阅读更多
1 Overview
1.1 Kubernetes Components
1.1.1 Master Components
Master Component构成了集群的控制面板。Master Component是整个集群的决策者,检测并响应集群消息
Master Component可以运行在集群中的任意一台机器上,不要在Master机器上运行User Container
1.1.1.1 kube-apiserver
kube-apiserver是整个控制面板的最前端,将Master Component通过Kubernetes API露出,它被设计成易于水平扩展
1.1.1.2 etcd
etcd是高一致性、高可用的key-value存储,用于存储Kubernetes所有的集群数据
1.1.1.3 kube-shceduler
kube-shceduler会观测新创建且尚未被分配的Pod,并为其选择一个Node来运行
1.1.1.4 kube-controller-manager
kube-controller-manager用于在Master上运行Controller。逻辑上讲,每个Controller都是一个独立的进程,但是为了减小实现复杂度,这些被编译进了一个二进制中,运行在同一个进程中
Controller包括
Node Controller: 观测节点,并在节点退出集群时响应Replication Controller: 为系统中每个Replication Controller Object保持一定数量的PodEndpoints Controller:Service Account & Token Controller: 为新Namespace创建默认的账号以及API访问的token
1.1.1.5 cloud-controller-manager
1.1.2 Node
Node component运行在每个Node之上,保持Pod的运行,并提供Kubernetes运行环境
1.1.2.1 kubelet
kubelet是运行在集群的每个Node上的代理。它确保Container在Pod中正常运行
kubelet采用通过各种机制提供的PodSpecs来确保Container以期望的方式健康运行
kubelet不会管理不由Kubernetes创建的Container
1.1.2.2 kube-proxy
kube-proxy通过维护网络规则并转发网络数据包,来支持Kubernetes Service的抽象机制
1.1.2.3 Container Runtime
Kubernetes支持多种运行时
Dockerrktrunc
1.1.3 Addons
???
1.1.4 参考
1.2 Kubernetes Object
Kubernetes Object作为持久化的实体,存在于Kubernetes系统中,Kubernetes用这些实体来表示集群的状态,具体来说
- 运行着什么容器化的应用程序
- 可以使用的资源清单
- 应用程序的策略,包括重启策略、更新、容错等
一个Kubernetes Object用于记录我们的意图,一旦我们创建了一个Kubernetes Object,那么Kubernetes系统就会努力保证对象的存活,并朝着我们预期的状态推进。换言之,创建一个Kubernetes Object,意味着告诉Kubernetes系统,我们期望它以何种方式运行
我们必须通过Kubernetes API来使用Kubernetes Object,包括创建、修改、删除等。我们也可以使用kubectl命令行工具,本质上,kubectl为我们封装了一个或多个Kubernetes API的调用。
每个Kubernetes Object都至少包含两个object field,即spec以及status
spec:描述了Kubernetes Object的期望状态status:描述了Kubernetes Object的实际状态,这个状态由Kubernetes system更新
当我们需要创建一个Kubernetes Object时,我们需要提供spec来描述这个Kubernetes Object的期望状态,同时,还需要提供一些基本的信息来描述这个Kubernetes Object,例如name等。当我们利用Kubernetes API来创建object时,API request中的request body必须包含这些信息。通常我们将这些信息记录在.ymal文件中,并将文件作为参数传递给Kubernetes API
注意,一个.yaml文件中,必须包含如下字段
apiVersion:指定Kubernetes API的版本kind:指定待创建object的类型metadata:object的元数据,包括nameUIDnamespace
1.2.1 Name
所有的Kubernetes Object都用一个Name和一个UID精确确定
1.2.1.1 Nmaes
Names是一种用户提供的字符串,表示了一个资源的路径,例如/api/v1/pods/some-name
在同一时刻,可以为同一种类型的Kubernetes Object分配一个名字。当然,如果我们删除了这个Kubernetes Object,我们还可以创建一个同名的Kubernetes Object
通常,Name最大不超过253个字符,只允许包含小写的字母以及-和.,具体的类型可能还有更加严格的限制
1.2.1.2 UIDs
UID是Kubernetes系统创建的用于唯一标志Kubernetes Object的字符串。每个Kubernetes Object在整个生命周期中都会有一个唯一的UID,将Kubernetes Object先删除再重新创建,会得到一个新的UID
1.2.2 Namespaces
Kubernetes支持同一个物理集群支持多个虚拟集群,这些虚拟集群被称为Namespaces。如果一个Kubernetes集群仅有数十个用户,那么我们完全不必考虑使用Namespaces
1.2.2.1 When to use Multiple Namespaces
Namespaces用于为使用同一集群的多个不同的小组、项目提供一定程度的隔离
在同一个Namespaces中的资源的名称必须唯一,但是在不同Namespaces中的资源名称可以重复
如果仅仅为了隔离资源,例如同一个软件的不同版本,可以使用Label而不需要使用Namespaces
1.2.2.2 Working with Namespaces
可以通过如下命令查看系统中的Namespaces
1 | kubectl get namespaces |
Kubernetes默认包含三个Namespaces
default: 在未指定Namespace时,Kubernetes Object默认属于这个Namespacekube-system: 由Kubernetes系统创建的Kubernetes Object所属的Namespacekube-public: 该Namespace对所有的用户可见,通常用于共享一些资源
在使用kubectl时,我们可以加上--namespace来暂时指定Namespace
我们可以为kubectl设定Namespace上下文,后续所有的命令都默认指定该Namespace
