阅读更多
1 Java基础
-
面向对象的三大特性
封装
继承
多态 -
重载与多态
重载横向,静态双分派。a.f(b),a的静态类型+b的静态类型
纵向,动态单分派。a.f(b),a的动态类型+b的静态类型 -
多态
- 要有继承关系
- 子类要重写父类的方法
- 父类引用指向子类
-
Object的public方法
- getClass:获取Class对象的实例
- hashCode:获取hash值,HashMap的实现依赖于hashcode。两个对象的hashCode可能是相同的。默认值与内存位置有关
- equals:判断对象是否相等
- toString:返回一个表示当前对象的String
- notify:重量级锁的wait/Notify机制
- notifyAll:重量级锁的wait/Notify机制
- wait:重量级锁的wait/Notify机制
-
Object的protected方法
- clone:浅拷贝,仅复制内存,如果包含引用类型,那么拷贝前后将会指向同一个对象
- finalize:与垃圾收集有关,第一次回收时会调用该方法,但不保证调用,也不保证正确执行。因此别用这个东西,历史遗留问题
-
cloneable接口与浅拷贝/深拷贝
实现cloneable接口必须调用父类Object.clone()方法来进行内存的拷贝
如果不加其他的逻辑,实现的就是浅拷贝。即副本中的内存与原象中的内存完全一致,意味着如果存在引用类型,那么副本与原象将引用的是同一个对象
如果要实现深拷贝,那么就需要加上额外的实现逻辑 -
String/StringBuffer/StringBuilder的区别
- 只有String中的char[]数组是final的
- StringBuffer是线程安全的,所有char[]数组的access方法被synchronized关键字修饰
- StringBuilder非线程安全
-
容器常用接口
- Collection
- List
- Set
- Map
- Queue
-
容器常用实现
- ArrayList
- LinkedList
- HashSet
- HashMap
- TreeMap
- LinkedHashMap
-
Arrays.sort实现原理
针对对象类型和基本类型,Arrays.sort会采用不同的排序算法
- 对象类型必须保证稳定性,因此采用的是插入排序以及归并排序的优化版本TimSort,具体详见SourceAnalysis-ComparableTimSort
- 基本类型的稳定性是不必要的,因此根据数组的长度以及分布规律选择特定的排序算法,包括插入排序,快速排序(3-way-quicksort以及2-pivot-quicksort),具体详见SourceAnalysis-DualPivotQuickSort
-
Collection.sort实现原理
Collection.sort在内部会转调用Arrays.sort
- 调用List#toArray()方法,生成一个数组
- 调用Arrays.sort方法进行排序
- 将排序好的序列利用迭代器回填到List当中(为什么用迭代器,因为这样效率是最高的,如果List的实现是LinkedList,那么采用下标将会非常慢)
-
LinkedHashMap的应用
实现一个LRU(Least Recently Used)
-
HashMap的并发问题
- 多线程put操作后,get操作导致死循环。(扩容时)
- 多线程put非NULL元素后,get操作得到NULL值。(扩容时,插入到了旧表中)
- 多线程put操作,导致元素丢失
具体参考http://www.cnblogs.com/kxdblog/p/4323892.html
-
Hashtable和HashMap的区别及实现原理
Hashtable是线程安全的,所有方法加上了synchronized关键字,效率较低(在单线程情况下由于JDK 1.6以后JVM对内建锁机制进行了优化,性能可能较为接近?但是并发效率远低于ConcurrentHashMap)
-
HashMap会问到数组索引,hash碰撞怎么解决
一般用链表法,实现较为简单,如果链表元素过多转为红黑树
另一种是开放寻址法,装载因子必定不大于1。采用这种方式的前提是,尽量保证不同元素遍历整个hashtable的顺序不一样,即等可能的是m!其中之一 -
HashMap可以只存Value么?
不可以,如果某个槽位存在冲突,那么取用哪一个value呢?此时只能通过键值的equals方法来进行比较
-
链表法解决冲突的缺点
链表长度过大会降低查询效率
可以用红黑树来解决,这也是HashMap和ConcurrentHashmap的解决方式 -
Class文件结构
Java-ClassFile-Structure
-
字节码的种类
Java-ClassFile-Structure
- 加载和存储指令
- 运算指令
- 类型转换指令
- 对象创建与访问指令
- 操作数栈管理指令
- 控制转义指令
- 方法调用和返回指令
- 异常处理指令
- 同步指令
-
foreach和while在编译之后的区别
foreach只能引用于实现了Iterator接口的类,因此在内部实现时会转化为迭代器的遍历,本质上是一种语法糖
while和for循环在编译之后基本相同,利用字节码goto来进行循环跳转 -
泛型
Java的泛型是通过擦除实现的,所有类只有一份代码,而C++的泛型是通过编译器生成特定类型的代码来实现的,代码有多份
编译期类型检查,将运行时异常提前到编译期
代码复用 -
Java泛型,类型信息何时保留,何时擦除
当前类的泛型信息会擦除
位于继承链路上的泛型信息会保留,例如class A extends B<Integer>,父类的类型B<Integer>会记录在A的class文件中 -
反射的原理
Class对象是访问类型信息的入口
-
Class.forName和ClassLoader#loadClass的区别
Class.forName执行过程
- 加载
- 验证-准备-解析:该过程称为链接
- 初始化
ClassLoader#loadClass执行过程
- 加载
详细类加载机制请参考Java-类加载机制
-
获取Class对象的方式
Class clazz = Class.forName(<string>)Class clazz = obj.getClass()Class clazz = <class>.class
-
为什么静态内部类和非静态内部类能够访问外围类的private属性或方法
对于private字段或者方法,在类的作用域中才能访问。而内部类(静态或者非静态)都存在于外围类的作用域中,因此可以访问外围类的private字段或者方法
-
非静态内部类为什么可以访问外围类的字段,如何实现
outer.new Inner();
在这种特殊的语法中,会向内部类传递外围类的引用。内部类隐含持有外围类对象的引用 -
Java NIO使用
Java-NIO
-
动态代理源码
SourceAnalysis-DynamicProxy
-
线程池的目的
目的是为了减少程序并发执行所付出的时空开销,使操作系统具有更好的并发性
-
线程池的种类,区别和使用场景
所有线程池本质上都是ThreadPoolExecutor,只是配置了不同的初始化参数。首先来看一个线程池构造方法
1
2
3
4
5
6
7
8public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}从构造方法的参数中可以看出ThreadPoolExecutor的核心参数有
- corePoolSize:核心线程数量,所谓核心线是指即便空闲也不会终止的线程(allowCoreThreadTimeOut必须是false)
- maximumPoolSize:最大线程数量,核心线程+非核心线程的总数不能超过这个数值
- keepAliveTime:非核心线程在空闲状态下保持active的最长时间,超过这个时间若仍然空闲,那么该线程便会结束
- unit:keepAliveTime的单位
- workQueue:任务队列,任务队列的不同,直接影响了线程池的行为
Executors.newCachedThreadPool()
1
2
3
4
5public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}- 注意到,这里用到了SynchronousQueue作为任务队列,这个任务队列相比于LinkedBlockingQueue而言有一个非常大的不同。
LinkedBlockingQueue#offer方法仅在任务队列达到最大容量时失败;SynchronousQueue#offer方法会在没有其他线程阻塞在取用任务时失败,也就是说执行offer方法时,如果没有线程阻塞在take方法上,那么offer失败
Executors.newSingleThreadExecutor()
1
2
3
4
5
6public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}Executors.newFixedThreadPool(int nThread)
1
2
3
4
5public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
} -
分析线程池的实现原理和线程的调度过程
添加一个新的Runnable时
- 当前线程数量小于核心线程数量时,开启新线程执行该任务
- 否则,将任务添加到任务队列,若添加任务成功则结束(还有一些细致的操作)
- 否则,若当前线程数量小于最大线程数量,则开启新线程执行该任务
- 否则,执行拒绝策略拒绝该任务
每个Work(线程)会从任务队列中获取任务
- 如果当前线程数量不大于核心线程数量,那么空闲线程会阻塞直至取到任务
- 如果当前线程数量大于核心线程数量,那么空闲线程会阻塞直至取到任务或者超时(keepAliveTime)
-
线程池如何调优
可以从以下几个方面考虑
- 最大线程数量:与CPU的数量相关
- 最小线程数量:一般设定得比较小,防止系统初期创建太多线程,节省系统资源,并且指定一个最小线程数量的负面影响比较小
- 任务的频繁程度:如果线程太少,那么等待的时间会很短,如果线程很多,最坏的情况下就是一个任务就开一个线程,那么此时CPU开销将会比较大
考虑阻塞队列的实现,ArrayBlockingQueue,LinkedBlockingQueue,SynchronousQueue等等
http://www.cnblogs.com/jianzh5/p/6437315.html
-
Java中最大线程数量
决定因素有三个
- MaxProcessMemory:操作系统留给用户空间的内存总大小
- JVMMemory:JVM分配的内存大小(通过-Xms与-Xmx来设定)
- ReservedOsMemory:操作系统保留内存大小
- ThreadStackSize:线程堆栈的大小(Java线程依赖操作系统原生线程,而线程只有栈是私有的),可以通过-Xss参数来设定
公式:(MaxProcessMemory - JVMMemory - ReservedOsMemory) / (ThreadStackSize) = Number of threads
-
如何知道哪个是核心线程?
worker是有个标记的,标记是否为core线程
-
线程池的keepAlive如何实现的?
