
zstd压缩的作者提出并实现
- 由
Google FarmHash (2014)CityHash的升级版,冲突概率更小
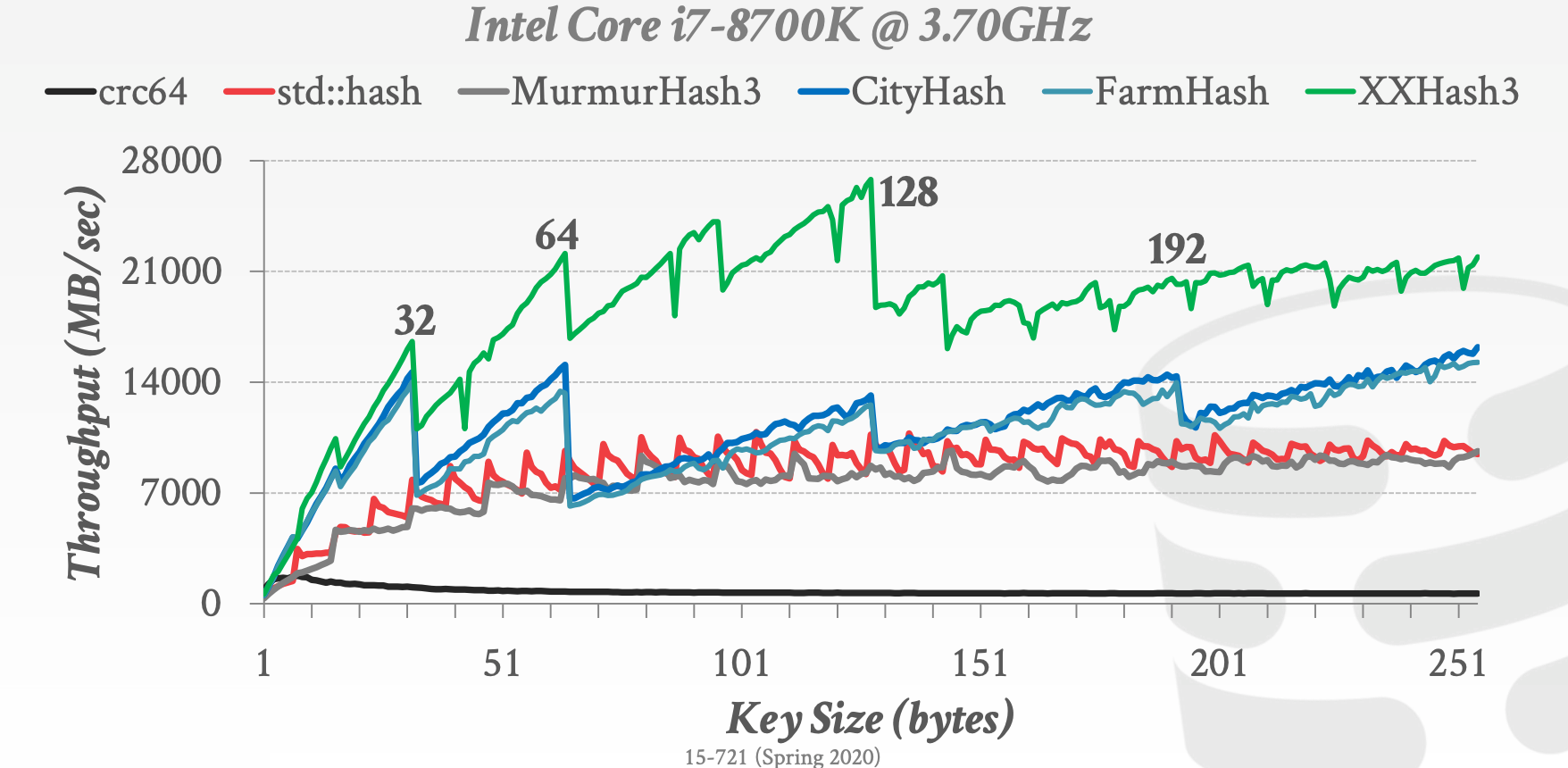
17.4 Hashing Schemes
Chained Hashing- 为哈希表中的每个槽维护一个桶的链表
Linear Probe Hashing- 开放寻址法
- 每个槽位存储一个元素
- 当槽位已被占用时,按规则寻找下一个可用槽位
- 示意图参考课件中的
52 ~ 59页
Robin Hood HashingLinear Probe Hashing的变体- 会将元素从
Rich Key的槽位迁移到Poor Key对应的槽位 - 需要额外存储原始槽位与当前槽位的
Offset - 示意图参考课件中的
62 ~ 72页
Hopscotch HashingLinear Probe Hashing的变体,也可看做是对Robin Hood Hashing的进一步限制,限制了迁移的距离- 元素会在其
Netighborhood之前进行迁移,Netighborhood Size通过配置指定 - 存在约束:如果
Key不存在于Netighborhood之中,那么Key不存在 - 示意图参考课件中的
74 ~ 94页
Cuckoo Hashing- 使用多个哈希表,每个哈希表用不同的哈希函数
- 插入时,检查每个哈希表,将元素插入到有空闲槽位的哈希表。若无法找到空闲槽位,则将对应槽位中的元素驱逐,并重新插入
- 需要确保上述流程不会进入死循环
- 哈希表的数量是2,那么哈希表利用率的上限是50%
- 哈希表的数量是3,那么哈希表利用率的上限是90%
- 示意图参考课件中的
96 ~ 106页
18 sort merge joins

18.1 Parallel Sort-Merge Join
由于排序的开销比较大,因此并行化能够显著的提升性能
- 尽可能地利用更多CPU
NUMASIMD
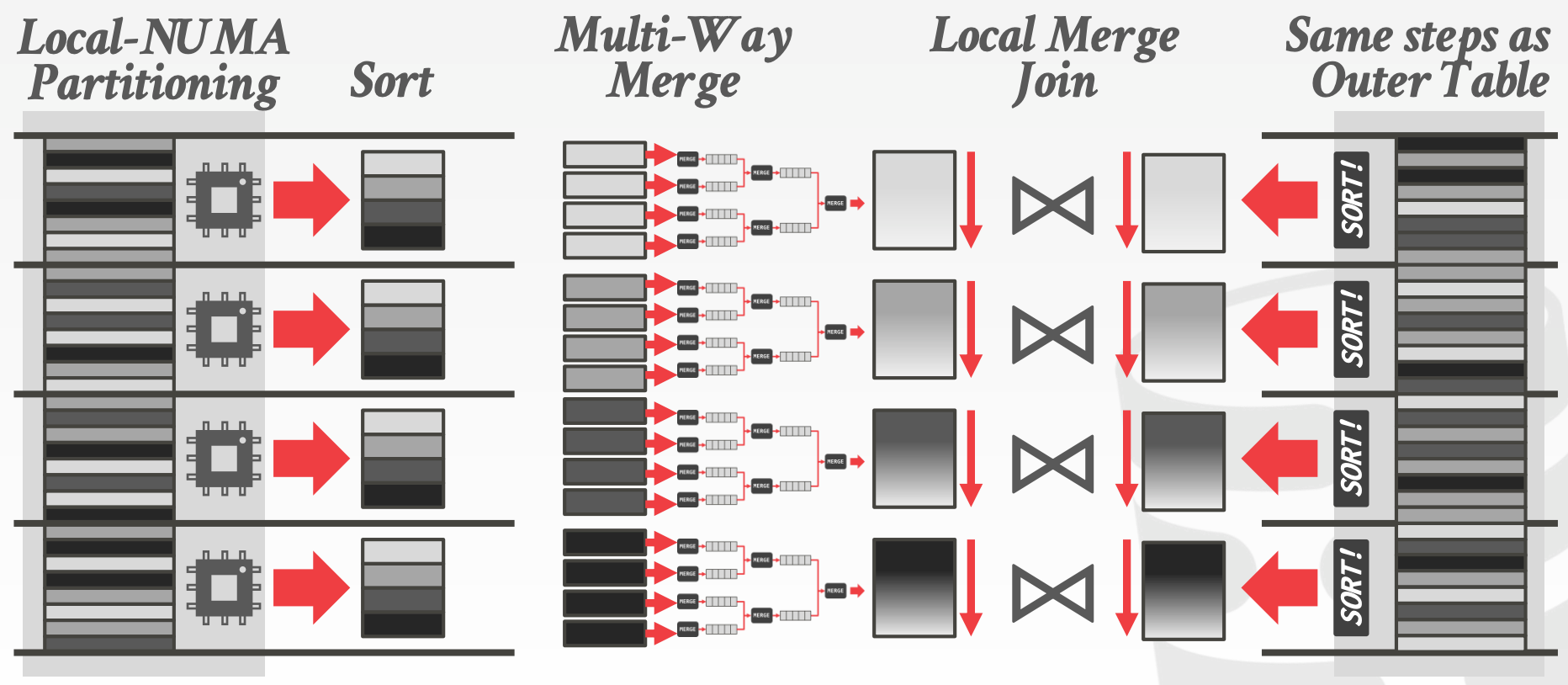
Sort-Merge Join (R ⨝ S)的主要流程如下:
Partitioning- 将
R和S中的元组按照Join Key进行分区 - 分区方式有如下两种
Implicit Partitioning- 数据存储时就已分区,因此无需额外的分区操作便可获得分区的数据
Explicit Partitioning- 需要对左表进行显式的分区操作
- 可以使用之前介绍过的
Radix Partitioning
- 将
Sort- 在每个分区中,对
R和S进行排序 - 一般使用
QuickSort - 可以探索其他能够更好地利用
