阅读更多
1 ClickHouse
类型:OLAP
特性:
- 列存
- 压缩性能高。由于列存,数据同质化,便于压缩,较易获得较高的压缩比
- 多核并行处理
MPP架构- 支持
ANSI SQL标准 - 向量化。数据按列组织,具有较好的空间局部性,对
Cache友好,向量化效果好 - 支持数据实时写入
- 索引
- 支持在线查询
- 不支持事务
架构:
主页:
博客&文章:
2 ByteHouse
Forked from ClickHouse
类型:OLAP
主页:
3 Delta
类型:Data Lake
特性:
- 基于
Spark上的ACID事务:可序列化的隔离级别确保读者永远不会看到不一致的数据 - 可扩展的元数据处理:利用
Spark分布式处理能力轻松处理具有数十亿文件的PB级表的所有元数据 - 流和批处理统一
Schema enforcement:自动处理Schema的变化,以防止在变更过程冲插入异常记录Time travel:数据版本控制支持回滚、完整的历史审计跟踪Upserts和Deletes:支持合并、更新和删除操作,以启用复杂的用例
架构:
主页:
4 Doris
类型:OLAP
特性:
架构:
主页:
5 Druid
类型:OLAP
特性:
- 列存储架构
- 可扩展的分布式架构
MPP架构- 支持实时和批处理