1 | kubectl config set-context $(kubectl config current-context) --namespace=<insert-namespace-name-here> |
1.2.2.3 Namespaces and DNS(未完成)
当我们创建一个Service,它会创建一个相关的DNS entry,其格式为<service-name>.<namespace-name>.svc.cluster.local
1.2.2.4 Not All Objects are in a Namespace
大部分Kubernetes资源位于一个Namespace中。某些底层次的资源,例如Node以及PersistentVolume不属于任何Namespace
以下命令用于查看哪些资源位于/不位于Namespace中
1 | # In a namespace |
1.2.3 Labels and Selectors
Labels是一些依附在Kubernetes Object上的键值对。Lebels用于为一些对用户有特殊意义的Kubernetes Object打标,这些标在Kubernetes内核中并无其他含义。Label用于组织和选择Kubernetes Object。我们可以再任何时刻为Kubernetes Object打上Label。对于一个Kubernetes Object来说,key必须是唯一的
1.2.3.1 Motivation
Lebal允许用户以一种松耦合的方式将组织结构与Kubernetes Object关联起来,用户不必自己存储这些映射关系
服务部署以及一些批处理流水线通常是一个多维度的实体,通常需要交叉式的管理,这会破坏层次结构的严格封装,通常这些封装是由基础设施而非用户完成的
1.2.3.2 Label selectors
与Name与UID不同,Label并不需要保证唯一性。而且,在通常情况下,我们期望多个Kubernetes Object共享同一个Label
通过Label Selector,用户/客户端就可以识别出这些Kubernetes Object,因此Label Selector是Kubernetes管理这些对象的核心
目前,Kubernetes支持两种类型的Selector:equality-based和set-based。Label Selector由多个requirement组成,以逗号分隔,多个requirement之间的关系是逻辑与&&。这两种类型可以混用
Equality-based requirement允许通过Label key以及Label value进行过滤,允许的比较操作包括:=、==、!=,其中=与==都表示相等型比较
1 | environment = production |
- 第一个规则表示:匹配
key等于environment且value等于production的所有Kubernetes Object - 第二个规则表示:匹配
key等于tier且value不等于frontend的所有Kubernetes Object - 第三个规则表示:前两个规则的逻辑与关系
Set-based requirement允许根据一组集合来进行过滤,允许的操作包括:in、notin、exists。Set-based requirement表达能力要大于Equality-based requirement,即Equality-based requirement可以用Set-based requirement的方式表示出来
1 | environment in (production, qa) |
- 第一个规则表示:匹配
key等于environment且value等于production或qa的所有Kubernetes Object - 第二个规则表示:匹配
key等于tier且value不等于frontend且value不等于backend的所有Kubernetes Object - 第三个规则表示:匹配含有
partition这个key的所有Kubernetes Object - 第四个规则表示:匹配不含有
partition这个key的所有Kubernetes Object
selector配置格式
1 | selector: |
matchLabels是一个key-value的mapmatchExpressions是一系列的selector requirement- 所有的条件会以逻辑与的方式组合(包括
matchLabels和matchExpressions)
1.2.3.3 API
1 | kubectl get pods -l environment=production,tier=frontend |
1.2.4 Annotations
我们可以通过Label以及Annotation为Kubernetes Object添加一些元数据。Label通常被用于Kubernetes Object的匹配,而Annotation通常用于为Kubernetes Object添加一些配置,这些配置可以包含一些Label不允许的字符
1.2.5 Field Selectors
Field Selector允许我们基于Kubernetes Object的字段匹配来过滤Kubernetes Object,支持的匹配操作包括:=、==、!=,其中=与==都表示相等型比较
1 | kubectl get pods --field-selector status.phase=Running |
1.2.6 Recommended Labels
1.2.7 参考
- Understanding Kubernetes Objects
- Imperative Management of Kubernetes Objects Using Configuration Files
2 Architecture
2.1 Node
Node是Kubernetes中的一个工作者。Node可能是一个虚拟机或者物理机。每个Node被Master Component管理,包含了一些运行Pod所必须的服务,包括Container runtime、kubelet、kube-proxy
2.1.1 Node Status
Node的状态包括以下几部分
AddressConditionCapacityInfo
2.1.1.1 Addresses
Address包含的字段与服务提供方或者裸机配置有关
HostName:hostname由Node的内核上报。可以通过kubelet参数--hostname-override覆盖ExternalIP: 公网IPInternalIP: 集群内的IP
2.1.1.2 Condition
conditions字段描述了Node的状态,包括
OutOfDisk: 如果剩余空间已经无法容纳新的Pod时,为Frue;否则FalseReady: 如果Node可以接收新的Pod时,为True;如果Node无法接纳新的Pod时,为False;如果Controller与该Node断连一定时间后(由node-monitor-grace-period字段指定,默认40s),为UnknownMemoryPressure: 存在内存压力时,为Ture;否则FalsePIDPressure: 存在进程压力时,为True;否则FalseDiskPressure: 存在磁盘压力时,为True;否则FalseNetworkUnavailable: 网络异常时,为True;否则False
