阅读更多
1 简介
1.1 什么是虚拟化(virtualization)?
虚拟化技术可以帮助我们创建基于软件的计算机资源,包括CPU、存储、网络等等
借助虚拟化技术,可以将单个物理计算机或服务器划分为多个虚拟机(VM)。在同一个硬件资源上,每个VM可以独立运行不同的操作系统以及应用软件
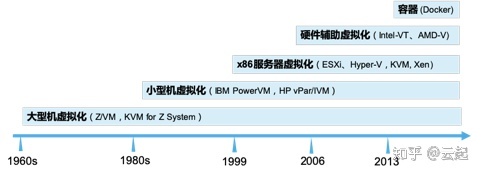
1.2 虚拟化发展史
计算虚拟化发展有几个关键节点。虚拟化技术最早60年代中期年在IBM大型机上实现,当时主流大型虚拟化有IBM Z/VM与KVM for Z Systems。80年代IBM与HP开始研究面向UNIX小型机虚拟化,当时主流的有IBM PowerVM与HP vPar,IVM等。1999年VMware推出针对x86服务器虚拟化,当时主流x86虚拟化有VMware ESXi、Microsoft Hyper-V,以及开源的KVM和Xen。2006年Intel和AMD推出硬件辅助虚拟化技术Intel-VT,AMD-V将部分需要通过软件来实现的虚拟化功能进行硬件化,大幅提升虚拟化的性能。容器作为一种更加轻量的应用级虚拟化技术,最早于1979年提出,不过2013年推出docker解决了标准化与可移植等问题,目前已成为最流行的容器技术。基于x86服务器的虚拟化技术对云计算发展发挥了重要作用,接下来将重点介绍
1.3 参考
- Introduction to Virtualization
- Virtualization
- PC架构系列:CPU/RAM/IO总线的发展历史!
- CPU 的工作原理是什么?
- 计算机如何执行一条机器指令
- 虚拟化技术 - CPU虚拟化
- 计算虚拟化详解
2 汇编语言
计算机真正能够理解的是低级语言,它专门用来控制硬件。汇编语言就是低级语言,直接描述/控制CPU 的运行。如果你想了解CPU到底干了些什么,以及代码的运行步骤,就一定要学习汇编语言。另外,学习汇编语言也能帮助我们更好地理解虚拟化过程
这部分内容请参考System-Architecture-Register以及Assembly-Language
3 CPU虚拟化
x86操作系统是设计在直接运行在裸硬件设备上的,因此它们自动认为它们完全占有计算机硬件。x86架构提供四个特权级别给操作系统和应用程序来访问硬件。Ring是指CPU的运行级别,Ring 0是最高级别,Ring 1次之,Ring 2再次之
操作系统(内核)需要直接访问硬件和内存,因此它的代码需要运行在最高运行级别Ring0上,这样它可以使用特权指令,控制中断、修改页表、访问设备等等。
应用程序的代码运行在最低运行级别上Ring 3上,不能做受控操作。如果要做,比如要访问磁盘,写文件,那就要通过执行系统调用(函数),执行系统调用的时候,CPU的运行级别会发生从Ring 3到Ring 0的切换,并跳转到系统调用对应的内核代码位置执行,这样内核就为你完成了设备访问,完成之后再从Ring 0返回Ring 3。这个过程也称作用户态和内核态的切换
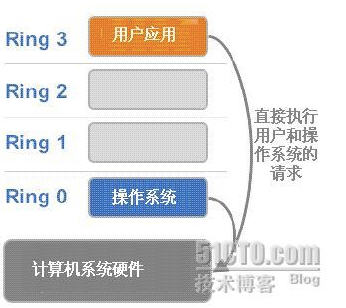