keepAlive如何实现,阻塞获取任务时,会根据当前线程数量是否大于core线程数量来决定是否要加超时时间(keepalive)。线程退出时,会唤醒所有线程,避免阻塞在获取任务上
-
JDK各个版本的特性
JDK 5
- 自动装箱与拆箱
- 枚举
- 静态导入
- 可变参数
- 泛型
- For-Each循环
JDK 6
不太常用的新特性,不罗列了JDK 7
- 二进制字面值
- 数字变量下划线的支持
- switch对String支持
- try-with-resource
- 捕获多种异常
- 创建泛型时的类型推断
- fork/join
- G1
JDK 8
- Lambdas表达式与Function接口
- parallel
具体内容请参考JDK-Features
-
单例模式
-
在装饰器模式和代理模式之间,你如何抉择,请结合自身实际情况聊聊
装饰器模式关注于在一个对象上动态的添加方法,然而代理模式关注于控制对对象的访问。换句话说,用代理模式,代理类(proxy class)可以对它的客户隐藏一个对象的具体信息。因此,当使用代理模式的时候,我们常常在一个代理类中创建一个对象的实例。并且,当我们使用装饰器模式的时候,我们通常的做法是将原始对象作为一个参数传给装饰者的构造器
-
JDK源码中都用了哪些设计模式
创建型模式
- 工厂方法模式:就是一个返回具体对象的方法
java.lang.Proxy#newProxyInstance()java.lang.Object#toString()java.lang.Class#newInstance()
- 抽象工厂模式:抽象工厂模式提供了一个协议来生成一系列的相关或者独立的对象,而不用指定具体对象的类型。它使得应用程序能够和使用的框架的具体实现进行解耦。这在JDK或者许多框架比如Spring中都随处可见。它们也很容易识别,一个创建新对象的方法,返回的却是接口或者抽象类的,就是抽象工厂模式了
java.util.Arrays.asList()
- 单例模式:用来确保类只有一个实例。Joshua Bloch在Effetive Java中建议到,还有一种方法就是使用枚举
java.lang.Runtimesun.misc.Unsafe
- 建造者模式:定义了一个新的类来构建另一个类的实例,以简化复杂对象的创建。建造模式通常也使用方法链接来实现
java.lang.StringBuilder
- 原型模式:使得类的实例能够生成自身的拷贝。如果创建一个对象的实例非常复杂且耗时时,就可以使用这种模式,而不重新创建一个新的实例,你可以拷贝一个对象并直接修改它
java.lang.Object#clone()
结构型模式
- 适配器模式:用来把一个接口转化成另一个接口
java.io.InputStreamReader(InputStream)java.io.OutputStreamWriter(OutputStream)
- 装饰器模式:动态的给一个对象附加额外的功能,这也是子类的一种替代方式。可以看到,在创建一个类型的时候,同时也传入同一类型的对象
- Java IO
- 代理模式:代理模式是用一个简单的对象来代替一个复杂的或者创建耗时的对象
- JDK 动态代理
- 外观(门面)模式:给一组组件,接口,抽象,或者子系统提供一个简单的接口
java.lang.Class提供了访问类元数据的接口
- 桥接模式:这个模式将抽象和抽象操作的实现进行了解耦,这样使得抽象和实现可以独立地变化
- JDBC,一个公共的对象持有一个接口,接口可以在不同实现中切换,对于用户而言,只需要持有这个公共对象即可
- 组合模式:使得客户端看来单个对象和对象的组合是同等的。换句话说,某个类型的方法同时也接受自身类型作为参数
java.util.List#addAll(Collection)
- 享元模式:使用缓存来加速大量小对象的访问时间
Integer.valueOf
行为型模式
- 策略模式:使用这个模式来将一组算法封装成一系列对象。通过传递这些对象可以灵活的改变程序的功能
java.util.Comparator#compare()
- 模板方法模式:让子类可以重写方法的一部分,而不是整个重写,你可以控制子类需要重写那些操作
java.util.Collections#sort()
- 观察者模式:它使得一个对象可以灵活的将消息发送给感兴趣的对象
java.util.EventListener
- 迭代子模式:提供一个一致的方法来顺序访问集合中的对象,这个方法与底层的集合的具体实现无关
java.util.Iterator
- 责任链模式:通过把请求从一个对象传递到链条中下一个对象的方式,直到请求被处理完毕,以实现对象间的解耦
java.util.logging.Logger#log()
- 命令模式:将操作封装到对象内,以便存储,传递和返回。命令模式的目的就是达到命令的发出者和执行者之间的解耦
java.lang.Runnable
- 备忘录模式:生成对象状态的一个快照,以便对象可以恢复原始状态而不用暴露自身的内容。Date对象通过自身内部的一个long值来实现备忘录模式
java.util.Datejava.io.Serializable
- 状态模式:通过改变对象内部的状态,使得你可以在运行时动态改变一个对象的行为
java.util.Iterator
- 访问者模式:提供一个方便的可维护的方式来操作一组对象。它使得你在不改变操作的对象前提下,可以修改或者扩展对象的行为
- 中介者模式:通过使用一个中间对象来进行消息分发以及减少类之间的直接依赖
- Spring
- 解释器模式:这个模式通常定义了一个语言的语法,然后解析相应语法的语句
java.util.Pattern
2 JVM
-
垃圾收集算法
Java-垃圾收集算法
-
垃圾收集器
Java-垃圾收集器
-
JVM参数
JVM-Options
-
Java方法区存了什么
静态字段
常量池
方法等数据
待补充 -
JVM内存分代
新生代、老年代、永久代
JDK 8中并无物理上分隔的分代,仅仅保留概念,取而代之的是Region
其中新生代采用的是复制算法,Eden和Survivor分为8:1
Java 8的内存分代改进- 用Region来替代,仅仅保留新生代和老年代的概念
- G1收集器会维护一个Region的列表,每次回收一个最有受益的Region,这也是G1收集器名字的来源,Garabage first
-
何时触发Minor GC/Full GC
Minor GC触发条件
- 当Eden区满时,触发MinorGC
Full GC触发条件 - 调用System.gc,系统建议执行Full GC,但并非必然执行
- 老年代空间不足
- 方法区空间不足
- 通过Minor GC后进入老年代的平均大小大于老年大的可用内存
- 由Eden区和From Space区向To Space区复制时,对象大小大于To Space可用内存,则把该对象转存到老年代,且老年代的可用内存小于该对象大小
- 当Eden区满时,触发MinorGC
-
对象如何晋升到老年代
经过数次Minor GC后仍然存活的对象进入老年代
-XX:MaxTenuringThreshold -
mataspace与permgen的区别
-
新生代和老生代的内存回收策略
新生代:复制算法,因为对象朝生夕死
老年代:标记-清除或者标记整理 -
Eden和Survivor的比例分配等
默认8:1,如果不够用,则由老年代来担保
-
G1和CMS的区别
Java-垃圾收集器
-
吞吐量优先和响应优先的垃圾收集器选择
吞吐量优先
- Parallel Scavenge + Parallel Old 收集器
- G1
响应优先 - CMS
- G1
-
强/软/弱/虚引用与GC
Java-对象生命周期
-
OutOfMemory异常
经过GC后,仍然无法为新产生的对象分配内存空间
-
StackOverFlow
函数调用层次太深,或者栈内存太小
-
PermGen Space
反射或者动态代理生成的类型对象过多
-
类加载机制
类加载过程如下
- 加载:获取.class文件的二进制字节流
- 验证:文件格式验证、元数据验证、字节码验证、符号引用验证
- 准备:内存清零
- 解析:将符号引用替换为直接引用
- 初始化:执行静态初始化语句以及静态子句
- 其中验证、准备、解析称为链接
详细内容请参考Java-类加载机制
-
双亲委派
Java-类加载机制
-
自定义的类加载器可以违反双亲委派规则吗
待补充
-
静态内部类的单例一定安全吗
当类加载器违反双亲委派规则的时候,可能会生成多个实例
-
三个类加载器
- Bootstrap ClassLoader
- Extension ClassLoader
- Application ClassLoader
详细内容请参考Java-类加载机制
-
类的初始化顺序
比如父类静态数据,构造函数,字段,子类静态数据,构造函数,字段,他们的执行顺序
以一个程序来说明1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46public class Test {
public static int init(String s) {
System.out.println(s);
return 1;
}
public static void main(String[] args){
new Derive();
}
}
class Base {
private static int si = Test.init("init Base's static field");
private int i=Test.init("init Base's field");
static{
Test.init("init Base's static Statement");
}
{
Test.init("init Base's Statement");
}
public Base(){
Test.init("init Base's constructor");
}
}
class Derive extends Base{
private static int si = Test.init("init Derive's static field");
private int i=Test.init("init Derive's field");
static{
Test.init("init Derive's static Statement");
}
{
Test.init("init Derive's Statement");
}
public Derive(){
Test.init("init Derive's constructor");
}
}以下是输出
1
2
3
4
5
6
7
8
9
10init Base's static field
init Base's static Statement
init Derive's static field
init Derive's static Statement
init Base's field
init Base's Statement
init Base's constructor
init Derive's field
init Derive's Statement
init Derive's constructor -
环境变量classpath
说一说你对环境变量classpath的理解?如果一个类不在classpath下,为什么会抛出ClassNotFoundException异常,如果在不改变这个类路径的前期下,怎样才能正确加载这个类?