2.1.1.3 Capacity
描述了可用资源的数量,包括CPU、内存、最大可运行的Pod数量
2.1.1.4 Info
描述了节点的通用信息,包括内核版本,Kubernetes版本,Docker版本,OS名称等等
2.1.2 Management
与Pod与Service不同,Pod与Service是由Kubernetes负责创建的,而Node是由云服务商或者使用者提供的。当Kubernetes创建了一个Node仅仅意味着创建了一个Kubernetes Object来描述这个Node
目前,存在三个与Node交互的组件,他们分别是:Node Controller、kubelet、kubectl
2.1.2.1 Node Controller
Node Controller是Kubernetes master component,用于管理Node的生命周期
- 当
Node注册时,为Node分配一个CIDR block - 保持
Node列表与云服务提供方的可用机器列表一致,当Node变得unhealthy后,Node Controller会询问云服务提供商该VM是否仍然可用,若不可用,则会将其从Node列表中删除 - 监视
Node的健康状况,Node Controller会在Node变得unreachable后将状态从NodeReady变为ConditionUnknown,然后以优雅的方式移除该Node上的所有Pod
在Kubernetes 1.4版本中,对集群中大批Node同时出故障这一情况的处理做了一些优化,Controller会观测集群中所有Node的状态,来决策Pod以何种方式、何种规模进行移除
在大多数情况下,Node Controller限制了移除率--node-eviction-rate(默认是0.1),意味着,10秒之内最多只有一个Node节点上的Pod会被移除
当一个可用区(Zone)中的某个Node发生故障时,Node移除的行为发生了改变。Node Controller会检测在当前可用区中发生故障的Node的占比,如果这个比例最少为--unhealthy-zone-threshold(默认0.55)时,移除率会降低。如果集群很小(节点数量小于),移除过程会直接停止
将Node分布于不同的可用区的原因是,当一个可用区变得完全不可用时,那这些Pod可以迁移到其他的可用区中
2.1.3 Node capacity
Node容量是Node Object的一部分。通常Node在向Master注册时,需要上报容量信息。如果我们是手动创建和管理Node,那么就需要手动设置容量信息
Kubernetes Scheduler会保证Node上的资源一定大于所有Pod占用的资源。注意到,它仅仅会计算通过kubelet创建的Container所占用的资源数量,而不会计算由Container runtime或者手动创建的Containter所占用的资源数量
2.2 Master-Node communication
2.2.1 Cluster to Master
Node与Master之间的通信全部依靠Api Server,除此之外,其他Master component不会提供远程服务。在一个典型的部署场景中,Api Server会在443端口上监听
应该为Node配置公共根证书,以便它们可以安全地连接到Api Server
Pod可以借助Service Account来与Api Server进行安全通信,Kubernetes会在Pod实例化的时候,将根证书以及令牌注入到Pod中去
Kubernetes会为每个Server分配一个虚拟IP,kube-proxy会将其重定向为Api Server的具体IP
因此,Node与Api Server之间的通信可以在可靠/不可靠的网络下进行
2.2.2 Master to Cluster
Master(Api server)与Node的通信的方式有两种:其一,Api Server通过与每个Node上的kubelet来完成通信;其二,Api Server通过Proxy来完成与Node、Pod、Server的通信
2.2.2.1 Api server to kubelet
Api Server与kubelet之间的通信主要用于以下几个用途
- 获取
Pod的日志 - 与运行时的
Pod进行交互 - 为
kubelet提供端口转发服务(port-forwarding functionality)
默认情况下,Api Server不会校验kubelet的服务端证书,因此有可能受到中间人攻击(man-in-the-middle),因此在不可信的网络中或者公网上是不安全的。我们可以通过--kubelet-certificate-authority来为Api Server提供一个根证书,用来校验kubelet的证书合法性
2.2.2.2 Api server to nodes, pods, and services
Api Server与Node、Pod、Service之间的通信默认用的是HTTP协议,显然这是不安全的。我们可以为Node、Pod、Service的API URL指定https前缀,来使用HTTPS协议。但是,Api Server仍然不会校验证书的合法性,也不会为客户端提供任何凭证,因此在不可信的网络中或者公网上是不安全的
2.3 Concepts Underlying the Cloud Controller Manager
最初提出Cloud Controller Manager(CCM)概念是为了能够让云服务商与Kubernetes可以相互独立地发展
CCM是的设计理念是插件化的,这样云服务商就可以以插件的方式与Kubernetes进行集成
2.3.1 Design
如果没有CCM,Kubernetes的架构如下:
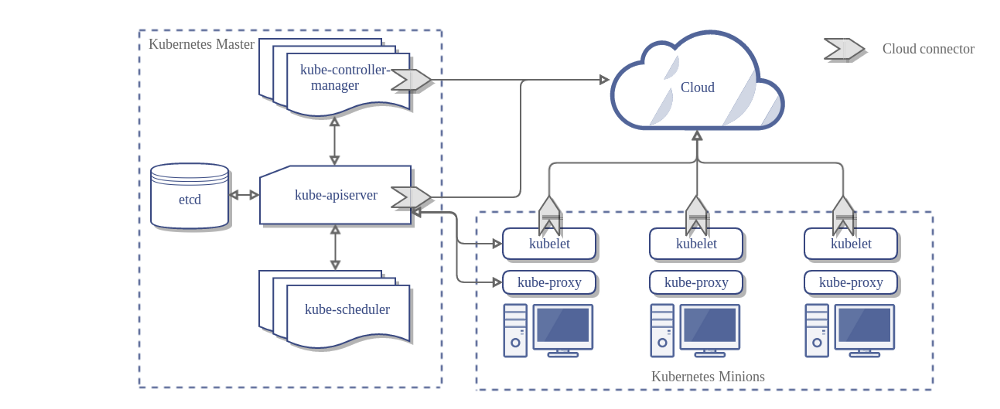
在上面的架构图中,Kubernetes与Cloud Provider通过几个不同的组件进行集成
kubeletKubernetes Controller Manager(KCM)Kubernetes API server
在引入CCM后,整个Kubernetes的架构变为:
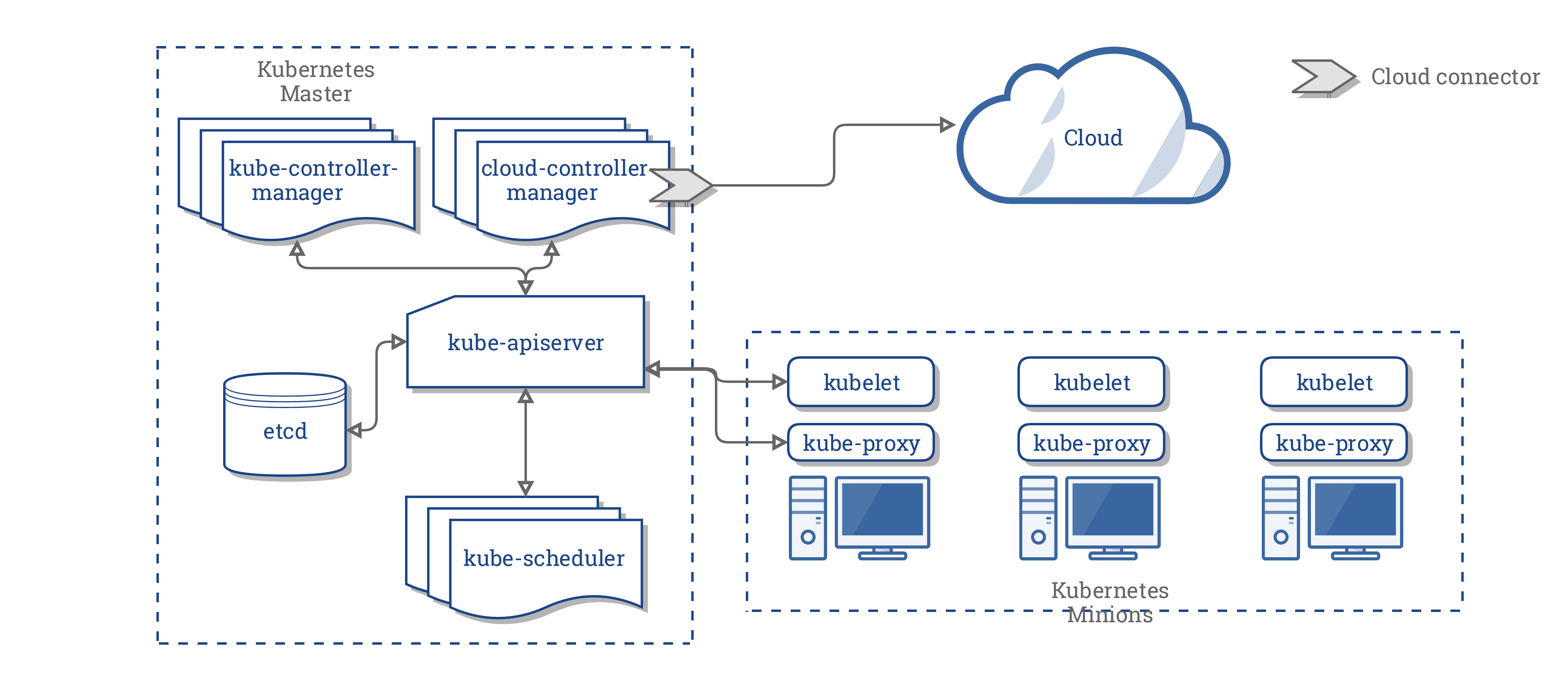
2.3.2 Components of the CCM
CCM打破了KCM的一些功能,并且作为一个独立的进程运行。具体来说,CCM打破了KCM那些依赖于云的Controller
KCM具有如下Controller:
Node ControllerVolume ControllerRoute ControllerService Controller
CCM包含如下Controller
Node ControllerRoute ControllerService ControllerPersistentVolumeLabels Controller