那么,虚拟化在这里就遇到了一个难题,因为宿主操作系统是工作在Ring 0的,客户操作系统就不能也在Ring 0了,但是它不知道这一点,以前执行什么指令,现在还是执行什么指令,但是没有执行权限是会出错的。所以这时候虚拟机管理程序(VMM)需要避免这件事情发生。 虚机怎么通过VMM实现 Guest CPU对硬件的访问,根据其原理不同有三种实现技术:
- 全虚拟化
- 半虚拟化
- 硬件辅助的虚拟化
3.1 基于二进制翻译的全虚拟化(Full Virtualization with Binary Translation)
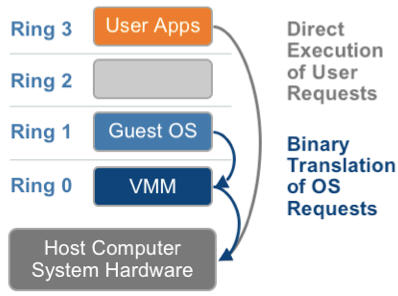
客户操作系统运行在Ring 1,它在执行特权指令时,会触发异常(CPU的机制,没权限的指令会触发异常),然后VMM捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗,就非常的大,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
异常「捕获(trap)-翻译(handle)-模拟(emulate)」过程:
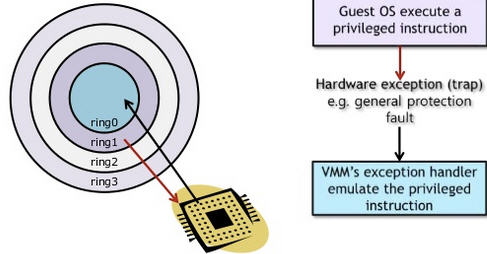
为什么VMM可以捕获到Guest OS执行特权指令时触发的异常?
中断向量表中记录了每个异常/中断所对应的处理程序,该中断表的首地址记录在
idtr寄存器中,但是当Guest OS在执行的时候,idtr是中记录的是Guest OS的线性地址。但是Guest OS中的所有线性地址,都通过「影子页表」被Host OS接管了,因此,中断向量表也是可以被Host OS完全管控的(这是我的猜测)
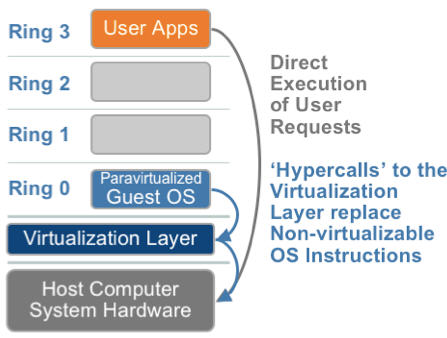
3.2 超虚拟化(或者半虚拟化/操作系统辅助虚拟化 Paravirtualization)
半虚拟化的思想就是,修改操作系统内核,替换掉不能虚拟化的指令,通过超级调用(hypercall)直接和底层的虚拟化层hypervisor来通讯,hypervisor同时也提供了超级调用接口来满足其他关键内核操作,比如内存管理、中断和时间保持
这种做法省去了全虚拟化中的捕获和模拟,大大提高了效率。所以像XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,和x86、mips、arm这些内核版本等价。这样以来,就不会有捕获异常、翻译、模拟的过程了,性能损耗非常低。这就是XEN这种半虚拟化架构的优势。这也是为什么XEN只支持虚拟化Linux,无法虚拟化windows原因,微软不改代码啊
3.3 硬件辅助的全虚拟化
2005年后,CPU厂商Intel和AMD开始支持虚拟化了。Intel引入了Intel-VT (Virtualization Technology)技术。 这种CPU,有VMX root operation和VMX non-root operation两种模式,两种模式都支持Ring 0 ~ Ring 3共 4 个运行级别。这样,VMM可以运行在VMX root operation模式下,客户OS运行在VMX non-root operation模式下
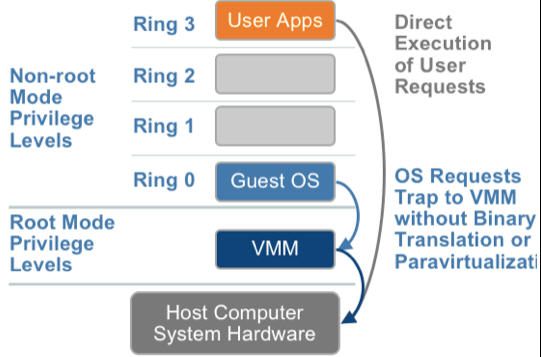