NUMA以及并发的排序算法 Cache-Conscious SortingIn-Register SortingIn-Cache SortingOut-of-Cache Sorting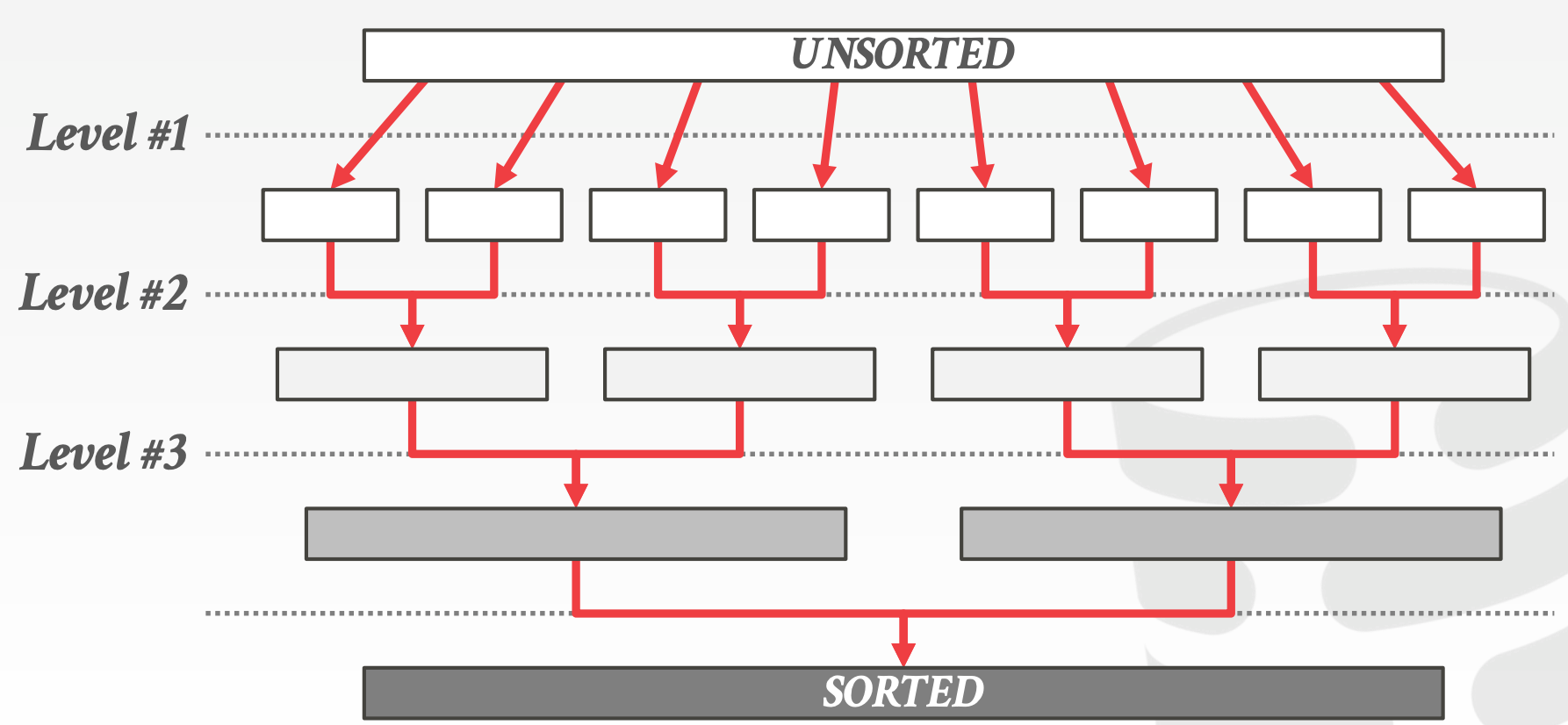
- 在每个分区中,对
MergeMulti-Way Sort-Merge (M-WAY)- 左表:
- 在每个核上对本地数据进行排序(
Level 1/Level 2) - 使用多路合并
Multi-Way Merge
- 在每个核上对本地数据进行排序(
- 右表:
- 与左表相同的方式
- 左表:
Multi-Pass Sort-Merge (M-PASS)- 左表:
- 在每个核上对本地数据进行排序(
Level 1/Level 2) - 不对排序后的数据进行重新分布
- 在每个核上对本地数据进行排序(
- 右表:
- 与左表相同的方式

- 左表:
Massively Parallel Sort-Merge (MPSM)- 左表:
- 按照范围进行分区,每个分区独立排序
- 右表:
- 不进行分区,每个核扫描本地的数据
- 左表:
18.2 Evaluation
19 optimizer1
优化器用于在Plan搜索空间中找出执行开销最小的Plan,该问题已被证明是NP-Complete问题
目前来说,已知的优化器选出的不一定是最优解
- 利用基数估计来预估实际的执行开销
- 利用启发式的方法来裁剪搜索空间的大小
19.1 Background
Logical vs. Physical PlansRelational Algebra Equivalences(A ⨝ (B ⨝ C)) = (B ⨝ (A ⨝ C))
Cost Estimation- 中间结果的大小
- 算法、访问方式
- 资源利用率
- 数据属性,包括倾斜、顺序、位置等
19.2 Implementation Design Decisions
设计点:
Optimization GranularitySingle Query- 搜索空间小
- 需要考虑资源竞争
Multiple Queries- 搜索空间大
- 数据、中间结果的共享能够带来显著增益
Optimization TimingStatic Optimization- 在执行前选出最优
Plan Plan的质量取决于Cardinality Estimation以及Cost Model的准确性- How-Good-Are-Query-Optimizers指出
Cardinality Estimation的准确性更重要
- How-Good-Are-Query-Optimizers指出
- 借助于
Prepared Statements,可以将优化开销均摊到多次不同的实现中
- 在执行前选出最优