环境变量classpath是JVM的App ClassLoader类加载器的加载*.class文件的路径
加载类的过程可以交给自定义的类加载器来执行,可以自定义类加载器,可以从任何地方获取一段.class文件的二进制字节流,这便是类的加载过程 -
class文件结构
- 魔数
- 次版本号
- 主版本号
- 常量计数值
- 常量池
- 访问标志
- 类索引
- 父类索引
- 接口计数值
- 接口
- 字段即数值
- 字段
- 方法计数值
- 方法
- 属性计数值
- 属性
-
JMM
-
锁机制
-
java程序退出了,有什么方法可以分析
-
full gc的问题如何分析
3 JUC
-
源码相关
- SourceAnalysis-AQS
- SourceAnalysis-AQS-ConditionObject
- SourceAnalysis-ReentrantLock
- SourceAnalysis-ReentrantReadWriteLock
- SourceAnalysis-ArrayBlockingQueue
- SourceAnalysis-ThreadPoolExecutor
- SourceAnalysis-FutureTask
- SourceAnalysis-ConcurrentHashMap
- SourceAnalysis-CountDownLatch
- SourceAnalysis-CyclicBarrier
- SourceAnalysis-Exchanger
- SourceAnalysis-Semaphore
- SourceAnalysis-ForkJoin
- SourceAnalysis-ThreadLocal
-
ThreadLocal原理是什么
ThreadLocal的实现需要Thread的配合,Thread内部为ThreadLocal增加了一个字段
threadLocals,该字段是一个Map<ThreadLocal,T>,也就是说,不同的ThreadLocal对于同一个线程的值将会存放在这个Thread#threadLocals字段中
Map以及Map.Entry都是延迟初始化的 -
并发容器有哪些
- ConcurrentHashMap
- ConcurrentLinkedDeque
- ConcurrentLinkedQueue
- ConcurrentSkipListMap
- ConcurrentSkipListSet
-
synchronized与其他锁机制
-
Lock
Lock是ReentrantLock,其实现依赖于AQS,是一种无锁数据结构
公平锁与非公平锁是ReentrantLock的概念- 公平锁意味着当一个线程尝试获取锁时,首先检查是否有其他线程正在等待这把锁。如果有其他线程,那么当前线程直接进入等待队列。否则才尝试获取锁
- 非公平锁意味着当一个线程尝试获取锁时,它首先尝试获取一下锁,失败了才会进入队列,这对于已经在队列中等待的线程而言是不公平的,在队列中等待的线程可能会被饿死
-
ConcurrentHashMap
- 并发扩容
- Node/TreeNode/TreeBin/ForwardingNode
- 链表、红黑树
- table大小为2的幂次,这样做可以实现一个扩张单调性,类似于一致性hash
- hash值的改造
详细源码剖析请参考SourceAnalysis-ConcurrentHashMap - 1.8把锁粒度降低有没有坏处
-
原子类实现原理
循环+CAS,即自旋
-
CAS操作
详细内容请参考Java-原子操作的实现原理
-
如果让你实现一个并发安全的链表,你会怎么做
参考ConcurrentLinkedQueue的实现
-
ConcurrentLinkedQueue与LinkedBlockingQueue的联系与区别
简而言之
- ConcurrentLinkedQueue是Queue接口的一个安全实现
- LinkedBlockingQueue是BlockingQueue的一种实现,被用于生产消费者队列
详细内容请参考http://www.cnblogs.com/linjiqin/archive/2013/05/30/3108188.html
-
CountDownLatch和CyclicBarrier的用法,以及相互之间的差别?
CountDownLatch
- 假设构造方法传入的数值是n,那么某个线程调用了CountDownLatch#await,那么当且仅当有n个线程调用过
- CountDownLatch#countDown方法后,调用了CountDownLatch#await才会从阻塞中被唤醒
- 注意调用CountDownLatch#countDown的线程并不会被阻塞
CyclicBarrier
- 假设构造方法传入的是n,那么当且仅当n个线程调用了CyclicBarrier#await后,这n个线程才会从阻塞中被唤醒
-
Unsafe
Unsafe是JDK实现所依赖的一个非公开的类,用于提供一些内存操作以及CAS操作等等。不具有跨平台性质,不同平台的实现可能有差异
Unsafe详细源码请参考SourceAnalysis-Unsafe -
LockSupport
- LockSupport.park
- LockSupport.unpark
可以先unpark再park,unpark可以理解为获取一个许可。但是多次调用unpark只有一个许可
-
Condition
两个重要方法,提供类似于wait/notify的机制
- await
- signal/signalAll
与Object提供的wait/notify的机制不同,await/signal可以提供多个不同的等待队列
有关ConditionObject源码剖析请参考SourceAnalysis-AQS-ConditionObject -
Fork/Join
从宏观上来说就是一个类似于归并的过程,将问题拆分成子问题,最终合并结果
关于Fork/Join的源码请参考SourceAnalysis-ForkJoin -
parallelStream
parallelStream其实就是一个并行执行的流。它通过默认的ForkJoinPool,可能提高你的多线程任务的速度
JDK 1.8之后,ForkJoinPool内部新添了一个全局的线程池,用于执行那些没有显式创建ForkJoinPool的并行任务。例如parallelStream
http://blog.csdn.net/u011001723/article/details/52794455 -
分段锁的原理
分段锁就是细化锁操作,类比于表锁和行锁。JDK 1.7中的ConcurrentHashMap的实现就是使用了分段锁,将整个hashtable分成多个Segment,访问某个元素必须获取该元素对应的Segment的锁,如果两个元素位于两个Segment,那么这两个元素的并发操作是不需要同步的
-
有一个第三方接口,有很多个线程去调用获取数据,现在规定每秒钟最多有10个线程同时调用它,如何做到
待补充
-
用三个线程按顺序循环打印abc三个字母,比如abcabcabc
CAS能实现吗?CAS加循环可以串行化并行操作,但是,不能很好地排序,即控制三个线程交替执行CAS成功
公平模式下,并且规定启动顺序时,可以用ReentrantLock1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class Solution {
private static ReentrantLock lock = new ReentrantLock(true);
private static Condition conditionA = lock.newCondition();
private static Condition conditionB = lock.newCondition();
private static Condition conditionC = lock.newCondition();
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
public void run() {
try {
lock.lock();
while (!Thread.currentThread().isInterrupted()) {
System.out.println("a");
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
break;
}
conditionB.signal();
try {
conditionA.await();
} catch (InterruptedException e) {
break;
}
}
} finally {
lock.unlock();
}
}
});
Thread t2 = new Thread(new Runnable() {
public void run() {
try {
lock.lock();
while (!Thread.currentThread().isInterrupted()) {
System.out.println("b");
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
break;
}
conditionC.signal();
try {
conditionB.await();
} catch (InterruptedException e) {
break;
}
}
} finally {
lock.unlock();
}
}
});
Thread t3 = new Thread(new Runnable() {
public void run() {
try {
lock.lock();
while (!Thread.currentThread().isInterrupted()) {
System.out.println("c");
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
break;
}
conditionA.signal();
try {
conditionC.await();
} catch (InterruptedException e) {
break;
}
}
} finally {
lock.unlock();
}
}
});
t1.start();
try {
TimeUnit.MICROSECONDS.sleep(100);
} catch (InterruptedException e) {
}
t2.start();
try {
TimeUnit.MICROSECONDS.sleep(100);
} catch (InterruptedException e) {
}
t3.start();
try {
TimeUnit.SECONDS.sleep(15);
} catch (InterruptedException e) {
}
t1.interrupt();
t2.interrupt();
t3.interrupt();
}
}volatile来实现,其中volatile只是为了保证可见性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73import java.util.concurrent.TimeUnit;
public class Solution {
private static volatile int state = 0;
public static void main(String[] args) {
Thread t1 = new Thread(new Runnable() {
public void run() {
while (!Thread.currentThread().isInterrupted()) {
if (state == 0) {
System.out.println("a");
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
break;
}
state = 1;
}
}
}
});
Thread t2 = new Thread(new Runnable() {
public void run() {
while (!Thread.currentThread().isInterrupted()) {
if (state == 1) {
System.out.println("b");
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
break;
}
state = 2;
}
}
}
});
Thread t3 = new Thread(new Runnable() {
public void run() {
while (!Thread.currentThread().isInterrupted()) {
if (state == 2) {
System.out.println("c");
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
break;
}
state = 0;
}
}
}
});
t1.start();
t2.start();
t3.start();
try {
TimeUnit.SECONDS.sleep(15);
} catch (InterruptedException e) {
}
t1.interrupt();
t2.interrupt();
t3.interrupt();
}
} -
interrupt状态恢复
Thread.isInterrupted()方法本身会将中断标志位复位 -
java对象头以及锁的优化
Java-synchronized的实现原理与应用
-
CAS和普通锁的适用场景
- 大概率不冲突:cas
- 大概率会冲突:锁
4 Spring
-
Spring AOP实现原理
AOP=增强收集以及适配+拦截器机制+动态代理
详细源码分析请参考SourceAnalysis-Spring-AOP
AOP中的术语- 切点:匹配关系
- 增强:增强逻辑以及方位信息
- 切面:增强和切点的组合
-
Spring IoC实现原理
待补充
-
非单例注入的原理?它的生命周期?
待补充
-
Spring的BeanFactory和FactoryBean的区别
BeanFactory就是IoC容器本身
FactorBean是一种工厂bean,调用指定的方法来生产对象 -
为什么CGlib方式可以对接口实现代理?
