阅读更多
1 概述
1.1 引言
系统和系统架构:
- 系统是为实现一个或多个所声明的目标而组织的相互关联的要素的组合
- 系统架构是系统组件的组织结构、它们之间的关系、与环境的关系、以及指导其设计和进化的原则
体系结构的定义:
- 设计、选择和连接硬件组件以及设计硬件/软件接口,以创建一个满足功能、性能、能耗、成本和其他具体目标的计算系统的科学和艺术
- 体现为描述计算机系统的功能、结构组织和实现的一组规则和方法
- 广义:计算机体系结构指计算机(硬件)系统的抽象表示,基于这些抽象表示使得我们可以更好地使用可用的制造技术实现(信息处理)硬件系统,高效地设计与实现(信息处理)软件系统
计算机体系结构研究范畴:
- 早期定义(Amdahl, Blaauw, and Brooks, 1964):程序员可见的计算系统的属性。包括:概念性的结构和功能行为。不包括:数据流和控制流的组织、逻辑设计以及物理实现
- 狭义:计算机体系结构是软件设计者与硬件设备设计者(VLSI)之间的中间层(ISA),以及微体系结构
- 扩展的观点:计算机体系结构包括:算法层、程序/语言层、系统软件层、ISA层、微体系结构、逻辑电路层、以及器件层
计算机组成与实现:
- 计算机组成(Computer Organization or Microarchitecture):ISA的逻辑实现。包括,物理机器级中的数据流和控制流的组成以及逻辑设计等
- 计算机实现(Computer Implementation):计算机组成的物理实现。包括,
CPU,MEMORY等的物理结构,器件的集成度、速度,模块、插件、底板的划分与连接、信号传输、电源、冷却及整机装配技术等
1.2 量化设计与分析基础
管理复杂性:
- 将工程师或计算机科学家与门外汉区分开来的特征之一是管理复杂性的系统方法
- 现代数字系统是由数百万甚至数十亿个晶体管组成的。没有人能够通过写出描述每个晶体管中电子运动的方程并同时解出所有方程来理解这些系统
- 管理复杂性的方法:抽象(Abstraction)+ 原则(Discipline)+ 3’Y
影响体系结构技术发展的主要因素:
- 产品应用方面:
PC/Server => IoT, Mobile/Cloud - 集成电路技术方面:
- 登纳德缩放比例定律的终结:功耗成为关键制约条件
- Moore定律的终结:晶体管的集成度提高延缓
- 体系结构方面
- 挖掘指令级并行性方面的限制和低效,04年结束了单处理器时代
- Amdahl定律暗示了简单多核时代的结束
1.3 定量分析基础
过去数十年间,计算机系统设计方面的巨大变化
- 在过去的50年,
Moore's law和Dennard scaling(登纳德缩放比例定律)主宰着芯片产业的发展Moore在1965年预测:晶体管数量随着尺寸缩小按接近平方关系增长(每18个月翻倍)Dennard在1974年预测:晶体管尺寸变小,功耗会同比变小(相同面积下功耗不变)- 工艺技术的进步可在不改变软件模型的情况下,持续地提高系统性能/能耗比
- 最近10年间,工艺技术的发展受到了很大制约
- Dennard scaling over(supply voltage ~fixed)
- Moore’s Law(cost/transistor)over?
- Energy efficiency constrains everything
- 功耗问题成为系统结构设计必须考虑的问题
- 软件设计者必须考虑
- Parallel systems
- Heterogeneous systems
有关体系结构的新旧观念
- 旧观念:
- 能源很便宜,晶体管很贵
- 通过编译、体系结构创新来增加指令级并行
- 乘法器速度较慢,访存速度比较快
- 单处理器性能,每1.5年翻倍
- 新观念:
- 能源很贵,晶体管很便宜
- 挖掘指令级并行的收益越来越小
- 乘法器速度提升了,访存成为瓶颈
Power Wall + ILP Wall + Memory Wall = Brick Wall,单处理器性能,每5年翻倍- 每2年,单个芯片上的处理器数量翻倍
性能:
- 性能度量
- 响应时间
- 吞吐率
- CPU执行时间=
IC * CPI * TCPI指的是Cycles per Instruction
Latency与BandwidthLatency指单个任务的执行时间,Bandwidth指单位时间完成的任务量(rate)Latency的提升滞后于带宽的提升(在过去的30年)
Amdahl's Law用来度量加速比- 性能提升受限于任务中可加速部分所占的比例
- 应用于多处理器系统的基本假设:在给定的问题规模下,随着处理器数目的增加性能的变化
Benchmarks:指一组用于测试的程序- 比较计算机系统的性能(算术平均、调和平均、几何平均)
1.4 相关课件
2 ISA
2.1 ISA的基本概念
什么是指令集架构?
- 软件子系统与硬件子系统的关键界面
- 一组直接由硬件执行的指令,包括
- 程序员可见的机器状态
- 程序员可见的指令集合(操作机器状态的指令)
- 应具备的特征(七个衡量指标)
- 成本(
cost) - 简洁性(
simplicity) - 性能(
performance):方便低层硬件子系统高效实现 - 架构和具体实现分离(
isolation of architecture from implementation):可持续多代,以保持向后兼容 - 可扩展空间(
room for growth):可用于不同应用领域(desktops、servers、embedded applications) - 程序大小(
program size):所生成的代码占用空间小 - 易于编程/编译/链接(
ease of programming/compiling/linking):为高层软件的实现与开发提供方便的功能
- 成本(
重要的系统界面(System Interface):
ISA界面ABI界面
ISA:用户级ISA+特权级ISA
- 用户级ISA适用于操作系统和应用程序
- 特权级ISA适用于硬件资源的管理(操作系统)
ISA必须说明哪些东西?
- 指令格式
- 存储器寻址
- 操作数的类型和大小
- 所支持的操作
- 控制转移类指令
尾端问题:在一个字内部的字节顺序问题,以int(0x12345678)为例
Little Endian:又称小端,高位在前,但是每个字节内部的bit还是按原来的顺序存放,即0x78->0x56->0x34->0x12Big Endian:又称大端,低位在前,即0x12->0x34->0x56->0x78
寻址方式:
| Model | Example | Meaning | When used |
|---|---|---|---|
| Register | Add R1, R2 |
R1 ← R1 + R2 |
操作数在寄存器中 |
| Immediate | Add R1, 100 |
R1 ← R1 + 100 |
立即数寻址,常量 |
| Register Indirect | Add R1, (R2) |
R1 ← R1 + Mem(R2) |
R2存储的是地址 |
| Displacement | Add R1, (R2 + 16) |
R1 ← R1 + Mem(R2 + 16) |
访问局部变量 |
| Absolute | Add R1, (1000) |
R1 ← R1 + Mem(1000) |
访问静态变量 |
| Indexed | Add R1, (R2 + R3) |
R1 ← R1 + Mem(R2 + R3) |
偏移寻址,R2 = base、R3 = index |
| Scaled Index | Add R1, (R2 + s * R3) |
R1 ← R1 + Mem(R2 + s * R3) |
s = scale factor(2,4,8) |
| Post-increment | Add R1, (R2)+ |
R1 ← R1 + Mem(R2)R2 ← R2 + s |
向后跳过array,其中s = element size |
| Pre-decrement | Add R1, -(R2) |
R2 ← R2 - sR1 ← R1 + Mem(R2) |
向前跳过array,其中s = element size |
操作数的类型、表示和大小:
- 操作数类型和操作数表示是软硬件的主要界面之一
- 操作数类型:是面向应用、面向软件系统所处理的各种数据类型
- 操作数的表示:操作数在机器中的表示,硬件结构能够识别,指令系统可以直接使用的表示格式
控制类指令:
- 条件分支
Conditional Branch - 跳转
Jump - 过程调用
Procedure calls - 过程返回
Procedure returns
指令格式选择策略
- 如果代码规模最重要,那么使用变长指令格式
- 如果性能至关重要,使用固定长度指令
- 有些嵌入式CPU附加可选模式,由每一应用自己选择性能还是代码量
2.2 ISA的功能设计
功能设计:
- 任务:确定硬件支持哪些操作
- 方法:统计的方法
CISC:
- 目标:强化指令功能,减少运行的指令条数,提高系统性能
- 方法:面向目标程序的优化,面向高级语言和编译器的优化
RISC:
- 目标:通过简化指令系统,用高效的方法实现最常用的指令
- 方法:充分发挥流水线的效率,降低CPI
2.2.1 CISC
目标:强化指令功能,减少指令条数,以提高系统性能
基本优化方法:
- 面向目标程序的优化是提高计算机系统性能最直接的方法
- 优化目标:
- 缩短程序长度
- 缩短程序的执行时间
- 优化方法:
- 统计分析目标程序执行情况,找出使用频率高,执行时间长的指令或指令串
- 优化使用频度高的指令
- 用心得指令代替使用频度高的指令串
- 主要优化途径:
- 增强运算型指令的功能
- 增强数据传送类指令的功能
- 增强程序控制指令的功能
- 优化目标:
- 面向高级语言和编译程序改进指令系统
- 优化目标:
- 缩小
HL-ML之间的差距
- 缩小
- 优化方法:
- 增强面向
HL和Compiler支持的指令功能- 统计分析源程序中各种语句的使用频度和执行时间
- 增强相关指令的功能,优化使用频度高、执行时间长的语句
- 增加专门指令,以缩短目标程序长度,减少目标程序执行时间,缩短编译时间
- 高级语言计算机系统:缩小
HL和ML的差别- 极端:
HL=ML,即所谓的高级语言计算机高级语言不需要经过编译,直接由机器硬件来执行 - 如
LISP机,PROLOG机
- 极端:
- 支持操作系统的优化实现:特权指令
- 处理器工作状态和访问方式的转换
- 进程的管理和切换
- 存储管理和信息保护
- 进程同步和互斥,信号量的管理等
- 增强面向
- 优化目标:
2.2.2 RISC
目标:通过简化指令系统,用最高效的方法实现最常用的指令
RISC是一种计算机体系结构的设计思想,它不是一种产品
RISC是近代计算机体系结构发展史中的一个里程碑
早期对RISC特点的描述:
- 大多数指令在单周期内完成
- 采用
Load/Store结构 - 硬布线控制逻辑
- 少指令和寻址方式的种类
- 固定的指令格式
- 注重代码的优化
从目前的发展看,RISC体系结构还应具有如下特点:
- 面向寄存器结构
- 十分重视流水线的执行效率-尽量减少断流
- 重视优化编译技术
减少指令平均执行周期数是RISC思想的精华
RISC如何降低CPI:
- 硬件方面:
- 硬布线控制逻辑
- 减少指令和寻址方式的种类
- 使用固定格式
- 采用Load/Store
- 指令执行过程中设置多级流水线
- 软件方面:十分强调优化编译的作用
2.2.3 典型ISA
2.2.3.1 MIPS
MIPS是最典型的RISC 指令集架构:
Stanford(1980)提出- 第一个商业实现是
R2000(1986) - 最初的设计中,其整数指令集仅有58条指令,直接实现单发射、顺序流水线
- 30年来,逐步增加到约400条指令。
主要特征:
Load/Store型结构ALU类指令的操作数来源于寄存器或立即数- 降低了
ISA和硬件的复杂性,方便了流水线的实现 - 依赖于优化编译技术
主要缺陷:
- 针对特定的微体系架构的实现方式(5级流水、单发射、顺序流水线)进行过度的优化设计
ISA对位置无关的代码(position-independent code, PIC)支持不足- 16位位宽立即数消耗了大量编码空间,只有少量的编码空间可供扩展指令
- 乘除指令使用了特殊的寄存器(
HI,LO),导致上下文切换内容、指令条数、代码尺寸增加,微架构实现复杂 - 除了技术方面,
MIPS是非开放的专属指令集,不能自由使用
2.2.3.2 SPARC
Sun Microsystems的专属指令集
SPARC V8主要特征
- 用户级整型
ISA90条指令 - 硬件支持
IEEE 754-1985标准的浮点数50条 - 特权级指令20条
主要问题:
SPARC使用了寄存器窗口来加速函数调用。当函数调用所需的栈空间超过了窗口的寄存器数,性能会急剧下降。对于所有的实现来说,寄存器窗口都消耗很大的面积和功耗- 分支使用条件码。这些条件码由于在一些指令之间创建了额外的依赖关系,增加了体系结构状态并使实现复杂化
load和store相邻寄存器对的指令。对于简单的微体系结构很有吸引力,可以在增加很少硬件复杂性的情况下提高吞吐量。遗憾的是当使用寄存器重命名时使实现复杂化,因为在寄存器文件中数据在物理上可能不再相邻- 浮点寄存器文件和整数寄存器文件之间的移动必须使用内存系统作为中介,限制了系统性能
- 唯一的原子内存操作是
fetch-and-store,这对于实现许多无等待的数据结构是不够的
2.2.3.3 Alpha(DEC)
主要特征:
- 摒弃了当时非常吸引人的特性,如分支延迟、条件码、寄存器窗口等
- 创建了64位寻址空间、设计简洁、实现简单、高性能的ISA
Alpha架构师仔细地将特权体系结构和硬件平台的大部分细节隔离在抽象接口(特权体系结构库)后面(PALcode)
主要问题:DEC对顺序微架构的Alpha进行了过度优化,并添加了一些不太适合现代实现的特性
- 为了追求高时钟频率,
ISA的原始版本避免了8位和16位的load/store指令,实际上创建了一个字寻址的内存系统。为了补偿广泛使用这些(非字)操作的应用程序性能,添加了特殊的未对齐的load/store指令以及一些整数指令来加速重新对齐操作 - 为了方便长延迟浮点指令的乱序完成,
Alpha有一个非精确的浮点陷阱模型。这一决定单独来看是可以的。但是ISA还规定:如果使用这种浮点陷阱模型,必须由软件处理例程来给出异常标记和默认值 Alpha缺少整数除法指令,建议使用软件牛顿迭代法实现,导致浮点除法速度高于整数除法- 与其他前期的
RISC一样,没有预先考虑可能的压缩指令集扩展,因此没有足够的操作码空间来进行更新 ISA包含有条件的mov操作,这使得带有寄存器重命名的微架构复杂化- 使用商业
Alpha ISAs的一个重要风险:它们可能会被摒弃
2.2.3.4 ARMv7
ARMv7是32位RISC ISA
- 使用最广的体系结构
- 当我们权衡指令集(选择
vs重新设计)时,ARMv7是一个自然的选择 - 大量的软件已经移植到该
ISA上,在嵌入式和移动设备中无处不在
- 当我们权衡指令集(选择
- 是一个封闭的标准,剪裁或扩充是不允许的,即使是微架构的创新也仅限于那些能够获得ARM所称的架构许可的组织
ARMv7十分庞大复杂。整型类指令600+条
即使知识产权不是问题,它仍然存在一些技术缺陷:
- 不支持64位地址,
ISA缺乏硬件支持IEEE754-2008标准(ARMv8纠正了这些缺陷) - 特权体系结构的细节渗透到用户级体系结构的定义中
ISA中包含了许多实现复杂的特性。例如程序计数器PC是整数寄存器组的成员,这意味着几乎任何指令都可以改变控制流(比如ADD指令)
2.2.3.5 ARMv8
2011年,ARM发布新的ISA ARMv8
- 64位地址;扩展了整型寄存器组
- 摒弃了
ARMv7中实现复杂的一些特性
主要问题:
- 使用条件码
- 存在许多特殊的寄存器
- 指令集更加厚重:1070条指令,53种格式,8种寻址方式。说明文档达到了5778页
- 以暴露底层实现的方式将用户级
ISA和特权级ISA紧密地结合在一起 - 随着
ARMv8的引入,ARM不再支持压缩指令编码 ARMv8也是一个封闭的标准
2.2.3.6 OpenRISC
OpenRISC项目是一个开放源码处理器设计项目
- 来源于
Hennessy和Patterson的体系结构教科书DLX ISA - 适用于教学、科研和工业界的实现
主要问题:
- OpenRISC项目主要是开源处理器设计项目,而不是开源的
ISA规格说明,ISA和实现是紧密耦合的 - 固定的32位编码与16位立即数阻碍了压缩
ISA扩展 - 不支持
IEEE 754-2008标准 - 用于分支和有条件mov的条件码使高性能实现复杂化
ISA对位置无关的寻址方式支持较弱OpenRISC不利于虚拟化。从异常返回的指令L.RFE,定义为在用户模式下功能,而不是捕获
2.2.3.7 80x86
Intel 8086架构是过去40年里 笔记本电脑、台式机和服务器市场上最流行的指令集
- 除了嵌入式系统领域,几乎所有流行的软件都被移植到x86上,或者是为x86开发的
- 它受欢迎的原因有很多:该架构在
IBM PC诞生之初的偶然可用性;英特尔专注于二进制兼容性;它们积极的卓有成效的微结构实现;以及他们的前沿制造技术 - 指令集设计质量并不是它流行的原因之一
主要问题:
- 1300条指令,许多寻址方式,很多特殊寄存器,多种地址翻译方式,从
AMD K5微架构开始,所有的Intel支持乱序执行的微结构,都是动态地将x86指令翻译为内部的RISC风格的指令集。 - 不利于虚拟化。因为一些特权指令在用户模式下会无声地失败,而不是被捕获。
VMware的工程师们用动态二进制翻译软件解决了这一缺陷 ISA的指令长度为任意整数字节数,最多为15个字节,数量较少的短操作码已经被随意使用ISA有数量极少的寄存器组- 大多数整数寄存器在
ISA中执行特殊功能,加剧了体系结构寄存器的不足 - 更糟糕的是,大多数x86指令只有一种破坏性的指令格式,它会覆盖其中一个源操作数
- 一些
ISA特性,包括隐式条件码和带有谓词的mov操作,在微架构中实现复杂
80x86是一个专有指令集
2.2.3.8 小结
| MIPS | SPARAC | Alpha | ARMv7 | ARMv8 | OpenRISC | 80x86 | |
|---|---|---|---|---|---|---|---|
| Free and Open | ✅ | ✅ | |||||
| 64-bit Address | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| Compressed Instructions | ✅ | ✅ | Partial | ||||
| Separate Privileged ISA | ✅ | ||||||
| Position-Indep. Code | Partial | ✅ | ✅ | ✅ | |||
| IEEE 754-2008 | ✅ | ✅ | |||||
| Classically Virtualizable | ✅ | ✅ | ✅ | ✅ |
2.3 ISA的实现
通用的ISA的设计理念(指导思想):
- 能适应从最袖珍的嵌入式控制器,到最快的高性能计算机等各种规模的处理器
- 能兼容各种流行的软件栈和编程语言
- 适应所有实现技术,包括现场可编程门阵列(FPGA)、专用集成电路(ASIC)、全定制芯片,甚至未来的技术
- 对所有微体系结构实现方式都有效。例如:
- 微程序或硬布线控制;顺序或乱序执行流水线;单发射或超标量等等
- 支持定制化,成为定制专用加速器的基础。随着摩尔定律的消退,加速器的重要性日益提高
- 基础的指令集架构是稳定的。避免被弃用,如过去的
AMD Am29000、Digital Alpha、Digital VAX、Hewlett Packard PA-RISC、Intel i860、Intel i960、Motorola 88000、以及Zilog Z8000 - 完全开源
技术目标:
- 将
ISA分成基础ISA和可选的扩展部分ISA的基础部分足够简单、完整,可以用于教学和嵌入式处理器,包括定制加速器的控制单元。它足够完整,可以运行软件栈- 扩展部分提高计算的性能,并支持多处理机并行
- 支持32位和64位地址空间
- 方便根据应用需求扩展
ISA(指令集扩展)- 包括紧耦合功能单元和松耦合协处理器
- 支持变长指令集扩展
- 既为了提高代码密度,也为了扩展可能的自定义
ISA扩展的空间
- 既为了提高代码密度,也为了扩展可能的自定义
- 提供对现代标准的有效硬件支持
- 用户级
ISA和特权级ISA是正交的(相互独立,互不依赖)- 在保持用户应用程序二进制接口(ABI)兼容性的同时,允许完全虚拟化,并允许在特权
ISA中进行实验测试
- 在保持用户应用程序二进制接口(ABI)兼容性的同时,允许完全虚拟化,并允许在特权
RISC-V ISA的特点:
- 完全开源
- 它属于一个开放的,非营利性质的
RISC-V基金会 - 开源采用
BSD协议(企业完全自由免费使用,允许企业添加自有指令而不必开放共享以实现差异化发展)
- 它属于一个开放的,非营利性质的
- 架构简单
- 没有针对某一种微体系结构实现方式做过度的架构设计
- 新的指令集,没有向后(backward)兼容的包袱
- 说明书的页数少
- 模块化的指令集架构
RV32I和RV64I是基础的ISA。可扩展增加其他特性的支持- 面向教育或科研,易于扩充或剪裁
- 支持32位和64位地址空间
- 面向多核并行
- 有效的指令编码方式
为什么学习微程序控制?