Dynamic Optimization- 执行时实时调整
Plan - 在多次执行时,有机会可以调整
Plan - 难以实现
- 执行时实时调整
Adaptive Optimization
Prepared Statements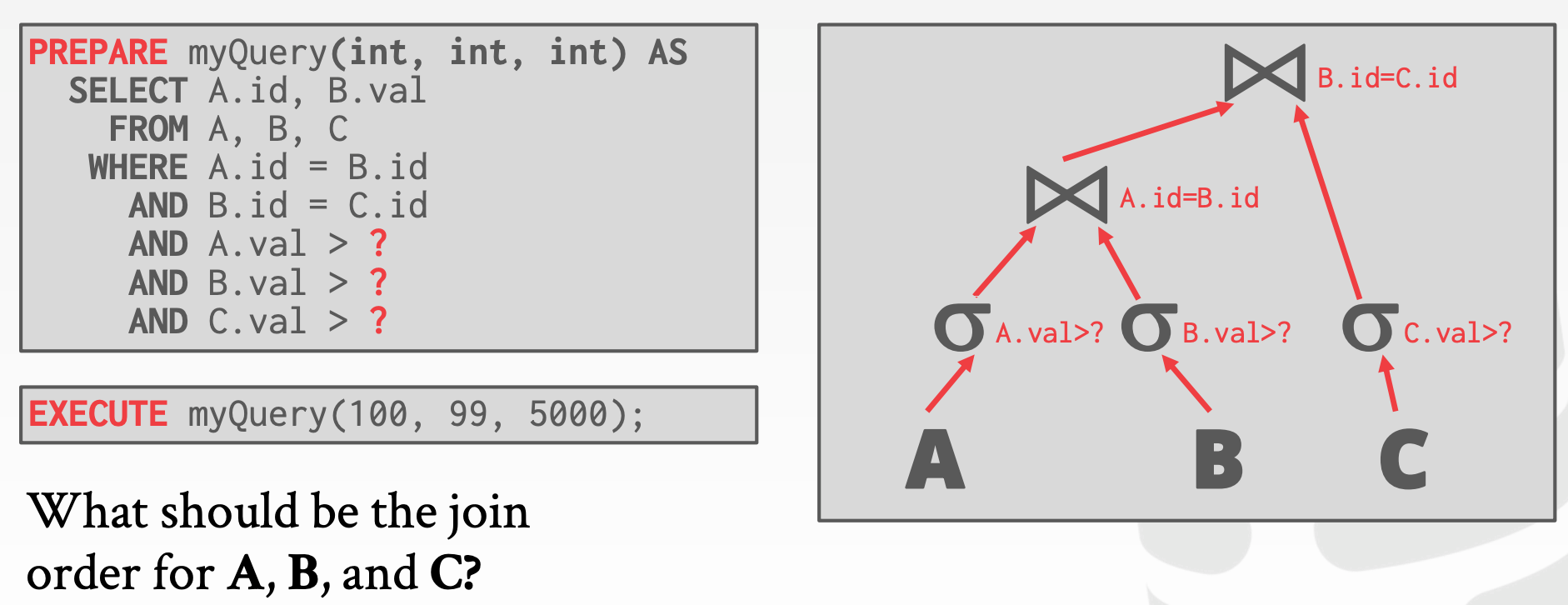
Reuse Last Plan:直接复用前一次生成的PlanRe-Optimize:每次都重新进行优化Multiple Plans:用不同的参数,生成多个PlanAverage Plan:用参数的均值来生成Plan
Plan StabilityHintsFixed Optimizer VersionsBackwards-Compatible Plans
Search TerminationWall-clock Time:优化超时Cost Threshold:通过Cost Boundary来裁剪搜索空间Exhaustion:穷尽枚举
19.3 Optimizer Search Strategies
搜索策略如下:
Heuristics Only- 优化手段包括
- 尽早执行最严格的选择
- 在
Join之前执行选择 - 谓词下推
Limit下推Projection下推Join Ordering
- 优点:
- 易于实现和调试
- 对于简单查询能够有效地工作
- 缺点:
- Relies on magic constants that predict the efficacy of a planning decision
- 在算子间存在相关性的情况下,很难产生较好的
Plan
- 优化手段包括
Heuristics + Cost-based Join Order SearchTop-Down vs. Bottom-UpTop-DownVolcano、Cascades
Bottom-upSystem R、Starburst
- 优点:
- 通常可以选出一个较好的
Plan,而无需穷举搜索空间
- 通常可以选出一个较好的
- 缺点:
- 包含
Heuristics Only的所有缺点 - 只考虑左深树,但最优解并不一定是左深树
- 需要额外考虑数据的物理属性(例如倾斜、排序等)
- 包含
Randomized Algorithms- 在搜索空间中随机搜索
Plan,直至找到Cost低于指定Threshold的Plan或者超时 - 示例:
Postgre's genetic algorithm - 优点:
- 在搜索空间中随机跳跃可以让优化器摆脱局部最小值
- 内存开销小
- 缺点:
- 很难解释如何选出某个
Plan - 不稳定性,必须做额外的工作以确保
Plan是稳定的
- 很难解释如何选出某个
- 在搜索空间中随机搜索