- 具有自动异常恢复、自动负载均衡等能力,运维简单
- 云原生
- 使用
bitmap索引来加速数据过滤 - 支持数据分区,默认以时间分区
- 支持近似算法,比如近似计算
count-discount等,用于应对一些正确性不敏感,但是时间敏感的场景 - 在查询数据时进行自动汇总,以提高效率
架构:
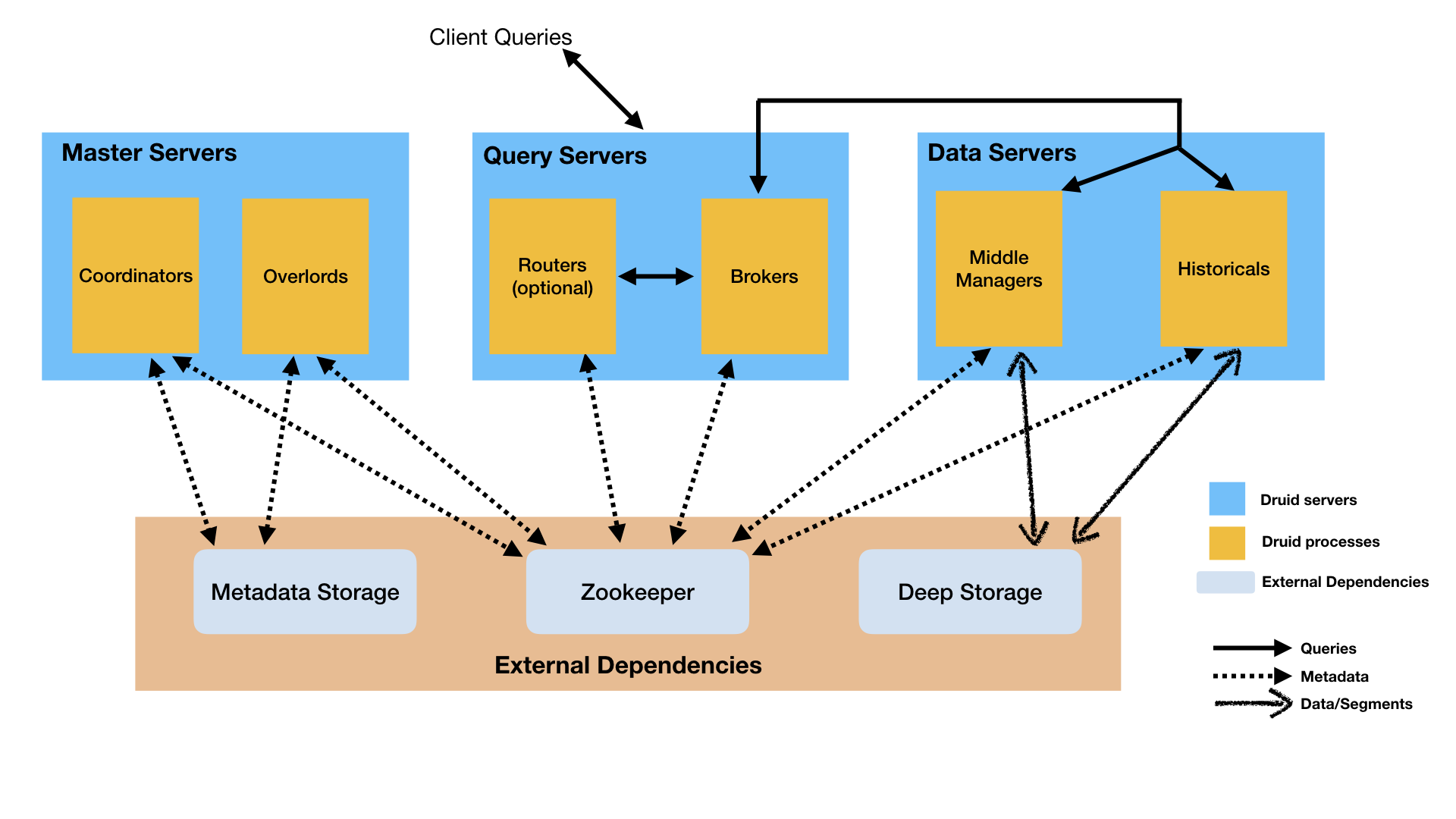
主页:
6 DuckDB
类型:OLAP
特性:
- High Speed
- Columnar Storage
- Compatibility
- Embeddable
- Low Memory Footprint
- Analytical Capabilities
- Open Source
架构:
主页:
博客&文章:
7 Gbase
类型:OLAP
特性:
架构:
主页:
8 GreenPlum
类型:OLAP
特性:
- 先进的基于开销的优化器(
Cost-Based Optimizer, CBO) MPP架构- 基于
PostgreSQL 9.4 Append-optimized storage- 列存
- 执行引擎采用火山模型(
Volcano-style)
架构:
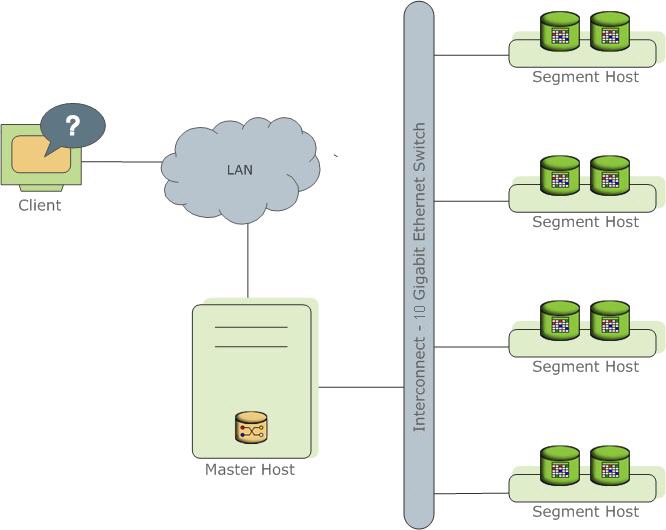
主页:
9 Hadoop
包含三大组件:
HDFS:存储MapReduce:计算YARN:调度
类型:Framework
特性:
架构:
主页:
10 Hawq
类型:OLAP
特性:
- 支持
SQL-92、SQL-99、SQL-2003、OLAP extension - 比
Hadoop SQL engines快 - 优秀的并行优化器
- 完整的事务支持
- 基于
UDP的流引擎 - 弹性执行引擎
- 支持多级分区和基于列表/范围的分区表
- 支持多种压缩算法
- 支持多用语言的
UDF,包括:Python、Perl、Java、C/C++、R - 易接入其他数据源
Hadoop Native- 支持标准链接,包括
JDBC/ODBC
架构:
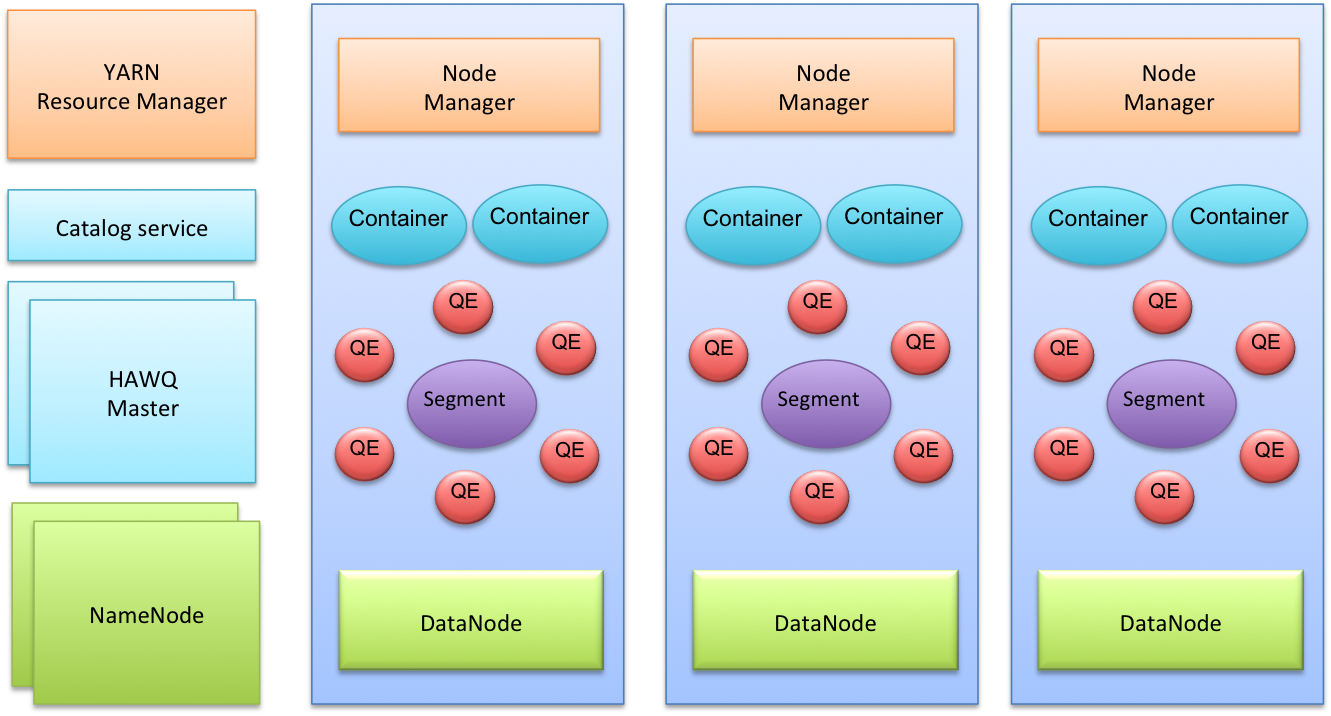
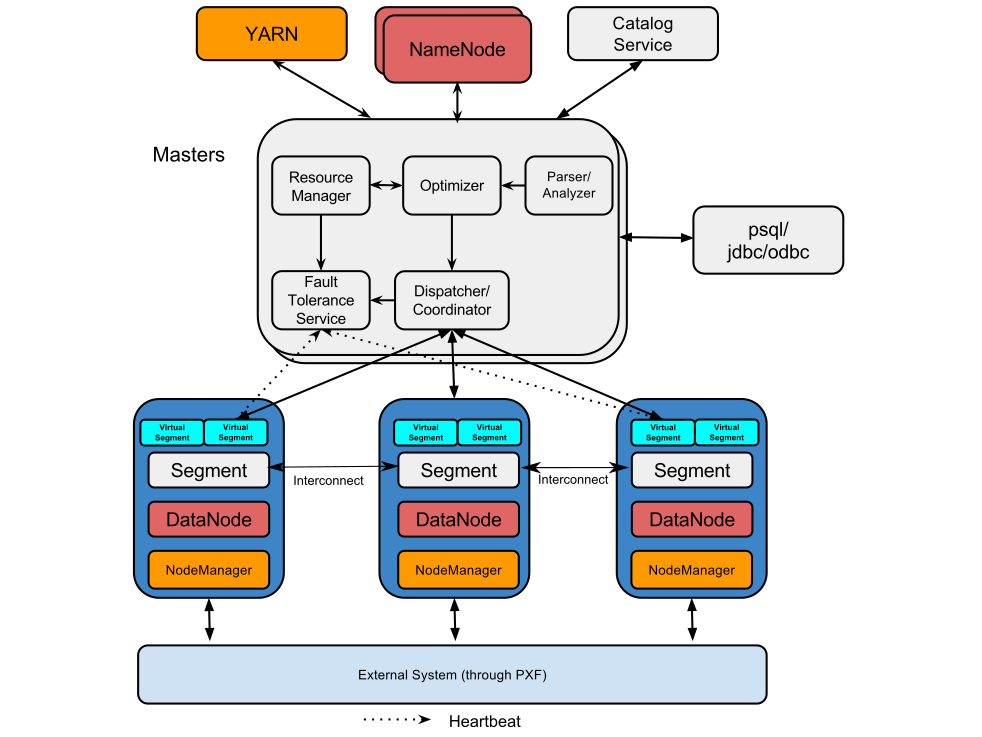
主页:
11 HBase
类型:NoSQL/Storage
特性:
- 线性和模块化的可扩展性
- 强一致性的读写
- 自动和可配置的表分片
- 自动异常恢复
- 面向Java的连接器
- 通过
Block Cache以及布隆过滤器支持实时查询
架构:
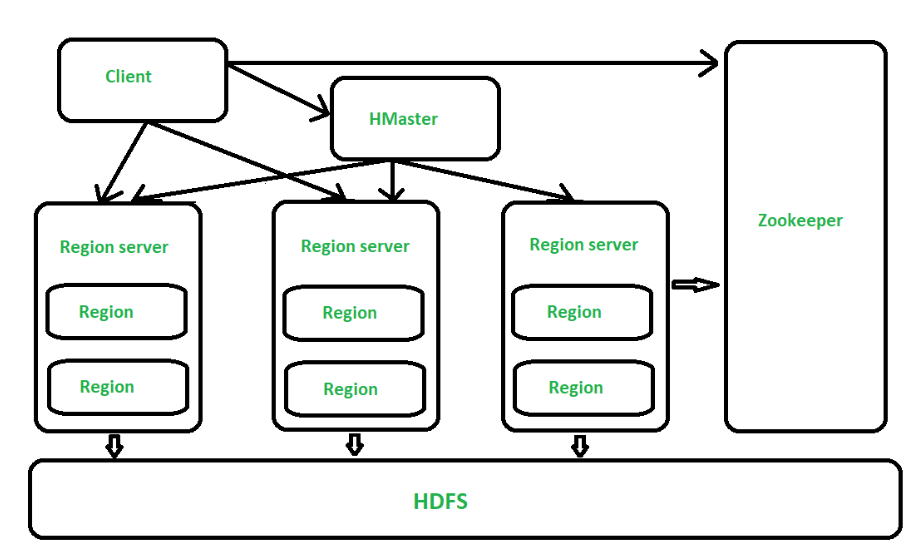
主页:
12 Hive
类型:OLAP
特性:
- 通过