采用字节码技术,直接生成子类
-
RMI(Remote Method Invoke)与代理模式
待补充
-
Spring的事务传播级别,实现原理
PROPAGATION_SUPPORTS:支持当前事务,如果当前没有事务,就以非事务方式执行
PROPAGATION_MANDATORY:支持当前事务,如果当前没有事务,就抛出异常
PROPAGATION_REQUIRES_NEW:新建事务,如果当前存在事务,把当前事务挂起
PROPAGATION_NOT_SUPPORTED:以非事务方式执行操作,如果当前存在事务,就把当前事务挂起
PROPAGATION_NEVER:以非事务方式执行,如果当前存在事务,则抛出异常 -
MyBatis的底层实现原理
-
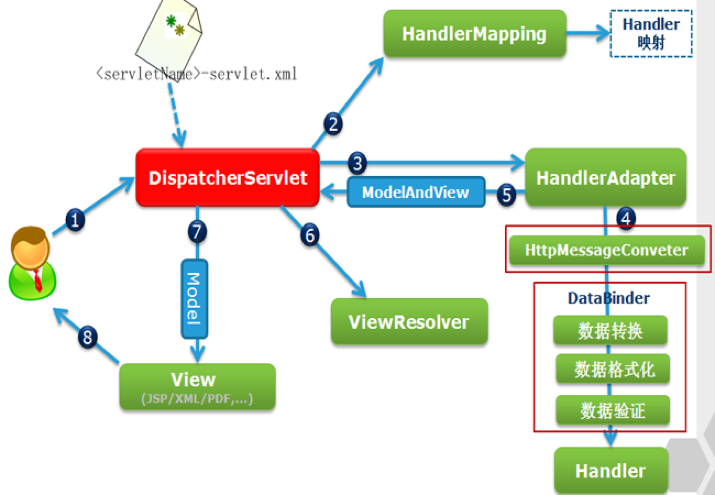
MVC框架原理,他们都是怎么做url路由的
-
Spring boot特性、优势、适用场景等
http://www.cnblogs.com/larryzeal/p/5799195.html#c4
Spring Boot 解决的问题,边界,适用场景
解决的问题:Spring框架创建一个可运行的应用比较麻烦,再加上很多Spring子项目和组件没有完善实践指导,让实际项目上选择使用哪些组件很困难。Spring Boot 的作用在于创建和启动新的基于 Spring 框架的项目。它的目的是帮助开发人员很容易的创建出独立运行和产品级别的基于 Spring 框架的应用。Spring Boot 会选择最适合的 Spring 子项目和第三方开源库进行整合。大部分 Spring Boot 应用只需要非常少的配置就可以快速运行起来。Spring Boot 包含的特性如下:- 创建可以独立运行的 Spring 应用
- 直接嵌入 Tomcat 或 Jetty 服务器,不需要部署 WAR 文件
- 提供推荐的基础 POM 文件来简化 Apache Maven 配置
- 尽可能的根据项目依赖来自动配置 Spring 框架
- 提供可以直接在生产环境中使用的功能,如性能指标、应用信息和应用健康检查
- 没有代码生成,也没有 XML 配置文件
- 通过 Spring Boot,创建新的 Spring 应用变得非常容易,而且创建出的 Spring 应用符合通用的最佳实践。只需要简单的几个步骤就可以创建出一个 Web 应用
-
quartz和timer对比
Java.util.Timer
- 在Java中有一个任务处理类java.util.Timer,非常方便于处理由时间触发的事件任务,只需建立一个继承java.util.TimerTask的子类,重载父类的run()方法实现具体的任务,然后调用Timer的public void schedule(TimerTask task, long delay, long period)方法实现任务的调度
- 但是这种方法只能实现简单的任务调度,不能满足任务调度时间比较复杂的需求。比如希望系统在每周的工作日的8:00时向系统用户给出一个提示,这种方法实现起来就困难了,还有更为复杂的任务调度时间要求
Quartz - OpenSymphony 的Quartz提供了一个比较完美的任务调度解决方案
- Quartz 是个开源的作业调度框架,为在 Java 应用程序中进行作业调度提供了简单却强大的机制
- Quartz中有两个基本概念:作业和触发器。作业是能够调度的可执行任务,触发器提供了对作业的调度
-
Spring的Controller是单例还是多例,怎么保证并发的安全
单例
无状态的单例本身就是线程安全的
有状态的单例那么就需要用ThreadLocal来保证线程安全了,即每个线程有自己的一份拷贝
5 其他框架
-
MyBatis
#和$的区别(http://blog.csdn.net/kobi521/article/details/16941403)
-
Netty
待补充
-
OkHttp
待补充
-
MINA
待补充
-
Cglib
待补充
-
SLF4J
待补充
-
JUNIT
待补充
-
mybatis
mybatis延迟加载
6 操作系统
-
操作系统内存管理
-
虚拟内存和物理内存是怎样一个关系
呵呵,一言难尽。Linux-Memory-Management
-
一个二进制的程序跑起来的它各个段在内存中的分布是什么样的
代码段、数据段、堆、共享内存、栈、内核
-
读取一个2G的文件需要多久?为什么?还有哪些因素会影响读取速度?
待补充
-
cache是什么东西
读写速度,成本,局部性原理
缓存一致性协议MESI- M:Modified,该行数据被修改,以和该数据在内存中的映像所不同。最新的数据只存在于Cache中
- E:Exclusive,该行数据有效,且数据与内存中的数据一致,但数据值只存在于本Cache中。通俗来说,该数据只在Cache中独一份
- S:Share,该行数据有效,且该数据与内存中的数据一致。同时,该数据存在与其它多个Cache中
- I:Invalid,该数据无效
-
- buffer是为了解决读写速率不一致的问题,比如从内存往磁盘上写数据,往往需要通过buffer来进行缓冲
- cache是为了解决热点问题,比如频繁访问一些热点数据,那么就可以把这些热点数据放到读性能更高的存储介质中
-
缓存替换策略有哪些
LRU(Least Recently Used)
LFU(Least Frequently Used)
RANDOM
FIFO -
介绍一下线程和进程
进程与线程
-
如果一个进程里有多个线程,其中一个崩溃了会发生什么
(共享内存、信号、信号的处理)https://www.zhihu.com/question/22397613
线程有自己的 stack,但是没有单独的 heap,也没有单独的 address space。只有进程有自己的 address space,而这个 space 中经过合法申请的部分叫做 process space。Process space 之外的地址都是非法地址。当一个线程向非法地址读取或者写入,无法确认这个操作是否会影响同一进程中的其它线程,所以只能是整个进程一起崩溃 -
进程间通信
-
如果有10个进程两两一对儿要通信,用一个消息队列能不能行
感觉不行?一个进程想要给另一个发送,那么如何保证其他线程不取用呢?
-
共享内存有啥缺陷
需要同步
-
多进程和多线程有什么区别
(还是很常规的问题,现在我想着如果大家自己做过一个小操作系统,这种东西是不是直接聊出风采;我说得并不好,一深挖就露怯,纸上得来终觉浅。比如会问到进程和线程的适用场景(需要有经验),进程切换比线程慢的原因(需要懂原理),切换时需要保存哪些数据,问得很细,光说PCB都不够,比如我说切换打开的文件符和资源什么的比较慢,面试官一针见血地说这些东西本来就在内存中,切换的时候难道需要关闭吗?问到最后只好承认并不清楚了)
-
进程有哪些运行状态
运行态:进程占用CPU,并在CPU上运行
就绪态:进程已经具备运行条件,但是CPU还没有分配过来
阻塞态:进程因等待某件事发生而暂时不能运行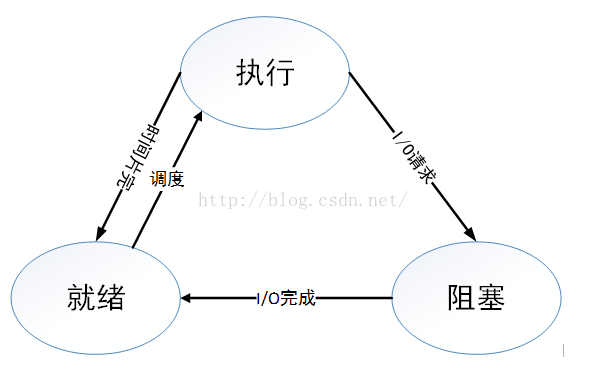
-
一串int型整数存放磁盘上的压缩存储方式,包括写入与读取及内存无法一次性读取时的解决办法
待补充
-
文件读写使用的系统调用
在 Linux 中,这种访问文件的方式是通过两个系统调用实现的:read() 和 write()。当应用程序调用 read() 系统调用读取一块数据的时候,如果该块数据已经在内存中了,那么就直接从内存中读出该数据并返回给应用程序;如果该块数据不在内存中,那么数据会被从磁盘上读到页高缓存中去,然后再从页缓存中拷贝到用户地址空间中去。如果一个进程读取某个文件,那么其他进程就都不可以读取或者更改该文件;对于写数据操作来说,当一个进程调用了 write() 系统调用往某个文件中写数据的时候,数据会先从用户地址空间拷贝到操作系统内核地址空间的页缓存中去,然后才被写到磁盘上。但是对于这种标准的访问文件的方式来说,在数据被写到页缓存中的时候,write() 系统调用就算执行完成,并不会等数据完全写入到磁盘上。Linux 在这里采用的是我们前边提到的延迟写机制( deferred writes )
-
文件读写中涉及的磁盘缓冲区与其手动flush问题
IO越少,效率越高
-
操作系统内核的划分
待补充
-
信号与中断
处理时机不同
- 中断在内核态处理
- 信号在由内核态返回用户态后进行处理,在进程表的表项中有一个软中断信号域,该域中每一位对应一个信号
详细内容请参考进程通信-信号
-
跨进程通信,消费者模式的阻塞式如何实现的
待补充
-
mmap什么作用
系统调用使得进程之间通过映射同一个普通文件实现共享内存,普通文件被映射到进程地址空间后,进程可以像访问普通内存一样对文件进行访问,不必再调用read(),write()等操作
-
做了几次拷贝操作?