2.3.3 Functions of the CCM
2.3.3.1 Kubernetes Controller Manager
CCM中大部分的功能都是从KCM中继承过来的,包括如下Controller
Node ControllerRoute ControllerService ControllerPersistentVolumeLabels Controller
2.3.3.1.1 Node Controller
Node Controller负责初始化Node,它会从Cloud Provier中获取有关Node的一些信息,具体包括
- 初始化
Node时,为其打上zone/region的标签 - 初始化
Node时,记录一些定制化的信息,包括type和size - 获取
Node的hostname和address - 当
Node失联时,询问Cloud Provider该Node是否已被其删除,如果已被删除,那么删除该Node对应的Kubernetes Node Object
2.3.3.1.2 Route Controller
Route Controller负责配置路由信息,以便位于不同Node节点上的Container能够进行相互通信,目前只与Google Compute Engine Cluster兼容
2.3.3.1.3 Service Controller
Service Controller负责监听Service的创建、更新、删除对应的事件,确保负载均衡可以时时感知服务的状态
2.3.3.1.4 PersistentVolumeLabels Controller
PersistentVolumeLabels Controller在AWS EBS/GCE PD Volume创建时,为其打上标签。这些标签对于Pod的调度至关重要,因为这些Volume只在特定的区域,因此被调度的Pod也必须位于这些区域才行
PersistentVolumeLabels Controller仅用于CCM中
2.3.3.2 Kubelet
Node controller包含了kubelet中依赖于云的功能。在引入CCM之前,kubelet在初始化Node时,还需要负责初始化IP地址、区域标签以及实例类型等信息。引入CCM后,这些初始化操作将从kubelet中被移除,完全由CCM负责初始化
在新模式下,kubelet可以单纯地创建一个Node,而不用关心与云相关的一些依赖信息。在CCM完成初始化之前,该Node是无法被调度的
2.3.3.3 Kubernetes API server
同样地,PersistentVolumeLabels也将Api Server中与云相关的部分迁移到CCM中
2.3.4 Plugin mechanism
CCM定义了一系列的接口(Go接口),交由云服务商自行提供实现
2.3.5 Authorization
2.3.5.1 Node Controller
Node Controller只与Node Object进行交互,可以进行如下操作
GetListCreateUpdatePatchWatchDelete
2.3.5.2 Route Controller
Route Controller监听Node Object的创建以及配置路由规则,可以进行如下操作
Get
2.3.5.3 Service Controller
Service Controller监听Service Object的创建、更新、删除,以及配置endpoint,可以进行如下操作
ListGetWatchPatchUpdate
2.3.5.4 PersistentVolumeLabels Controller
PersistentVolumeLabels Controller监听PersistentVolume (PV)的创建,可以进行如下操作
GetListWatchUpdate
2.4 参考
3 Workloads
3.1 Pods
3.1.1 Pod Overview
3.1.1.1 Understanding Pods
Pod是Kubernetes中,用户能够创建或部署的最小单元,一个Pod代表了一个进程(可能是高耦合的一组进程)。Pod封装了以下资源
Container:一个或多个应用容器volume:存储资源IP:一个pod会被分配一个IP,在所属的namespace下唯一options:控制容器运行的参数
通常,Pod在Kubernetes集群中有两种主要用法
Pods that run a single container: 该模式是Kubernetes最常用的模式。在这种情况下,我们可以认为Pod对Container做了一层封装,Kubernetes直接管理Pod而不是ContainerPods that run multiple containers that need to work together: 在这种模式下,Pod封装了由一组高耦合的Container构成的应用,这些Container需要共享资源
每一个Pod都运行着一个应用的一个实例。如果我们想要水平扩展,我们必须使用多个Pod,同样,每个Pod运行一个实例。在Kubernetes中,这称为replication。通常,Replicated Pod由Controller统一创建和管理
Pod为Container提供了两种共享资源的方式
networking: 每个Pod被分配了一个唯一的IP地址,每个Container共享网络的Namespace,包括IP地址以及端口号。位于同一个Pod中的Container可以通过localhost来进行通信。位于不同Pod中的Container需要借助host以及port来通信storage:Pod可以分享一些存储卷。位于同一个Pod中的所有Container共享这些卷
3.1.1.2 Working with Pods
在Kubernetes中,我们很少直接创建独立的Pod,因为Pod被设计成一种相对短暂的、一次性的实体。当Pod被创建后(被用户直接创建,或者被Controller创建),它就会被调度到某个节点上开始运行。Pod会一直在Node上运行,直至被终结、Pod Object被删除、Node宕机
Pod自身并不会自我恢复。也就是说,当Pod部署失败或者挂了,这个Pod的生命周期就结束了。Kubernetes用一个高层次的概念,即Controller,来管理Pod的生命周期,包括Pod的创建、部署、副本、恢复等工作
Controller可以为我们创建和管理多个Pod,水平扩容、提供自我修复能力。例如,当一个Node宕机后,Controller会自动地在另一个Node上重新启动一个新的Pod
3.1.1.3 Pod Templates
Pod Template是Pod的一份声明(如下),可以被其他Kubernetes Object(包括Replication Controllers、Job等)引用
1 | apiVersion: v1 |
Pod Template更像一个饼干模具,而不是指定所有副本的当前期望状态。当一个饼干制作完成后,它与饼干模具毫无关系。Pod Template杜绝了量子纠缠,更新或者替换Pod Template对于已经生产的Pod不会产生任何影响