Stratified Search- 第一步:应用
Transformation Rules,对原Logical Plan进行重写 - 第二步:基于
Cost Model,将Logical Plan转换成Physical Plan
- 第一步:应用
Unified Search- 将
Logical Plan到Logical Plan以及Logical Plan到Physical Plan都视为Transformation,因此,整个优化过程就一个阶段
- 将
Optimizer Generators
- 用面向过程的语言来写
Transformation Rule会比较难,且容易出错,需要写大量的模糊测试来保证正确性 - 另一种途径:通过
DSL来描述规则;通过Optimizer Generator来生成对应的代码 - 例子:
Starburst、Exodus、Volcano、Cascades、OPT++
涉及到的优化器包括:
Ingres OptimizerSystem R OptimizerPostgres Genetic OptimizerStarburst OptimizerVolcano Optimizer
20 optimizer2
20.1 Logical Query Optimization
该阶段的目的主要包括:
- 扩充搜索空间,枚举可能的
Plan - 简化
Plan- 表达式的重写和简化
- 列裁剪
- 谓词拆分
- 谓词下推
- Limit下推
- Projection下推
- 笛卡尔积替换为Join(有等值条件的情况下)
- 等价谓词推导(常量传播)
- 常量折叠
- 公共表达式复用
- 子查询重写
- 消除不必要的
Cast
20.2 Physical Query Optimization
该阶段的目的主要包括:
- 将
Logical Plan中的Logical Operator转换成Physical Operator- 需要知道更多的执行相关的信息
- 索引、访问方式
- 实现方式
- 何时物化
- 需要使用
Cost Model来对每个Physical Plan进行代价评估
20.3 Cascades / Columbia
概念:
Expression:由一个算子以及零或多个输入构成,每个输入也是ExpressionOperator区分逻辑与物理,因此Expression也有逻辑和物理之分
Group:由一组等价的Logical Expression以及Physical Expression构成- 等价意味着,这些
Expression都能产生相同的输出
- 等价意味着,这些