- 如何用一个结构简单的处理器实现复杂
ISA CISC机器怎么发展起来的- CISC指令集仍然广泛使用(
x86、IBM360、PowerPC)
- CISC指令集仍然广泛使用(
- 帮助我们理解技术驱动从
CISC->RISC
微程序控制:
- 每条
宏指令是通过执行一段由若干条微指令构成的微程序来完成 - 微程序技术对计算机技术与产业发展起到了巨大的推动作用
- 可以采用简单的数据通路以及微程序控制器实现复杂的指令
处理器设计可以分为datapath和Control设计两部分
datapath:存储数据、算术逻辑运算单元、内部处理器总线control:控制数据通路上的一系列操作
60到70年代微程序盛行的原因
ROM比DRAM要快的多- 微程序存放在
ROM中实现扩展的复杂指令
- 微程序存放在
- 对于复杂的指令集,采用微程序设计技术使得
datapath和controller更便宜、更简单- 新的指令(例如 floating point)可以在不修改数据通路情况下增加
- 修改控制器的bug更容易
- 不同型号的机器实现
ISA的兼容性更简单、成本更低
80年代初的微程序技术
- 微程序技术的进展孕育了更复杂的微程序控制的机器
- 复杂指令集导致
µcode需要子程序和调用堆栈 - 需要修复控制程序中的bug与
µROM的只读属性冲突
- 复杂指令集导致
- 随着超大规模集成电路技术的出现,有关
ROM和RAM速度的假设变得无效- 逻辑部件、存储部件(
RAM,ROM)均采用MOS晶体管实现 - 半导体
RAM与ROM的存取速度相同
- 逻辑部件、存储部件(
- 随着编译器技术的进步,复杂指令变得不再那么重要
- 随着微结构技术的进步(pipeling, caches and buffers),使得多周期执行
reg-reg指令失去了吸引力
2.4 相关课件
3 基本流水线
3.1 基本流水线
流水线的基本概念
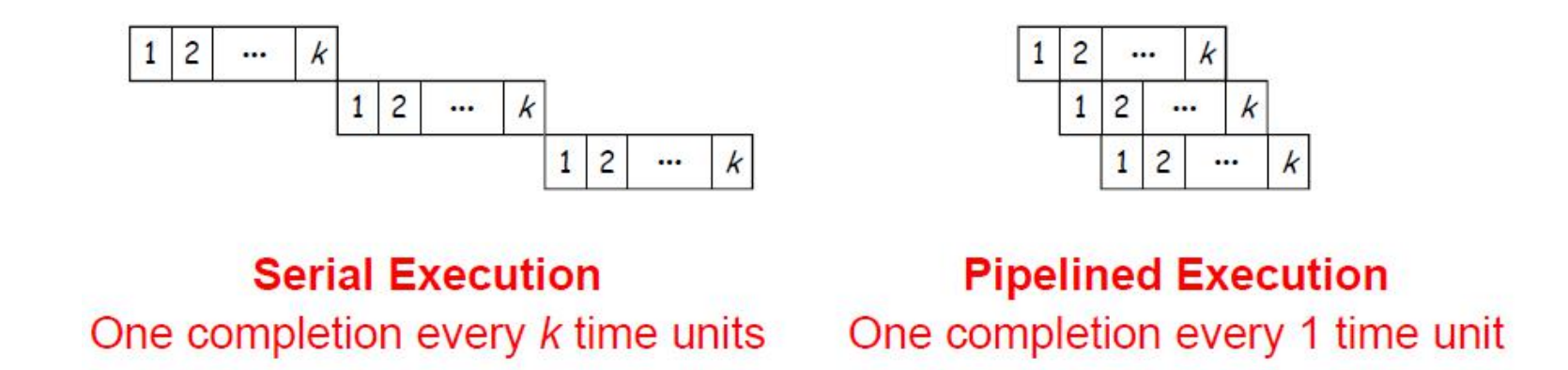
- 一个任务可以分解为
k个子任务k个子任务在k个不同阶段(使用不同的资源)运行- 每个子任务执行需要1个单位时间
- 整个任务的执行时间为
k倍单位时间
- 流水线执行模式是重叠执行模式
k个流水段并行执行k个不同任务- 每个单位时间进入/离开流水线一个任务
流水线性能衡量:
- 设$\tau_i = time\ delay\ in\ stage\ S_i$
- 时钟周期$\tau = max(\tau_i)$为最长的流水段延迟
- 时钟频率$f = \frac{1}{\tau} = \frac{1}{max(\tau_i)}$
- 流水线可以再
k + n -1个时钟周期完成n个任务- 完成第一个任务需要
k个时钟周期 - 其他
n-1个任务需要n-1个时钟周期
- 完成第一个任务需要
k段流水线的理想加速比(相对于串行执行)- $S_k = \frac{Serial\ execution\ in\ cycles}{Pipelined\ execution\ in\ cycles}=\frac{nk}{k+n-1}$
典型的RISC 5段指令流水线
- 5个流水段,每段的延迟为1个cycle
IF(Instruction Fetch):取指令阶段- 选择地址:下一条指令地址、转移地址
ID(Instruction Decode):指令译码- 确定控制信号并从寄存器文件中读取寄存器值
EX(Execute Address Calc):执行Load/Store:计算有效地址Branch:计算转移地址并确定转移方向
MEM(Memory Access):存储器访问(仅Load和Store)WB(Write Back):结果写回
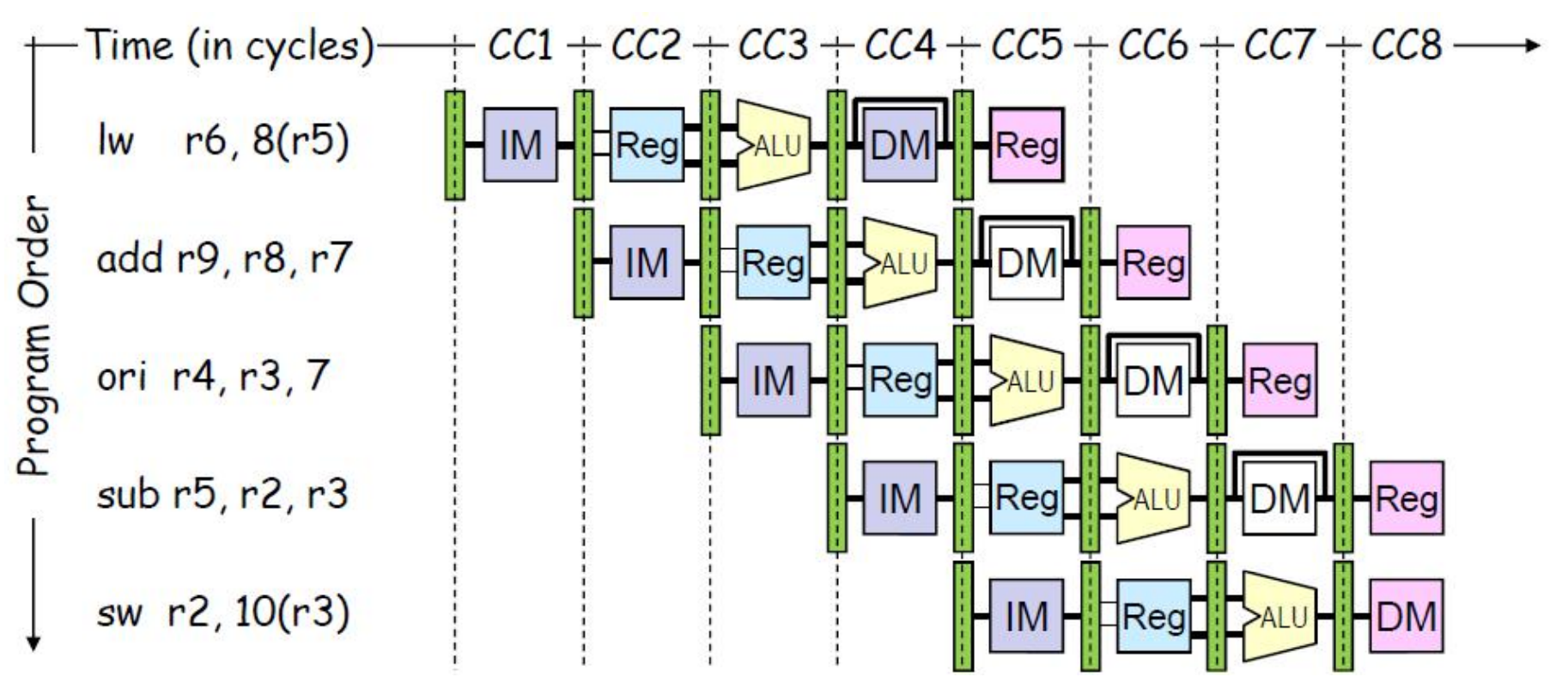
流水线的可视化表示:多条指令执行多个时钟周
- 指令按程序序从上到下排列
- 图中展示了每一时钟周期资源的使用情况
- 不同指令相邻阶段之间没有干扰
流水线的技术要点:
- 流水线的基本概念
- 多个任务重叠(并发/并行)执行,但使用不同的资源
- 流水线技术提高整个系统的吞吐率,不能缩短单个任务的执行时间
- 其潜在的加速比=流水线的级数
- 流水线正常工作的基本条件
- 增加寄存器文件保存当前段传送到下一段的数据和控制信息
- 需要更高的存储器带宽
- 流水线的相关
Hazards问题- 由于存在相关
Hazards问题,会导致流水线停顿 Hazards问题:流水线的执行可能会导致对资源的访问冲突,或破坏对资源的访问顺序
- 由于存在相关
流水线的相关Hazards:
- 结构相关:流水线中一条指令可能需要另一条指令使用的资源
- 数据和控制相关:一条指令可能依赖于先前的指令生成的内容
- 数据相关:依赖先前指令产生的结果(数据)值
- 控制相关:依赖关系是如何确定下一条指令地址(
branches,exceptions)
- 处理相关的一般方法是插入
bubble,导致CPI>1(单发射理想CPI)
消减结构相关:
- 当两条指令同时需要相同的硬件资源时,就会发生结构相关(冲突)
- 方法1:通过将新指令延迟到前一条指令执行完(释放资源后)执行
- 方法2:增加新的资源。例如,如果两条指令同时需要操作存储器,可以通过增加到两个存储器操作端口来避免结构冲突
- 经典的
RISC5-段整型数流水线通过设计可以没有结构相关- 很多
RISC实现在时存在结构相关。例如多周期操作的multipliers、dividers、floating-point units等,由于没有多个寄存器文件写端口导致结构冲突
- 很多
三种基本的数据相关:
- 写后读相关:
RAW, Read After Write - 读后写相关:
WAR, Write After Read - 写后写相关:
WAW, Write After Write
消减数据相关的三种策略:
- 联锁机制(
Interlock):在issue阶段保持当前相关指令,等待相关解除 - 设置旁路定向路径(
Bypass or Forwarding):只要结果可用,通过旁路尽快传递数据 - 投机(Speculate):猜测一个值继续,如果猜测错了再更正。这种技术,仅在某些情况下可以使用
- 分支预测
- 堆栈指针更新
- 存储器地址消除歧义
延迟槽技术(Branch Delay Slots)
- 对于分支跳转指令,在指令执行完毕之前,无法知道下一条指令的具体位置。而cpu又是流水线执行,因此需要插入一些空指令,这些空指令
NOP所占据的时空就称谓延迟槽。更高级的做法是,将一些与分支跳转指令无关的指令,填充到这个延迟槽中,以提高指令执行效率 - 软件不得不填充延迟槽,即用
NOP或者真实指令填充延迟槽
Post-1990 RISC ISAs取消了延迟槽
- 性能问题
- 当延迟槽中填充了
NOP指令后,增加了I-Cache的失效率 - 即使延迟槽中只有一个
NOP,I-Cache失效导致机器等待
- 当延迟槽中填充了
- 使先进的微体系架构复杂化
- 分支预测技术的进步减少了采用延迟槽技术的动力
解决控制相关的方法
Stall直到分支方向确定- 可通过修改数据通路,减少
Stall
- 可通过修改数据通路,减少
- 预测分支失败
- 直接执行后继指令
- 如果分支实际情况为分支成功,则撤销流水线中的指令对流水线状态的更新
- 要保证:分支结果出来之前不会改变处理机的状态,以便一旦猜错时,处理机能够回退到原先的状态
- 预测分支成功
- 前提:先知道分支目标地址,后知道分支是否成功
- 延迟转移技术
为什么在经典的五段流水线中指令不能在每个周期都被分发CPI>1
- 采用全定向路径可能代价太高而无法实现
- 通常提供经常使用的定向路径
- 一些不经常使用的定向路径可能会增加时钟周期的长度,从而抵消降低CPI的好处
Load操作有两个时钟周期的延迟- Load指令后的指令不能马上使用
Load的结果 MIPS-I ISA定义了延迟槽,软件可见的流水线冲突(由编译器调度无关的指令或插入NOP指令避免冲突),MIPS-II中取消了延迟槽语义(硬件上增加流水线interlocks机制)
- Load指令后的指令不能马上使用
Jumps/Conditional branches可能会导致流水线断流(bubbles)- 如果没有延迟槽,则
Stall后续的指令
- 如果没有延迟槽,则
- 带有软件可见的延迟槽有可能需要执行大量的由编译器插入的
NOP指令NOP指令降低了CPI,增加了程序中执行的指令条数
流水线的性能分析:
- 衡量指标
- 吞吐率:假设
k段,完成n个任务,单位时间所实际完成的任务数 - 加速比:
k段流水线的速度与等功能的非流水线的速度之比 - 效率:流水线的设备利用率
- 吞吐率:假设
- 影响流水线性能的因素
- 流水线中的瓶颈——最慢的那一段
- 流水段所需时间不均衡将降低加速比
- 流水线存在装入时间和排空时间,使得加速比降低
对MIPS的扩充:
Integer部件处理:Loads、Store、Integer ALU操作和BranchFP/Integer乘法部件:处理浮点数和整数乘法FP加法器:处理FP加,减和类型转换FP/Integer除法部件:处理浮点数和整数除法- 这些功能部件未流水化
3.2 基本流水线的扩展
3.2.1 异常处理
陷阱和中断:
- 异常(Exception):由程序执行过程中引起的异常「内部事件」
- 陷阱(Trap):因异常情况而被迫将控制权移交给监控程序
- 中断(Interrupt):响应(处理)程序之外的「外部事件」,导致控制权转移到监控程序
- 陷阱和中断通常由同样的流水线机制处理
异步中断:
I/O设备通过发出中断请求信号来请求处理- 当处理器决定响应该中断时
- 停止当前指令
li的执行,执行完当前指令前面的指令(执行完li-1) (精确中断) - 将
li指令的PC值保存到专门寄存器EPC中 - 关中断并将控制转移到以监控模式运行的指定的中断处理程序
- 停止当前指令
Interrupt Handler:
- 允许嵌套中断时,在开中断之前需要保存
EPC- 需要执行指令将
EPC存入GPRs - 至少在保存EPC之前,需要一种方法来暂时屏蔽进一步的中断
- 需要执行指令将
- 需要读取记录中断原因的状态寄存器
- 使用专门的间接跳转指令
ERET(returnfrom-environment) 返回- 开中断
- 将处理器恢复到用户模式
- 恢复硬件状态和控制状态
Synchronous Trap:
- 同步陷阱是由特定指令执行的异常引起的
- 通常,该指令无法完成,需要在处理异常之后重新启动
- 需要撤消一个或多个部分执行的指令的效果
- 在系统调用(陷阱)的情况下,该特殊的跳转指令被认为已经完成
- 一种特殊的跳转指令,涉及到切换到特权模式的操作
Exception Handling:
- 在流水线中将异常标志保留到提交阶段
- 在提交阶段并入异步中断请求 (抑制其他中断)
- 针对某一给定的指令,早期流水阶段中的异常抑制该指令的后续异常
- 如果提交时检测到异常:
- 更新异常原因及
EPC寄存器 - 终止所有流水段
- 将异常处理程序的地址送入
PC寄存器,以跳转到处理程序中执行
- 更新异常原因及
异常的推测:
- 预测机制
- 异常总是比较少的,所以简单地预测为没有异常
- 检查预测机制
- 在指令执行的最后阶段进行异常检测
- 采用专门的硬件用于检测各种类型的异常
- 恢复执行机制
- 仅在提交阶段改变机器状态,因此可以在发生异常后丢弃部分执行的指令
- 刷新流水线后启动异常处理程序
- 定向路径机制允许后续的指令使用没有提交的指令结果
3.2.2 多周期操作
问题:
- 浮点操作在1~2个
cycles完成是不现实的,一般要花费较长时间 - 在MIPS中如何处理
在1到2个cycles时间内完成的处理方法:
- 采用较慢的时钟源,或
- 在
FP部件中延迟其EX段
现假设FP指令与整数指令采用相同的流水线,那么:
EX段需要循环多次来完成FP操作,循环次数取决于操作类型- 有多个
FP功能部件,如果发射出的指令导致结构或数据相关,需暂停
Latency和Repeat Interval:
- 延时
Latency- 定义1:完成某一操作所需的
cycle数 - 定义2:使用当前指令所产生结果的指令与当前指令间的最小间隔周期数
- 定义1:完成某一操作所需的
- 循环间隔(Repeat/Initiation interval)
- 发射相同类型的操作所需的间隔周期数
- 对于
EX部件流水化的新的MIPS
Function Unit |
Latency |
Repeat Interval |
|---|---|---|
| Integer AU | 0 | 1 |
| Data Memory (Integer and FP loads(1 less for store latency)) | 1 | 1 |
| FP Add | 3 | 1 |
| FP multiply | 6 | 1 |
| FP Divide (also integer divide and FP sqrt) | 24 | 25 |
将部分执行部件流水化后的MIPS流水线如下图
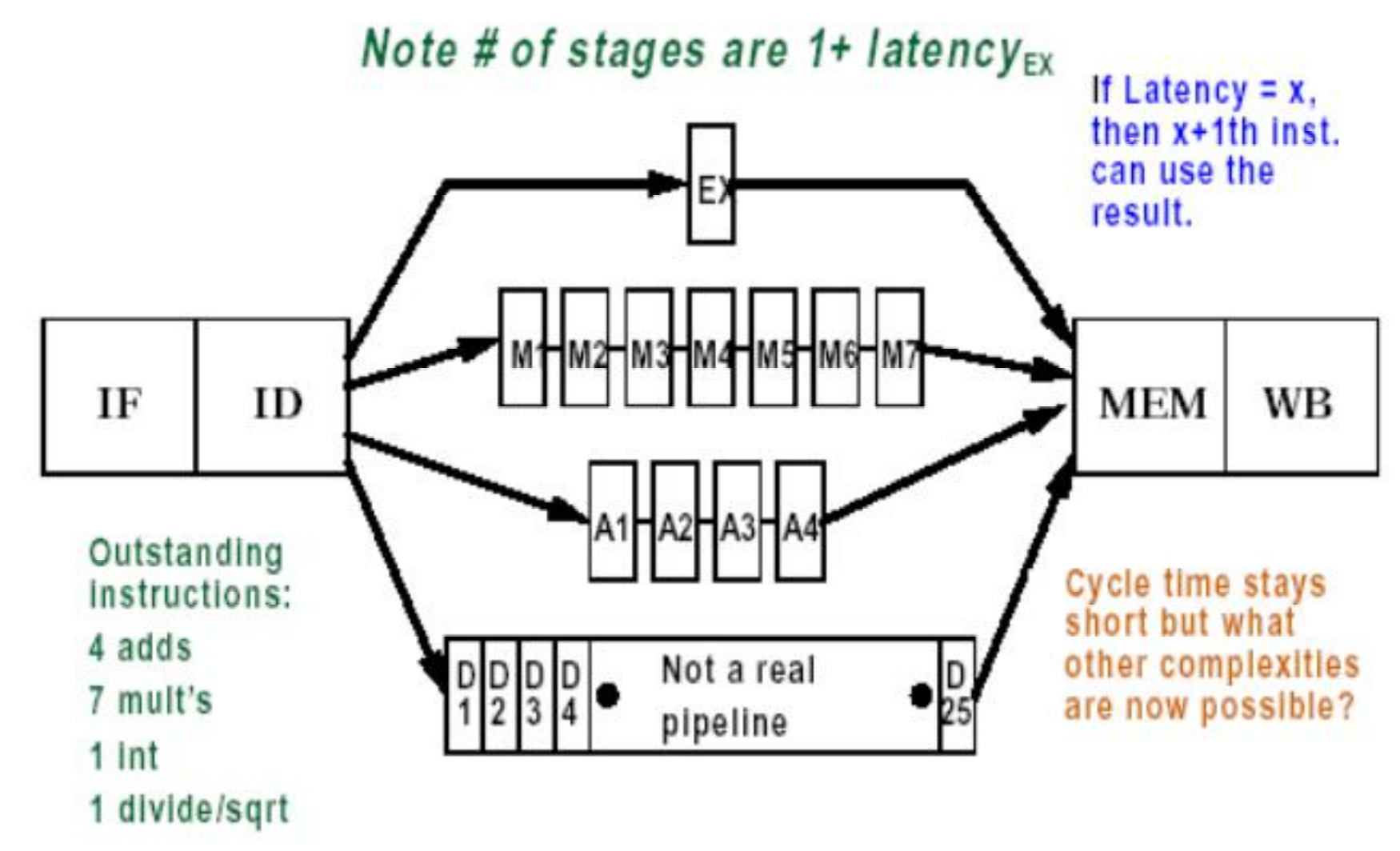
新的相关和定向问题:
- 结构冲突增多
- 非流水的
Divide部件,使得EX段增长24个cycles
- 非流水的
- 在一个周期内可能有多个寄存器写操作
- 可能指令乱序完成(乱序到达
WB段)有可能存在WAW - 乱序完成导致异常处理复杂
- 由于指令的延迟加大导致
RAW相关的stall数增多 - 需要付出更多的代价来增加定向路径
解决方法:
- 方法1
- 在
ID段跟踪写端口的使用情况,以便能暂停该指令的发射 - 一旦发现冲突,暂停当前指令的发射
- 在
- 方法2
- 在进入
MEM或WB段时,暂停冲突的指令,让有较长延时的指令先做。这里假设较长延时的指令,可能会更容易引起其他RAW相关,从而导致更多的stalls
- 在进入
精确异常与非精确异常:
- 精确异常
- 如果流水线可以控制使得引起异常的指令前序指令都执行完,故障后的指令可以重新执行,则称该流水线支持精确异常
- 按照指令的逻辑序处理异常
- 理想情况,引起故障的指令没有改变机器的状态
- 要正确的处理这类异常请求,必须保证故障指令不产生副作用
- 在有些机器上,浮点数异常
- 流水线段数多,在发现故障前,故障点后的指令就已经写了结果,在这种情况下,必须有办法处理
- 很多高性能计算机,
Alpha 21164、MIPS R10000等支持精确中断,但精确模式要慢10+倍,一般用在代码调试时,很多系统要求精确异常模式,如IEEE FP标准处理程序,虚拟存储器等
- 精确异常对整数流水线而言,不是太难实现
- 指令执行的中途改变机器的状态
- 例如
IA-32的自动增量寻址模式
处理异常的4种可能的办法:
- 方法1:忽略这种问题,当非精确处理
- 但现代计算机对
IEEE浮点标准的异常处理,虚拟存储的异常处理要求必须是精确异常。
- 但现代计算机对
- 方法2:缓存操作结果,直到早期发射的指令执行完
- 当指令运行时间较长时,
Buffer区较大 future file(Power PC620 MIPS R10000)- 缓存执行结果,按指令序确认
history file(CYBER 180/990)- 尽快确认
- 缓存区存放原来的操作数,如果异常发生,回卷到合适的状态
- 当指令运行时间较长时,
- 方法3:以非精确方式处理,用软件来修正
- 为软件修正保存足够的状态
- 让软件仿真尚未执行完的指令的执行
- 例如
Instruction 1 – A执行时间较长,引起中断的指令Instruction 2, instruction 3, ….instruction n-1未执行完的指令Instruction n已执行完的指令- 由于第
n条指令已执行完,希望中断返回后从第n+1条指令开始执行,如果我们保存所有的流水线的PC值,那么软件可以仿真Instruction 1到Instruction n-1的执行
- 方法4:暂停发射,直到确定先前的指令都可无异常的完成,再发射下面的指令