3.1.2 Pods
3.1.2.1 What is a Pod?
Pod包含一个或者一组Container,一些共享的存储/网络组件,以及运行应用的方式。Pod中的共享上下文包括:Linux namespaces,cgroups,以及其他可能的隔离因素
在一个Pod中的所有Container共享一个IP地址,以及端口空间,Container之间可以通过localhost进行通信,或者其他IPC方式。不同Pod中的Container具有不同的IP地址,因此,仅能通过Pod IP进行通信
在同一个Pod中的Container可以访问共享卷,共享卷是Pod的一部分,并且可以挂载到文件系统上
Pod被设计成一种短暂的、一次性的实体。Pod在创建时会被赋予一个唯一的UID,并且被调度到某个Node上一直运行直至被销毁。如果一个Node宕机了,那些被调度到该Node上的Pod会被删除。一个特定的Pod(UID层面)不会被重新调度到新的Node上,相反,它会被一个新的Pod替代,这个新Pod可以复用之前的名字,但是会被分配一个新的UID,因此那么些共享的卷也会重新创建(旧数据无法保留)
3.1.2.2 Motivation for pods
通常一个服务由多个功能单元构成,各模块相互协作,而Pod就是这种多协作过程的模型。Pod通过提供一个高阶抽象来简化应用的部署、管理。Pod是部署,水平扩展和复制的最小单元
Pod允许内部的组件共享数据以及相互通信。在一个Pod中的所有组件共享同一个网络Namespace(IP和port),他们之间可以通过localhost相互通信,因此在一个Pod中的所有组件需要共享port,同时,Pod也允许其组件与外部通信
Pod的hostname被设置为Pod的名字
3.1.2.3 Durability of pods (or lack thereof)
Pod并不是一个高可用的实体。Pod不会从调度失败、节点宕机或其他错误中恢复
通常情况下,用户不需要直接创建Pod,而应该使用Controller,Controller提供了一个集群层面上的自我修复能力,以及水平扩容能力和删除能力
Pod对外直接露出,其原因如下
- 提供可插拔式的调度和控制方式
- 支持
Pod-level的操作,而不需要通过Controller API来代理 - 解耦
Pod生命周期与Controller生命周期 - 解耦
Controller和Service - 解耦
Kubelet-level的功能与cluster-level的功能 - 高可用性
3.1.2.4 Termination of Pods
由于Pod代表了集群中一组运行的进程,因此允许Pod优雅地终结是很有必要的。用户需要发出删除指令,需要了解终结时间,需要确保Pod真的被终结了。当用户发出删除Pod的请求时,系统会记录一个宽限期(发出删除请求到被强制清除的时间间隔),然后向Pod中的所有Container发出TERM signal,如果超过宽限期,Pod还未终结,那么会向Pod中的所有Container发出KILL signal,当Pod终结后,它会被API server删除
一个具体的例子
- 用户发出指令删除
Pod,默认的宽限期是30s API server会更新该Pod的状态,并且设定宽限期- 当用户通过命令查看
Pod状态时,该被删除的Pod会显示Terminating状态 Kubelet观测到Pod被标记为Terminating状态,以及宽限期后,就开始终结流程- 如果有
Container定义了preStop hook,那么会运行该钩子方法。如果超过宽限期后,preStop hook方法还在执行,那么步骤2将会被执行,并且会指定一个更小的宽限期(2s) - 向
Container发送TERM信号
- 如果有
Pod被移除服务节点列表。因此,那些终止过程十分缓慢的Pod,在此时也不会继续提供服务Kubelet通过API server将宽限期设置为0来结束删除过程。之后该Pod就对用户彻底不可见了,即彻底被删除了
Kubernetes允许强制删除Pod,强制删除意味着将该Pod从集群状态以及etcd中立即删除。当强制删除执行时,Api Server不会等待kubelet确认删除Pod,而是直接将该Pod删除,这样一来,一个新的复用了原来名字的Pod就可以被立即创建。而那个被删除的Pod仍然会给定一个比较小的宽限期来进行上述删除操作。尽量不要使用这种方式
3.1.3 Pod Lifecycle
3.1.3.1 Pod phase
Pod的status字段是一个PodStatus对象,该对象包含一个phase字段
phase是对Pod生命周期中的状态的高度抽象,仅包含以下几个值
Pending:该Pod已被Kubernetes system接管,但是Container尚未创建完毕。可能处于尚未被调度的状态,或者正在下载容器镜像Running:所有Container已经启动完毕,并且至少有一个Container处于运行状态,或者处于启动或者重启的过程中Succeeded:所有Container成功终止,且不会重启Failed:至少有一个Container终止失败Unkown:系统错误
可以通过如下命令查看phase
1 | kubectl get pod -n <namespace> <pod-name> -o yaml |
3.1.3.2 Pod conditions
Pod的status字段是一个PodStatus对象,该对象包含一个conditions字段,该字段对应的值是一个PodConditions对象的数组
每个PodConditions对象包含如下字段
lastProbeTime:上一次进行状态监测的时刻lastTransitionTime:上一次发生状态变更的时刻message:状态变更的描述,一个human-readable的描述reason:状态变更的原因,一个较为精确的描述status:True、False、Unknown中的一个type:以下几种可能值中的一个PodScheduled:Pod已被调度到一个node上Ready:Pod已经能够提供服务,应该被添加到load balancing pool中去Initialized:所有的Init Container已经执行完毕Unschedulable:调度失败,可能原因是资源不足ContainersReady:Pod中的所有Container已经就绪
3.1.3.3 Container probes
probe是kubelet对Container定期进行的诊断。为了实现诊断,kubelet通过调用一个handler来完成,该handler由容器实现,以下是三种handler的类型
ExecAction:在容器中执行一个命令,当命令执行成功(返回状态码是0)时,诊断成功TCPSocketAction:通过Container的IP以及指定的port来进行TCP检测,当检测到port开启时,诊断成功HTTPGetAction:通过Container的IP以及指定的port来进行HTTP Get检测,当HTTP返回码在200至400之间时,诊断成功