-
虚拟内存的作用是啥
程序不用关心绝对地址,只需要关心虚拟地址,操作系统会协助做地址映射
-
什么是协程,协程和线程的区别
7 Linux
-
统计一个文件的行数
wc -l -
Linux线程同步的方式都有哪些(对于与Java线程同步也是一样的)
互斥锁、信号量、条件变量
-
Linux下怎么查看进程的CPU占用、IO占用、内存占用
ps aux
top
netstat -
Linux Signal有什么作用
进程间通信,进程通信-信号
-
如果有一个服务要求不能启动两次,用什么机制来做
说写bash每次启动前检查(ps配合grep)
纯C程序怎么写 -
找出一篇文章中某个单词的出现次
grep -o word a.txt | wc -l -
Linux利用哪些命令,查找哪里出了问题(例如io密集任务,cpu过度)
iotop
top
ps aux -
Linux下IO模型有几种,各自的含义是什么
Java-NIO
-
异步IO的详细解释
-
I/O复用的水平触发与边缘触发
水平触发
- 对于读操作:只要缓冲内容不为空,LT模式返回读就绪
- 对于写操作:只要缓冲区还不满,LT模式会返回写就绪
边缘触发
- 对于读操作
- 当缓冲区由不可读变为可读的时候,即缓冲区由空变为不空的时候
- 当有新数据到达时,即缓冲区中的待读数据变多的时候
- 当缓冲区有数据可读,且应用进程对相应的描述符进行EPOLL_CTL_MOD 修改EPOLLIN事件时
- 对于写操作
- 当缓冲区由不可写变为可写时
- 当有旧数据被发送走,即缓冲区中的内容变少的时候
- 当缓冲区有空间可写,且应用进程对相应的描述符进行EPOLL_CTL_MOD 修改EPOLLOUT事件时
-
Linux零拷贝的了解
http://www.jianshu.com/p/fad3339e3448
零拷贝主要的任务就是避免CPU将数据从一块存储拷贝到另外一块存储,主要就是利用各种零拷贝技术,避免让CPU做大量的数据拷贝任务,减少不必要的拷贝,或者让别的组件来做这一类简单的数据传输任务,让CPU解脱出来专注于别的任务。这样就可以让系统资源的利用更加有效。 -
Direct I/O 和其与异步I/O的区别
http://blog.csdn.net/wdjhzw/article/details/39402035
Direct I/O相对于缓存IO(Buffer I/O)而言,减小了数据拷贝(从用户空间到内核空间)的次数
凡是通过直接 I/O 方式进行数据传输,数据均直接在用户地址空间的缓冲区和磁盘之间直接进行传输,完全不需要页缓存的支持 -
Linux内核如何调用Direct I/O
待补充
-
常用的Linux命令介绍
显示目录和文件的命令
- ls
- dir
- du
修改目录、文件权限、属性和属主的命令
- chmod
- chown
- chgrp
- chattr
- lsattr
创建和删除目录的命令
- mkdir
- rmdir
- rm
创建和删除,重命名,复制文件的命令
- touch
- vi/vim
- rm
- mv
- cp
显示文件内容的命令
- cat
- more
- less
- head
- tail
- tail -f
查找命令
- find
- whereis
- which
- locate
- grep
关机和重启计算机的命令
- shutdown
- poweroff
压缩和打包命令
- tar
用户操作命令
- su
- sudo
改变目录和查看当前目录命令
- cd
- pwd
-
对awk与sed的了解
awk将一行按分隔符进行拆分,并填入$1/$2…变量中
seq按行进行处理 -
对文件系统的了解
Linux-File-System
-
hard link与symbolic link的区别
目录的block存放的是文件名与inode的关联记录
hard link:hard link只是在某个目录下新建一条文件名连接到某inode号码的关联记录而已。因此两个文件名会连接到同一个inode号码。ls -l查看的连接数就是多少个文件名连接到这个inode号码的意思
symbolic link:创建一个独立的文件,这个文件会让数据的读取指向它连接的文件名。注意这里连接到文件名而不是inode号码 -
cgroup实现原理
Linux-Mechanism
8 分布式相关
-
说说分布式计算
-
分布式存储
-
Zookeeper
-
Zookeeper watch机制
-
Zookeeper的用途
Zookeeper是注册中心,提供目录和节点服务,watch机制
http://blog.csdn.net/tycoon1988/article/details/38866395 -
Zookeeper选举原理
ZAB协议,paxox算法Protocol-Paxos
-
redis/Zookeeper节点宕机如何处理
利用一致性协议进行一次master的选举
-
Dubbo和Zookeeper的联系与区别
-
Dubbo的底层实现原理和机制
https://zhidao.baidu.com/question/1951046178708452068.html
dubbo的负载均衡已经是服务层面的了,和nginx的负载均衡还在http请求层面完全不同。至于二者哪个优秀,当然没办法直接比较
涉及到负载均衡就涉及到你的业务,根据业务来选择才是最适合的
dubbo具备了server注册,发现、路由、负载均衡的功能,在所有实现了这些功能的服务治理组件中,个人觉得dubbo还是略微笨重了,因为它本身是按照j2EE范畴所制定的中规中矩的服务治理框架
dubbo在服务发现这个地方做的更像一个dns(个人感觉),一个消费者需要知道哪里有这么一个服务,dubbo告诉他,然后他自己去调用
而nginx在具备了以上功能,还有两个最主要的功能是,1,维持尽可能多的连接。2,把每个连接的具体服务需求pass到真正的worker上
但是这两个功能,dubbo做不到第一个
所以,结合你自己的业务来选择用什么,nginx和dubbo在使用上说白了就是一个先后的关系而已(当然也是我个人感觉)
http://dubbo.io/developer-guide/框架设计.html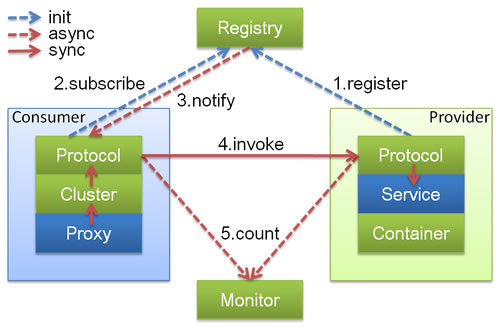
-
Dubbo的服务请求失败怎么处理
dubbo启动时默认有重试机制和超时机制
超时机制的规则是如果在一定的时间内,provider没有返回,则认为本次调用失败
重试机制在出现调用失败时,会再次调用。如果在配置的调用次数内都失败,则认为此次请求异常,抛出异常
http://www.cnblogs.com/binyue/p/5380322.html -
消息中间件
-
分布式事务
-
分布式锁
-
接口的幂等性的概念
-
数据表垂直拆分/水平拆分
垂直拆分,将一张表中的不同类别的数据分别放到不同的表中去
水平拆分,将一张表的不同数据项放到两台机器上 -
数据库分库分表策略
DBMS-Subtable-Strategy
-
分库分表后的全表查询问题
-
负载均衡算法
-
分布式集群下的唯一序列号
- 数据库自增id
- uuid(MacAddress+timeStamp)
-
消息队列(Message Queue)
待补充
-
用过哪些MQ,怎么用的,和其他mq比较有什么优缺点,MQ的连接是线程安全的吗
待补充
-
MQ系统的数据如何保证不丢失
-
描述一个服务从发布到被消费的详细过程
待补充
-
分布式系统怎么做服务治理
-
用到的rpc框架
待补充
-
mq的推模式和拉模式各有什么优势
推模式,实时性更高;拉模式,批量拉取,实时性要求不高,吞吐量大
-
raft和paxos的区别
- raft弱化了选主过程中的强一致性,可能会先后选出多个leader,但是这些leader的term(类似于paxos中的proposal-id)是不同的,成员可以根据term的大小关系选出最终的leader,也就是保证了最终只会有一个leader
- Raft协议强调日志的连续性,multi-paxos则允许日志有空洞:协议的最终目的其实是为了维护数据的最终一致性,raft协议能够保证选出的leader一定包含所有已提交的日志(会将term最大且日志序号最大的选为leader);而paxos无法保证,因此需要有额外的补偿流程来恢复那些已经提交,但是又未被leader记录的日志。根本原因就在于:raft在选主时会兼顾数据的完整性,而paxos不会
9 算法&数据结构
-
贪心的计算思想是什么?其弊端是什么?