- 在EX段的前期确认(MIPS流水线在前三个周期中)
MIPS R2K to R4K以及Pentium使用这种方法
3.2.3 MIPS R4000
MIPS R4000是64-bit机器
- 主频
100MHz ~200MHz - 较深的流水线(级数较多)(有时也称为
superpipelining)
MIPS R4000的8级整数流水线:
IF:取指阶段前半部分,选择PC值,初始化指令Cache的访问IS:取指阶段后半部分,主要完成访问指令Cache的操作RF:指令译码,寄存器读取,相关检测及指令Cache命中检测EX:执行,包括计算有效地址,进行ALU操作,计算分支目标地址和检测分支条件DF:取数据,访问数据Cache的前半部分DS:访问数据Cache的后半部分TC–tag:检测,确定数据Cache是否命中WB–Load:操作和R-R操作的结果写回
3.3 小结
3.4 相关课件
4 存储层次结构设计
存储层次结构:
- 存储系统设计是计算机体系结构设计的关键问题之一
- 容量、价格、速度的权衡
- 用户对存储器的容量、价格和速度的要求是相互矛盾的
- 速度越快,每位价格就高
- 容量越大,每位价格就低
- 容量越大,速度就越慢
- 目前主存一般由
DRAM构成
Microprocessor与Memory之间的性能差异越来越大CPU性能提高大约60%/yearDRAM性能提高大约9%/year
存储系统的设计目标:
- 目标:针对典型应用平均访存时间最短
- 途径:通过优化存储系统的组织
多级分层结构:cpu -> M1 -> M2 -> ... -> Mn
M1速度最快,容量最小,每位价格最高Mn速度最慢,容量最大,每位价格最低- 存储系统接近
M1的速度,容量和价格接近Mn - 并行
CPU |
L1 Cache |
L2 Cache |
L3 Cache |
Memory |
I/O Device |
|
|---|---|---|---|---|---|---|
speed |
300-500ps | 1-2ns | 3-10ns | 10-20ns | 50-100ns | 5-10ms |
capacity |
500-1000B | 64KB | 256KB | 2-4MB | > 1GB | > 100GB |
存储层次工作原理:Locality
- 应用程序局部性原理:给用户
- 一个采用低成本技术达到的存储容量(容量大,价格低)
- 一个采用高速存储技术达到的访问速度(速度快)
- Temporal Locality(时间局部性)
- 保持最近访问的数据项最接近微处理器
- Spatial Locality(空间局部性)
- 以由地址连续的若干个字构成的块为单位,从低层复制到上一层
存储层次结构涉及的基本概念
- Block
- 不同层次的Block大小可能不同
- 命中和命中率
- 失效和失效率
- 镜像和一致性问题
- 高层存储器是较低层存储器的一个镜像
- 高层存储器内容的修改必须反映到低层存储器中
- 数据一致性问题
- 寻址:不管如何组织,我们必须知道如何访问数据
- 要求:不同层次上块大小可以不同
- 以块为单位进行数据交换
- 不同级
Cache块的大小可能不同 - 页面(块)大小通常大于
Cache块大小 - 存在地址映射问题
- 物理地址格式
Block Frame Address + Block Offset
存储层次的性能参数(假设采用二级存储:M1和M2,M1和M2的容量价格访问时间分别为S1, C1, TA1以及S2, C2, TA2)
- 存储层次的平均每位价格
CC = (C1 * S1 + C2 * S2)/(S1 + S2)
- 命中(
Hit):访问的块在存储系统的较高层次上- 若一组程序对存储器的访问,其中
N1次在M1中找到所需数据,N2次在M2中找到数据 则 Hit Rate(命中率):存储器访问在较高层命中的比例H = N1/(N1 + N2)Hit Time(命中时间):访问较高层的时间,TA1
- 若一组程序对存储器的访问,其中
- 失效(
Miss):访问的块不在存储系统的较高层次上Miss Rate(失效率)= 1 - (Hit Rate) = 1 - H = N2/(N1 + N2)- 当在
M1中没有命中时:一般必须从M2中将所访问的数据所在块搬到M1中,然后CPU才能在M1中访问 - 设传送一个块的时间为
TB,即不命中时的访问时间为:TA2 + TB + TA1 = TA1 + TMTM通常称为失效开销
- 平均访存时间
TA = H * TA1 + (1 - H)(TA1 + TM) = TA1 + (1 - H)TM:平均访存时间 = 命中时间 + 失效率 * 失效开销
常见的存储层次的组织:
Registers<->Memory:由编译器完成调度Cache<->Memory:由硬件完成调度Memory<->Disk:由硬件、操作系统、应用程序完成调度
在体系结构中,Cache无处不在
- 寄存器:
Cache on variables 1-2级Cache:Cache on memoryMemory:Cache on hard diskshard disk可以视为主存的扩展(VM)
4.1 Cache的基本概念
Cache
- 小而快(
SRAM)的存储技术- 存储正在访问的部分指令和数据
- 用于减少平均访存时间
- 通过保持最近访问的数据在处理器附近来挖掘时间局部性
- 通过以块为单位在不同层次移动数据来挖掘空间局部性
- 主要目标:
- 提高访存速度
- 降低存储系统成本
Cache的四个问题
- 映像规则
- 查找方法
- 替换算法
- 写策略
映像规则:把一个块从主存调入Cache时,如何放置的问题
- 全相联映像:即所调入的块可以放在
Cache中的任何位置 - 直接相联映像:主存中每一块只能存放在
Cache中的唯一位置- 一般,主存块地址
i与Cache中块地址j的关系为:j = i mod (M),其中M为Cache中的块数
- 一般,主存块地址
- 组相联映像:主存中每一块可以被放置在
Cache中唯一的一个组中的任意一个位置,组由若干块构成,若一组由n块构成,我们称N路组相联- 组间直接映像
- 组内全映像
- 如果
Cache中有G组,则主存中第i块的组号K = i mod (G)
不同相联度下的路数和组数,假设Cache的块数为M,每组由N个块构成,那么Cache的组数G = M/N
- 相联度越高,
Cache空间利用率就越高,块冲突概率就越小,失效率就越低 N值越大,失效率就越低,但Cache的实现就越复杂,代价越大- 现代大多数计算机都采用直接相联,两路或四路组相联
| 路数 | 组数 | |
|---|---|---|
| 全相联 | M |
1 |
| 直接相联 | 1 |
M |
| 组相联 | 1 < N < M |
1 < G < M |
Cache查找方法
- 在
Cache中每一block都带有tag域(标记域),标记分为两类- Address Tags:标记所访问的单元在哪一块中,这样物理地址就分为三部分:
Address Tags ## Block index ## block Offset- 全相联没有
Block Index Address Tags越短,查找所需代价就越小
- 全相联没有
Status Tags:标记该块的状态,如Valid、Dirty等
- Address Tags:标记所访问的单元在哪一块中,这样物理地址就分为三部分:
- 原则:所有可能的标记并行查找,
Cache的速度至关重要,即并行查找 - 并行查找的方法
- 用相联存储器实现,按内容检索
- 用单体多字存储器和比较器实现
- 相联度
N越大,实现查找的机制就越复杂,代价就越高 - 无论直接相联还是组相联,查找时,只需比较
tag,index无需参加比较
Cache替换算法
- 主存中块数一般比
Cache中的块多,可能出现该块所对应的一组或一个Cache块已全部被占用的情况,这时需强制腾出其中的某一块,以接纳新调入的块,替换哪一块,这是替换算法要解决的问题- 直接映象,因为只有一块,别无选择
- 组相联和全相联有多种选择
- 替换方法
- 随机法(Random),随机选择一块替换
- 优点:简单,易于实现
- 缺点:没有考虑
Cache块的使用历史,反映程序的局部性较差,失效率较高
FIFO-选择最早调入的块- 优点:简单
- 虽然利用了同一组中各块进入
Cache的顺序,但还是反映程序局部性不够,因为最先进入的块,很可能是经常使用的块
- 最近最少使用法(LRU, Least Recently Used)
- 优点:较好的利用了程序的局部性,失效率较低
- 缺点:比较复杂,硬件实现较困难
- 随机法(Random),随机选择一块替换
- 实验结论
- 相联度高,失效率较低。
Cache容量较大,失效率较低。LRU在Cache容量较小时,失效率较低- 随着
Cache容量的加大,Random的失效率在降低
Cache写策略
- 程序对存储器读操作占
26%, 写操作占9%- 写所占的存储器访问比例
9/(100+26+9)大约为7% - 写所占访问数据
Cache的比例:9/(26+9)大约为25%
- 写所占的存储器访问比例
- 大概率事件优先原则:优化
Cache的读操作 Amdahl定律:不可忽视写的速度- 写策略就是要解决:何时更新主存问题
- 写命中(
Write Hit)时的两种策略- 写直达法(
Write Through):当写Cache命中时,Cache与主存同时发生写修改,因而较好的维护了与主存的内容一致性- 优点:易于实现,容易保持不同层次间的一致性
- 缺点:速度较慢
- 写回法(
Write Back):只修改Cache的内容,而不立即写入主存。只有当此行被换出时才写回主存- 优点:速度快,减少访存次数
- 缺点:一致性问题
- 写直达法(
- 写失效(
Write Miss)时的两种策略- 什么是写失效?当我们要更新主存时,发现主存中存储的数据与
Cache中不一致(换言之,Cache中的数据已过时) - 按写分配法(
Write Allocate):写失效时,先把所写单元所在块调入Cache,然后再进行写入,也称写时取(Fetch on Write)方法 - 不按写分配法(
No-write Allocate):写失效时,直接写入下一级存储器,而不将相应块调入Cache,也称绕写法(Write Around) - 原则上以上两种方法都可以应用于写直达法和写回法,一般情况下
Write Back用Write AllocateWrite Through用No-write Allocate
- 什么是写失效?当我们要更新主存时,发现主存中存储的数据与
4.2 Cache的基本优化方法
Cache性能分析指标:
CPU time = (CPU execution clock cycles + Memory stall clock cycles) ✖️ clock cycle timeMemory stall clock cycles = (Reads ✖️ Read miss rate ✖️ Read miss penalty) + (Writes ✖️ Write miss rate ✖️ Write miss penalty)Memory stall clock cycles = Memory accesses ✖️ Miss rate ✖️ Miss penalty
改进Cache性能的基本途径:
- 降低失效率
- 增加Cache块的大小
- 增大Cache容量
- 提高相联度
- 减小失效开销
- 多级Cache
- 使读失效优先于写失效
- 缩短命中时间
- 避免在索引缓存期间进行地址转换
4.2.1 降低失效率
Cache失效的原因可以分为三类
- 强制性失效(
Compulsory)- 第一次访问某一块,只能从下一级
Load,也称为冷启动或首次访问失效
- 第一次访问某一块,只能从下一级
- 容量失效(
Capaticy)- 如果程序执行时,所需块由于容量不足,不能全部调入
Cache,则当某些块被替换后,若又重新被访问,就会发生失效 - 可能会发生抖动现象
- 如果程序执行时,所需块由于容量不足,不能全部调入
- 冲突失效(
Conflict/Collision)- 组相联和直接相联的副作用
- 若太多的块映像到同一组(块)中,则会出现该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况,这就属于冲突失效
一些统计规律:
- 相联度越高,冲突失效就越小
- 强制性失效和容量失效不受相联度的影响
- 强制性失效不受Cache容量的影响
- 容量失效随着容量的增加而减少
2:1Cache经验规则:即大小为N的直接映象Cache的失效率约等于大小为N/2的两路组相联的Cache失效率
降低失效率的方法:
- 增大Cache容量
- 对冲突和容量失效的减少有利
- 增大块
- 减缓强制性失效
- 可能会增加冲突失效(因为在容量不变的情况下,块的数目减少了)
- 通过预取可帮助减少强制性失效
- 必须小心不要把你需要的东西换出去
- 需要预测比较准确(对数据较困难,对指令相对容易)
块大小、容量的权衡:
- 从统计数据可得到的结论
- 对于给定Cache容量,块大小增加时,失效率开始是下降,但后来反而上升
Cache容量越大,使失效率达到最低的块大小就越大
- 分析
- 块大小增加,可使强制性失效减少(空间局部性原理)
- 块大小增加,可使冲突失效增加(Cache中块数量减少)
- 失效开销增大(上下层间移动,数据传输时间变大)
- 设计块大小的原则,不能仅看失效率
提高相联度
- 8路组相联在降低失效率方面的作用已经和全相联一样有效
- 提高相联度,会增加命中时间
Victim Cache
- 基本思想
- 通常
Cache为直接映象时冲突失效率较大 Victim Cache采用全相联,因此失效率较低Victim Cache存放由于(冲突)失效而被丢弃的那些块- 失效时,首先检查
Victim Cache是否有该块,如果有就将该块与Cache中相应块互换
- 通常
Jouppi (DEC SRC)发现- 含1到5项的
Victim Cache对减少失效很有效,尤其是对于那些小型的直接映象数据Cache - 测试结果,项为4的
Victim Cache能使4KB直接映象数据 Cache冲突失效减少20%-90%
- 含1到5项的
4.2.2 减小失效开销
基本手段:
- 多级
Cache技术(Multilevel Caches) - 让读优先于写(
Giving Priority to Read Misses over Writes)
多级Cache
- 一级
Cache保持较小容量- 降低命中时间
- 降低每次访问的能耗
- 增加二级
Cache- 减少与存储器的
gap - 减少存储器总线的负载
- 减少与存储器的
- 多级
Cache的优点- 减少失效开销
- 缩短平均访存时间(
AMAT)
- 较大容量的
L2 Cache可以捕捉许多L1 Cache的失效- 降低全局失效率
多级包容性(multilevel inclusive)
L1 Cache的块总是存在于L2 Cache中- 浪费了
L2 Cache空间,L2还应当有存放其他块的空间
- 浪费了
- 在
L1中miss,但在L2中命中,则从L2拷贝相应的块到L1 - 在
L1和L2中均miss, 则从更低级拷贝相应的块到L1和L2 - 对
L1写操作导致将数据同时写到L1和L2 Write Through策略用于L1到L2Write Back策略可用于L2到更低级存储器,以降低存储总线的数据传输压力L2的替换动作(或无效)对L1可见- 即
L2的一块被替换出去,那么其在L1中对应的块也要被替换出去
- 即
L1和L2的块大小可以相同也可以不同
多级不包容(Multilevel Exclusive)
L1 Cache中的块不会在L2 Cache中,以避免浪费空间- 在
L1中miss,但在L2中命中,将导致Cache间块的互换 - 在
L1和L2均miss,将仅仅从更低层拷贝相应的块到L1 L1的被替换的块移至L2L2存储L1抛弃的块,以防后续L1还需要使用