而且两种操作模式可以互相转换。运行在VMX root operation模式下的VMM通过显式调用VMLAUNCH或VMRESUME指令切换到VMX non-root operation模式,硬件自动加载Guest OS的上下文,于是Guest OS获得运行,这种转换称为VM entry。Guest OS运行过程中遇到需要VMM处理的事件,例如外部中断或缺页异常,或者主动调用VMCALL指令调用VMM的服务的时候(与系统调用类似),硬件自动挂起Guest OS,切换到VMX root operation模式,恢复VMM的运行,这种转换称为VM exit。VMX root operation模式下软件的行为与在没有VT-x技术的处理器上的行为基本一致;而VMX non-root operation模式则有很大不同,最主要的区别是此时运行某些指令或遇到某些事件时,发生VM exit
也就说,硬件这层就做了些区分,这样全虚拟化下,那些靠「捕获异常-翻译-模拟」的实现就不需要了。而且CPU厂商,支持虚拟化的力度越来越大,靠硬件辅助的全虚拟化技术的性能逐渐逼近半虚拟化,再加上全虚拟化不需要修改客户操作系统这一优势,全虚拟化技术应该是未来的发展趋势
| 利用二进制翻译的全虚拟化 | 硬件辅助虚拟化 | 操作系统协助/半虚拟化 | |
|---|---|---|---|
| 实现技术 | BT和直接执行 | 遇到特权指令转到root模式执行 | hypercall |
| 客户操作系统修改/兼容性 | 无需修改客户操作系统,最佳兼容性 | 无需修改客户操作系统,最佳兼容性 | 客户操作系统需要修改来支持hypercall,因此它不能运行在物理硬件本身或其他的hypervisor上,兼容性差,不支持Windows |
| 性能 | 差 | 全虚拟化下,CPU需要在两种模式之间切换,带来性能开销;但是,其性能在逐渐逼近半虚拟化 | 好。半虚拟化下CPU性能开销几乎为0,虚机的性能接近于物理机 |
| 应用厂商 | VMware Workstation/QEMU/Virtual PC | VMware ESXi/Microsoft Hyper-V/Xen 3.0/KVM | Xen |
3.4 参考
3.5 问题
- 访问内存需要在
Ring 0上么?用户态程序也存在大量的内存读写,如何访问的? - 客户机的kernel为什么运行在
Ring 1上,它不是应该认为自己跑在Ring 0上才对么,Ring x这个属性是谁赋予的?操作系统本身感知么?- 特权信息是记录在段选择因子(段式内存管理、段页式内存管理)中的,段描述符表GDT、LDT只有一个
- 虚拟机的内核代码所在的段其实对应了
USER_CODE以及USER_DATA(类似cr3,影子页表)
- 普通程序在执行的过程中(用户态),需要操作系统参与吗?参与了哪些过程
- 在内核态执行指令与在用户态执行指令有什么区别?为什么VMM能拦截到客户机的特权指令的执行?(
VMM通过显式调用VMLAUNCH或VMRESUME) - 有操作系统和没有操作系统时,程序分别是如何执行的。对于有操作系统的情况下,操作系统对程序执行多了哪些干预操作?
Ring x这个信息记录在哪- Guest Machine本身并不感知自己跑在一个虚拟的环境中,但是CPU知道!!!