Rule:将一个Expression转换成另一个等价的ExpressionTransformation Rule:Logical to LogicalImplementation Rule:Logical to PhysicalRule的构成Pattern:匹配当前Rule的模式Substitute:应用当前Rule会产生的输出
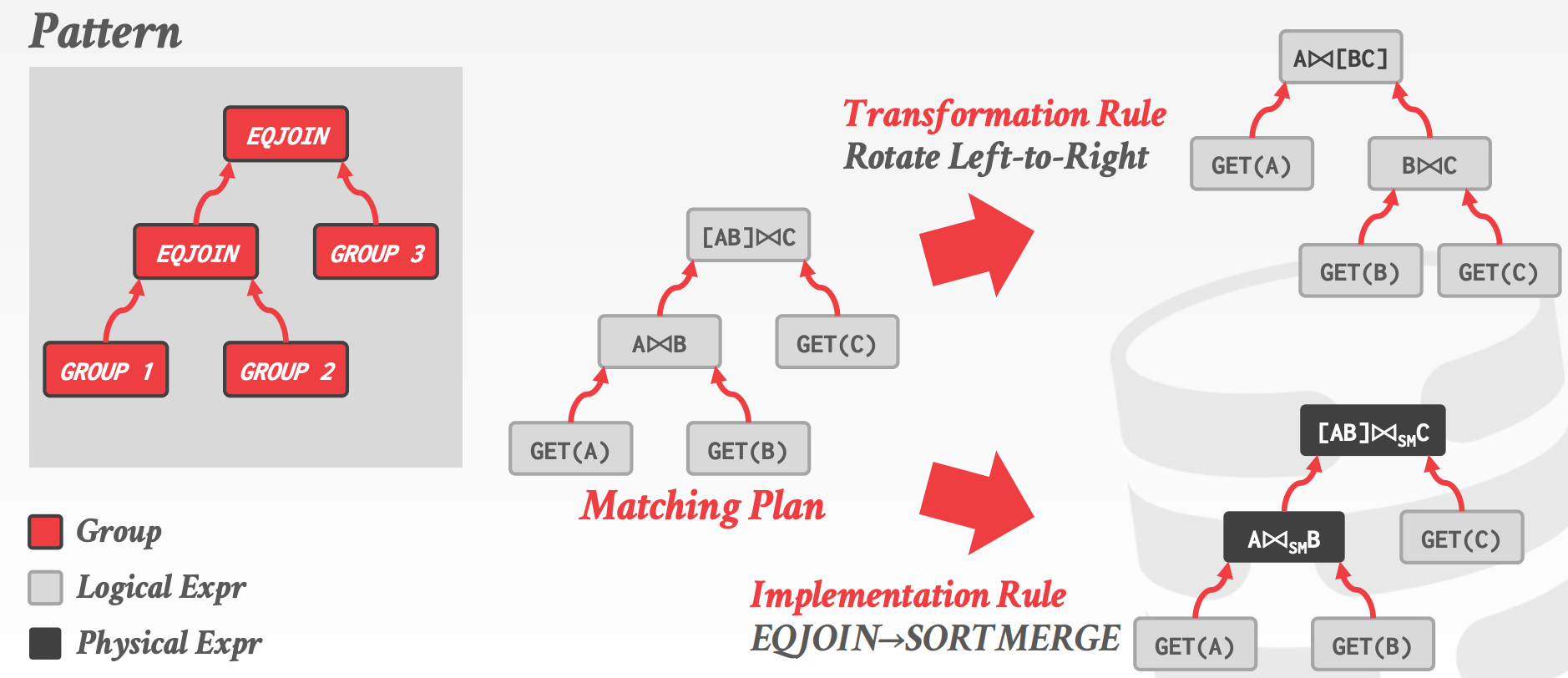
Memo Table:存储所有已探索的Plan,即搜索空间- 重复检测
Property、Cost管理
示意图参考课件中的35 ~ 52页
Cascades的实现包括:
StandaloneWisconsin OPT++ (1990s)Portland State Columbia (1990s)Pivotal Orca (2010s)Apache Calcite (2010s)
IntegratedMicrosoft SQL Server (1990s)Tandem NonStop SQL (1990s)Clustrix (2000s)CMU Peloton (2010s – RIP)
20.4 Dynamic Programming
20.5 Other Implementations
Pivotal OrcaApache CalciteQuery Language、Cost Model、Rule支持插件化- 不区分
Logical Operator以及Physical Operator
MemSQL OptimizerRewriter- 利用
Cost Model进行Logical to Logical的转换
- 利用
Enumerator- 进行
Logical to Physical的转换
- 进行
Planner- 将
Physical Plan转换成SQL
- 将
20.6 一些思考
优化器是否能选出最优的Plan取决于Cost Model,而Cost Model依赖于合理且准确的统计信息
21 optimizer3
优化器依赖Cardinality Estimation以及Cost Model,若偏差较大的话,容易生成Bad Plan
优化器基于一些静态的统计信息以及执行上下文来进行代价估计
- 静态模型/直方图/采样
- 硬件性能(CPU/IO)
- 当前算子的复杂度
21.1 Adaptive Query Optimization
Modify Future Invocations- 监控查询执行,并采集相关信息,用于优化后续的查询
- 方法包括
Plan CorrectionFeedback Loop
Identifying Equivalent SubplansLogical Expression相同且Physical Property相同的Sub Plan就被认为是等价的
Replan Current Invocation- 如果在执行时,发现实际开销远大于估计值,那么终止当前执行,并重新生成