SQL访问管理数据,hive会将其转换成数仓的任务,例如提取/转换/加载(extract/transform/load, ETL)、报告和数据分析 - 支持多种数据格式
- 支持
HDFS、HBase等存储层 - 执行引擎通过
Apache Tez、Apache Spark、MapReduce等系统来完成具体的操作 - 通过
Hive LLAP、Apache YARN和Apache Slider进行亚秒级查询检索。
架构:
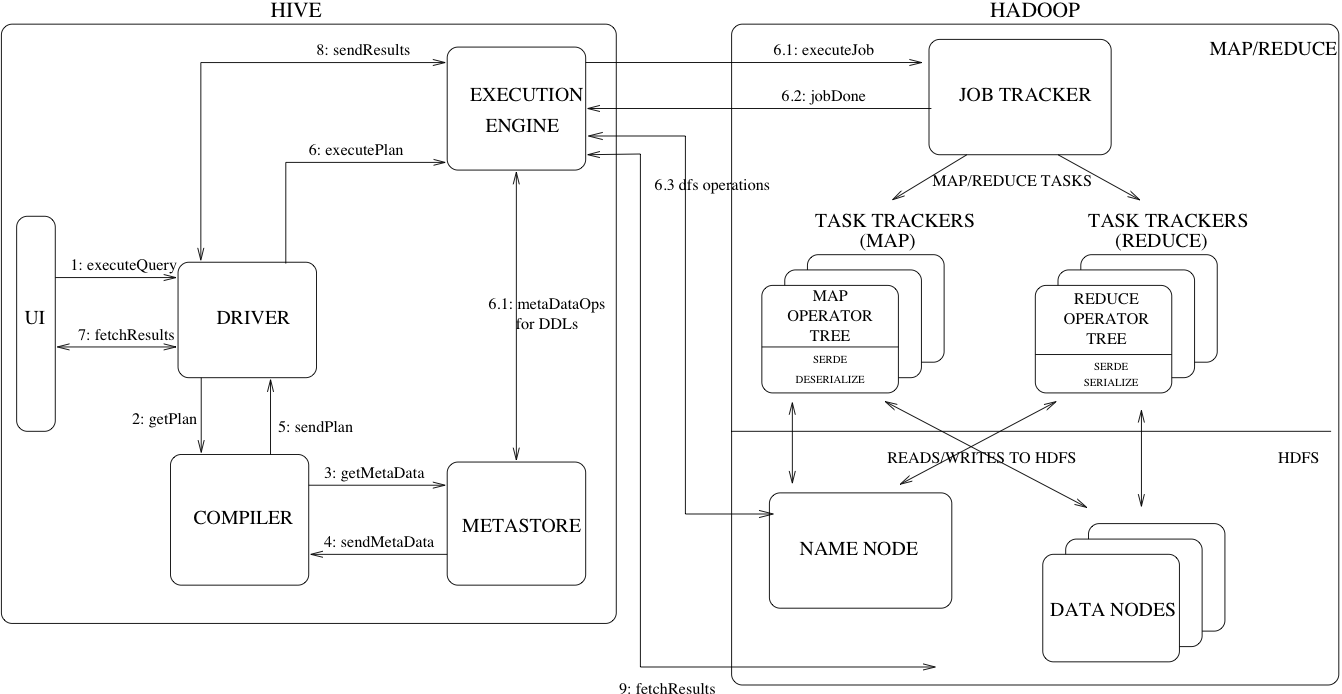
主页:
13 Hudi
类型:Data Lake
特性:
- 更新、删除性能好,索引插件化
- 事务、回滚、并发控制
- 自动调整文件大小、数据集群、压缩、清理
- 用于可扩展存储访问的内置元数据跟踪
- 增量查询,记录级别更改流
- 支持多种数据源,包括
Spark、Presto、Trino、Hive
架构:
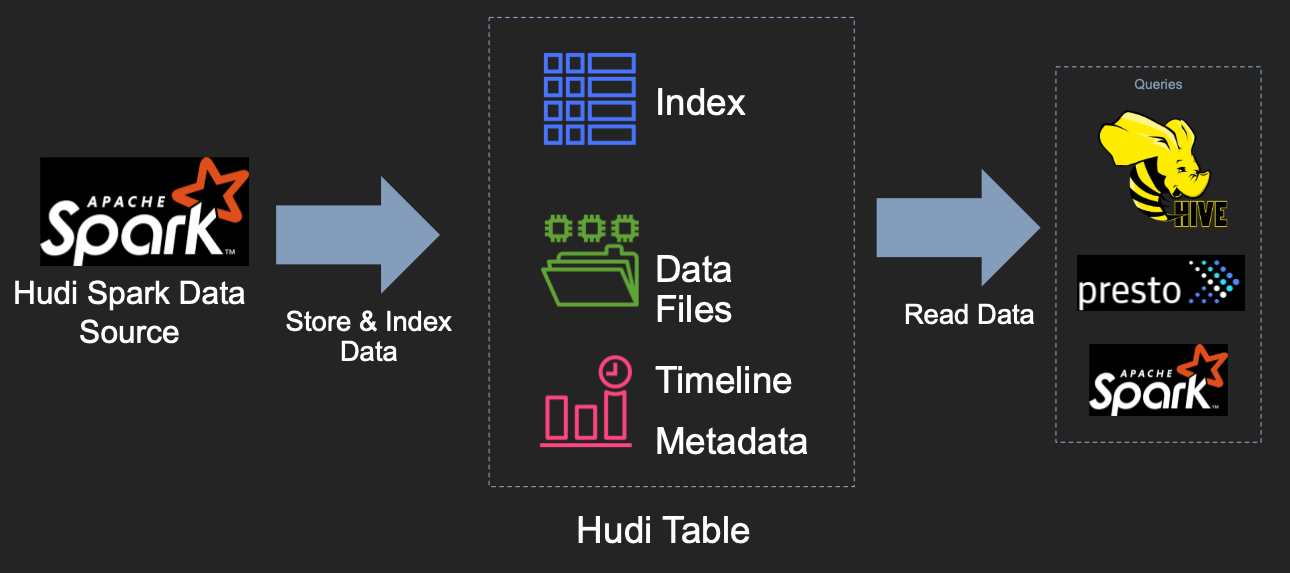
主页:
14 Iceberg
类型:Data Lake
特性:
架构:
主页:
15 Impala
类型:OLAP
特性:
- 支持SQL
- 支持在
Hadoop上查询大量数据 - 分布式架构
- 无需复制或导出/导入步骤即可在不同组件之间共享数据文件;例如,用