局部最优解就是全局最优解
-
动态规划的原理与本质
问题的拆分+递推表达式
全局最优解依赖于局部最优解
https://www.zhihu.com/question/23995189 -
LRU的实现
hash+双向链表
-
单源最短路径
Algorithm-SSSP
-
BTree
-
大根堆
就是最大堆
-
单链表排序
归并,fast/slow指针
leetcode 148 -
除了平衡二叉树这种结构还知道别的支持lgn插入的结构吗?
redis里的skip list
-
无序数组的最长递增子序列
回溯
-
并查集
DataStructure-Disjoint-Set
-
海量url去重类问题
DataStructure-Bloom-Filter
-
海量整数去重问题
bitmap
布隆过滤器 -
Bloom过滤器处理大规模问题时的持久化,包括内存大小受限、磁盘换入换出问题
Bloom过滤器无法100%准确,优点就是占用的内存非常小
http://blog.csdn.net/xiaxzhou/article/details/75193936 -
海量url中找到出现次数最多的10个url
待补充
map-reduce -
二叉树遍历
Algorithm-Tree
-
经典排序总结
Algorithm-Sort
-
快速排序
SourceAnalysis-DualPivotQuickSort
-
hash算法的有哪几种,优缺点,使用场景
链表法,Java中Map的实现都用这个
开放寻址法,空间利用率不高,对hash函数的性能要求非常高 -
什么是一致性hash
- Consistency-Hash
- 普通hash --> 一致性hash,本质上就是固定模的长度,在增加或删除节点后hash求模的值不变
-
paxos算法
Protocol-Paxos
-
二叉树的最大搜索子树
DFS就可以貌似
-
01背包问题的详细解释,空间复杂度的优化
Algorithm-SSSP中的Foly算法中有提到01背包的优化
-
字典树与其在统计词频上的应用
待补充
-
字典树构造及其优化与应用
-
红黑树
DataStructure-RB-Tree
-
实现bitmap数据结构,包括数据的存储与插入方式
要确定
数据与bit位的映射关系 -
字符串hash成状态位的具体实现方式
下面给出Java中的实现
1
2
3
4
5
6
7
8
9
10
11
12
13public int hashCode() {
//hash就是hash值,最开始是0,延迟初始化
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
} -
线性时间选择
partition
-
hash函数如何保证冲突最小
hash函数本身的性能
计算hash值的时候,尽量利用数据本身的所有特征 -
hash算法有哪几种
- md5
- sha
-
银行家算法
Algorithm-Bank
-
解决哲学家进餐问题
避免死锁
http://blog.sina.com.cn/s/blog_e33e27b70102w68z.html
当其中一个哲学家两边的筷子都可用时,才会拿起筷子,否则不会拿起筷子,拿筷子这个动作需要是原子的,比如CAS -
环形公路上加油站算法问题
leetcode 134
保留欠下的所有油,最后剩下的油一定要大于这个欠下的油
当剩余油小于0,更换起始位置 -
枚举给定数组中的所有非递减子序列
回溯,位置i的元素,选择或者不选
-
图的邻接矩阵和邻接表的表示,邻接表的数据结构
邻接表
List<Node>[] graph,其中graph[i]代表节点i的邻接表
邻接矩阵boolean [][] graph,其中graph[i][j]代表节点i与节点j之间是否有边,注意是有向的。无向怎么办?graph[i][j] == graph[j][i] -
给定二叉树,假设相连接的两结点间距离为1,求所有结点中距离其他所有结点距离和最小的结点
待补充
-
给定数组,快速求出所有数右边第一个比其大的数
栈
-
字符串匹配KMP算法
复杂度O(M+N)
-
无锁编程解决单生产者多消费者问题和多生产者多消费者问题
循环+CAS
-
快速排序的稳定化算法
3-way-quicksort稍微改进一下就是稳定的了
如果pivot取得是最后一个元素,那么将pivot放置在center part(与pivot相同)的尾部即可 -
平面上百万个点,设计数据结构求每个点最近的k个点(范围搜索问题)
http://blog.csdn.net/liuqiyao_01/article/details/8478719
http://blog.csdn.net/sunmenggmail/article/details/8122743 -
DOM树的实现模拟
待补充
-
NFA(Nondeterministic Finite Automaton)、DFA(Deterministic Finite Automaton)的过程与正则的区别
http://blog.csdn.net/chinamming/article/details/17166577
http://blog.csdn.net/kingoverthecloud/article/details/41621557 -
实现一个栈,并且能够快速返回栈中最大元素。怎么优化空间
两个栈,一个正常。另一个实现如下:当新元素比栈顶大时,压入新元素,否则复制栈顶元素并压入
-
判断两个链表是否相交,并求交点
可以转化为链表是否有环
-
求最大公约数
1
2
3
4
5
6
7
8
9
10int greatestCommonDivisor(int a, int b) {
int c;
c = a % b;
while (c != 0) {
a = b;
b = c;
c = a % b;
}
return b;
} -
100个硬币,A和B两个人,每人每次只能拿1~6个硬币,谁拿到最后一个谁赢,A先拿,A能保证必胜吗?
1-6:A胜利
7:B胜利
8-13:A胜利(只要剩下的是7即可)
因此100不是7的倍数,A胜利。如何操作:A每次拿完后,剩下的硬币数量只要是7的倍数即可 -
给定一颗二叉树和一个整数 sum,求累加和为 sum 的最长路径长度。路径是指从某个节点往下,每次最多选择一个孩子节点或者不选所形成的节点链。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* }
*/
public class Solution {
private int maxLen = 0;
/**
* @param root TreeNode类 the root
* @param target int整型 the target
* @return int整型
*/
public int findLengthofSum(TreeNode root, int sum) {
List<TreeNode> pathNodes = new ArrayList<>();
findLengthofSum(root, pathNodes, sum);
return maxLen;
}
private void findLengthofSum(TreeNode root, List<TreeNode> pathNodes, int sum) {
if (root == null) {
return;
}
pathNodes.add(root);
int curSum = 0;
int len = 0;
for (int i = pathNodes.size() - 1; i >= 0; i--) {
len++;
curSum += pathNodes.get(i).val;
if (curSum == sum) {
maxLen = Math.max(maxLen, len);
}
}
findLengthofSum(root.left, pathNodes, sum);
findLengthofSum(root.right, pathNodes, sum);
pathNodes.remove(pathNodes.size() - 1);
}
} -
skip list
以空间复杂度换时间复杂度
-
1000w个数据,top k问题
最小堆,当前元素若大于堆顶元素,那么将堆顶出堆,然后将当前元素入堆
-
hash算法的实现原理
-
两个球,100个楼层,如何最快的找到临界楼层(扔球会碎)
10 数据库
-
- 第一范式:确保每列保持原子性
- 第二范式:确保表中的每列都和主键相关(每一列都与主键相关,而不能只与主键的某一部分相关,主要针对的是联合主键这种情况)
- 第三范式:确保每列都和主键列直接相关,而不是间接相关(订单和客户信息如果存在一张表里,那么客户的联系方式和订单id其实是间接相关)
-
数据库触发器是什么
其是一种特殊的存储过程。一般的存储过程是通过存储过程名直接调用,而触发器主要是通过事件(增、删、改)进行触发而被执行的。其在表中数据发生变化时自动强制执行。常见的触发器有两种:after(for)、instead of,用于insert、update、delete事件
- after(for) 表示执行代码后,执行触发器
- instead of 表示执行代码前,用已经写好的触发器代替你的操作
-
MySQL InnoDB存储的文件结构
http://www.cnblogs.com/benshan/archive/2013/01/08/2851714.html
-
数据库引擎
DBMS-MySQL-Engine
-
索引树是如何维护的
B+树,不同的引擎有不同的方式
DBMS-MySQL-Engine -
创建索引时的注意事项
- 表的主键、外键必须有索引
- 数据量超过300的表应该有索引
- 经常与其他表进行连接的表,在连接字段上应该建立索引
- 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引
- 索引应该建在选择性高的字段上
- 索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引
- 正确选择复合索引中的主列字段,一般是选择性较好的字段
- 复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引
- 如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引
- 如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段
- 如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引
- 频繁进行数据操作的表,不要建立太多的索引