4 内存虚拟化
内存管理相关知识点参考Linux-Memory-Management
本小节转载摘录自虚拟化技术 - 内存虚拟化 [一]
大型操作系统(比如Linux)的内存管理的内容是很丰富的,而内存的虚拟化技术在OS内存管理的基础上又叠加了一层复杂性,比如我们常说的虚拟内存(virtual memory),如果使用虚拟内存的OS是运行在虚拟机中的,那么需要对虚拟内存再进行虚拟化,也就是vitualizing virtualized memory。本文将仅从「内存地址转换」和「内存回收」两个方面探讨内存虚拟化技术
在Linux这种使用虚拟地址的OS中,虚拟地址经过page table转换可得到物理地址
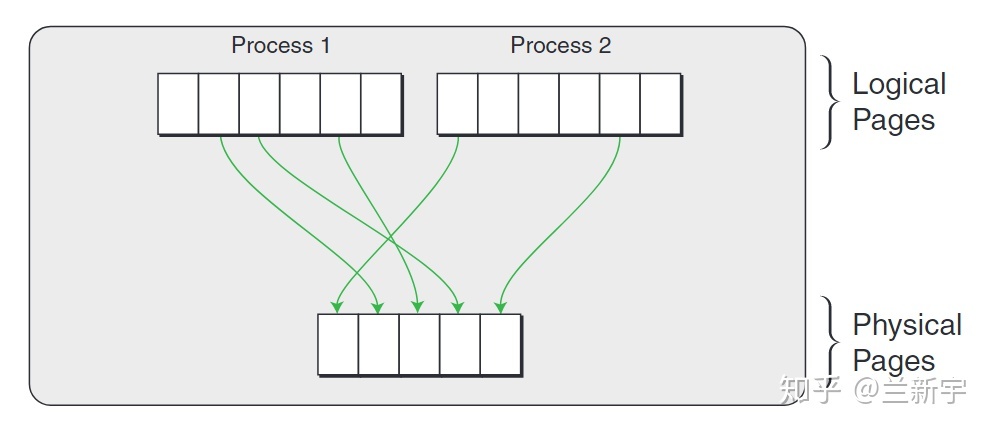
如果这个操作系统是运行在虚拟机上的,那么这只是一个中间的物理地址(Intermediate Phyical Address - IPA),需要经过VMM/hypervisor的转换,才能得到最终的物理地址(Host Phyical Address - HPA)。从VMM的角度,guest VM中的虚拟地址就成了GVA(Guest Virtual Address),IPA就成了GPA(Guest Phyical Address)
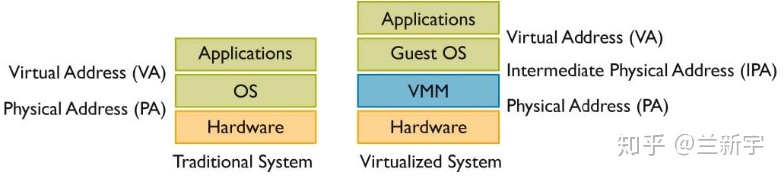
可见,如果使用VMM,并且guest VM中的程序使用虚拟地址(如果guest VM中运行的是不支持虚拟地址的RTOS(real time OS),则在虚拟机层面不需要地址转换),那么就需要两次地址转换
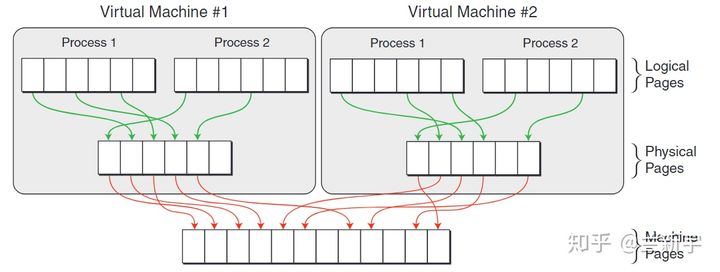
但是传统的IA32架构从硬件上只支持一次地址转换,即由CR3寄存器指向进程第一级页表的首地址,通过MMU查询进程的各级页表,获得物理地址
针对GVA->GPA->HPA的两次转换的问题,存在2种解决方案
- 软件实现「影子页表」
- 硬件辅助「EPT/NPT」
首先介绍「影子页表」的实现方式