L1到L2的写策略为Write-BackL2到更低级Cache的写策略为Write-BackAMD Athlon:64KB L1、256KB L2
多级Cache的性能分析
- 局部失效率:该级
Cache的失效次数/到达该级Cache的访存次数 - 全局失效率:该级
Cache的失效次数/CPU发出的访存总次数- 全局失效率是度量
L2 Cache性能的更好方法
- 全局失效率是度量
两级Cache的一些研究结论
- 在
L2比L1大得多得情况下,两级Cache全局失效率和容量与第二级Cache相同的单级Cache的失效率接近 - 局部失效率不是衡量第二级
Cache的好指标- 它是第一级
Cache失效率的函数 - 不能全面反映两级
Cache体系的性能
- 它是第一级
- 第二级Cache设计需考虑的问题
- 容量:一般很大,可能没有容量失效,只有强制性失效和冲突失效
- 相联度对第二级Cache的作用
Cache可以较大,以减少失效次数
- 多级包容性问题:第一级
Cache中的数据是否总是同时存在于第二级Cache中- 如果
L1和L2的块大小不同,增加了多级包容性实现的复杂性
- 如果
- 容量:一般很大,可能没有容量失效,只有强制性失效和冲突失效
让读失效优先于写
- 由于读操作为大概率事件,需要读失效优先,以提高性能
Write Through Cache->Write Buffer(写缓冲),特别对写直达法更有效Write Buffer:CPU不必等待写操作完成,即将要写的数据和地址送到Write Buffer后,CPU继续作其他操作- 写缓冲导致对存储器访问的复杂化
- 解决问题的方法
- 推迟对读失效的处理,直到写缓冲器清空,导致新的问题——读失效开销增大。
- 在读失效时,检查写缓冲的内容,如果没有冲突,而且存储器可访问,就可以继续处理读失效
- 写回法时,也可以利用写缓冲器来提高性能
- 把脏块放入缓冲区,然后读存储器,最后写存储器
Write Back Cache->Victim Buffer- 被替换的脏块放到了
Victim Buffer - 在脏块被写回前,需要处理读失效
- 问题:
Victim Buffer可能含有该读失效要读取的块- Solution:查找
Victim Buffer,如果命中直接将该块调入Cache
- Solution:查找
- 被替换的脏块放到了
4.3 Cache的高级优化方法
4.3.1 缩短命中时间
- 小而简单的第一级
Cache - 路预测方法
4.3.2 增加Cache带宽
Cache访问流水化- 提高
Cache的带宽,有利于采用高相联度的缓存 L1 Cache的访问由多个时钟周期构成- 缺点
- 增加了分支预测错误造成的额外开销
- 增加了
Load指令与要使用其结果的指令间的latency - 增加了
I-Cache和D-Cache的延时
- 提高
- 无阻塞
Cache - 多体
Cache
4.3.3 减小失效开销
- 关键字优先和提前重启
- 合并写
4.3.4 降低失效率
- 编译优化
4.3.5 通过并行降低失效开销或失效率
- 硬件预取
- 编译器控制的预取
4.4 存储器技术与优化
存储器
- 存储器的访问源
- 取指令、取操作数、写操作数和
I/O
- 取指令、取操作数、写操作数和
- 存储器性能指标
- 容量、速度和每位价格
- 访问时间(Access Time)
- 存储周期(Cycle Time)
- 种类:
DRAM和SRAMMemory:DRAMCache:SRAM
DRAM
DRAM是由单个信息位构成的阵列- 通过行选择线和列选择线访问
- 所有DRAM都由这些阵列构成
- 不同的结构根据性能的需求选择的阵列数可能不同
- 所有
DRAM的访问至少三个阶段Prechargerow accesscolumn acces
DRAM的性能Latency- 地址信号有效到第一组数据信号有效所需要的时间
- 处理器发出请求到所请求的第一组数据到达处理器输入引脚所需要的
cycle数
Bandwidth- 第一组数据到达后,后续数据到达的速率
提高主存性能的方法:增大存储器的宽度(并行访问存储器)
- 最简单直接的方法
- 优点:简单、直接,可有效增加带宽
- 缺点
- 增加了CPU与存储器之间的连接通路的宽度,实现代价提高
- 主存容量扩充时,增量应该是存储器的宽度
- 写操作问题(部分写操作)
- 冲突问题
- 取指令冲突,遇到程序转移时,一个存储周期中读出的n条指令中,后面的指令将无用
- 读操作数冲突。一次同时读出的几个操作数,不一定都有用
- 写操作冲突。这种并行访问,必须凑齐n个字之后一起写入。如果只写一个字,必须先把属于同一个存储字的数据读到数据寄存器中,然后在地址码的控制下修改其中一个字,最后一起写
- 读写冲突。当要读写的字在同一个存储字内时,无法并行操作
- 冲突的原因
- 从存储器本身看,主要是地址寄存器和控制逻辑只有一套
采用简单的多体交叉存储器
- 一套地址寄存器和控制逻辑
- 存储器组织为多个体(Bank)
- 存储体的宽度,通常为一个字,不需要改变总线的宽度
- 目的:在总线宽度不变的情况下,完成多个字的并行读写
- 存储模块中所包含的体数,为避免访问冲突,基本原则为:
- 体的数目
>=访问体中一个字所需的时钟周期数 - 例如:某一向量机的存储系统,CPU发出访存请求10个时钟周期后,CPU将从存储体0得到一个字,随后体0开始读该存储体的下一个字,而CPU依次从其余7个存储体中得到后继的7个字。在第18个周期,CPU 将需要存储体0提供下一个字,但该字要到第20个时钟周期才被读出,CPU只好等待
- 体的数目
- 缺陷:不能对单个体单独访问,对解决冲突没有帮助,逻辑上是一种宽存储器,对各个存储体的访问被安排在不同的时间段
4.5 虚拟存储器-基本原理
虚拟存储器
- 允许应用程序的大小,超过主存容量。目的是提高存储系统的容量
- 帮助OS进行多进程管理
- 每个进程可以有自己的地址空间
- 提供多个进程空间的保护
- 可以将多个逻辑块映射到共享的物理存储器上
- 静态重定位和动态重定位
- 应用程序运行在虚地址空间
- 虚实地址转换对用户是透明的
- 虚拟存储管理的是主存-辅助存储器这个层面上
- 失效:页失效或地址失效
- 块:页或段
Cache与VM的区别
- 目的不同
Cache是为了提高访存速度VM是为了提高存储容量
- 替换的控制者不同
Cache失效由硬件处理VM的页失效通常由OS处理- 一般页失效开销很大,因此替换算法非常重要
- 地址空间
VM空间由CPU的地址尺寸确定- Cache的大小与CPU地址尺寸无关
- 下一级存储器
Cache下一级是主存VM下一级是磁盘,大多数磁盘含有文件系统,文件系统寻址与主存不同,它通常在I/O空间中,VM的下一级通常称为SWAP空间
VM的四个问题
- 映像规则
- 查找方法
- 替换算法
- 写策略
映像规则
- 选择策略:低失效率(复杂映象算法) vs. 高失效率(简单映射方法)
- 由于失效开销很大,一般选择低失效率方法,即全相联映射
查找方法-用附加数据结构
- 固定页大小-用页表
VPN->PPNTag标识该页是否在主存
- 可变长段-段表
- 段表中存放所有可能的段信息
- 段号->段基址再加段内偏移量
- 可能存在许多小尺寸段
- 页表
- 页表中所含项数:一般为虚页的数量
- 功能:
VPN->PPN,方便页重新分配,有一位标识该页是否在内存
替换规则
LRU是最好的- 但真正的
LRU方法,硬件代价较大 - 用硬件简化,通过OS来完成
- 为了帮助OS寻找
LRU页,每个页面设置一个use bit - 当访问主存中一个页面时,其
use bit置位 - OS定期复位所有使用位,这样每次复位之前,使用位的值反映了从上次复位到现在的这段时间中,哪些页曾被访问过
- 当有失效冲突时,由OS来决定哪些页将被换出去
- 为了帮助OS寻找
写策略
- 总是用写回法(
Write Back),因为访问硬盘速度很慢
页面大小的选择
- 页面选择较大的优点
- 减少了页表的大小
- 如果局部性较好,可以提高命中率
- 页面选择较大的缺点
- 内存中的碎片较多,内存利用率低
- 进程启动时间长
- 失效开销加大
TLB:
- 页表一般很大,存放在主存中
- 导致每次访存可能要两次访问主存,一次读取页表项,一次读写数据
- 解决办法:采用
TLB
TLB- 存放近期经常使用的页表项,是整个页表的部分内容的副本
- 基本信息:
VPN##PPN##Protection Field##use bit ## dirty bit - OS修改页表项时,需要刷新
TLB,或保证TLB中没有该页表项的副本 - TLB必须在片内
- 速度至关重要
TLB过小,意义不大TLB过大,代价较高- 相联度较高(容量小)
4.6 小结
4.7 相关课件
5 指令级并行
5.1 指令级并行的基本概念及静态指令流调度
系统结构的Flynn分类:
SISD:单处理器模式SIMD:相同的指令作用在不同的数据MISD:无商业实现MIMD:通用性最强的一种结构,可用来挖掘线程级并行、数据级并行。组织方式可以是松耦合方式也可以是紧耦合方式
并行的层级:
- 请求级并行
- 多个任务可被分配到多个计算机上并行执行
- 进程级并行
- 进程可被调度到不同的处理器上并行执行
- 线程级并行
- 任务被组织成多个线程,多个线程共享一个进程的地址空间
- 每个线程有自己独立的程序计数器和寄存器文件
- 数据级并行
- 单线程(逻辑上)中并行处理多个数据(
SIMD/Vectorexecution) - 一个程序计数器,多个执行部件
- 单线程(逻辑上)中并行处理多个数据(
- 指令级并行(
ILP)- 针对单一指令流,多个执行部件并行执行不同的指令
指令级并行的基本概念及挑战:
ILP:无关的指令重叠(并行)执行- 流水线的平均
CPI- $\begin{split}Pipeline\ CPI\ =&\ Ideal\ Pipeline\ CPI\\&\ Struct\ Stalls\\&\ RAW\ Stalls\ +\ WAR\ Stalls\ +\ WAW\ Stalls\\&\ Control\ Stalls\\&\ Memory\ Stalls\end{split}$
- 本章研究:减少停顿(
stalls)数的方法和技术 - 基本途径
- 软件方法:
gcc:17%控制类指令,5 instructions + 1 branch- 在基本块上,得到更多的并行性
- 挖掘循环级并行
- 硬件方法
- 动态调度方法
- 以
MIPS的浮点数操作为例
- 软件方法:
循环展开
- 基本块的定义:
- 直线型代码,无分支
- 单入口
- 程序由分支语句连接基本块构成
- 循环级并行(
for (i = 1; i <= 1000; i++) x(i) = x(i) + s;)- 循环展开对循环间无关的程序是有效降低
stalls的手段 - 指令调度,必须保证程序运行的结果不变
- 注意循环展开中的
Load和Store,不同次循环的Load和Store是相互独立的。需要分析对存储器的引用,保证他们没有引用同一地址(检测存储器访问冲突) - 不同次的循环,使用不同的寄存器(寄存器重命名)
- 删除不必要的测试和分支后,需调整循环步长等控制循环的代码
- 循环展开对循环间无关的程序是有效降低
从编译器角度看代码移动
- 编译器分析程序的相关性依赖于给定的流水线
- 编译器通过指令调度来消除相关
- 数据相关
- 对于指令
i和j,如果指令j使用指令i产生的结果,或指令j与指令k相关,并且指令k与指令i有数据相关 - 如果相关,不能乱序执行
- 对于寄存器比较容易确定(
fixed names) - 但对
memory的引用,比较难确定
- 对于指令
- 另一种相关称为名相关(
name dependence):两条指令使用同名参数(register or memory location)但不交换数据- 反相关(
anti-dependence)- 指令
j所写的寄存器或存储单元,与指令i所读的寄存器或存储单元相同,注指令i先执行
- 指令
- 输出相关(
output dependence):(WAW if a hazard for HW)- 指令
i和指令j对同一寄存器或存储单元进行写操作,必须保证两条指令的写顺序
- 指令
- 访问存储单元时,很难判断名相关
- 反相关(
- 最后一种相关称为控制相关(
control dependence)- 例如
if p1 {S1;};:S1依赖于P1的测试结果 - 处理控制相关的原则
- 受分支指令控制的指令,不能移到控制指令之前,以免该指令的执行不在分支指令的控制范围
- 不受分支指令控制的指令,不能移到控制指令之后,以免该指令的执行受分支指令的控制
- 减少控制相关可以提高指令的并行性
- 例如
5.2 硬件方法挖掘指令级并行
为什么要使用硬件调度方案:
- 在编译时无法确定的相关,可以通过硬件调度来优化
- 简化编译器
- 代码在不同组织结构的机器上,同样可以有效地运行
基本思想:允许stall后的指令继续向前流动
- 允许乱序执行
5.2.1 指令流动态调度方法之一:Scoreboard
记分牌技术要点:
Out-of-order execution将ID段分为Issue:译码,检测结构相关Read operands:等待到无数据相关时,读操作数
- 起源于1964年
Control Data Corporation推出的CDC6000:顺序发射,乱序执行,乱序完成,没有采用定向技术,只实现非精确中断 - 集中相关(冲突)检查(
Scoreboard),互锁机制(interlock)解决相关 - 采用这种技术的微处理器企业
MIPS、HP、IBMSun公司的UltraSparcDEC Alpha
Out-of-order completion => WAR, WAW hazards?WAR:一般解决方案(在不采用寄存器重命名的情况下)- 对操作排队
- 仅在读操作数阶段读寄存器
WAW:检测到相关后,停止发射前一条指令,知道前一条指令完成
- 提高效率的前提:需要有多条指令进入执行阶段=>必须有多个执行部件或者执行部件是流水化的
- 记分牌保存相关操作和状态
- 指令执行过程:
IF、ISSUE、RO、EX、WR
记分牌控制的四阶段:
Issue:指令译码,检测结构相关- 如果当前指令所使用的功能部件空闲,并且没有其他活动的指令使用相同的目的寄存器(
WAW),记分牌发射该指令到功能部件,并更新记分牌内部数据,如果有结构相关或WAW相关,则该指令的发射暂停,并且也不发射后继指令,直到相关解除
- 如果当前指令所使用的功能部件空闲,并且没有其他活动的指令使用相同的目的寄存器(
Read operands:没有数据相关时,读操作数- 如果先前已发射的正在运行的指令不对当前指令的源操作数寄存器进行写操作,或者一个正在工作的功能部件已经完成了对该寄存器的写操作,则该操作数有效。操作数有效时,记分牌控制功能部件读操作数,准备执行
- 记分牌在这一步动态地解决了
RAW相关,指令可能会乱序执行
Execution:取到操作数后执行(EX)- 接收到操作数后,功能部件开始执行。当计算出结果后,它通知记分牌,可以结束该条指令的执行
Write result:finish execution(WR)- 一旦记分牌得到功能部件执行完毕的信息后,记分牌检测
WAR相关,如果没有WAR相关,就写结果,如果有WAR相关,则暂停该条指令
- 一旦记分牌得到功能部件执行完毕的信息后,记分牌检测
记分牌的结构:
Instruction status:记录正在执行的各条指令的状态步Functional unit status:记录功能部件(FU)的状态。用9个域记录每个功能部件的9个参量:Busy:指示该部件是否空闲Op:该部件所完成的操作Fi:其目的寄存器编号Fj, Fk:源寄存器编号Qj, Qk:产生源操作数Fj, Fk的功能部件Rj, Rk:标识源操作数Fj, Fk是否就绪的标志
Register result status:如果存在功能部件对某一寄存器进行写操作,在寄存器结果状态表中记录该功能部件。如果没有指令对该寄存器进行写操作,则该域为Blank
为什么顺序发射?