Plan - 方法包括
Start-Over from ScratchKeep Intermediate Results
- 如果在执行时,发现实际开销远大于估计值,那么终止当前执行,并重新生成
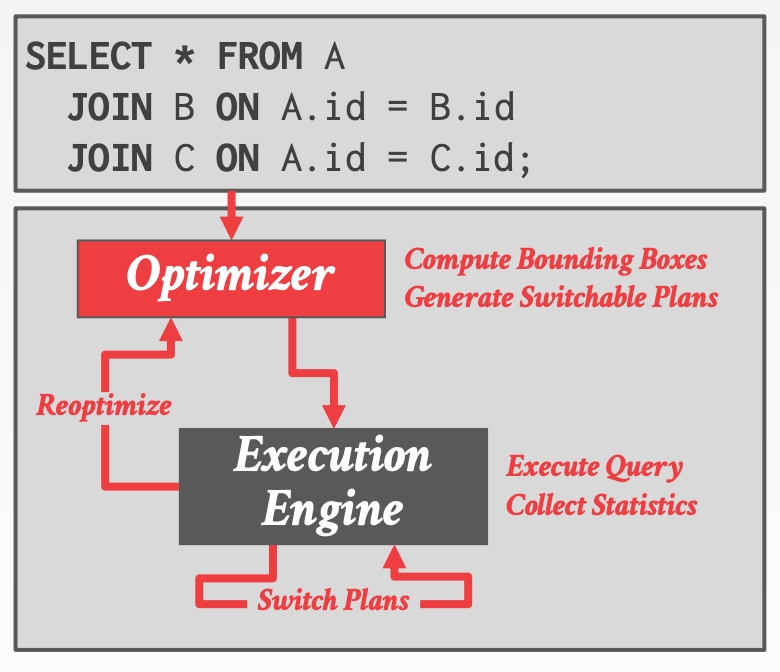
Plan Pivot Points- 在物化节点,提供多个
Sub Plan,当执行到该节点时,依据当前执行所获取的统计信息,选择使用哪个Sub Plan继续执行 - 方法包括
Parametric OptimizationProactive Reoptimization
- 在物化节点,提供多个
22 cost models
22.1 Cost Models
Cost Model Components:
Physical CostsInstruction cyclessCache missesRAMI/O- 与硬件强相关
Logical Costs- 算子输出数据的大小
- 与具体算法无关
Algorithmic Costs- 算法的开销
Disk-Based DBMS Cost Model:
CPU成本对于磁盘I/O而言,可以忽略不计- 若整个
DB都可以cache在内存中之后,那么此时就与CPU成本相关了
- 若整个
- 需要考虑顺序或者随机
I/O
Postgres Cost Model:
- 分别给
CPU和I/O一个乘因子,用于调整它们的占比 - 默认配置值假设不存在大量内存(无法全部cache)
- 读内存的性能大约是读磁盘的400倍
- 顺序读的性能大约是随机读的4倍
In-Memory DBMS Cost Model:
- 由于没有磁盘
I/O的开销,因此需要考虑CPU和内存的开销 - 内存开销的估计比较困难,因为
MESI协议对于DBMS而言完全是透明的 CPU开销可以用算子处理的数据量来代替
22.2 Cost Estimation
Selectivity:估计谓词的选择度
- 估计时会用到的信息:
Domaon Constraints:领域限制,比如温度,不可能存在低于-274℃的温度值Precomputed Statistics(Zone Map)Histograms / ApproximationsSampling
- 此外,还与如下因素相关
- 访问数据的方式
- 数据分布
- 谓词
Approximations:给估值加上一个错误边界,不至于错的太离谱
Count DistinctQuantilesFrequent ItemsTuple Sketch
Sampling:采样
Result Cardinality:对于ScanOperator来说,结果基数取决于选择度以及输入的数据量。且存在如下假设:
Uniform Data:数据均匀分布Indenpendent Predicates:谓词之间相互独立Inclusion Principle:包容性原则
Column Group Statistics:
- 列的相关性会导致谓词之间也有相关信息
- 可以将一组相关性较强的列放入一个分组中,然后对分组进行统计分析
- 需要
DBA手动指定分组
- 需要
一些观点:
- 一个好的优化器要比一个快的执行器更重要
- 基数估计存在误差
Hash Join以及Seq Scan通常是一个较好的选择- 研究准确的模型是浪费时间
- 结合
Sampling与Sketch,也许可以得到一个较为准确的估计
23 larger than memory
23.1 Implementation Issues
OLTP Issues:
Runtime Operations:Cold Data IdentificationOn-lineOff-line
Eviction Policies:TimingThresholdOn Demand
Evicted MetadataTuple TombstonesBloom FiltersDBMS Managed PagesOS Virtual Memory
Data Retrieval Policies:GranularityAll Tuples in BlockOnly Tuples Needed
Retrieval MechanismAbort-and-RestartSynchronous Retrieval
MergingAlways MergeMerge Only on UpdateSelective Merge
24 udfs
我们可以将一些业务逻辑相关的代码嵌入在DBMS中,形式可以是:
User-Defined Functions, UDFsStored ProceduresTriggersUser-Defined Types, UDTsUser-Defined Aggregates, UDAs
Microsoft SQL Server UDF History:
- 2001 – Microsoft adds TSQL Scalar UDFs.
- 2008 – People realize that UDFs are “evil”.
- 2010 – Microsoft acknowledges that UDFs are evil.
- 2014 – UDF decorrelation research @ IIT-B.
- 2015 – Froid project begins @ MSFT Gray Lab.
- 2018 – Froid added to SQL Server 2019.