在一个运行Linux的guest VM中,每个进程有一个由内核维护的页表,用于GVA->GPA的转换,这里我们把它称作gPT(guest Page Table)。VMM层的软件会将gPT本身使用的物理页面设为write protected的,也就是说gPT的每次写操作都会触发page fault,该异常会被VM捕获,然后由VM来维护gPT的相关数据(该页表在VMM视角下,称为sPT(shadow Page Table))。「影子页表」是将GVA-GPA和GPA-HPA的两次转换合并成一次转换GVA-HPA,因此gPT和sPT指代的是同一个页表,只是视角不同而已
- 在
guest VM的视角下,这就是一个普通的page table,负责将线性地址转换成物理地址(GVA->GPA),guest VM并不知道这个页表的维护实际上是VMM负责的(被骗了) - 在
VVM的视角下,这就是一个影子页表shadow page table,它可以直接将虚拟机的虚拟地址转换成物理机的物理地址(GVA->HPA)
「影子页表」存在如下两个缺点:
- 实现较为复杂,需要为每个
guest VM中的每个进程的gPT都维护一个对应的sPT,增加了内存的开销 - VMM使用的截获方法增多了
page fault和trap/vm-exit的数量,加重了CPU的负担- 在一些场景下,这种影子页表机制造成的开销可以占到整个VMM软件负载的75%
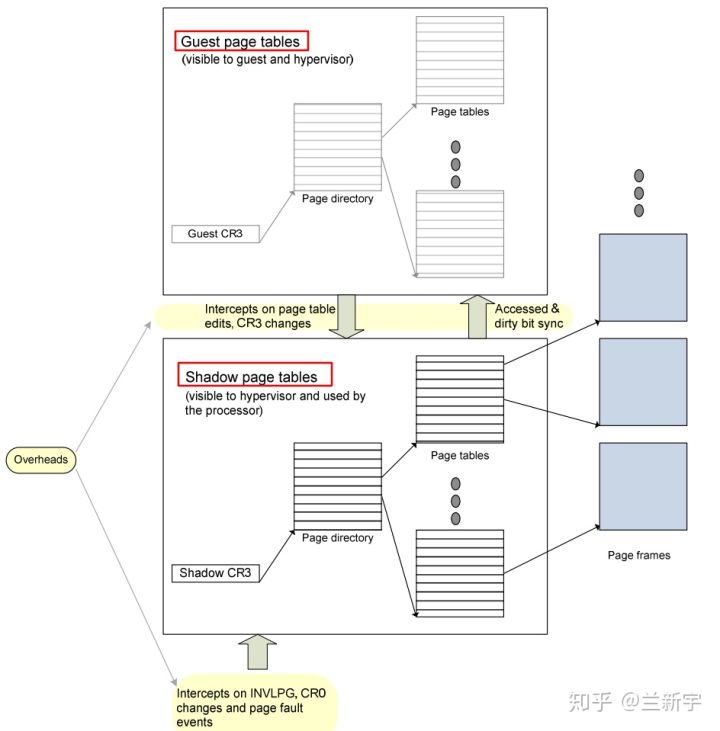
在「影子页表」的方案中,CPU还是按照传统的方式来进行内存的寻址(一次转换),因此CPU并不感知,为了更好的支持虚拟化,各大CPU厂商相继推出了硬件辅助的内存虚拟化技术,比如Intel的EPT(Extended Page Table)和AMD的NPT(Nested Page Table),它们都能够从硬件上同时支持GVA->GPA和GPA->HPA的地址转换的技术
GVA->GPA的转换依然是通过查找gPT页表完成的,而GPA->HPA的转换则通过查找nPT页表来实现,每个guest VM有一个由VMM维护的nPT。其实,EPT/NPT就是一种扩展的MMU(以下称EPT/NPT MMU),它可以交叉地查找gPT和nPT两个页表。在这种方案下,CPU是明确感知这是虚拟机的寻址过程
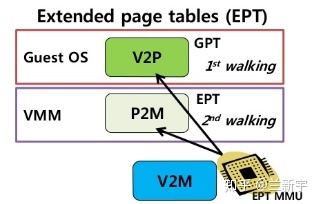