- 顺序发射使我们可以进行程序的数据流分析
- 我们可以知道某条指令的结果会流向哪些指令
- 如果我们乱序发射,可能会混淆
RAW和WAR相关
- 每一周期发射多条指令也使用该原则将会正确地工作
- 寄存器文件至少需要有
2x个读端口和x个写端口 - 当有寄存器重命名时,例如:
Tomasulo,还需要- 多端口的
rename table,以同时对一组指令所用的寄存器重命名
- 多端口的
- 在单周期内发射到多个
RS中
- 寄存器文件至少需要有
小结:
- 硬件方法挖掘
ILP- 编译阶段无法确定的相关性,在程序执行时,用硬件方法判定
- 可以使得程序代码在其他机器上有效地执行
- 记分牌的主要思想:允许
stall后的指令继续- 乱序执行(
out-of-order execution) => 乱序完成(out-of-order completion) - 发射前检测结构相关和
WAW相关 - 读操作数前检测
RAW相关 - 写结果前处理
WAR相关
- 乱序执行(
5.2.2 指令流动态调度方法之二:Tomasulo
Tomasulo用于在没有专用编译器的情况下,提高系统性能
Tomasulo三阶段:
Issue:从FP操作队列中取指令- 如果
RS空闲(no structural hazard),则控制发射指令和操作数(renames registers)
- 如果
Execution—operate on operands (EX)- 当两操作数就绪后,就可以执行如果没有准备好,则监测
Common Data Bus以获取结果
- 当两操作数就绪后,就可以执行如果没有准备好,则监测
Write result—finish execution (WB)- 将结果通过
Common Data Bus传给所有等待该结果的部件;表示RS可用
- 将结果通过
基本数据结构:
Instruction StatusReservation StationRegister Result Status
Tomasulo算法的特点:
- 控制和缓存分布在各部件中
FU缓存称reservation stations:保存待用操作数
- 指令中的寄存器在
RS中用寄存器值或指向RS的指针代替(称为register renaming)- 避免
WAR,WAW hazards RS多于寄存器,因此可以做更多编译器无法做的优化
- 避免
- 传给
FU的结果从RS来而不是从寄存器来,FU的计算结果通过Common Data Bus以广播方式发向所有功能部件Load和Store部件也看作带有RS的功能部件
- 可以跨越分支,允许
FP操作队列中FP操作不仅仅局限于基本块
5.3 分支预测方法
5.3.1 控制相关对于性能的影响
控制相关的动态解决技术
- 控制相关:
- 由条件转移或程序中断引起的相关,也称全局相关
- 控制相关对流水线的吞吐率和效率影响相对于数据相关要大得多
- 条件指令在一般程序中所占的比例相当大
- 中断虽然在程序中所占的比例不大,但中断发生在程序中的哪条指令,发生在一条指令执行过程中的哪个功能段都是不确定的
- 处理条件转移和异常引起的控制相关的关键问题:
- 要确保流水线能够正常工作
- 减少因断流引起的吞吐率和效率的下降
- 当分支方向预测错误时:
- 流水线中有多个功能段要浪费
- 可能造成程序执行结果发生错误
- 因此当程序沿着错误方向运行后,作废这些程序时,一定不能破坏通用寄存器和主存储器的内容
条件转移指令对流水线性能的影响:
- 条件转移指令对流水线的影响很大,必须采取相关措施来减少这种影响
- 预测可以是静态预测
Static (at compile time)或动态预测Dynamic (at runtime)
5.3.2 基于BHT的分支预测
术语:
Not taken | taken:跳转|不跳转(成功|失败)- 预测准确率(
Accuracy),预测错误率(Misprediction)
Branch History Table:
- 分支指令的PC的低位索引
- 该表记录上一次转移是否成功
- 不做地址检查
1-bit BHT以及2-bit BHT
1-bit BHT记录上一次跳转的结果2-bit BHT记录上两次跳转的结果
BHT正确性
- 分支预测错误的原因:
- 预测错误
- 由于使用
PC的地位查找BHT表,可能得到错误的分支历史记录
BHT表的大小问题- 4096项的表分支预测错误的比例为1%
- 再增加项数,对提高预测准确率几乎没有效果
5.3.3 基于BTB的分支预测
BTB, Branch Target Buffer
- 分支指令的地址作为
BTB的索引,以得到分支预测地址 - 投机执行面临的挑战:预测间接跳转
- 运行时才能确定分支目标地址
- 多数间接跳转来源于
Procedure Return- 采用
BTB时,对于过程返回的预测精度较低
- 采用
- 使用一个小的缓存(栈)存放
Return Address
5.4 基于硬件的推测执行
5.5 存储器访问冲突消解及多发射技术
5.6 多线程技术
多发射处理器受到的限制:
- 程序内在的
ILP的限制- 如果每5条指令中有1条相关指令:如何保持5-路
VLIW并行? - 部件的操作延时:许多操作需要调度,使部件延时加大
- 如果每5条指令中有1条相关指令:如何保持5-路
- 多指令流出的处理器需要大量的硬件资源
- 需要多个功能部件来使得多个操作并行(
Easy) - 需要更大的指令访问带宽(
Easy) - 需要增加寄存器文件的端口数(以及通信带宽,
Hard) - 增加存储器的端口数(带宽,Harder)
- 需要多个功能部件来使得多个操作并行(
Multithreading:
- 背景:从单线程程序挖掘指令集并行越来越困难
- 前提:许多工作任务可以使用线程级并行来完成
- 线程级并行来源于多道程序设计
- 线程级并行的基础是多线程应用,即一个任务可以用多个线程并行来加速
- 基本思想:多线程应用可以用线程级并行来提高单个处理器的利用率
- 针对单个处理器:多个线程以重叠方式共享单个处理器的功能
- 如何保证流水线中指令间无数据依赖关系?一种办法是:在相同的流水线中交叉执行来自不同线程的指令
多线程开销:
- 每个线程需要拥有自己的用户态信息(
user state) :包括PC、GPRs - 需要自己的系统态信息(
system state)- 虚拟存储的页表基地址寄存器(
Virtual-memory pagetable-base register) - 异常处理寄存器(
Exception-handling registers)
- 虚拟存储的页表基地址寄存器(
- 其他开销
- 需要处理由于线程竞争导致的
Cache/TLB冲突或需要更大的Cache/TLB容量 - 更多的OS调度开销
- 需要处理由于线程竞争导致的
线程调度策略:
- 固定交叉模式(
CDC 6600 PPUs, 1964)- 针对
N个线程,每个线程每隔N个周期执行一条指令 - 如果流水线的某一时隙(
slot)其对应线程未就绪,插入pipeline bubble
- 针对
- 软件控制的交叉模式(
TI ASC PPUs, 1971)- OS为
N个线程分配流水线的S个pipeline slots - 硬件针对
S个slots采用固定交叉模式执行相应的线程
- OS为
- 硬件控制的线程调度(
HEP, 1982)- 硬件跟踪哪些线程处于
ready状态 - 根据优先级方案选择线程执行
- 硬件跟踪哪些线程处于
5.7 相关课件
6 数据级并行
动机:
- 传统指令级并行技术的问题
- 程序内在的并行性
- 提高流水线的时钟频率:提高时钟频率,有时导致
CPI随着增加(branches, other hazards) - 指令预取和译码:有时在每个时钟周期很难预取和译码多条指令
- 提高
Cache命中率:在有些计算量较大的应用中(科学计算)需要大量的数据,其局部性较差,有些程序处理的是连续的媒体流(multimedia),其局部性也较差
Data-Level Parallelism, DLP的兴起- 应用需求和技术发展推动着体系结构的发展
- 图形、机器视觉、语音识别、机器学习等新的应用均需要大量的数值计算,其算法通常具有数据并行特征
SIMD-based结构(vector-SIMD,subword-SIMD, SIMT/GPUs)是执行这些算法的最有效途径
SIMD结构的优势SIMD结构可有效地挖掘数据级并行- 基于矩阵运算的科学计算
- 图像和声音处理
- …
SIMD比MIMD更节能- 针对每组数据操作仅需要取指一次
SIMD对PMD(personal mobile devices)更具吸引力
SIMD允许程序员继续以串行模式思维
SIMD结构的种类
- 向量体系结构
- 多媒体
SIMD指令集扩展 Graphics Processor Units, GPUs- 对于x86处理器:
- 每年增加
2cores/chip SIMD宽度每4年翻一番SIMD潜在加速比是MIMD的2倍
- 每年增加
6.1 向量处理机模型
向量处理机具有更高层次的操作,一条向量指令可以处理N个或N对操作数(处理对象是向量)
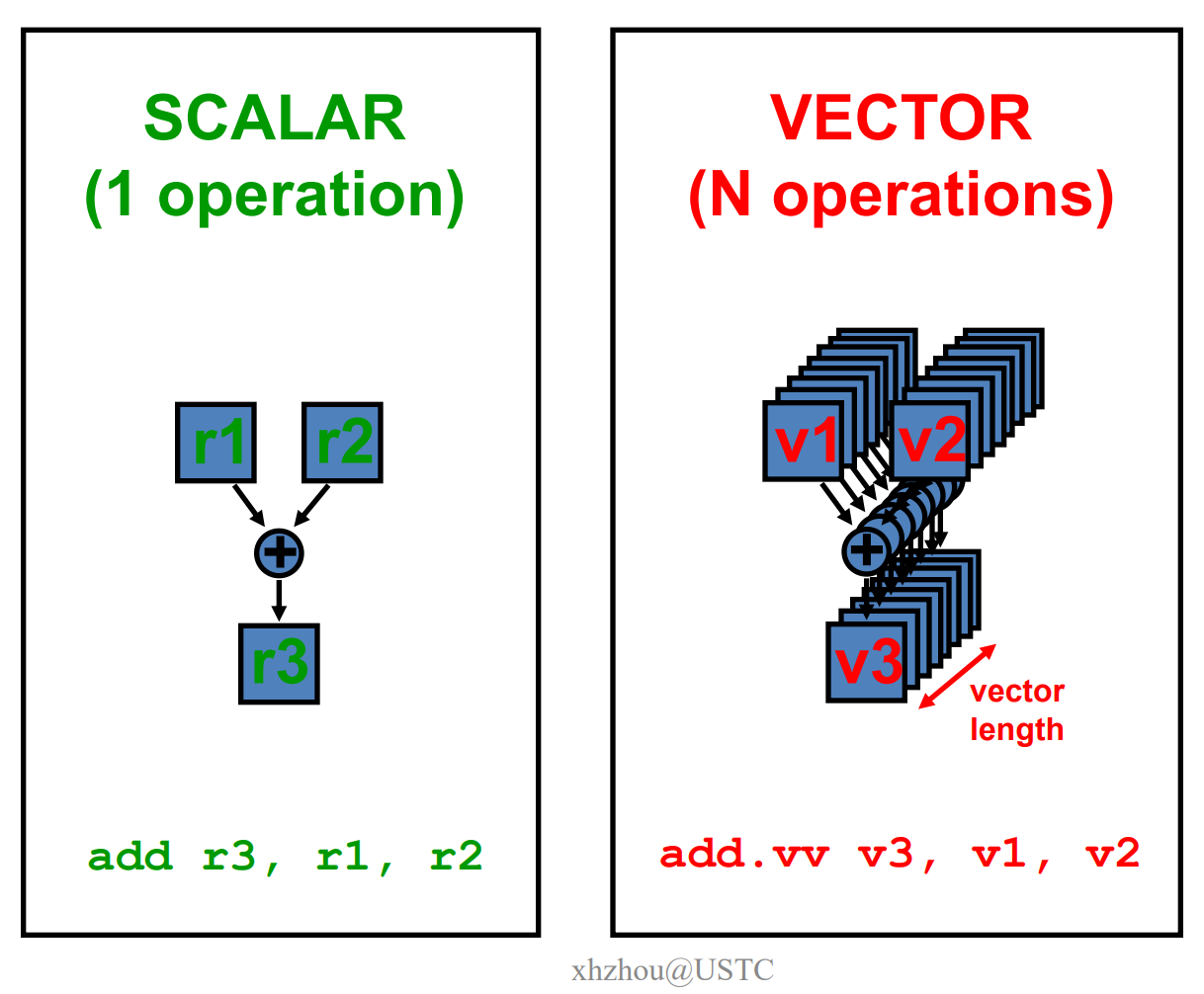
向量处理机的基本特性:
- 基本思想:两个向量的对应分量进行运算,产生一个结果向量
- 简单的一条向量指令包含了多个操作:
fewer instruction fetches - 每一结果独立于前面的结果
- 长流水线,编译器保证操作间没有相关性
- 硬件仅需检测两条向量指令间的相关性
- 较高的时钟频率
- 向量指令以已知的模式访问存储器
- 可有效发挥多体交叉存储器的优势
- 可通过重叠减少存储器操作的延时。例如:一个向量包含64个元素
- 不需要数据
Cache,仅使用指令Cache(为什么?指的是一个指令的操作数会一次性取到寄存器?)
- 在流水线控制中减少了控制相关
向量处理机的基本结构:
memory-memory vector processors:所有的向量操作是存储器到存储器vector-register processors:除了Load和Store操作外,所有的操作是向量寄存器与向量寄存器间的操作- 向量机的
Load/Store结构 - 1980年以后的所有的向量处理机都是这种结构:Cray, Convex, Fujitsu, Hitachi, NEC
- 向量机的
向量指令的优势:
- 格式紧凑
- 一条指令包含N个操作
- 表达能力强
- 一条指令包含N个操作
- 使用同样的功能部件
- 访问不相交的寄存器
- 访问存储器中的连续块
- 以已知的模式访问存储器
- 可扩展性好
- 可以在多个并行的流水线上运行同样的代码
向量处理机的基本组成单元:
Vector Register:固定长度的一块区域,存放单个向量- 至少2个读端口和一个写端口(一般最少16个读端口,8个写端口)
- 典型的有8-32向量寄存器,每个寄存器存放
64到128个64位元素
Vector Functional Units (FUs):全流水化的,每一个clock启动一个新的操作- 一般4到8个
FUs:FP add、FP mult、FP reciprocal (1/X)、integer add、logical、shift。可能有些重复设置的部件
- 一般4到8个
Vector Load-Store Units (LSUs): 全流水化地Load或Store一个向量,可能会配置多个LSU部件Scalar registers:存放单个元素用于标量处理或存储地址