Froid Overview:
- Transform Statements
- Break UDF into Regions
- Merge Expressions
- Inline UDF Expression into Query
- Run Through Query Optimizer
25 hardware
25.1 Persistent Memory
Fundamental Elements of Circuits:
Capacitor:电容器Resistor:电阻器Inductor:电感器Memristor:忆阻器
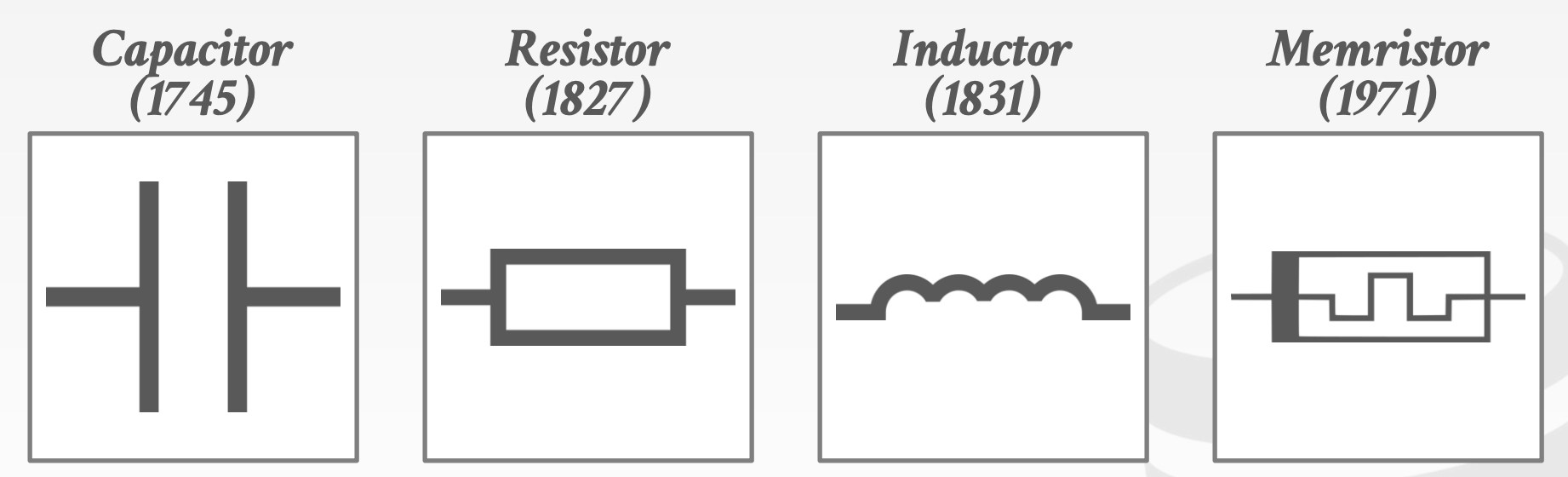
Technologies:
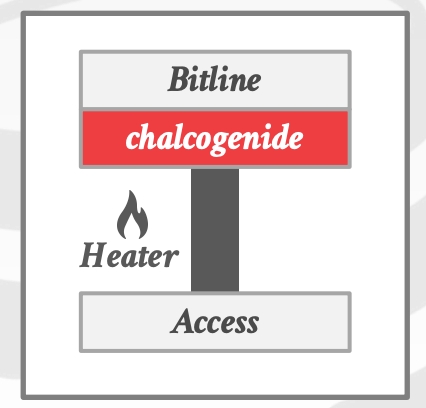
Phase-Change Memory, PRAM- 存储单元由两个由电阻加热器和相变材料(硫属化物)隔开的金属电极组成
Resistive RAM, ReRAM- 两个金属层,中间有两个
TiO2层。 向一个方向运行电流会将电子从顶部TiO2层移动到底部,从而改变电阻 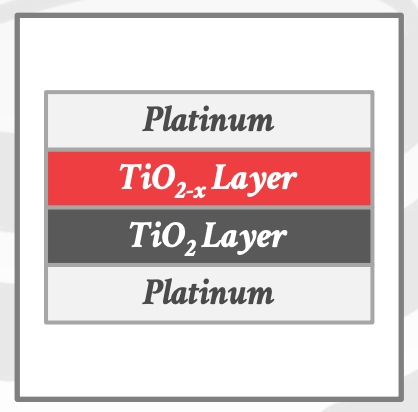
- 两个金属层,中间有两个
Magnetoresistive RAM, MRAM- 使用磁存储元件而不是电荷或电流来存储数据

25.2 GPU Acceleration
25.3 Hardware Transactional Memory
26 课件
- 01-history
- 02-inmemory
- 03-mvcc1
- 04-mvcc2
- 05-mvcc3
- 06-oltpindexes1
- 07-oltpindexes2
- 08-storage
- 09-compression
- 10-recovery
- 11-networking
- 12-scheduling
- 13-execution
- 14-compilation
- 15-vectorization1
- 16-vectorization2
- 17-hash-joins
- 18-sort-merge-joins
- 19-optimizer1
- 20-optimizer2
- 21-optimizer3
- 22-cost-models
- 23-larger-than-memory
- 24-udfs
- 25-hardware
27 Summary
28 Else
- Apache Arrow format
- Delta: always refers to what changed
- RCU, Read-Copy-Update
- Latch vs. Lock
- 本质上都是锁,锁的对象不同。Lock锁的对象是事务;而
Latch锁的对象是一些内存资源(数据结构)
- 本质上都是锁,锁的对象不同。Lock锁的对象是事务;而