假设gPT和nPT都是4级页表,那么EPT/NPT MMU完成一次地址转换的过程是这样的(不考虑TLB):
首先它会查找guest VM中CR3寄存器(gCR3)指向的PML4页表,由于gCR3中存储的地址是GPA,因此CPU需要查找nPT来获取gCR3的GPA对应的HPA。nPT的查找和前面文章讲的页表查找方法是一样的,这里我们称一次nPT的查找过程为一次nested walk
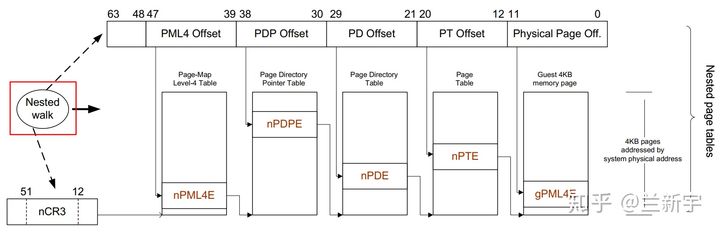
如果在nPT中没有找到,则产生EPT violation异常(可理解为VMM层的page fault)。如果找到了,也就是获得了PML4页表的物理地址后,就可以用GVA中的bit位子集作为PML4页表的索引,得到PDPE页表的GPA。接下来又是通过一次nested walk进行PDPE页表的GPA->HPA转换,然后重复上述过程,依次查找PD和PE页表,最终获得该GVA对应的HPA
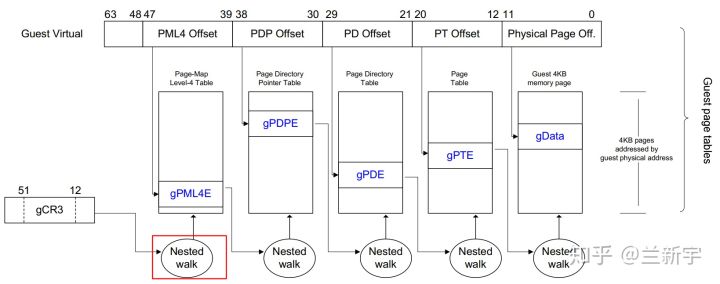
不同于影子页表是一个进程需要一个sPT,EPT/NPT MMU解耦了GVA->GPA转换和GPA->HPA转换之间的依赖关系,一个VM只需要一个nPT,减少了内存开销。如果guest VM中发生了page fault,可直接由guest OS处理,不会产生vm-exit,减少了CPU的开销。可以说,EPT/NPT MMU这种硬件辅助的内存虚拟化技术解决了纯软件实现存在的两个问题
EPT/NPT MMU优化
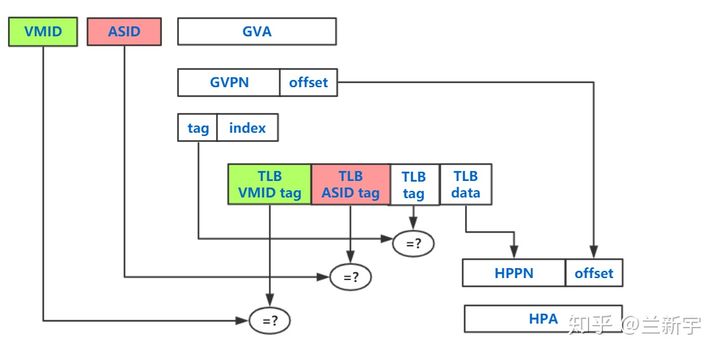
事实上,EPT/NPT MMU作为传统MMU的扩展,自然也是有TLB的,它在查找gPT和nPT之前,会先去查找自己的TLB(前面为了描述的方便省略了这一步)。但这里的TLB存储的并不是一个GVA->GPA的映射关系,也不是一个GPA->HPA的映射关系,而是最终的转换结果,也就是GVA->HPA的映射