6.2 向量处理机模型优化
6.2.1 链接优化
不采用链接技术,必须处理完前一条指令的最后一个元素,才能启动下一条相关的指令

采用链接技术,前一条指令的第一个结果出来后,就可以启动下一条相关指令的执行
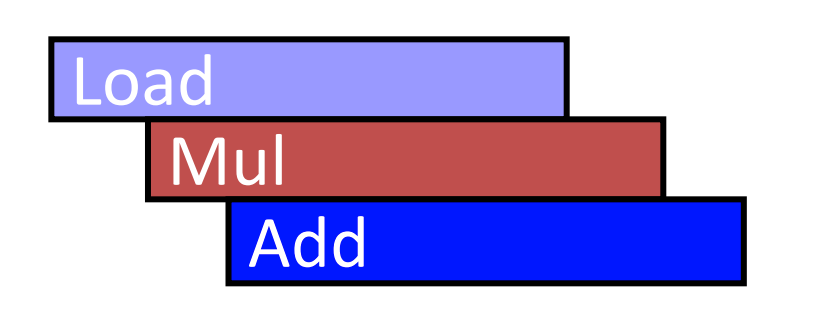
6.2.2 条件执行
例如下面这段伪代码
1 | for i from 1 to 64 |
原理:
vector-mask control使用长度为MVL的布尔向量控制向量指令的执行- 当
vector-mask register使能时,向量指令操作仅对vector-mask register中对应位为1的分量起作用
缺点:
- 简单实现时,条件不满足时向量指令仍然需要花费时间
- 有些向量处理器带条件的向量执行仅控制向目标寄存器的写操作,可能会有除法错
6.2.3 稀疏矩阵
看下面这段伪代码
1 | for i from 1 to n |
原理:
gather (LVI) operation:使用index vector(伪代码中的K和M)中给出的偏移再加基址来读取 =>a nonsparse vector in a vector register- 这些元素以密集的方式操作完成后,再使用同样的
index vector存储到稀疏矩阵的对应位置 - 这些操作编译时可能无法完成。主要原因:编译器无法预知
K(i)以及是否有数据相关 - 使用
CVI设置步长(index 0, 1xm, 2xm, ..., 63xm)
6.3 面向多媒体应用的SIMD指令集扩展
6.4 GPU-1
GPU起源:
- 源于计算机图形学。1960年在
Ivan Sutherland的Sketchpad项目中首先提到计算机图形学- 早期,计算机图形学用于电影动画离线渲染,以及游戏中的实时渲染
- 硬件支持渲染。显卡始于1981年
IBM Monochrome Display Adapter (MDA),后来支持2D、3D加速 - 早期的3D加速卡(
Graphics Processing Unit):用来渲染图形的专用处理器- 如1999年
NVIDIA GeForce 256功能相对固定 - 早期的
GPU是指带有高性能浮点运算部件、可高效生成3D图形的具有固定功能的专用设备(mid-late 1990s) - 用户可以配置图形处理流水线,可编程性较弱
- 如1999年
- GPU的可编程性
- 2001年
NVIDIA改善了GPU的可编程性(GeForce3) - 2003年,学术界研究将矩阵数据转换为纹理数据并使用
shaders完成运算,从而在GPU上实现通用计算,这些努力激发了GPU制造商直接支持通用计算 - 第一个支持通用计算的
GPU是GeForce 8系列 Fermi architecture:具有缓存读写数据的能力AMD的混合结构(GPU和CPU集成在一个芯片中,支持thread的动态调度)Volta architecture:引入Tensor Cores可有效加速机器学习应用
- 2001年
- 现代
GPU, GP-GPU是可编程的,可用于通用计算
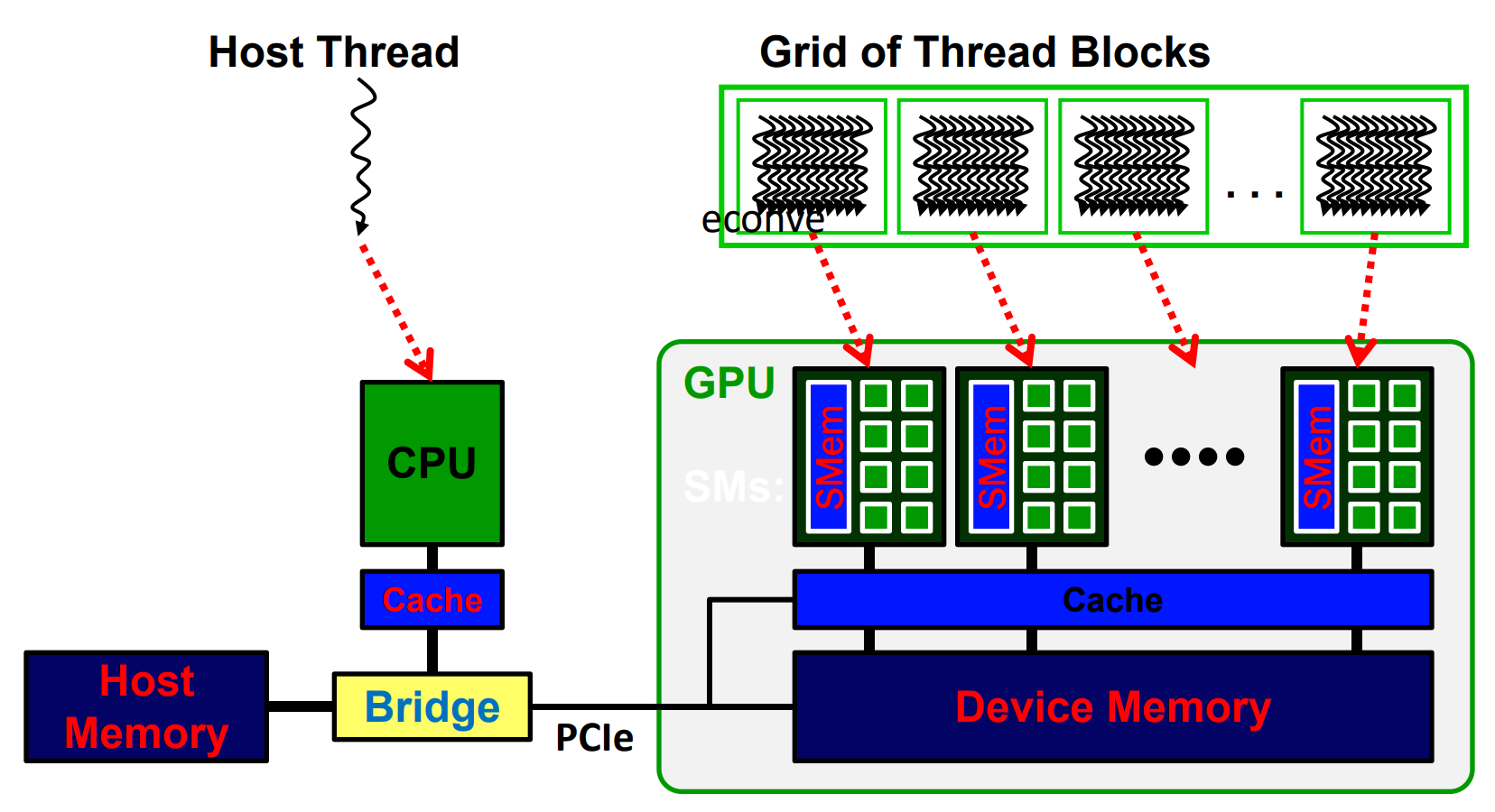
GPU基本硬件结构
CPU + GPU异构多核系统- 针对每个任务选择合适的处理器和存储器
CPU适合执行一些串行的线程(强控制、弱计算)- 串行执行快
- 带有cache,访问存储器延时低
GPU适合执行大量并行线程(弱控制、强计算)- 可扩放的并行执行
- 高带宽的并行存取
多核 vs. 多线程:
- 多核处理器结构随着线程数的增加会落入性能低谷
Cache容量不足时,性能就会下降
- 当线程数较少时多线程结构(
GPU)会落入性能低估- 无法抵消对片外存储访问的延时
6.4.1 GPU编程模型
概念:
- 编程模型:指程序员如何描述应用(从程序员角度看到的机器模型)
- 例如,顺序模型(
von Neumann),数据并行(SIMD),数据流模型、多线程模型(MIMD,SPMD)
- 例如,顺序模型(
- 执行模型:指硬件底层如何执行代码
- 例如,乱序执行、向量机、数据流处理机、多处理机、多线程处理机等
- 执行模型与编程模型可以差别很大
- 例如,顺序模型可以在乱序执行的处理器上执行
SPMD
SPMD是一种编程模型而不是计算机组织- 每个处理单元执行同样的过程,处理不同的数据
- 这些过程可以在程序中的某个点上同步,例如
barriers
- 这些过程可以在程序中的某个点上同步,例如
- 多条指令流执行相同的程序
- 每个程序/过程
- 操作不同的数据
- 运行时可以执行不同的控制流路径
- 许多科学计算应用以这种方式编程,运行在
MIMD硬件结构上(multiprocessors) - 现代
GPUs以这种类似的方式编程,运行在SIMD硬件上
- 每个程序/过程
GPU编程模型
CUDANvidia研制开发的专用模型- 第一个
GP-GPUs编程环境
C++ AMP- 微软研制开发
CUDA/OpenCL的更高层抽象
- OpenACC – Open Accelerator
UDA/OpenCL的更高层抽象
- OpenCL
- 最早由苹果公司研制开发,后来形成开放的异构平台编程规范
- 异构平台编程框架,
OpenCL用来编写设备端程序 OpenCL工作组的成员包括:3Dlabs、AMD、苹果、ARM、Codeplay、爱立信、飞思卡尔、华为、HSA基金会、GraphicRemedy、IBM、Imagination Technologies、Intel、诺基亚、NVIDIA、摩托罗拉、QNX、高通,三星、Seaweed、德州仪器、布里斯托尔大学、瑞典Ume大学
Threads and Blocks:
- 一个线程对应一个数据元素
- 许多线程组织成一个线程块(
Block) - 许多线程块组成一个网格(
Grid) GPU由硬件对线程进行管理
6.4.2 GPU执行模型
GPU执行模型:SIMT
GPU不是用SIMD指令编程- 使用多线程模型 (一种
SPMD编程模型)- 每个线程执行同样的代码,但操作不同的数据元素
- 每个线程有自己的上下文(即可以独立地启动/执行等)
- 一组执行相同指令的线程由硬件动态组织成
warp- 一个warp是由硬件形成的
SIMD操作 lockstep模式执行
- 一个warp是由硬件形成的
6.4.3 GPU存储模型
6.5 GPU-2
GPU: throughput processing:
GPU使用许多精简的core并行运行- 包含大量
ALU的Core形成的SIMD Processing - 通过交叉执行许多组片段来避免延迟(数据访问)
CPU vs. GPU:
CPU: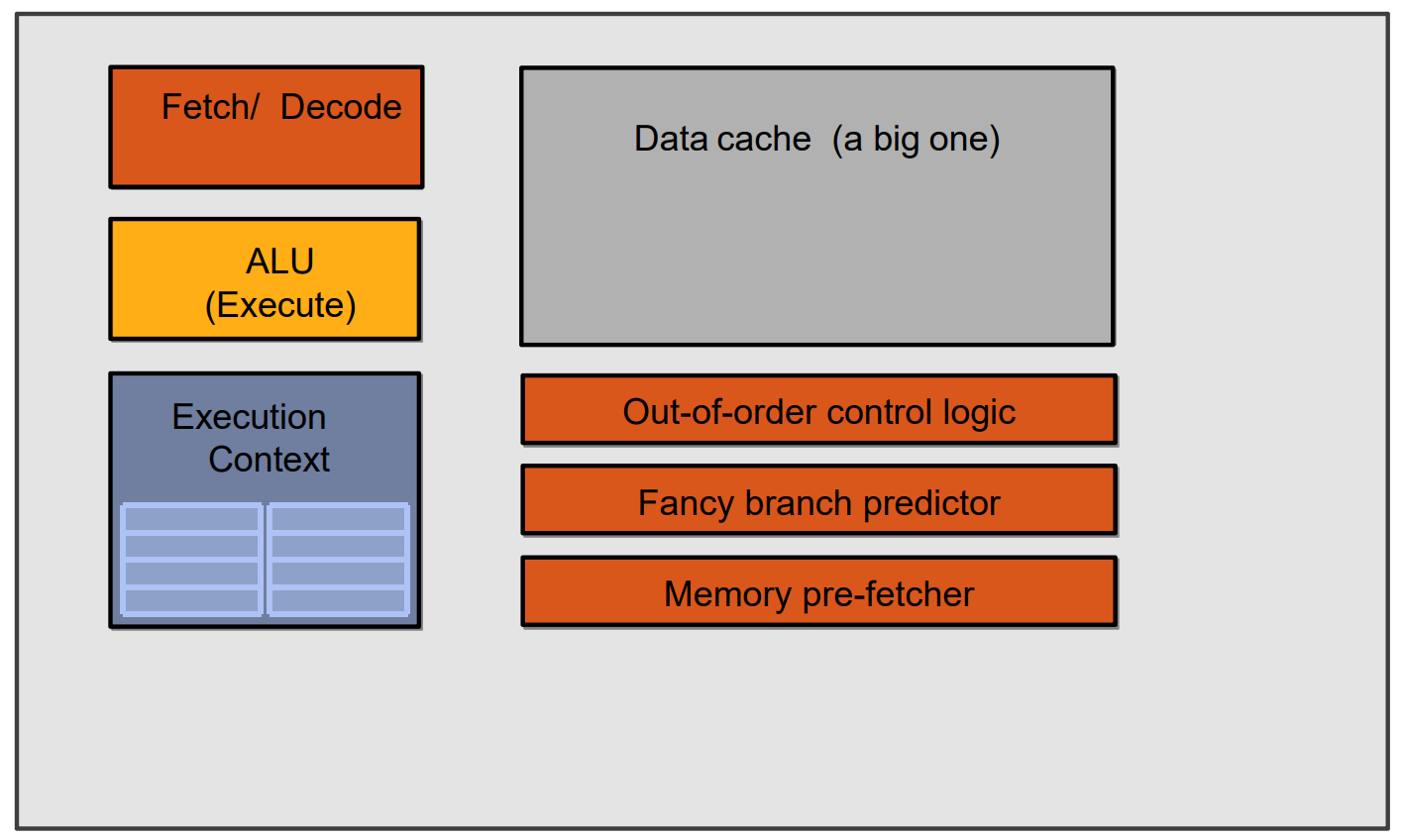
GPU- 架构1:将那些协助单处理器运行得更快的组件从CPU中移除:
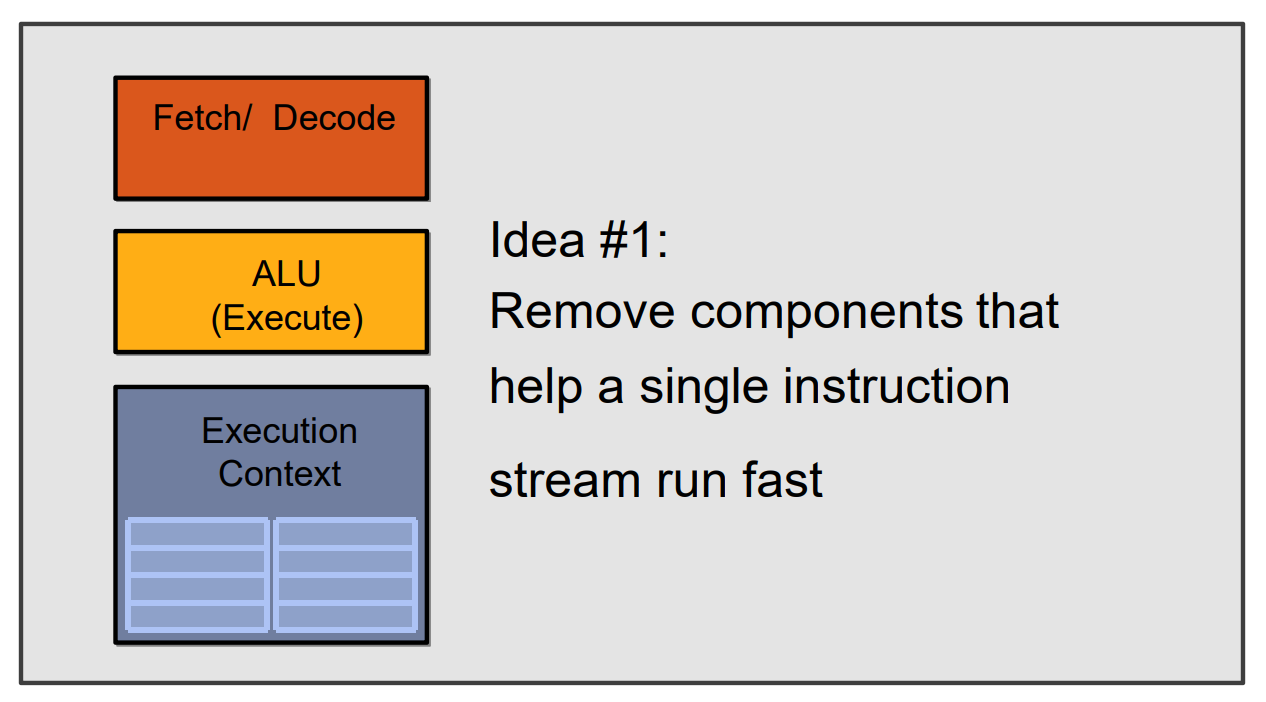
- 架构2:添加
ALU,用以分摊管理指令流的成本/复杂性: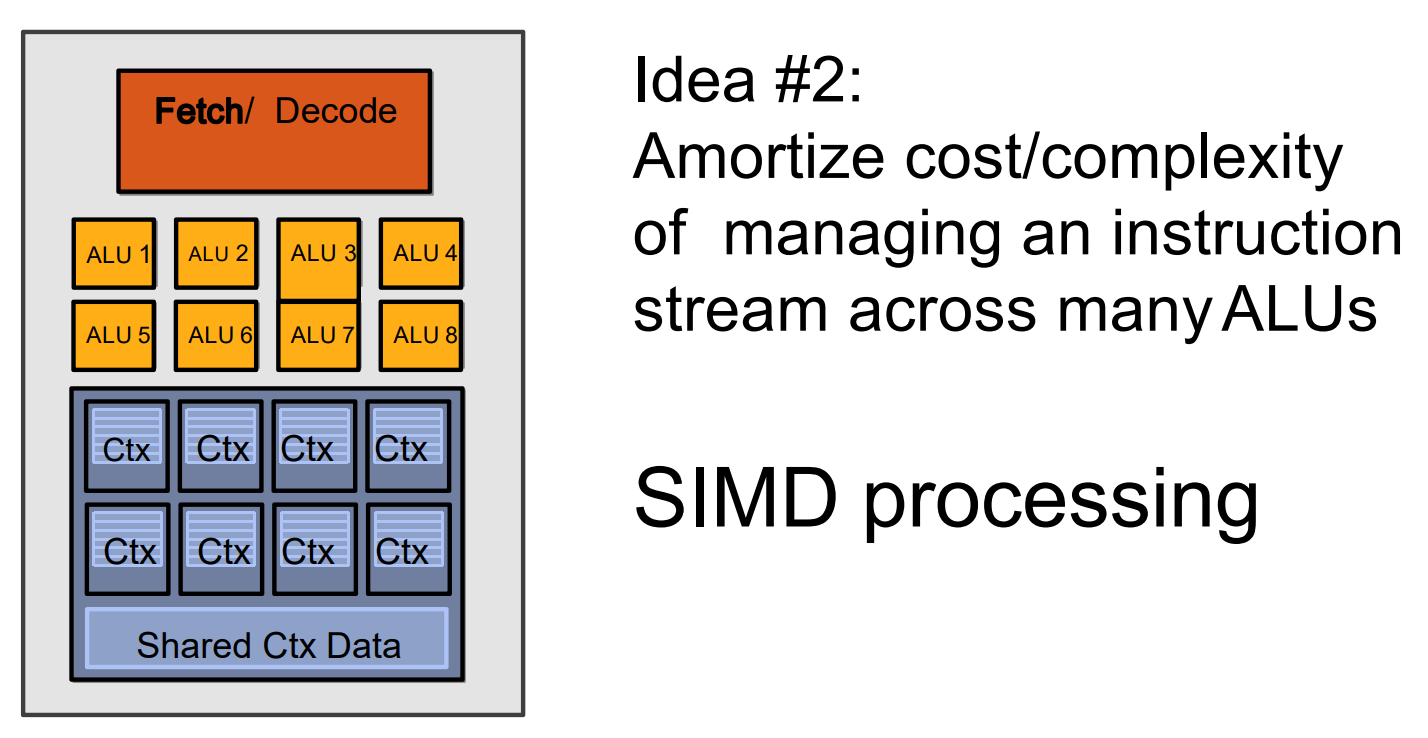
- 架构1:将那些协助单处理器运行得更快的组件从CPU中移除:
Warps are multithreaded on core:
- 一个
warp由32个μthreads构成 - 多个
μthreads线程在单个核上交叉运行,以隐藏存储器访问和功能部件的延迟 - 1个线程块包含多个
warp,这些warp都映射到同一个核上 - 多个线程块也可以在同一个核上运行
6.5.1 分支处理
问题引入:每个线程可以包含相同的控制流指令,且这些线程可以执行不同的控制流路径。当一个warp中的线程分支到不同的执行路径时,产生分支发散
如何处理分支发散:
- 硬件跟踪各
µthreads转移的方向(判定哪些是成功的转移,哪些是失败的转移) - 如果所有线程所走的路径相同,那么可以保持这种
SIMD执行模式 - 如果各线程选择的方向不一致,那么创建一个屏蔽(
mask)向量来指示各线程的转移方向(成功、失败) - 继续执行分支失败的路径,将分支成功的路径压入硬件堆栈(分支同步堆栈),待后续执行
SIMT的主要优点:
- 可以独立地处理线程,即每个线程可以在任何标量流水线上单独执行(
MIMD处理模式) - 可以将线程组织成
warp,即可以将执行相同指令流的线程构成warp,形成SIMD processing处理模式,以充分发挥SIMD处理的优势 - 如果有许多线程,对具有相同
PC值的线程可以将它们动态组织到一个warp中- 这样可以减少分支发散,提高
SIMD利用率(执行有用操作的SIMD lanes的比例)
- 这样可以减少分支发散,提高
动态构成warp:
- 分支发散之后,动态合并执行相同指令的线程
- 固定模式的存储器访问相对简单,当动态构成
warp时,使得访问模式具有随机性,使得问题变得复杂。降低存储器访问的局部性- 需要有相关技术来解决存储器发散访问问题
6.6 小结
6.7 相关课件
7 多处理器及线程级并行
并行计算机体系结构的分类:
- 按照
Flynn分类法,可把计算机分成- 单指令流单数据流(
SISD) - 单指令流多数据流(
SIMD) - 多指令流单数据流(
MISD) - 多指令流多数据流(
MIMD)
- 单指令流单数据流(
MIMD已成为通用多处理机体系结构的选择,原因:MIMD灵活性高MIMD可以充分利用商品化微处理器在性价比方面的优势
通信模型和存储器的结构模型:
- 两种地址空间的组织方案
- 共享存储(多处理机):物理上分离的多个存储器可作为一个逻辑上共享的存储空间进行编址
- 非共享存储(多计算机):
- 整个地址空间由多个独立的地址空间构成,它们在逻辑上也是独立的,远程的处理器不能对其直接寻址
- 每一个处理器-存储器模块实际上是一个单独的计算机,这种机器也称为多计算机
- 两种通信模型
- 共享地址空间的机器:称为共享存储器通信
- 利用Load/Store指令的地址隐含地进行数据通讯
- 多个地址空间的机器:称为消息传递通信
- 通过处理器间显式地传递消息完成
- 通过
Send、Receive操作来进行数据通信
- 共享地址空间的机器:称为共享存储器通信
不同通信机制的优点:
- 共享存储器通信的主要优点
- 当处理器通信方式复杂或程序执行动态变化时易于编程,同时在简化编译器设计方面也占有优势
- 通信数据量较小时,通信开销较低,带宽利用较好
- 通过硬件控制的Cache减少了远程通信的频度,减少了通信延迟以及对共享数据的访问冲突
- 消息传递通信的主要优点
- 硬件较简单。
- 通信是显式的,从而引起编程者和编译程序的注意,着重处理开销大的通信
并行处理面临的挑战:
- 并行处理面临着两个重要的挑战和一个重要问题:
- 程序中有限的并行性
- 相对较高的通信开销
- 一个重要问题:存储器访问的序问题
- 挑战之一:有限的并行性使机器要达到好的加速比十分困难
- 挑战之二:多处理机中远程访问的较大延迟。在现有的机器中,处理器之间的数据通信大约需要35~>500个时钟周期
存储器访问的序问题:
- 存储同一性(
Consistency):- 也有翻译为存储一致性
- 不同处理器发出的所有存储器操作的顺序问题(即针对不同存储单元或相同存储单元)
- 所有存储器访问的全序问题
Cache一致性(Coherence):- 不同处理器访问相同存储单元时的访问顺序问题
- 访问每个
Cache块的局部序问题
如何应对挑战/问题?