诊断结果如下
SuccessFailureUnknown
kubelet可以对运行状态下的Container进行如下两种probe
livenessProbe:检测Container是否存活(健康检查),若不存活,将杀死这个ContainerreadinessProbe:检测Container是否准备好提供服务,若检查不通过,那么会将这个Pod从service的endpoint列表中移除
我们如何决定该使用livenessProbe还是readinessProbe
- 如果我们的
Container在碰到异常情况时本身就会宕机,那么我们就不需要livenessProbe,kubelet会自动根据restartPolicy采取相应的动作 - 如果我们想要在
probe失败时杀死或者重启Container,那么,我们需要使用livenessProbe,同时将restartPolicy指定为Always或OnFailure模式 - 如果我们想要在
Pod可读时才向其转发网络数据包,那么,我们需要使用readinessProbe - 如果我们的
Container需要读取大量数据,配置文件或者需要在启动时做数据迁移,那么需要readinessProbe - 如果我们仅仅想要避免流量打到被删除的
Pod上来,我们无需使用readinessProbe。在删除过程中,Pod会自动将自己标记为unready状态,无论readinessProbe是否存在
3.1.3.4 Pod readiness gate
为了织入一些回调逻辑或者信号到PodStatsu中来增强Pod readiness的可扩展性,Kubernetes在1.11版本之后引入了一个性特性,称为Pod ready++,我们可以在PodSpec中使用ReadinessGate来增加一些额外的用于判断Pod readiness的条件。如果Kubernetes在status.conditions中没有找到对应于ReadinessGate中声明的条件类型,那么检测结果默认是Flase
1 | Kind: Pod |
3.1.3.5 Restart policy
PodSpec有一个restartPolicy字段,其可选值为Always、OnFailure、Never。默认值为Always。restartPolicy对Pod中的所有Container都会生效。restartPolicy仅针对在同一个Node中重启Container。多次启动之间的时间间隔以指数方式增长(10s、20s、40s…),最多不超过5分钟。在成功重启后10分钟后,时间间隔会恢复默认值
3.1.3.6 Pod lifetime
通常情况下,Pod一旦创建就会永远存在,直至被某人或Controller销毁。唯一例外就是,当Pod的status.phase字段为Succeeded或Failed且超过一段时间后(该时间由terminated-pod-gc-threshold设定),该Pod会被自动销毁
有三种类型的Controller可供选择
- 使用
Job,这类Pod预期会终止,例如batch computations。此时restartPolicy通常设置为OnFailure或Never - 使用
ReplicationController、ReplicaSet、Deployment,这类Pod预期会一直运行,例如web servers。此时restartPolicy通常设置为Always - 使用
DaemonSet,这类Pod通常每台机器都会运行一个
这三种类型的Controller都含有一个PodTemplate。通常,创建一个Controller,然后利用它来创建Pod是最常规的选择,而不是自己创建Pod,因为Pod自身是不具有错误恢复能力的,但是Controller具备该能力
当某个Node宕机或者失联后,Kubernetes会将位于这些Node上的Pod全部标记为Failed
3.1.4 Init Containers
3.1.4.1 Understanding Init Containers
一个Pod中可以运行一个或多个Container,同时,一个Pod中也可以运行一个或多个Init Container(Init Container会优先于Container运行)
Init Container具有如下特性
- 他们总会结束运行,即并不是一个常驻进程
Init Container总是一个接一个地运行,上一个Init Container运行结束后,下一个Init Container才开始运行
如果Init Container执行失败,Kubernetes会重启Pod直至Init Container成功执行(至于Pod是否重启依赖于restartPolicy)
为了将一个Container指定为Init Container,我们需要在PodSpec中添加initContainers字段
Init Container支持所有普通Container的字段,唯独不支持readiness probe,因为Init Container在ready之前已经结束了
3.1.4.2 Detailed behavior
在Pod的启动过程中,在网络以及磁盘初始化后,Init Container以配置的顺序启动。Init Container会一个接一个地启动,且只有前一个启动成功后,后一个才会启动。如果Init Container启动失败,会根据restartPolicy来决定是否重新启动。特别地,如果Pod的restartPolicy被设置为Always,那么对于Init Container而言,就为OnFailure
如果Pod重启(可能仅仅指重新启动container?并不是销毁Pod后再创建一个新的Pod),那么所有的Init Container都会重新执行
3.1.5 Pod Preset
Pod Preset用于在Pod创建时注入一些运行时的依赖项,我们可以使用Label Selector来指定需要注入的Pod
原理:Kubernetes提供了一个准入控制器(PodPreset)。在创建Pod时,系统会执行以下操作:
- 获取所有的
PodPreset - 检查正在创建的
Pod的Label是否匹配某个或某些PodPreset的Label Selector - 将匹配的
PodPreset所指定的资源注入到待创建的Pod中去 - 如果发生错误,抛出一个事件,该事件记录了错误信息,然后以纯净的方式创建
Pod(无视所有PodPreset中的资源) - 修改
Pod的status字段,记录其被PodPreset修改过。描述信息如下podpreset.admission.kubernetes.io/podpreset-<pod-preset name>: "<resource version>".