Pig编写,用Hive转换,用Impala查询。Impala可以读取和写入Hive表,从而使用Impala实现简单的数据交换,以分析Hive生成的数据 - 用于大数据处理和分析的单一系统,因此客户可以避免仅用于分析的昂贵建模和
ETL
架构:
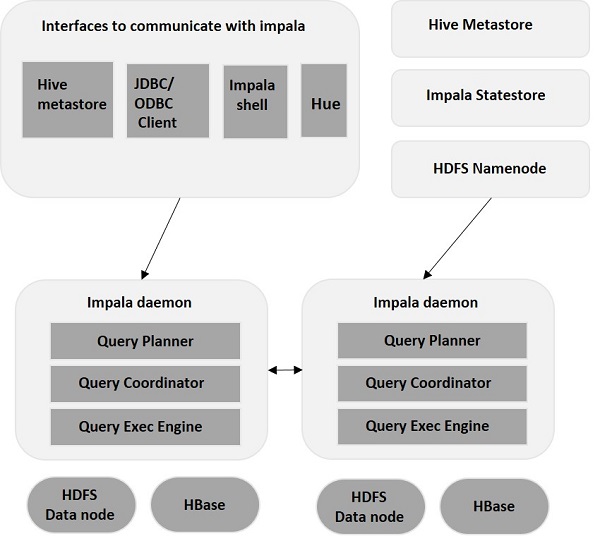
主页:
16 Kudu
类型:Columnar Storage
特性:
- 能快速处理
OLAP的工作负载 - 与
MapReduce、Spark和其他Hadoop生态系统组件集成较好 - 与
Apache Impala高度集成 - 强大但灵活的一致性模型,允许基于每个请求选择不同的一致性模型,包括严格序列化一致性的选项
- 同时支持顺序和随机的工作负载,且性能较好
- 便于管理
- 高可用
- 结构化的数据模型
架构:
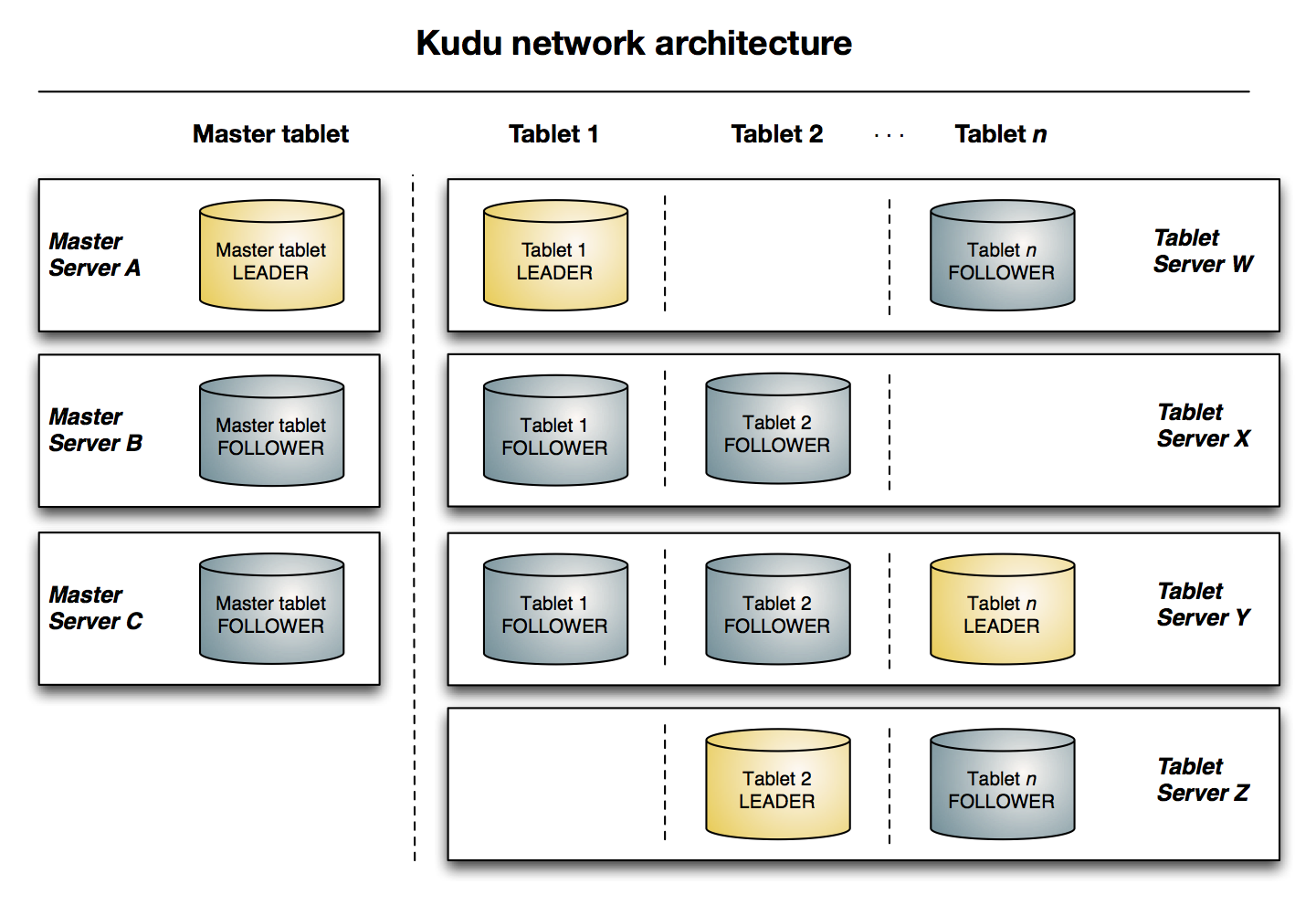
主页:
17 Kylin
类型:OLAP
特性:
- 为
Hadoop提供标准SQL支持大部分查询功能 - 多维体立方
- 实时多维分析
- 与
BI工具无缝整合,包括Tableau,PowerBI/Excel,MSTR,QlikSense,Hue和SuperSet
架构:
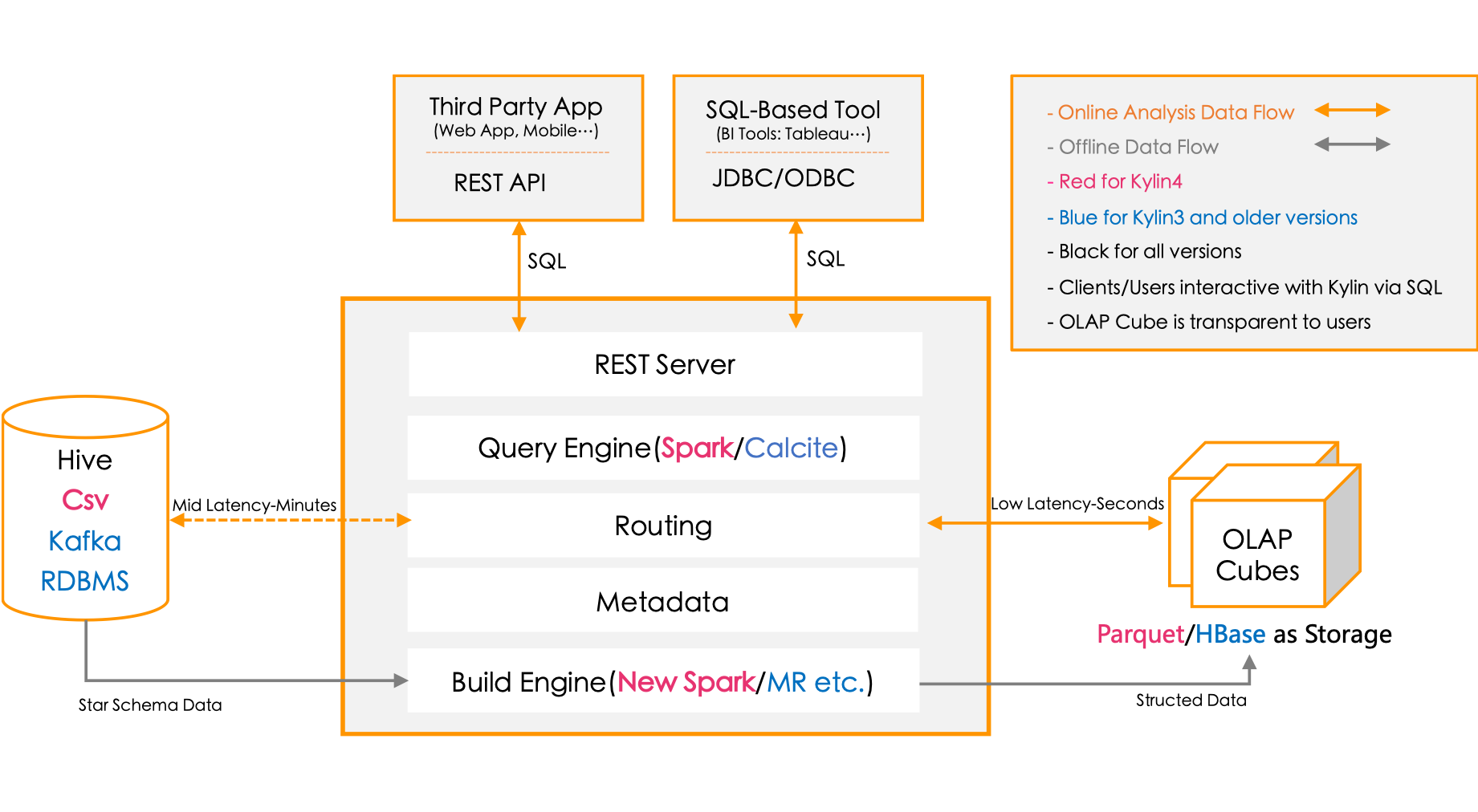
主页:
18 Pinot
类型:OLAP
特性:
- 列存
- 索引插件化,支持包括
Sorted Index、Bitmap Index、Inverted Index、StarTree Index、Bloom Filter、Range Index、Text Search Index(Lucence/FST)、Json Index、Geospatial Index - 可以基于元数据进行查询优化
- 支持从
Kafka、Kinesis中实时获取数据 - 支持从
Hadoop、S3、Azure、GCS中批量获取数据 - 提供类似于
SQL的语言,用于聚合、过滤、分组、排序等操作 - 易于水平扩展,容错性好
架构:
- [Architecture(https://docs.pinot.apache.org/basics/architecture)

主页:
19 PostgreSQL
类型:OLAP
特性:
架构:
主页:
其他:
20 Presto
类型:OLAP
特性:
- 支持就地分析(
In-place analysis)。直接对接数据源,包括Hive、Cassandra、Relational Databases甚至是专有数据存储 - 允许单个查询的数据来自不同的数据源
架构:
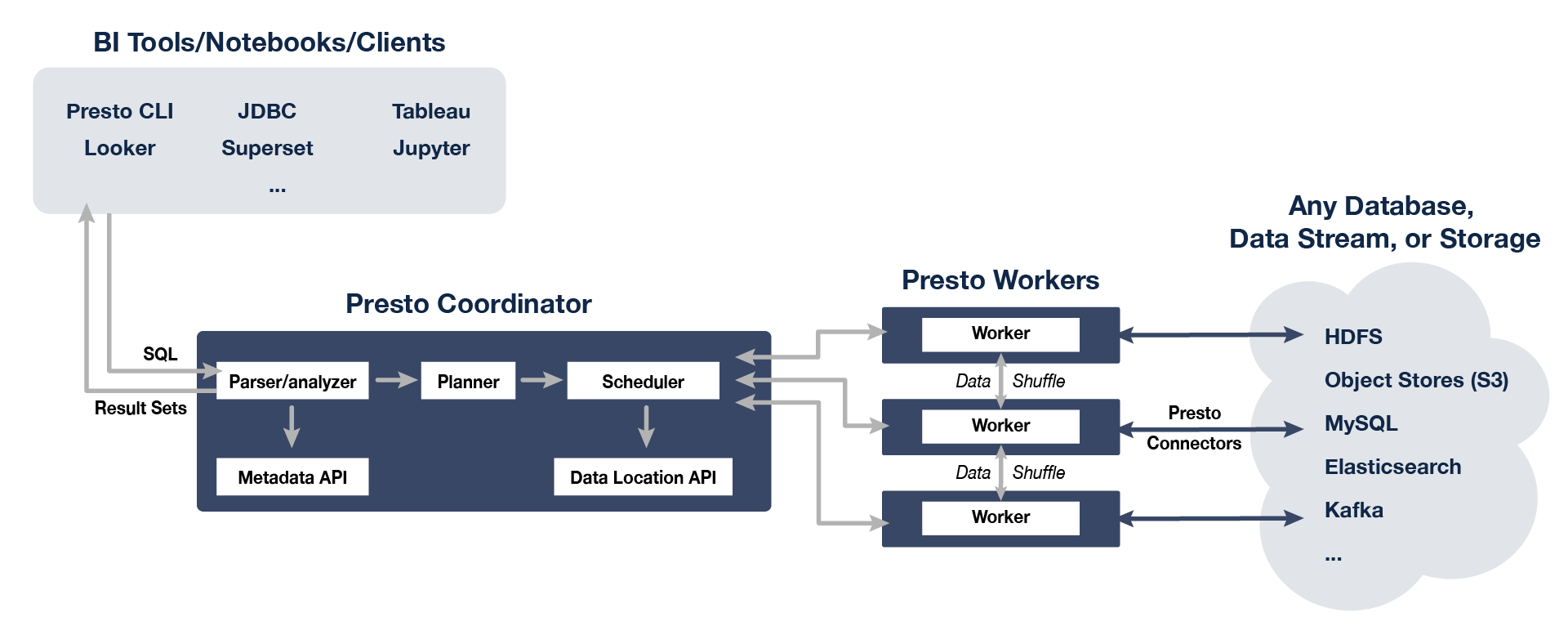
主页:
21 Starrocks
类型:OLAP
特性:
MPP架构- 架构精简,不依赖外部系统
- 全面向量化引擎
- 只能查询分析
- 联邦查询
- 物化视图
- 兼容mysql协议
架构:
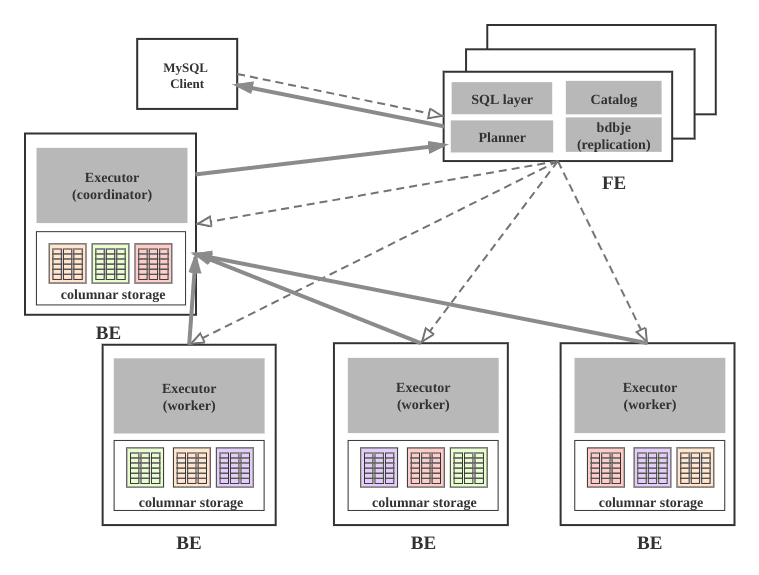
主页:
博客&文章:
22 Snowflake
类型:OLAP
特性:
- 数据安全
- 支持标准以及扩展
SQL - 大量的工具
- 面向各类语言的连接器,包括
Python、Spark、Node.js、Go、.NET、JDBC、ODBC、PHP等等
架构:
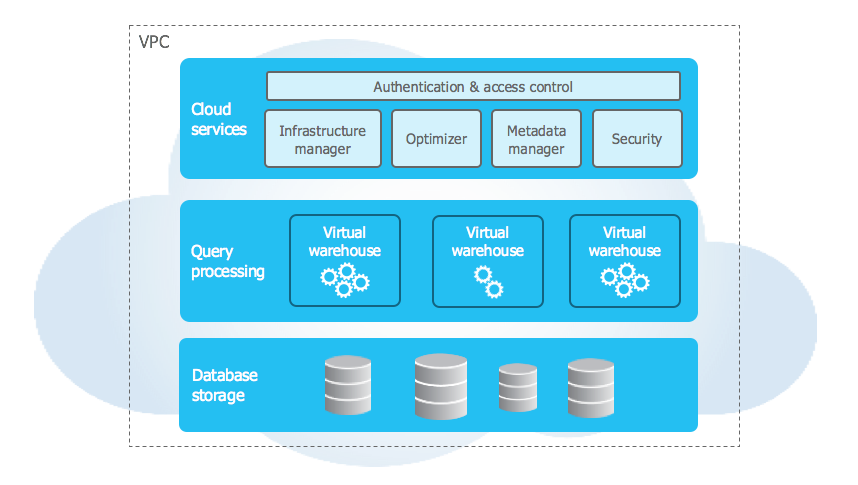
主页:
23 Spark
类型:Analytics Engine(Alternative to MapReduce)
特性:
- 支持流批
- 支持
ANSI SQL
架构:
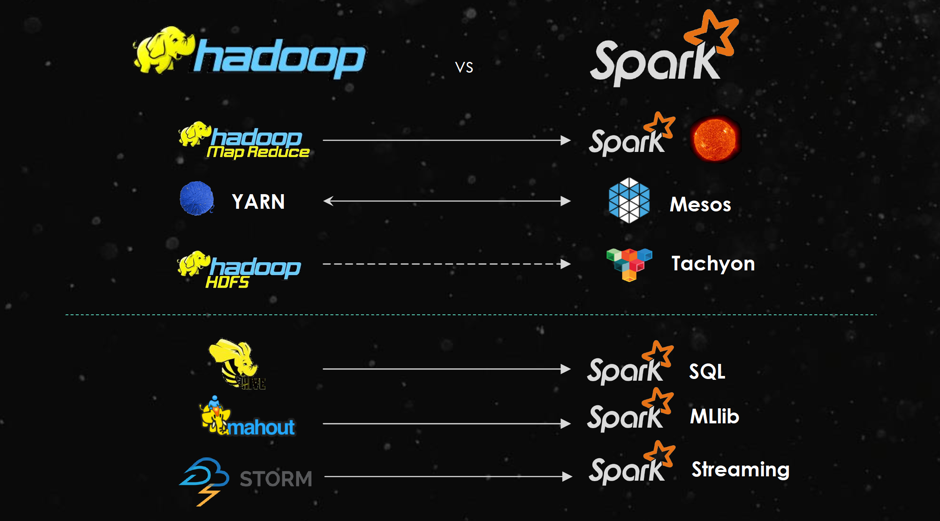
主页:
24 TiDB
类型:OLTP
特性:
- 一键水平扩容或者缩容
- 金融级高可用
- 实时
HTAP - 云原生的分布式数据库
- 兼容
MySQL 5.7协议和MySQL生态
架构:
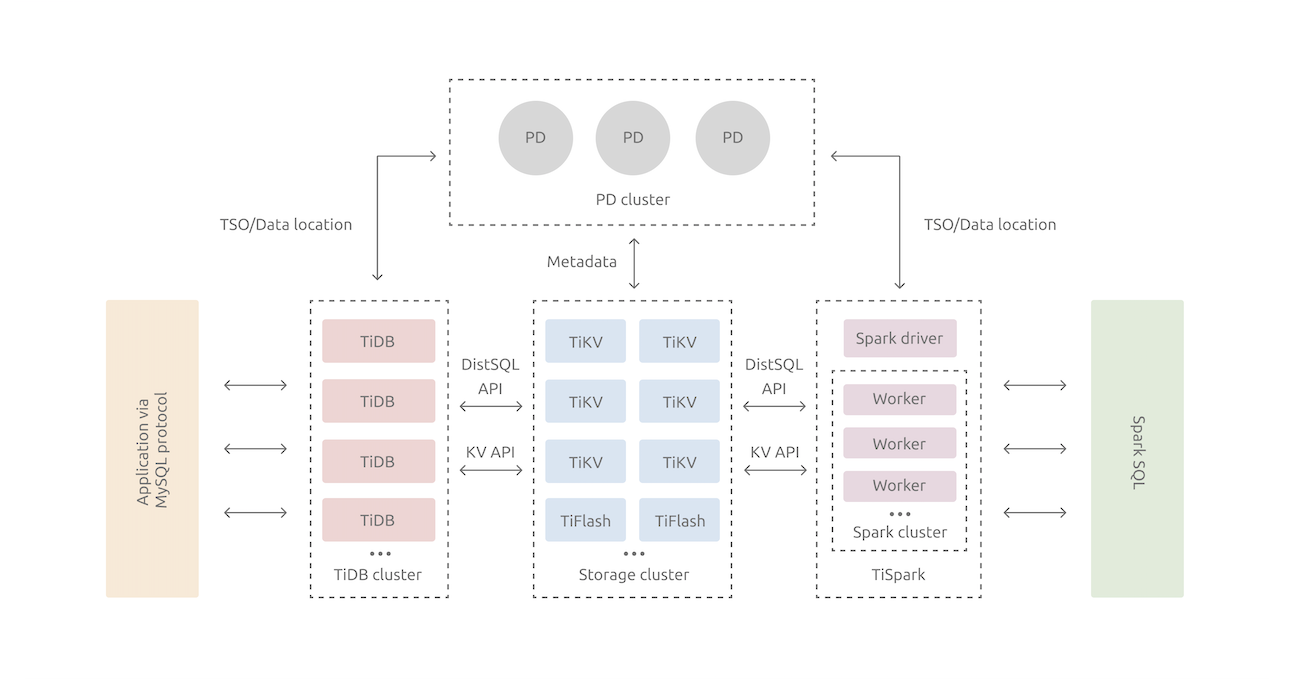
主页:
25 Trino