- 如何应对并行性不足问题:
- 通过采用并行性更好的算法来解决
- 如何降低远程访问的延迟:
- 靠体系结构支持和编程技术
- 如何正确有效地访问共享存储器
- 一致性协议
7.1 集中式共享存储器体系结构
集中式共享存储器体系结构的特点:
- 多个处理器共享一个存储器
- 当处理器规模较小时,这种机器十分经济
- 支持对共享数据和私有数据的
Cache缓存- 私有数据供一个单独的处理器使用,而共享数据供多个处理器使用
- 共享数据进入Cache产生了一个新的问题:
Cache的一致性问题
不一致产生的原因(Cache一致性问题):
I/O操作Cache中的内容可能与由I/O子系统输入输出形成的存储器对应部分的内容不同
- 共享数据
- 不同处理器的
Cache都保存有对应存储器单元的内容
- 不同处理器的
关于存储系统是一致的的定义:
- 如果对某个数据项的任何读操作均可得到其最新写入的值,则认为这个存储系统是一致的(非正式定义)
- 如果存储系统行为满足条件:
- 处理器
P对X进行一次写之后又对X进行读,读和写之间没有其它处理器对X进行写,则读的返回值总是写进的值 - 一个处理器对
X进行写之后,另一处理器对X进行读,读和写之间无其它写,则读X的返回值应为写进的值 - 对同一单元的写是顺序化的,即任意两个处理器对同一单元的两次写,从所有处理器看来顺序都应是相同的
- 处理器
- 2点假设
- 直到所有的处理器均看到了写的结果,一次写操作才算完成(写传播)
- 允许处理器无序读,但必须以程序序进行写(写串行化)
实现一致性的基本方案:
- 在一致的多处理机中,
Cache提供两种功能- 共享数据的迁移: 共享块迁移到私有
Cache中- 降低了对远程共享数据的访问延迟和对共享存储器的带宽要求
- 共享数据的复制:共享块被复制到多个私有
Cache中- 不仅降低了访存的延迟,也减少了访问共享数据所产生的冲突
- 共享数据的迁移: 共享块迁移到私有
- 小规模多处理机不是采用软件而是采用硬件技术实现
Cache一致性
Cache一致性协议:
- 对多个处理器维护存储一致性的协议
- 关键:跟踪共享数据块的状态
- 共享数据状态跟踪技术
- 目录:物理存储器中共享数据块的状态及相关信息均被保存在一个称为目录的地方
- 监听:每个
Cache除了包含物理存储器中块的数据拷贝之外,也保存着各个块的共享状态信息
基于监听的两种协议:
- 写作废协议
- 在一个处理器写某个数据项之前保证它对该数据项有唯一的访问权
- 写更新协议
- 当一个处理器写某数据项时,通过广播使其它
Cache中所有对应的该数据项拷贝进行更新
- 当一个处理器写某数据项时,通过广播使其它
- 写更新和写作废协议性能上的差别
- 对同一数据(字)的多个写而中间无读操作情况,写更新协议需进行多次写广播操作,而在写作废协议下只需一次作废操作
- 对同一块中多个(不同)字进行写,写更新协议对每个字的写均要进行一次广播,而在写作废协议下仅在对本块第一次写时进行作废操作
- 一个处理器写到另一个处理器读 之间的延迟通常在写更新模式中较低。而在写作废协议中,需要读一个新的拷贝
- 在基于总线的多处理机中,写作废协议成为绝大多数系统设计的选择
监听协议的基本实现技术:
- 小规模多处理机中实现写作废协议的关键利用总线进行作废操作,每个块的有效位使作废机制的实现较容易
- 写直达
Cache,因为所有写的数据同时被写回主存,则从主存中总可以取到最新的数据值 - 对于写回
Cache,得到数据的最新值会困难一些,因为最新值可能在某个Cache中,也可能在主存中 - 在写回
Cache条件下的实现技术- 用
Cache中块的标志位实现监听过程 - 给每个
Cache块加一个特殊的状态位说明它是否为共享
- 用
7.1.1 MSI Protocol
MSI Write-Back Invalidate Protocol(为什么有2个4 bus transactions)
3 states:- Modified:仅该
Cache拥有修改过的、有效的该块copy - Shared:该块是干净块,其他
Cache中也可能含有该块,存储器中的内容是最新的 - Invalid:该块是无效块
- Modified:仅该
4 bus transactions:Read Miss:服务于Read Miss on BusWrite Miss:服务于Write Miss on Bus,得到一个独占的块Invalidate:作废该块在其他处理器中的CopyWrite back:替换操作将修改过的块写回
- 写操作时,作废所有其他块
- 直到
Invalidate transaction出现在总线上,写操作才算完成 - 写串行化:总线事务在总线上串行化
- 直到
4 bus transactions:Bus Read:读失效时产生BusRd总线事务Bus Read Exclusive:BusRdX- 得到独占的(
exclusive)cache block - bus read with intention to write
- 得到独占的(
Bus Write-Back:BusWB用于Cache块的替换Flush on BusRd or BusRdXCache将数据块放到总线上(而不是从存储器取数据)完成Cache-to-Cache的传送,并更新存储器
State Transitions in the MSI Protocol
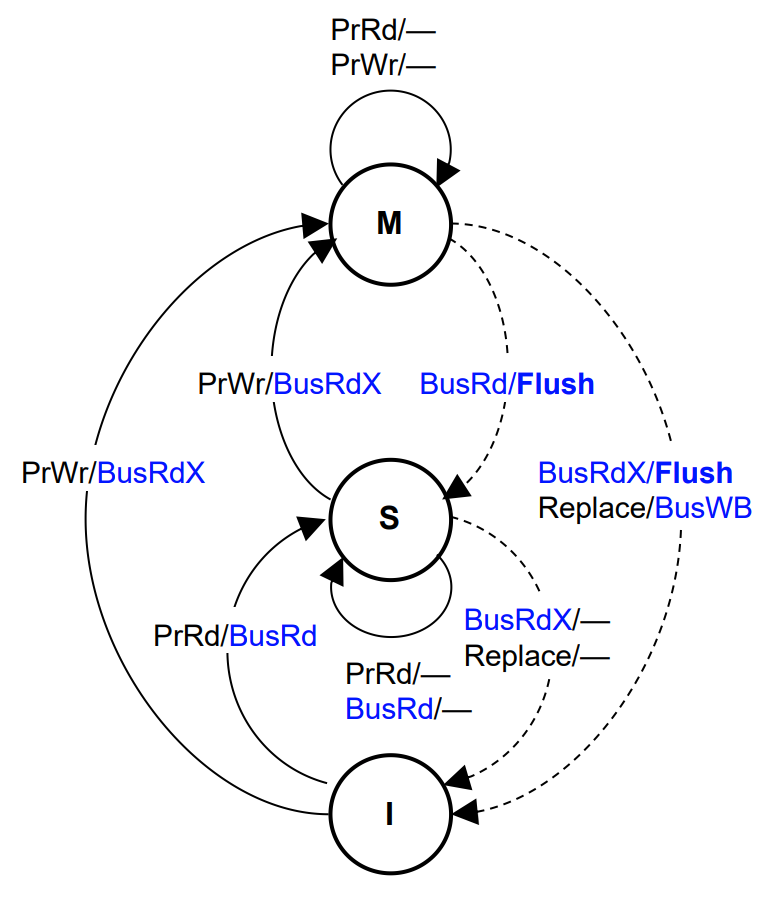
Processor ReadCache miss:产生BusRd事务Cache hit (S or M):无总线动作
Processor Write- 当在非
Modified状态时,产生总线BusRdX事务,BusRdX导致其他Cache中的对应块作废(invalidate) - 当在
Modified状态时,无总线动作
- 当在非
Observing a Bus Read- 如果该块是
Modified,产生Flush总线事务- 更新存储器和有需求的
Cache - 引起总线事务的
Cache块状态:Shared
- 更新存储器和有需求的
- 如果该块是
Observing a Bus Read Exclusive- 作废相关
block - 如果该块是
Modified,产生Flush总线事务
- 作废相关
Lower-level Design Choices:
- 引入
Bus Upgrade (BusUpgr)将Cache块状态从S到M- 引起作废操作 (类似
BusRdX) ,但避免块的读操作
- 引起作废操作 (类似
- 当
M态的块观察到BusRd时,变迁到哪个态Transition to state S或者Transition to state I取决于访问模式
Transition to state S:- 如果不久会有本地读操作,而不是其他处理器的写操作
- 比较适合于经常发生读操作的访问模式
Transition to state I:- 经常发生其他处理器写操作
- 比较适合数据迁移操作:即本地写后,其他处理器将会发出读和写请求,然后本地又进行读和写。即连续的对称式访问模式
- 不同选择方案会影响存储器的性能
Satisfying Coherence:
- 写传播(
Write propagation)- 对一个
Shared或Invalid块的写,其他Cache都可见- 使用
Bus Read-exclusive (BusRdX)事务,Bus Read- exclusive事务作废其他Cache中的块 - 其他处理器在未看到该写操作的效果前体验到的是
Cache Miss
- 使用
- 对一个
- 写串行(
Write serialization)- 所有出现在
bus上的写操作(BusRdX)被总线串行化- 所有处理器(含发出写操作的处理器)以同样的方式排序
- 首先更新发出写操作的处理器的本地
Cache,然后处理其他事务
- 并不是所有的写操作都会出现在总线上
- 对
Modified块的写序列来自同一个处理器将不会产生总线事务 - 同一处理器是串行化的写:由同一处理器进行读操作将会看到串行序的写序列
- 其他处理器对该块的读操作:会导致一个总线事务,这保证了写操作的顺序对其他处理器而言也是串行化的
- 对
- 所有出现在
Snoopy Cache-Coherence Protocols:
- 总线作为广播的媒介,
Caches可知总线的行为- 总线上的事务对所有
Cache是可见的 - 这些事务对所有控制器以同样的顺序可见
- 总线上的事务对所有
Cache控制器监测(snoop)共享总线上的所有事务- 根据
Cache中块的状态不同会产生不同的事务 - 通过执行不同的总线事务来保证
Cache的一致性
- 根据
7.1.2 MESI Protocol
MESI Write-Back Invalidation Protocol
MSI Protocol的缺陷- 读进+修改一个
block,产生2个总线事务- 首先是读操作产生
BusRd(I→S),并置状态为Shared,写更新时产生BusRdX (S→M)
- 首先是读操作产生
- 即使一个块是
Cache独占的这种情况仍然存在 - 使用多道程序负载时,这种情况很普遍
- 读进+修改一个
- 增加
exclusive state,减少总线事务Exclusive state表示仅当前Cache包含该块,并且是干净的块- 区分独占块的
clean和dirty - 一个处于
exclusive state的块,更新时不产生总线事务
Four States: MESI:
M, Modified- 仅当前
Cache含有该块,并且该块被修改过 - 内存中的
Copy是陈旧的值
- 仅当前
E, Exclusive or exclusive-clean- 仅当前
Cache含有该块,并且该块没被修改过 - 内存中的数据是最新的
- 仅当前
S, Shared- 多个
Cache中都含有本块,而且都没有修改过 - 内存中的数据是最新的
- 多个
I, Invalid- 该块是无效块
- 也称
Illinois protocol- 首先是由
Illinois的研究人员研制并发表论文 MESI协议的变种广泛应用于现代微处理器中
- 首先是由
Hardware Support for MESI:
- 总线互连的新要求
- 增加一个称为
shared signal S,必须对所有Cache控制器可用 - 可以实现成
wired-OR line
- 增加一个称为
- 所有
cache controllers监测BusRd- 如果所访问的块的状态是(
state S, E, or M) - 请求
Cache根据shared signal选择E或S
- 如果所访问的块的状态是(
MESI State Transition Diagram:
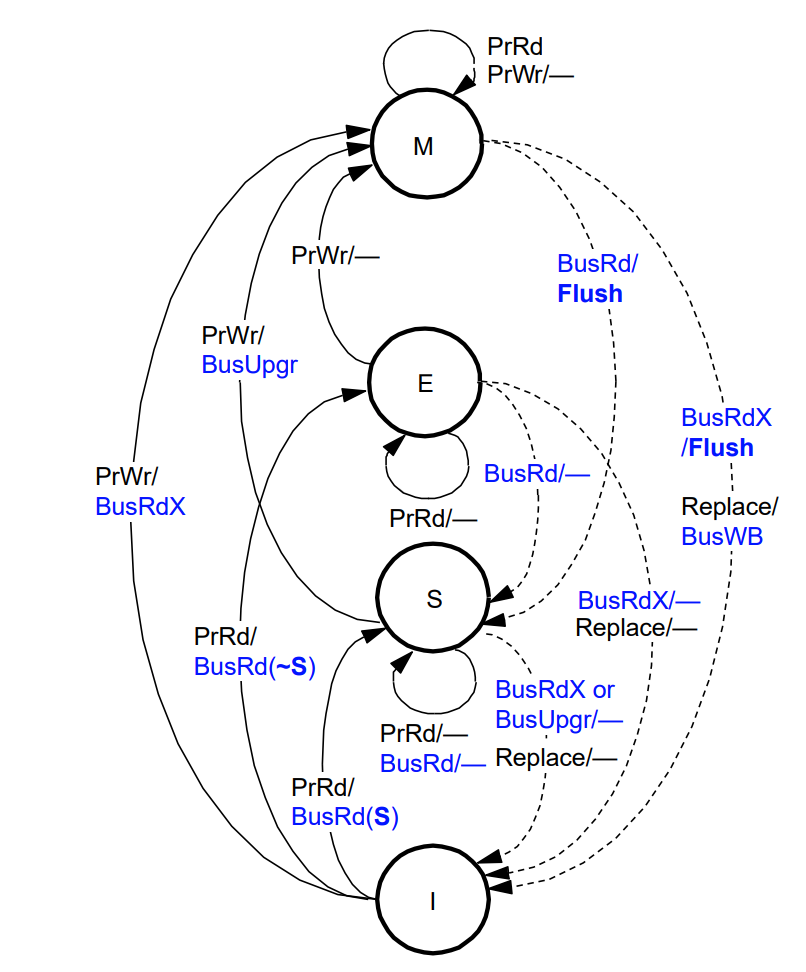
Processor Read- 读失效时产生
BusRd事务,进而有可能产生replace动作? BusRd(S) => shared line asserted- 在其他
Cache中有有效的copy Goto state S
- 在其他
BusRd(~S) => shared line not asserted- 在其他
Cache中不存在该块 Goto state E
- 在其他
- 读命中时不产生总线事务
- 读失效时产生
Processor Write- 该
Cache块的状态转至M - 在
I或S态(命中)产生BusRdX/BusUpgr- 作废其他
Cache中的Copies
- 作废其他
- 写命中且
Cache块处于E和M态时,不产生总线事务 - 写失效时,
E或S态的块有可能引起replace动作 - 写失效时,
M态的块有可能引起replace和BusWB
- 该
Observing a BusRd- 该块的状态从
E降至S- 因为存在其他
copy
- 因为存在其他
- 该块从
M降至S- 将引起更新过的块刷新操作
- 刷新内存和其他有需求的
Cache
- 该块的状态从
Observing a BusRdX or BusUpgr- 将作废相应的
block - 对于处于
modified状态的块,将产生flush事务 BusUpgr:仅引起作废其他块,不产生读块操作
- 将作废相应的
Cache-to-Cache (C2C) Sharing- 原来的
Illinois version支持这种共享 - 由
Cache提供数据,而不是由内存提供数据
- 原来的
7.1.3 MOESI Protocol
MOESI中的Owned和Shared状态:
Owned位O位为1表示在当前Cache块中包含的数据是当前处理器系统最新的数据拷贝,而且在其他CPU中一定具有该Cache块的副本,其他CPU的Cache块状态为S- 如果存储器的数据在多个CPU的
Cache中都具有副本时,有且仅有一个CPU的Cache块状态为O,其他CPU的Cache块状态只能为S - 与MESI协议中的S状态不同,状态为
O的Cache块中的数据与存储器中的数据并不一致
Shared位- 当
Cache块状态为S时,其包含的数据并不一定与存储器一致 - 如果在其他CPU的
Cache中不存在状态为O的副本时,该Cache块中的数据与存储器一致 - 如果在其他CPU的
Cache中存在状态为O的副本时,Cache块中的数据与存储器不一致
- 当
7.1.4 Cache一致性引起的失效(缺失)
Coherency Misses:
- 由于对共享块的写操作引起
- 共享块在多个本地
Cache有副本 - 当某处理器对共享块进行写操作时会 作废其他处理器的本地
Cache的副本 - 其他处理器对共享块进行读操作时会有