一个Pod Preset可以应用于多个Pod,同样,一个Pod也可以关联多个Pod Preset
3.1.6 Disruptions
3.1.6.1 Voluntary and Involuntary Disruptions
Pod会一直存在,直到某人或者Controller摧毁它,或者碰到一个无法避免的硬件或者系统问题。我们将这些异常称为involutary disruption,包括
- 硬件错误
- 集群管理员误删VM实例
- 内核错误
- 网络抖动
- 由于资源耗尽而导致
Pod被移出Node
对于其他的情况,我们称之为voluntary disruption,包括
- 删除管理
Pod的Node - 更新了
PodSpec而导致的Pod重启 - 删除
Pod - 将
Node从集群中移出,对其进行维护或升级 - 将
Node从集群中移出,进行缩容
3.1.6.2 Dealing with Disruptions
下列方法可以减轻involuntary disruption造成的影响
- 确保
Pod只拿它需要的资源 - 复制应用,以获得高可用性
- 将应用副本分别部署到不同的区域的节点上,以获得更高的可用性
3.1.6.3 How Disruption Budgets Work
应用Owner可以为每个应用创建一个PodDisruptionBudget(PDB)对象。PDB限制了应用同时缩容的最大数量,即保证应用在任何时候都有一定数量的Pod在运行
当集群管理员利用kubectl drains命令将某个Node移除时,Kubernetes会尝试移除该Node上的所有Pod,但是这个移除请求可能会被拒绝,然后Kubernetes会周期性的重试,直至所有Pod都被终结或者超过配置的时间(超过后,直接发送KILL signal)
PDB无法阻止involuntary disruptions。Pod由于灰度升级造成的voluntary disruption可以被PDB管控。但是Controller灰度升级不会被PDB管控
3.1.7 参考
3.2 Controller
3.2.1 ReplicaSet
ReplicaSet是新一代的Replication Controller,ReplicaSet与Replication Controller之间的唯一区别就是select的方式不同。ReplicaSet支持set-based selector,而Replication Controller仅支持equality-based selector
3.2.1.1 How to use a ReplicaSet
大部分支持Replication Controller的kubectl命令都支持ReplicaSet,其中一个例外就是rolling-update命令。如果我们想要进行灰度升级,更推荐使用Deploymenet
尽管ReplicaSet可以独立使用,但到目前为止,它主要的用途就是为Deployment提供一种机制—编排Pod创建、删除、更新
3.2.1.2 When to use a ReplicaSet
ReplicaSet保证了在任何时候,都运行着指定数量的Pod副本。然而,Deployment是一个更高阶的概念,它管理着ReplicaSet、提供声明式的Pod升级方式,以及一些其他的特性。因此,推荐使用Deployment而不是直接使用ReplicaSet,除非我们要使用自定义的升级策略或者根本不需要升级
3.2.1.3 Writing a ReplicaSet manifest
示例
1 | apiVersion: apps/v1 |
与其他Kubernetes Object相同,ReplicaSet同样需要apiVersion、kind、metadata三个字段。除此之外,还需要以下字段
.spec.template: 该字段是.spec字段的唯一要求的字段,.spec.template描述了一个Pod Template,其格式与Pod几乎完全一致,除了不需要apiVersion、kind这两个字段.spec.selector:ReplicaSet会管理所有匹配该Selector的Pod。注意到ReplicaSet并不会区分由它创建或删除的Pod与其他人或过程创建或删除的Pod,因此,我们可以替换掉ReplicaSet,而不会影响到正在执行的Pod,它们仍然会被这个新的ReplicaSet所管理。此外,.spec.template.metadata.labels必须与.spec.selector匹配,否则会被API拒绝.metadata.labels:ReplicaSet还允许拥有自己的Label,通常来说,.spec.template.metadata.labels与.metadata.labels是一致的。同样,它们也可以不一致,但要注意的是,.metadata.labels与.spec.selector无关.spec.replicas: 该字段指定了Pod副本的数量,默认为1
3.2.1.4 Working with ReplicaSets
3.2.1.4.1 Deleting a ReplicaSet and its Pods
如果我们要删除ReplicaSet以及所有相关的Pod,我们只需要使用kubectl delete来删除ReplicaSet。Garbage Controller默认会自动删除所有相关的Pod
3.2.1.4.2 Deleting just a ReplicaSet
如果我们仅仅要删除ReplicaSet,那么需要在kubectl delete命令加上--cascade=false参数
一旦ReplicaSet被删除后,我们就可以创建一个新的ReplicaSet,如果新的ReplicaSet名字与原来的相同,那么它将会接管之前由原来的ReplicaSet创建的Pod。尽管如此,它不会要求已存在的Pod来满足新的Pod Template。如果要更新Pod使其匹配新的Spec,那么需要使用Rolling Update
3.2.1.4.3 Isolating Pods from a ReplicaSet
我们可以通过改变Pod的Label来将其与ReplicaSet分离(通常用于分离那些用于Debug、Data recovery的Pod),通过这种方式移除Pod后,新的Pod随之会被创建出来
3.2.1.4.4 Scaling a ReplicaSet
我们可以简单的修改ReplicaSet的.spec.replicas字段来进行扩容或缩容。ReplicaSet Controller会保证Pod的数量与ReplicaSet保持一致
3.2.1.4.5 ReplicaSet as a Horizontal Pod Autoscaler Target
ReplicaSet也可以是Horizontal Pod Autoscalers(HPA)的目标。也就是说,HPA可以自动缩放ReplicaSet
1 | apiVersion: autoscaling/v1 |
3.2.1.5 Alternatives to ReplicaSet
3.2.1.5.1 Deployment(recommended)
Deployment是一个Kubernetes Object,它可以包含ReplicaSet,并且可以更新ReplicaSet以及相关的Pod。尽管ReplicaSet可以独立使用,但是通常ReplicaSet都作为Deployment的一种机制来组织Pod的创建、删除和更新。当我们使用Deployment时,ReplicaSet的创建完全由Deployment来管控
3.2.1.5.2 Bare Pods
与直接创建Pod不同,ReplicaSet会在Pod删除或者不可用时创建新的Pod来替换原有的Pod,例如Node宕机,或者进行破坏性的维护,例如内核升级。即便我们的应用只需要一个Pod,也应该使用ReplicaSet而不是直接管理Pod
3.2.1.5.3 Job
对于预期会终止的Pod而言,推荐使用Job而不是ReplicaSet
3.2.1.5.4 DaemonSet
DaemonSet可以提供机器级别的功能,例如机器监控,机器日志等。这些Pod有着与机器强相关的生命周期,且优先于其他普通Pod运行。当机器重启或者关机时,可以安全地终止这些Pod
3.2.1.5.5 ReplicationController
ReplicaSet可以看做是新一代的ReplicationController,他们有着相同的使命,且行为相同。此外,ReplicationController不支持set-based Selector
3.2.2 ReplicationController
ReplicationController确保:在任何时候,应用都运行着一定数量的副本
3.2.2.1 How a ReplicationController Works