Trino is forked from Presto
类型:OLAP
特性:
- 并行化、分布式的查询引擎,查询速度快
- 兼容
ANSI SQL,与BI工具集成较好,包括R、Tablau、Power BI、Superset - 支持多种工作负载,包括实时分析、批处理、亚秒级查询
- 支持就地分析(
In-place analysis)。直接对接数据源,包括Hadoop、S3、Cassandra、MySQL等 - 允许单个查询的数据来自不同的数据源
- 支持云原生
架构:
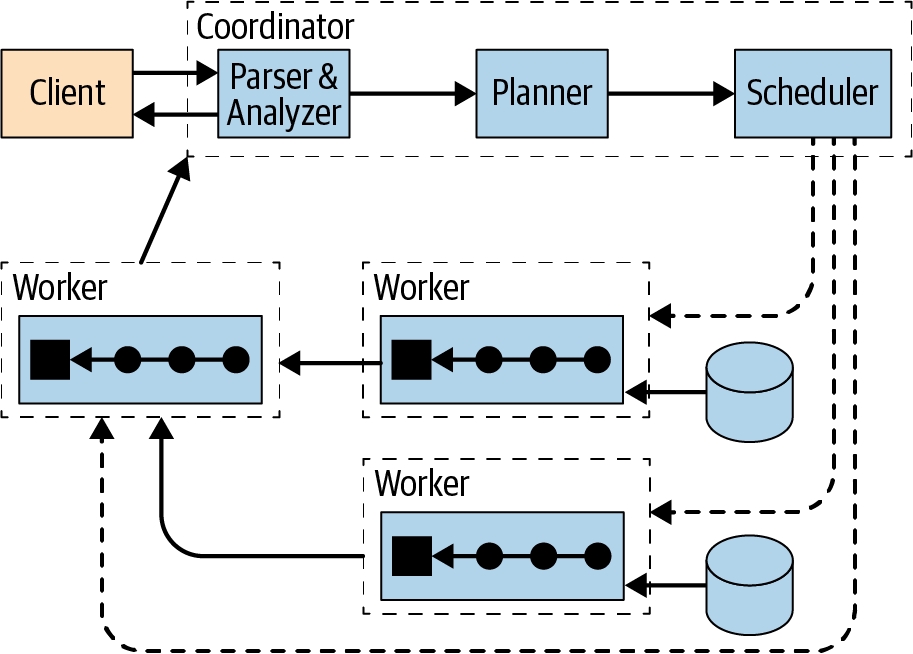
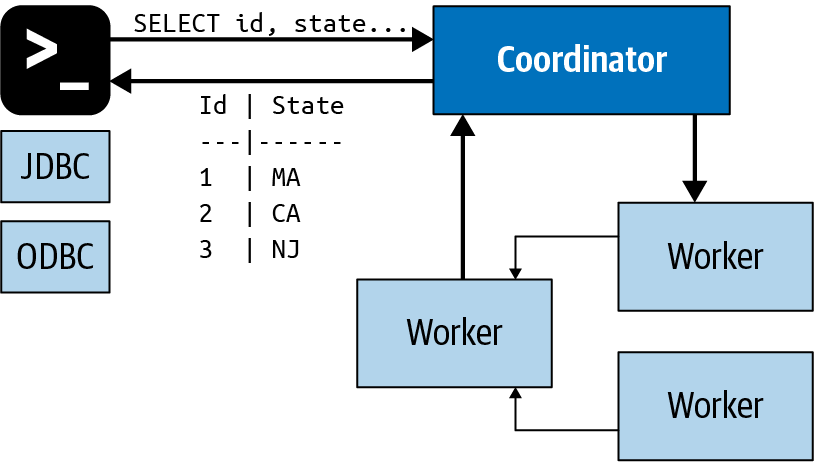
主页:
博客&文章:
26 Vertica
类型:OLAP
特性:
架构:
主页:
27 VikingDB
类型:Graph/Vector
特性:
架构:
主页:
28 Relations
- Databricks: Spark 团队成员组建的商业化公司
- Trino: 基于 Presto
29 TODO
- mysql
- sqlite
- Zilliz
- 向量数据库
- ksqlDB
- Rockset
- Databend
- Umbra
- Thomas Neumann
- Publications
- paimon