coherence miss
- 共享块在多个本地
True sharing misses:Cache coherence机制引起的数据通信- 通常是不同的处理器写或读同一个变量
- 对共享块(
S态块)某一字的第一次写操作引起作废其他cache中的共享块 - 处理器试图读一个存在于其他处理器的
Cache中并且已经修改过的字(modified),这会导致失效,并将当前Cache中的对应块写回 - 即时块大小为1个字,失效仍然会发生
False sharing misses:由于某个字在某个失效块中- 读写同一块中的不同变量
- 失效并没有通过通信产生新的值,仅仅是产生了额外的失效
- 块是共享的,但块中没有真正共享的字
- 如果块的大小为1个字,那么就不会产生这种失效
7.2 分布式共享存储器体系结构
7.2.1 问题分析
Limitations of Snooping Protocols:
- 总线的可扩放性受到一定限制
- 总线上能够连接的处理器数目有限
- 共享总线存在竞争使用问题
- 在由大量处理器构成的多处理器系统中,监听带宽是瓶颈
- 解决方案之一:片上互连网络 -> 并行通信
- 多个处理器可并行访问共享的
Cache banks - 允许片上多处理器包含有更多的处理器
- 可扩放性仍然受到限制
- 多个处理器可并行访问共享的
- 在非总线或环的网络上监听是比较困难的
- 将一致性相关信息广播到所有处理器,这是比较低效的
- 如何不采用广播方式而保持
Cache coherence- 使用目录(
directory)来记录每个Cached块的状态 - 目录项说明了哪个私有
Cache包含了该块的副本
- 使用目录(
解决Cache一致性问题的关键:
- 寻找替代监听协议的一致性协议
- 目录协议
- 目录:用于记录共享块相关信息的数据结构,它记录着可以进入
Cache的每个数据块的访问状态、该块在各个处理器的共享状态以及是否修改过等信息
- 目录:用于记录共享块相关信息的数据结构,它记录着可以进入
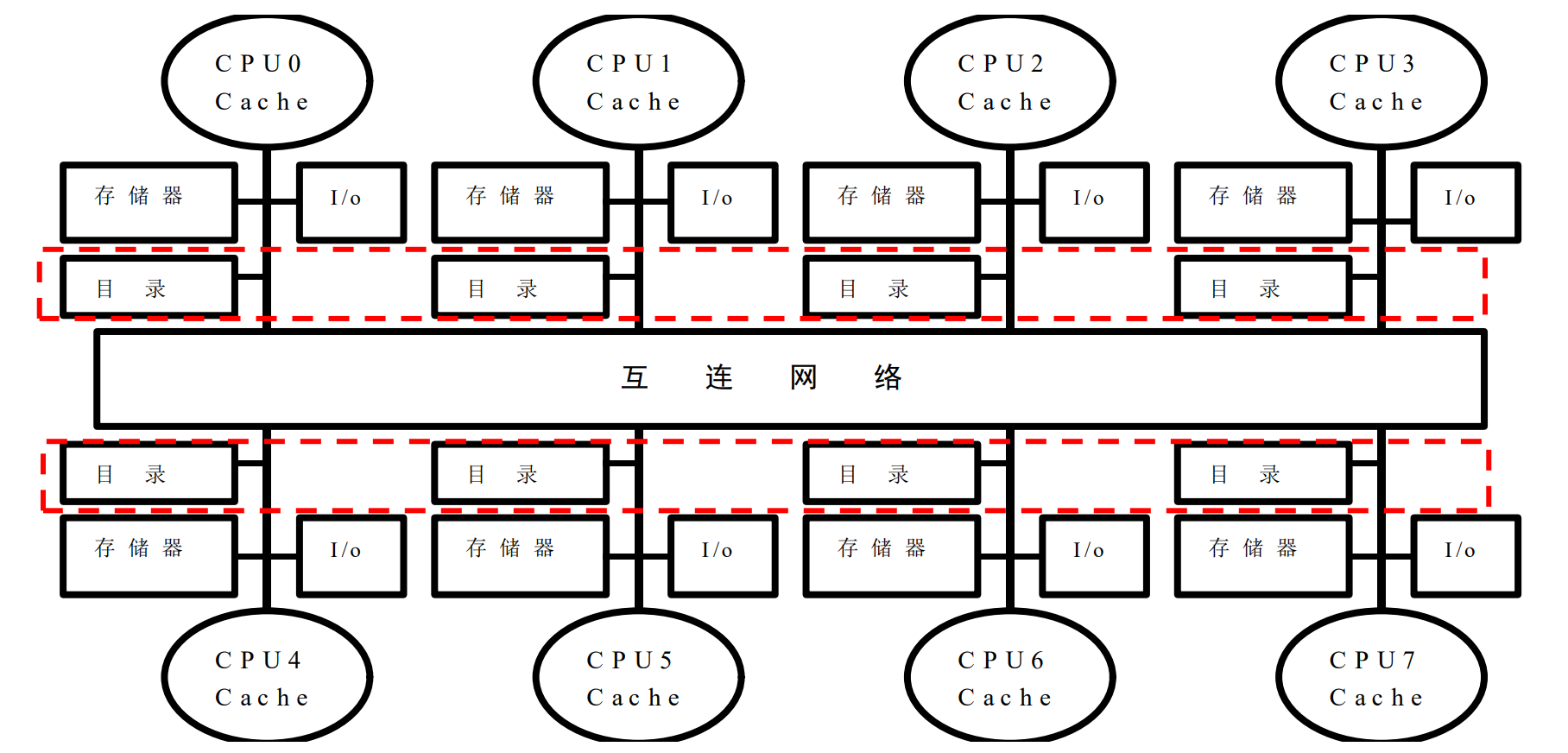
7.2.2 基于目录的一致性协议
目录(Home directory):
- 目录在所有处理器共享的最外层
Cache(共享Cache)中- 目录记录了每个私有
Cache中块的相关信息
- 目录记录了每个私有
- 最外层
Cache分成若干个banks,以便并行访问Cache的banks数可以与cores的数量相同,也可以不同
Shared Cache包含所有的私有Cache- 共享
Cache是私有Cache块的超集
- 共享
- 目录在共享
Cache中- 共享
Cache中的每个块增加若干presence bits - 如果有
k个processors,那么共享Cache中每个块都含有k位的presence bits以及state位 presence bits指示了包含该块copy的cores- 每个块都有其在私有
Cache和共享Cache中的状态信息
- 共享
States for Local and Shared Cache:
- 对于私有
Cache块,存在3种状态:Modified:仅当前Cache具有该块修改过的副本Shared:该块可能在多个Cache中有副本Invalid:该块无效
- 对于共享
Cache中的块 ,存在4种状态:Modified:只有一个本地Cache是这个块的拥有者- 只有一个本地
Cache具有该块修改后的副本
- 只有一个本地
Owned:共享Cache是Modified块的拥有者Modified block被写回到共享Cache,但不是内存- 处于
Owned态的块可以被多个本地Cache共享
Shared:该块可能被复制到多个Cache中Uncached:该块不在任何本地或共享Cache中
Read Miss by Processor P:
Processor P发送Read Miss消息给Home directoryHome Directory:block是Modified状态Directory发送Fetch Message给拥有该块的Remote CacheRemote Cache发送Write-Back Message到Directory(SharedCache)Remote Cache将该块状态修改为SharedDirectory将其所对应的共享块状态修改为OwnedDirectory发送数据给P,并将对应于P的presence bit置位P的Local Cache将所接收到的块状态置为shared
Home Directory:block是Shared或Owned状态Directory发送数据给P,并将对应P的presence bit置位P的Local cache将所接收到的块状态置为Shared
Home Directory:Uncached- 从存储器中获取块
Write Miss Message by P to Directory:
Home Directory:block是Modified状态Directory发送Fetch-Invalidate Message给处理器Q的Cache(Remote Cache)- 处理器
Q的Cache直接发送数据应答消息给P Q的Cache将对应块的状态修改为InvalidP的Cache(Local)将接收到的块的状态信息修改为ModifiedDirectory将对应于Q的presence bit复位,并将对应于P的presence bit置位
Home Directory:block是Shared或Owned状态Directory根据presence bit位给所有的共享者发送Invalidate MessageDirectory接收Acknowledge Message并将对应的presence bits复位Directory发送数据回复信息给P,并将P对应的presence bit置位P的Cache和Directory将该块的状态修改为Modified
Home Directory:Uncached- 从存储器获取数据
7.3 存储同一性
存储同一性的定义:共享地址空间的存储同一性模型是在多个处理器对存储单元并发读写操作时,每个进程看到的这些操作被完成的序的一种约定
-
Cache一致性(Coherence)保证的是当对共享存储空间中的某一单元修改后,对所有读取者是可见的。即每个单元都能返回最后一次写
操作的值 -
没有明确所写入的数据何时成为可见的
-
Cache一致性协议没有涉及处理器P1和P2对不同地址单元的访问顺序 -
Cache一致性协议没有涉及到P2对不同存储单元的读操作相对于P1所见到的顺序
顺序同一性(Sequential Consistency,Lamport):该模型要求所有处理器的读、写和交换(swap)操作以某种序执行所形成的全局存储器次序,符合各处理器的原有程序次序。即:不论指令流如何交叠执行,全局序必须保持所有进程的程序序
- 所有读写操作执行以某种顺序执行
- 每一进程的操作以程序序(
program order)执行
多处理器操作的困难:
- 大多数并行计算机体系结构所研究的问题:
- 如何克服顺序执行和并行执行的瓶颈,以得到更高的性能和效率
- 如何为用户提供良好的编程模型,以便编写正确而高性能的并行程序
- Load/store操作的顺序问题
Operations: A, B, C, D- 硬件以何种顺序执行(和报告结果)这些操作?
- 程序员与微结构设计人员的协议由
ISA来约定 - 保留程序员所希望的执行顺序
- 可降低编程的难度,如:易于
debugging、易于状态恢复、异常处理等 - 通常会使得硬件设计变得困难,特别是当我们的设计目标为高性能处理器时,乱序
Load-Store的执行,使得问题变得复杂
- 可降低编程的难度,如:易于
单个处理器存储器操作的序:
- 操作顺序由
Von Neumann模型约定 - 顺序串行执行
- 硬件执行
Load和Store操作以程序序顺序执行
- 硬件执行
- 乱序执行不改变程序语义
- 硬件以程序序报告
Load和Store操作的结果
- 硬件以程序序报告
- 优点:
- 在执行时机器状态是确定的
- 程序的不同次运行机器状态是一致的,有利于程序调试
- 缺点:维护这种序的额外开销,降低了性能,增加了复杂性,降低了可扩放性
数据流处理器的存储器操作的序:
- 当操作数准备好就可以执行存储器操作
- 操作的顺序仅仅由数据依赖性来确定
- 相互独立的操作可以以任意序执行和提交
- 结果
- 优点:并行度高,性能高
- 缺点:相同程序的不同次运行次序可以不同,使得调试困难
序的重要性:
- 易于调试
- 若程序的每次执行都是相同的序有利于程序的调试
- 正确性
- 从不同处理器看到的存储器操作序可能会不同
- 性能和代价权衡
- 强制符合严格
Sequential Ordering使得硬件设计人员实现性能增强技术变得十分复杂
<p:程序序(program order)<m:存储器操作序(memory order)
顺序同一性的充分条件:
- 多个进程可以交织执行,但顺序同一性模型没有定义具体的交织方式,满足每个进程程序序的总体执行序可能会很多。因此有下列定义
- 顺序同一性的执行:如果程序的一次执行产生的结果与前面定义的任意一种可能的总体序产生的结果一致,那么程序的这次执行就称为是顺序同一的
- 顺序同一性的系统:如果在一个系统上的任何可能的执行都是顺序同一的,那么这个系统就是顺序同一的
- 每个进程按照程序执行序发出存储操作
- 发出写操作后,进程要等待写的完成,才能发出它的下一个操作
- 发出读操作后,进程不仅要等待读的完成,还要等待产生所读数据的那个写操作完成,才能发出它的下个操作。即:如果该写操作对这个处理器来说完成了,那么这个处理器应该等待该写操作对所有处理器都完成了
- 第三个条件保证了写操作的原子性。即读操作必须等待逻辑上先前的写操作变得全局可见
Memory Fences
- 实现弱同一性或放松的存储器模型的处理器(允许针对不同地址的
Loads和Stores操作乱序)需要提供存储器栅栏指令来强制对某些存储
器操作串行化
7.4 同步与通信
Synchronization:
- 系统中只要存在并发进程,即使是单核系统都需要同步操作
- 总体上存在两类同步操作问题
- 生产者-消费者问题:一个消费者进程必须等待生产者进程产生数据
- 互斥问题(
Mutual Exclusion):保证在一个给定的时间内只有一个进程使用共享资源(临界区)
Atomic Operations:
- 顺序一致性并不保证操作的原子性
- 原子性:存储器操作使用原子性操作,操作序列一次全部完成。例如
exchange(交换操作)
7.5 小结
7.6 相关课件
8 FAQ
- Cache架构
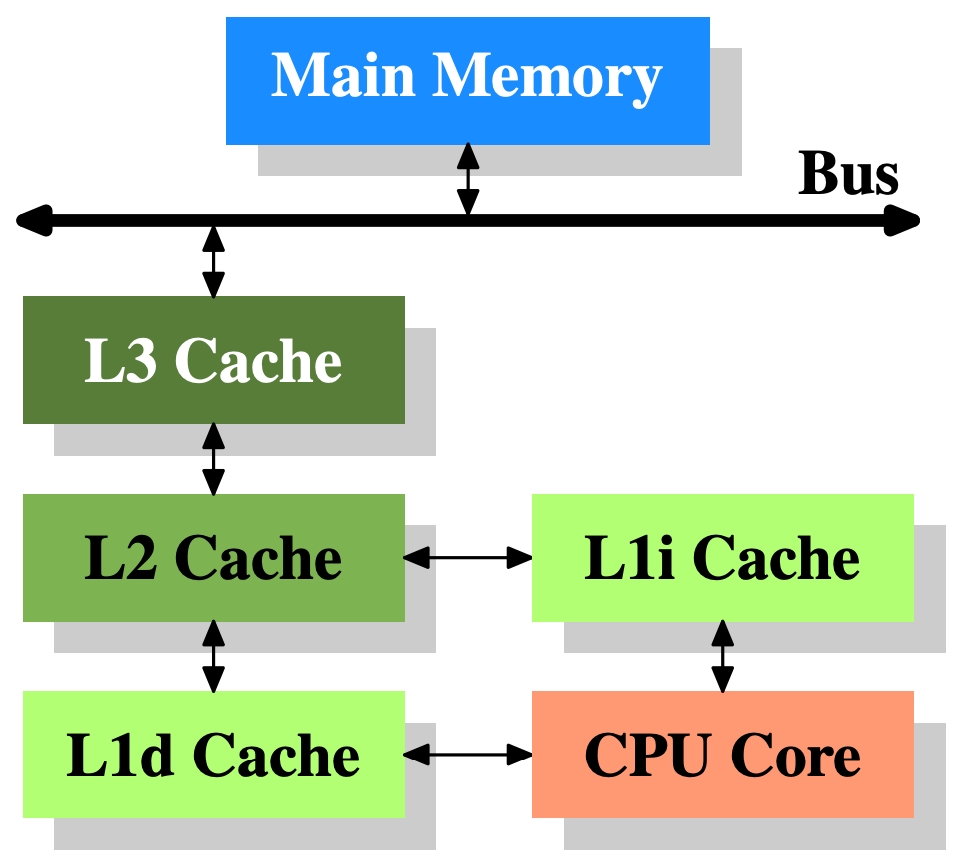
L1d:level 1 data cacheL1i:level 1 instruction cache
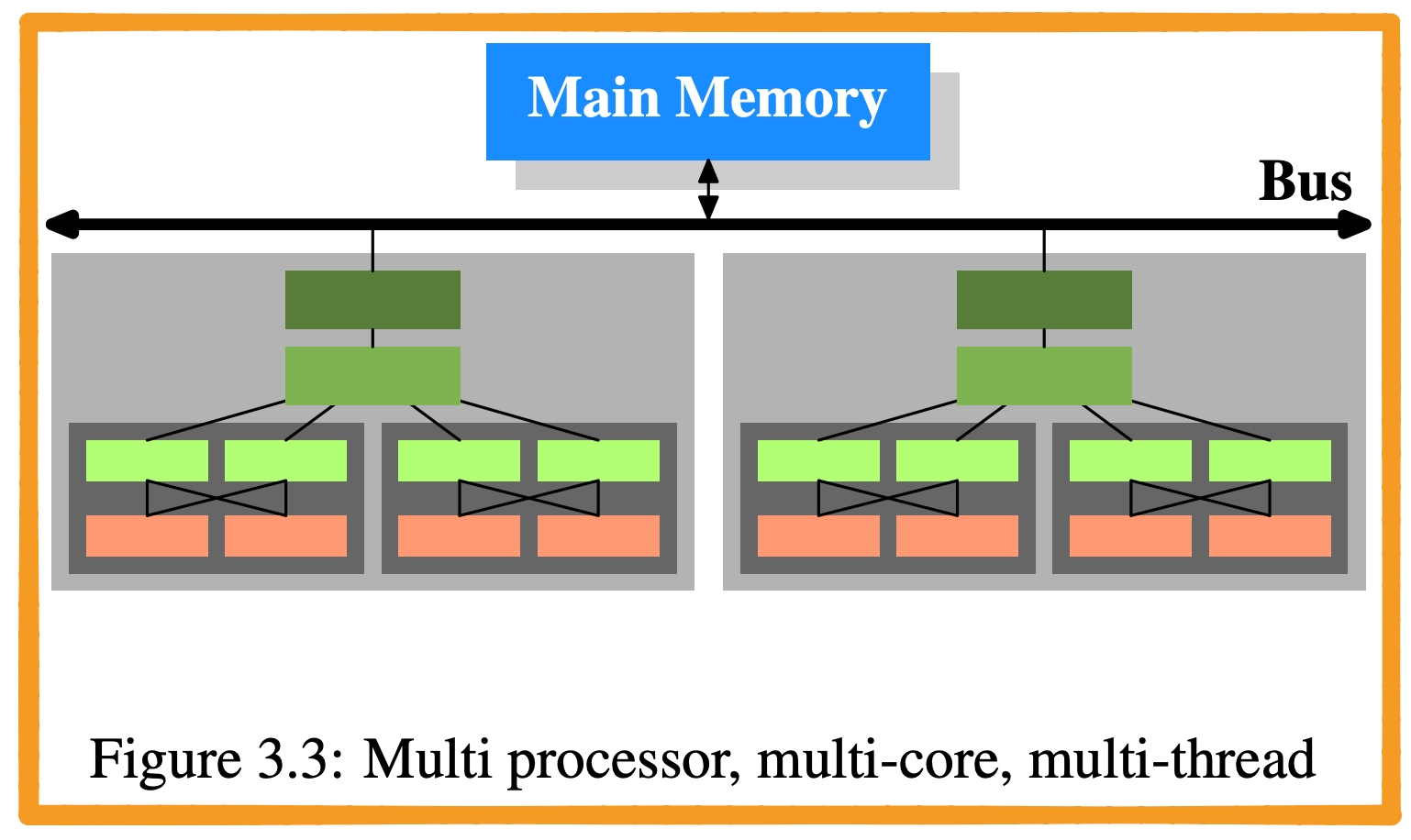
- 橙色:
Thread:共享L1 Cache - 深灰阴影:
Core:独占L1 Cache,共享L2/L3 Cache - 浅灰阴影:
Processor:不共享任意一级的Cache(这个其实取决于硬件设计) - 亮绿色:
L1 Cache - 绿色:
L2 Cache - 深绿色:
L3 Cache
- 橙色:
- 在现代CPU中,访存缓存/内存时,一般需要多少指令周期。
- How many machine cycles does it take a CPU to fetch a value from the SRAM cache?
- Approximate cost to access various caches and main memory?
SRAM-L1:3–5 cyclesSRAM-L2:8–20 cyclesSRAM-L3:30–80 cyclesDRAM:150-180 cycles- Numbers Everyone Should Know (Page 84)
- Cache的大小(
getconf -a | grep -i cache)L1:8KB - 64KBL2:256KB - 8MBL3:10MB - 64MB
- Cache Line大小,一般是64字节(
getconf -a | grep -i cache) - 主板南北桥。简单来说,北桥负责与CPU通信,并且连接高速设备,例如内存、显卡,并且与南桥通信;南桥负责与低速设备(硬盘/USB)通信,时钟、BIOS、系统管理、旧式设备控制,并且与北桥通信
- Intel从第一代
Core i7 (i7 9xx)开始,将原属于北桥功能的内存控制器整合到CPU当中,在主流机更将PCI-e控制器(主要负责连接显卡)整合到CPU当中,这时候传统意义上的北桥的所有功能都已经整合到CPU内部了,所以Intel 50系芯片组(X58除外,这是搭配i7 9xx用的,还有北桥)已经没有传统意义的北桥了,而南桥依然负责处理低速设备(SATA、USB、PCI等)、时钟等功能
- Intel从第一代
- 并行等级
- 指令级并行(
ILP):PipelineVLIWOOO Execution, Out-of-orderRegister renamingSpeculative executionBranch prediction
- 数据级并行(
DLP):SIMD - 线程级并行(
TLP):SMP
- 指令级并行(
9 参考
- 计算机体系结构(Spring 2021)
- 《Computer Architecture: A Quantitative Approach》
- cpu的制造和