不同的进程可能会有相同的虚拟地址,为了避免进程切换的时候flush所有的TLB,可通过给TLB entry加上一个标识进程的PCID/ASID的tag来区分(参考这篇文章)。同样地,不同的guest VM也会有相同的GVA,为了flush的时候有所区分,需要再加上一个标识虚拟机的tag,这个tag在ARM体系中被叫做VMID,在Intel体系中则被叫做VPID
在最坏的情况下(也就是TLB完全没有命中),gPT中的每一级转换都需要一次nested walk,而每次nested walk需要4次内存访问,因此5次nested walk总共需要(4 + 1) * 5 - 1 =24次内存访问(就像一个5x5的二维矩阵一样):
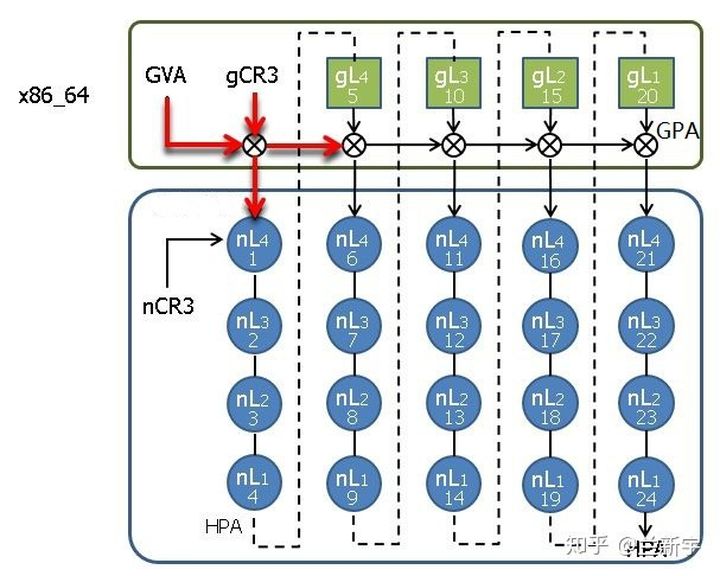
虽然这24次内存访问都是由硬件自动完成的,不需要软件的参与,但是内存访问的速度毕竟不能与CPU的运行速度同日而语,而且内存访问还涉及到对总线的争夺,次数自然是越少越好。
要想减少内存访问次数,要么是增大EPT/NPT TLB的容量,增加TLB的命中率,要么是减少gPT和nPT的级数。gPT是为guest VM中的进程服务的,通常采用4KB粒度的页,那么在64位系统下使用4级页表是非常合适的(参考这篇文章)。
而nPT是为guset VM服务的,对于划分给一个VM的内存,粒度不用太小。64位的x86_64支持2MB和1GB的large page,假设创建一个VM的时候申请的是2G物理内存,那么只需要给这个VM分配2个1G的large pages就可以了(这2个large pages不用相邻,但large page内部的物理内存是连续的),这样nPT只需要2级(nPML4和nPDPE)
如果现在物理内存中确实找不到2个连续的1G内存区域,那么就退而求其次,使用2MB的large page,这样nPT就是3级(nPML4,nPDPE和nPD)
4.1 问题
- 内核是直接访问内存的么?(内核和内存之间是否存在抽象层)。内核面向的是内存的物理地址还是逻辑地址?(固定的起始地址?)。内核是怎么感知到物理地址的范围的
- 在内存分页的方案中,cpu访问的是虚拟内存地址,即页号+页内偏移。但是程序本身应该不感知这个事情,程序又是如何使用内存的呢
- 内存管理是CPU完成的还是OS完成的?(MMU是CPU的一个芯片)
- 每个进程的页表目录都不同么?页表目录本身不经过内存管理么?