- 删除无用的索引,避免对执行计划造成负面影响
- 复合索引的建立需要进行仔细分析,尽量考虑用单字段索引代替
-
数据库视图和索引的区别
视图的作用:
- 视图能够简化用户的操作。利用视图可以为用户集中数据,简化用户数据的查询和处理。有时用户所需要的数据在多张表里,定义视图可以让他们集中在一起,从而方便查询和处理
- 视图能够使用户以多种角度看待同一数据。通过给不同的用户定义不同的视图,能够让不同的用户以不同的角度来共享视图
- 视图对重构数据库提供了一定程度的逻辑独立性
- 能够对机密数据提供安全保护
- 适当的使用视图可以更清晰的表达查询
1
2
3
4
5
6
7
8
9
10
11CREATE VIEW view_name
AS
SELECT column1,column2,...columnk
FROM table_name
WHERE condition;
CREATE VIEW user_view_1
AS
SELECT first_name, last_name
FROM crm_user
WHERE sex = 0;索引:实质上得是单独的,物理的数据库结构,他是表中的一个列或者多个列的值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单
-
数据库自增主键可能的问题
http://www.cnblogs.com/zhoujinyi/p/3433823.html
自增主键会产生表锁(插入语句完成后释放锁而不是事务结束后释放锁),大量并发插入时引起阻塞
自增主键不连续。版本5.1.22之后,插入前会通过语句分析得出插入数量,然后一次性分配足够的id,只有分配的过程是同步的,而分配之后的插入是可以并发执行的 -
MySQL的几种优化
-
数据库索引的作用
快速查找
CREATE INDEX index_name ON table_name(column_name)
CREATE INDEX index_name ON table_name(column_name1, column_name2)
CREATE UNIQUE INDEX index_name ON table_name(column_name) -
MySQL索引为什么使用B+树
每个节点的数据更多,降低树的深度提高查询效率,并且减少IO次数
范围查找会比较快捷
查询效率稳定,查询路径相同 -
数据库锁表的相关处理
待补充
-
20万条数据,存在XML里面,如果要保存到数据库里,注意一些什么
待补充
-
索引失效场景
http://blog.csdn.net/zmx729618/article/details/52701370
- WHERE子句查询条件有不等号
- 查询条件使用了函数
- JOIN主键外键数据类型不同
- 利用LIKE或者REGEXP时第一个字符是通配符
- ORDER BY条件不是查询条件表达式
- 某个数据列包含了大量的重复
-
高并发下如何做到安全的修改同一行数据,乐观锁和悲观锁是什么,INNODB的行级锁有哪2种,解释其含义
悲观锁(Pessimistic Lock),顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁
乐观锁(Optimistic Lock),顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库如果提供类似于write_condition机制的其实都是提供的乐观锁
两种锁各有优缺点,不可认为一种好于另一种,像乐观锁适用于写比较少的情况下,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果经常产生冲突,上层应用会不断的进行retry,这样反倒是降低了性能,所以这种情况下用悲观锁就比较合适
http://blog.csdn.net/hongchangfirst/article/details/26004335 -
共享锁、排他锁
共享锁(S锁):如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据
排他锁(X锁):如果事务T对数据A加上排他锁后,则其他事务不能再对A加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据
共享锁下其它用户可以并发读取,查询数据。但不能修改,增加,删除数据。资源共享 -
数据库会死锁吗,举一个死锁的例子,MySQL怎么解决死锁
虽然进程在运行过程中,可能发生死锁,但死锁的发生也必须具备一定的条件,死锁的发生必须具备以下四个必要条件
- 互斥条件:指进程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放
- 请求和保持条件:指进程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求进程阻塞,但又对自己已获得的其它资源保持不放
- 不剥夺条件:指进程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放
- 环路等待条件:指在发生死锁时,必然存在一个进程——资源的环形链,即进程集合{P0,P1,P2,…,Pn}中的P0正在等待一个P1占用的资源;P1正在等待P2占用的资源,…,Pn正在等待已被P0占用的资源
-
数据库中join的类型与区别
left jion
right join
inner join
outer join -
数据库事务的ACID
A:Atomicity
C:Consistency
I:Isolation
D:Durability -
MySQL默认隔离级别是什么,为什么
read committed,高并发
-
MySQL数据库事务的隔离级别
DBMS-Isolation
-
乐观锁
乐观锁
-
怎么知道SELECT是否用到了索引
利用
EXPLAIN + SQL进行分析 -
两列是否能做联合主键
可以
-
联合索引是如何实现的,和单索引的区别是啥
单索引的话每个中间节点存的就是该字段边界值,叶节点存的是值以及主键id
联合索引每个中间节点存的就是所有索引相关字段的边界值(无非比较是个复合比较),叶节点比中间节点多了主键id -
迁移数据库的基本操作
t0:开启双写,通过注解,在切面中完成双写,要区分insert(新库的主键id)、update和delete
t1:存量数据迁移
t2:数据一致性校验,以老库为准更新
t3:读切到新库
11 Redis&缓存相关
-
- redis是基于内存的操作,cpu不是瓶颈
- 单线程的好处:简单
-
Redis的并发竞争问题如何解决,了解Redis事务的CAS操作吗
Redis-Interview-Summary
-
缓存机器增删如何对系统影响最小,一致性哈希的实现
Consistency-Hash
-
Redis持久化的几种方式,优缺点是什么,怎么实现的
Redis-Persistence-Mechanism
-
Redis的缓存失效策略
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
-
缓存穿透的解决办法
- Bloom Filter
- 缓存该不存在的键(其值是一个约定好的值),其过期时间较短,并且应用端能够处理这个缓存值
-
- presharding,假设集群最大容量是50台机器,而最开始只有5台,那可以在5台机器上,每台机器跑10个副本,当需要扩容的时候,进行数据拷贝即可(通过主从配置)。同时节点宕机也不会带来更大的问题
- 集群中的每个节点再加主从
-
用Redis和任意语言实现一段恶意登录保护的代码,限制1小时内每用户Id最多只能登录5次
待补充
-
Redis的数据淘汰策略
ttl
lru
randum
缓存失效策略和数据淘汰策略类似,只不过缓存失效有已设置过期时间和所有这两个区别,因此有6种,而数据淘汰策略只有3种 -
常见的缓存策略有哪些
LRU
LFU
RANDOM
12 网络相关
-
介绍你知道的传输层协议
TCP、UDP
-
HTTP和HTTPS的区别
- 被篡改
- 被伪装
- 被窃听
-
HTTPS的建立过程
发送客户端支持的加密协议以及版本,例如SSL,TLS
服务器端从中筛选合适的加密协议
服务器端返回证书,证书中有公钥
客户端使用根证书验证证书合法性
客户端生成对称密钥,通过证书中的公钥加密,发送到服务端
服务器端使用私钥解密,获取对称密钥,使用对称密钥加密数据
客户端解密数据,SSL开始通信 -
TIME_WAIT状态什么情况下会产生,以及它有什么用主动关闭的一方在收到FIN之后会进入
TIME_WAIT状态
有两个作用(记A为主动关闭方,B为被动关闭方)- 如果B没有收到A发送的ACK信号,那么B会重新发送FIN。如果A处于Closed状态,那么A在接收到这个重发的FIN后会响应RST而不是ACK。这会导致B将其判断为错误
- 避免上次一连接的数据包在新连接的周期内到达,可以认为
TIME_WAIT之后,所有本次连接的数据包都消逝了,不会再重新出现了
-
HTTP请求详细过程
-
一个IP包大概是多大呢,有限制没有?
IP数据包的最大长度是64K字节(65535),因为在IP包头中用2个字节描述报文长度,2个字节所能表达的最大数字就是65535

-
什么情况下会考虑UDP、什么情况下会考虑TCP
TCP一般用于文件传输(FTP、HTTP对数据准确性要求高,速度可以相对慢),发送或接收邮件(POP、IMAP、SMTP对数据准确性要求高,非紧急应用),远程登录(TELNET、SSH对数据准确性有一定要求,有连接的概念)等等
UDP一般用于即时通信(QQ聊天 对数据准确性和丢包要求比较低,但速度必须快),在线视频(RTSP 速度一定要快,保证视频连续,但是偶尔花了一个图像帧,人们还是能接受的),网络语音电话(VoIP 语音数据包一般比较小,需要高速发送,偶尔断音或串音也没有问题)等等 -
如果要进行可靠的传输,又想要用UDP,你觉得可行吗
简单来讲,要使用UDP来构建可靠的面向连接的数据传输,就要实现类似于TCP协议的超时重传,有序接受,应答确认,滑动窗口流量控制等机制,等于说要在传输层的上一层(或者直接在应用层)实现TCP协议的可靠数据传输机制,比如使用UDP数据包+序列号,UDP数据包+时间戳等方法,在服务器端进行应答确认机制,这样就会保证不可靠的UDP协议进行可靠的数据传输
QQ的传输协议就是UDP,因为效率更高,但是UDP本身是不可靠的,因此利用应用层的一些重传机制,消息可靠性协议来做辅助。例如A->server,如果消息成功到达server,那么server会给A发送一个回执,当且仅当A收到回执,A才能认为消息已经送达至server -
HTTP请求在服务器应答、数据传完之后会怎么样一个操作呢?