- Guest上的进程在访问内存时,如果产生了一个缺页异常,为啥捕获到异常的是Guest Kernel而不是Host Kernel
- CPU在发现缺页异常后,会通过寄存idtr查询中断描述符表(Interrupt Descriptor Table,IDT),并根据表中的地址来获取相应的中断处理程序。当Guest运行的时候,CPU的该寄存器内填写的是Guest OS的IDT,因此捕获到异常的是Guest Kernel而不是Host Kernel
- 段寄存器中包含了特权指令级别(ring0-ring3),当Guest访问ring0级别的段时,为啥会报错?寄存器中的ring级别又没有虚拟化,Guest的ring0和Host的ring0有什么差别呢?
- 影子页表如何起作用?GVA->GPA,内存的寻址过程已经结束了,为啥可以再插入一个GPA-HPA的过程?
- 并不是插入一个GPA-HPA的过程,而是让GVA直接映射到HPA(Guest在一次正常的寻址就能直接定位到物理机的内存)
4.2 参考
- 20 张图揭开「内存管理」的迷雾,瞬间豁然开朗
- 线性地址转换为物理地址是硬件实现还是软件实现?具体过程如何?
- 浅谈Linux内存管理
- 虚拟化技术 - 内存虚拟化 [一]
- 虚拟化技术 - 内存虚拟化 [二]
- 内存虚拟化之影子页表
- 影子页表的问题?
- What exactly do shadow page tables (for VMMs) do?
- 内存虚拟化之基本原理
5 QEMU
5.1 参考
6 KVM
6.1 参考
7 KVM初体验
物理机系统:CentOS-7-x86_64-DVD-1810.iso
查看系统是否支持kvm
1 | lsmod | grep kvm |
软件安装:
1 | yum install -y qemu-kvm qemu-img |
用于安装虚拟机的镜像为:CentOS-7-x86_64-Minimal-1908.iso,运行虚拟机的命令如下
1 | # 创建虚拟网桥br0 |
看起来是因为没有安装图形化的工具
1 | yum install -y 'virt-viewer' |
由于我是通过ssh连到服务器上,然后执行相关指令的,看起来这种方式不行,得在服务器上装一个桌面应用,然后通过vnc连接过去,再执行virt-install进行安装
1 | # 安装桌面应用 |
通过vnc-client登录到该机器上之后,再执行下面的操作
1 | virsh destroy myvm_centos7 |
以图形化的方式连入虚拟机:
- 通过
vnc-client连接到服务器上 virt-viewer -a <vmname>
以文本的方式连入虚拟机:
- 通过
ssh或其他方式连接到服务器上 virsh console <vmname>
1 | virsh console myvm_centos7 |
7.1 常用命令
virsh domiflist <vmname>virsh attach-interface <vmname> --type bridge --source <主机上的网卡名>virsh detach-interface <vmname> --type bridge --mac <网卡mac地址>
7.2 参考
- KVM 介绍(1):简介及安装
- virsh console连接虚拟机遇到的问题
- 【虚拟化】KVM、Qemu、Virsh的区别与联系
- How to install KVM on CentOS 7 / RHEL 7 Headless Server
- Install and Configure VNC Server in CentOS 7 and RHEL 7
- 阿里云CentOS7.x服务器安装GNOME桌面并使用VNC server
8 TODO
- 物理机的内核如何与硬件交互?软件分层之后,下层才能屏蔽差异(欺骗)。虚拟机又是如何被虚拟硬件欺骗的?
- 总线、RAM、CPU、时钟。内存和CPU如何通信。VM使用的是物理内存中的某一段,VM中内存与CPU的交互与普通进程的内存与CPU的交互是类似的
- 基于二进制翻译的全虚拟化,VMM如何捕获异常?
- 客户机代码执行流程(内核or用户代码)