服务端主动关闭连接,至于为什么,参考:https://www.zhihu.com/question/24338653
-
select和epoll的区别
Java-NIO
select描述符个数限制是多少?(1024),能不能改怎么改等等(不能,想改得编译内核)
-
epoll为什么更快
epoll的高效就在于,当我们调用
epoll_ctl往里塞入百万个句柄时,epoll_wait仍然可以飞快的返回,并有效的将发生事件的句柄给我们用户。这是由于我们在调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。所以,epoll_wait非常高效
http://blog.csdn.net/wangfeng2500/article/details/9127421 -
介绍一下TCP三次握手/四次挥手
三次握手、四次挥手详见TCP-IP详解-读书笔记
流量控制是点到点的通信量的控制 -
TCP流量控制
流量控制是点到点的通信量的控制
流量控制是通过滑动窗口实现的,发送窗口在连接建立时由双方商定。但在通信的过程中,接收端可根据自己的资源情况,随时动态地调整对方的发送窗口上限值(可增大或减小)
我们可以把窗口理解为缓冲区(但是有些窗口和缓冲区又不太一样)。如果没有这些"窗口",那么TCP没发送一段数据后都必须等到接收端确认后才能发送下一段数据,这样做的话TCP传输的效率实在是太低了。解决的办法就是在发送端等待确认的时候继续发送数据,假设发送到第X个数据段是收到接收端的确认信息,如果X在可接受的范围内那么这样做也是可接受的。这就是窗口(缓冲区)引入的缘由
-
TCP拥塞控制
TCP拥塞控制是一个全局性的控制,控制整个网络的通畅程度
快开始:拥塞窗口长度cwnd<ssthresh时,采用慢开始,每次成功通信后将窗口加倍
拥塞避免:拥塞窗口长度cwnd>ssthresh时,采用拥塞避免,每次成功通信后将窗口加1
发生网络拥塞时:就把慢开始门限设置为出现拥塞时的发送窗口大小的一半。然后把拥塞窗口设置为1,执行慢开始算法
快重传:快重传算法规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期
快恢复:当发送方连续收到三个重复确认时,就执行"乘法减小"算法,把ssthresh门限减半。但是接下去并不执行慢开始算法。考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh的大小,然后执行拥塞避免算法
http://blog.csdn.net/sinat_21112393/article/details/50810053 -
为什么TCP建立连接需要三次握手,关闭连接需要4次挥手
TCP连接时全双工的,在建立连接时,两个方向可以同时建立,而在关闭连接时,两个方向可以不同时关闭,因此会多一次交互(被动关闭方的
CLOSE_WAIT) -
TCP粘包问题
TCP粘包是指发送方发送的若干包数据到接收方接收时粘成一包,从接收缓冲区看,后一包数据的头紧接着前一包数据的尾
原因1:使用了Nagle算法- 上一个分组得到确认,才会发送下一个分组
- 收集多个小分组,在一个确认到来时一起发送
原因2:TCP接收到分组时,并不会立刻送至应用层处理,或者说,应用层并不一定会立即处理;实际上,TCP将收到的分组保存至接收缓存里,然后应用程序主动从缓存里读收到的分组。这样一来,如果TCP接收分组的速度大于应用程序读分组的速度,多个包就会被存至缓存,应用程序读时,就会读到多个首尾相接粘到一起的包
解决方法- 关闭Nagle算法
- 应用层采用格式化数据(增加某个特殊字符作为分隔符什么的)或者增加发送长度的方式
-
TCP是面向流的面向连接的对吧,解释一下什么叫连接
意味着两个使用TCP的应用(通常是一个客户和一个服务器)在彼此交换数据之前必须先建立一个TCP连接。在一个TCP连接中,仅有两方进行彼此通信。广播和多播不能用于TCP
-
TCP报文
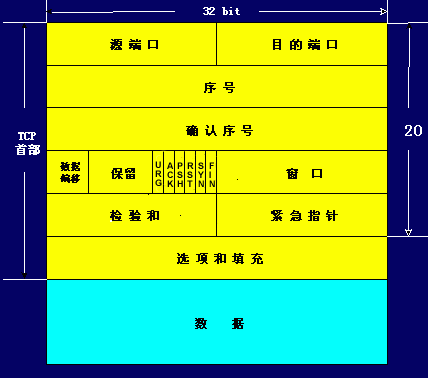
http://www.360doc.com/content/12/1218/10/3405077_254718387.shtml
-
TCP/IP如何保证可靠性,数据包有哪些数据组成
以下是TCP提供可靠性的方式:详细内容参考TCP-IP详解-读书笔记
- 将数据截断为合理的长度
- 超时重发
- 对于收到的请求,给出确认响应
- 校验出包有错,丢弃报文段,不给出响应,TCP发送数据端,超时时会重发数据
- 对失序数据进行重新排序,然后才交给应用层
- 对于重复数据,能够丢弃重复数据
- TCP可以进行流量控制,防止较快主机致使较慢主机的缓冲区溢出
各层数据包关系
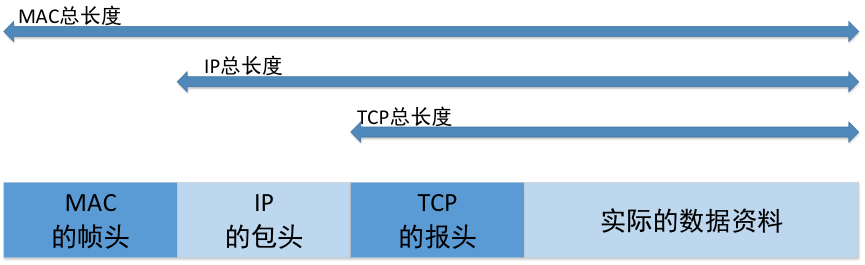
TCP数据包
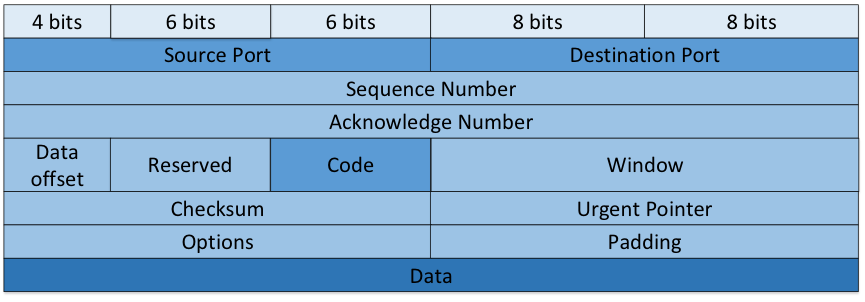
DUP数据包
-
accept是在三次握手的哪个阶段?
accept指的是应用层的accept方法,用于获取一个Socket对象
三次握手后,http://blog.csdn.net/wukui1008/article/details/7691499 -
假如三次握手后我没有调accept,那么你能感知到我是否调用了accept吗?
(不能,但是我能朝你发消息)能发成功吗?(可以的吧,我发过去的消息就是被操作系统缓存在那个buffer里)那你可以一直发吗?(那不能一直发,如果buffer满了之后,那你那边控制的那个叫receive wnd就减成0了)receive wnd是啥?(接收方维护的一个变量,用来做流量控制的)
-
HTTP的状态码知道哪些
1XX、2XX、3XX、4XX、5XX
-
两台电脑用一根网线直连,发现带宽总是跑不满,会是什么原因?
待补充
-
http1.0和http1.1有什么区别
keep-alive
http://www.cnblogs.com/shijingxiang/articles/4434643.html
http://www.cnblogs.com/gofighting/p/5421890.html -
长连接与短连接
-
长连接的实现
在HTTP1.0和HTTP1.1协议中都有对长连接的支持。其中HTTP1.0需要在request的请求头中增加"Connection:keep-alive" header才能够支持,而HTTP1.1默认支持
http1.0请求与服务端的交互过程:- 客户端发出带有包含一个header:"Connection: keep-alive"的请求
- 服务端接收到这个请求后,根据http1.0和"Connection: keep-alive"判断出这是一个长连接,就会在response的header中也增加"Connection: keep-alive",同是不会关闭已建立的tcp连接
- 客户端收到服务端的response后,发现其中包含"Connection: keep-alive",就认为是一个长连接,不关闭这个连接。并用该连接再发送request
http1.1请求与服务端的交互过程:
- 客户端发出http1.1的请求
- 服务端收到http1.1后就认为这是一个长连接,会在返回的response设置Connection: keep-alive,同时不会关闭已建立的连接
- 客户端收到服务端的response后,发现其中包含"Connection: keep-alive",就认为是一个长连接,不关闭这个连接。并用该连接再发送request
-
Http请求get和post的区别以及数据包格式
-
关闭连接时,出现TIMEWAIT过多是由什么原因引起,是出现在主动断开方还是被动断开方
待补充
-
网络层分片的原因与具体实现
待补充
-
网页解析的过程与实现方法
待补充
-
HTTP协议与TCP联系
HTTP是应用层协议,而TCP是传输层协议
HTTP利用的是TCP协议进行数据的传输,Client发送请求前建立TCP连接,Server响应后关闭连接 -
Unicode/UTF-8/UTF-16的区别
简单来说:
- Unicode 是「字符集」
- UTF-8/UTF-16是「编码规则」
其中:
- 字符集:为每一个「字符」分配一个唯一的 ID(学名为码位 / 码点 / Code Point)
- 编码规则:将「码位」转换为字节序列的规则(编码/解码 可以理解为 加密/解密 的过程)
UTF-8:是一套以8位为一个编码单位的可变长编码。会将一个码位编码为1到4个字节
UTF-16:每个字符两个字节,即16位 -
Session和Cookie
-
OSI七层协议
- 物理层
- 链路层
- 网络层
- 传输层
- 会话层
- 表示层
- 应用层
-
数字证书
-
进程最多可以打开多少个tcp连接受到哪些因素的影响
- CPU
- 内存,每个tcp连接需要缓冲区
- 端口号资源
- 文件描述符资源
- 线程资源,管理tcp连接需要线程,即便是io多路复用,也需要线程
13 场景设计
-
秒杀场景
-
有一堆音频文件需要下载,有多台机器,如何实现这个任务
一个中心节点存储下载状态,其他机器请求任务并去执行
中心节点要持久化存储,宕机后能够恢复
下载任务执行成功后需要通知中心节点,其他任何情况都视为失败(比如下载失败、下载超时,机器宕机) -
朋友圈
业务模型,存储,写扩散
服务架构,发消息,mq,削峰填谷 -
有一个集合有1亿条记录,其中每条记录长度在100~1000Bytes之间。假设有一台机器,内存100M,磁盘500G,请设计一个查询系统,每次用户给定一条记录,能够快速确认该记录是否在集合中
内存:bitmap
内存:LRU
磁盘:索引
14 其他
-
maven解决依赖冲突,快照版(SNAPSHOT)和发行版(RELEASE)的区别
SNAPSHOT不是一个特定的版本,而是一系列的版本的集合,HEAD指向最新的快照。客户端通过重新构建就能够拿到最新的快照
RELEASE是一个特定的版本,准确定位
http://www.cnblogs.com/wuchanming/p/5484091.html -
maven的scope标签指的是什么,scope中的test指的是什么
待补充
-
Java web过滤器的生命周期
待补充
-
怎样搭建服务器网络
待补充
-
实际场景问题,海量登录日志如何排序和处理SQL操作,主要是索引和聚合函数的应用
待补充
-
实际场景问题解决,典型的TOP K问题
用堆来解决
-
线上bug处理流程
待补充
-
如何从线上日志发现问题
待补充
-
设计一个秒杀系统,30分钟没付款就自动关闭交易(并发会很高)
待补充
-
请列出你所了解的性能测试工具
Visual vm
-
后台系统怎么防止请求重复提交?
待补充
-
mock测试框架
待补充
-
tomcat结构,类加载器流程
待补充
-
对云计算网络的了解
待补充
-
对路由协议的了解与介绍
待补充