如果Pod过多,ReplicationController会停止多余的Pod。如果Pod过少,ReplicationController会启动更多的Pod。与人工创建的Pod不同,如果Pod终结了,或者被删除了,那么ReplicationController重新启动一个新的Pod来代替它
在Kubernetes中,我们用缩写rc或rcs来表示ReplicationController
3.2.2.2 Writing a ReplicationController Spec
1 | apiVersion: v1 |
与其他Kubernetes Config类似,ReplicationController包含apiVersion、kind、metadata以及spec这四个字段
.spec.template: 该字段是.spec字段的唯一要求的字段。该字段描述的是一个Pod Template,它拥有与Pod几乎完全一样的schema(没有apiVersion与kind)。除此之外,必须制定Label以及Restart Policy(默认是Always).metadata.labels: 通常该字段的值与.spec.template.metadata.labels一致。如果.metadata.labels未设置,那么其值默认与.spec.template.metadata.labels相同。尽管如此,这两个字段的值可以不同,但是.metadata.labels不影响ReplicationController的行为.spec.selector: 该字段定义了一个Label Selector,ReplicationController会管理所有与该Label Selector匹配的Pod(无论该Pod是否由ReplicationController创建,因此要特别注意重叠问题),这就允许在Pod运行时替换ReplicationController。如果指定了该字段,那么.spec.template.metadata.labels与.spec.selector的值必须相同,否则会被Api Server拒绝,若.spec.selector未指定,那么默认与.spec.template.metadata.labels相同.spec.replicas: 指定同时运行的副本数量,默认为1
3.2.2.3 Working with ReplicationControllers
3.2.2.3.1 Deleting a ReplicationController and its Pods
若要删除一个ReplicationController以及相关联的Pod,那么使用kubectl delete命令,kubectl会负责删除所有相关的Pod
3.2.2.3.2 Deleting just a ReplicationController
若仅仅要删除ReplicationController,那么在使用kubectl delete命令时,需要加上--cascade=false选项。当ReplicationController被删除后,我们便可以创建一个新的ReplicationController,若新旧ReplicationController的.spec.selector也相同的话,那么新的ReplicationController会接管先前的Pod,且不会产生影响(即便Pod Template不同)。若要更新Pod使其匹配新的Pod Template,那么需要使用Rolling Update
3.2.2.3.3 Isolating pods from a ReplicationController
我们可以通过改变Pod的Label来将其与ReplicationController分离,这种方式通常用于分离那些用于Debug或Data Recovery的Pod,移除后,ReplicationController会重新补足Pod
3.2.2.4 Common usage patterns
3.2.2.4.1 Rescheduling
ReplicationController会保证运行一定数量的副本
3.2.2.4.2 Scaling
我们可以通过修改replicas字段来进行扩容和缩容
3.2.2.4.3 Rolling updates
ReplicationController旨在通过逐个替换Pod来对Service进行滚动更新
建议的方法是创建一个具有1个副本的新ReplicationController,逐个扩展新的(+1)和旧的(-1)ReplicationController,然后在旧的ReplicationController达到0个副本后删除它
ReplicationController需要考虑到应用的准备情况,且保证在任意时刻都运行着一定数量的副本。因此这两个ReplicationController创建的Pod的Label需要有区分度,例如image tage的差异
我们可以通过kubectl rolling-update命令来进行滚动更新
3.2.2.4.4 Multiple release tracks
在进行滚动升级时,可能同时运行着多个不同的版本,且通常会持续一段时间,我们要对这多个不同版本进行追踪,追踪将依据Label来进行区分
举例来说,最初一个Service中的所有Pod(10个),其Label都是tier in (frontend), environment in (prod)。此时,我们需要引入一个新的版本canary。我们可以创建一个ReplicationController,将其副本数量设定为9,且Label为tier=frontend, environment=prod, track=stable;另一个ReplicationController,将其副本数量设定为1,Label为tier=frontend, environment=prod, track=canary。于是该Service包含了canary以及non-canary两部分
3.2.2.4.5 Using ReplicationControllers with Services
同一个Service可以有多个不同的ReplicationController,这样一来,流量可以根据版本进行分流
ReplicationController不会自我终结,但是它的生命周期与Service不同。一个Service包含了由不同ReplicationController创建的Pod,且在一个Service的生命中期中可能会有很多ReplicationController被创建和销毁,这些对于Client来说是不感知的
3.2.2.5 Writing programs for Replication
由ReplicationController创建的Pod是可替换的,且在语义上是等价的,尽管随着时间的推移,它们会产生一些差异性。显然,这种特性非常适用于无状态的微服务架构。但是ReplicationController同样可以保持有状态服务架构的高可用性,例如master-elected、shared、worker-pool架构的应用。这些应用需要使用动态的分配机制,而不是静态的一次性的配置。这些动态分配的动作应该由另一个控制器来完成(该控制器是应用的一部分)而不是由ReplicationController来完成
3.2.2.6 Responsibilities of the ReplicationController
ReplicationController仅确保Pod保持额定的数量。在未来,可能会在Replacement Policy上增加更多的控制,同时引入可供外部用户使用的事件,用来处理更为复杂的Replacement
ReplicationController的责任仅限于此,ReplicationController自身并不会引入Readiness Probe或Liveness Probe。它通过外部缩放控制器来修改replicas字段,而不是提供自动缩放的机制。ReplicationController不会引入Scheduling Policy
3.2.2.7 API Object
ReplicationController是一个顶层的Kubernetes Rest API
3.2.2.8 Alternatives to ReplicationController
3.2.2.8.1 ReplicaSet
ReplicaSet可以看做是下一代的ReplicationController。ReplicaSet支持set-based Label Selector。ReplicaSet作为Deployment的一种机制来组织Pod的创建、删除和更新。我们强烈推荐使用Deployement而不是直接使用ReplicaSet
3.2.2.8.2 Deployment(Recommended)
Deployment是一种高阶的API Object,用于以一种非常简单的方式更新ReplicaSet以及Pod。Deployment具有Rolling Update的能力,且它是声明式的,服务级别的,且拥有额外的功能
3.2.2.8.3 Bare Pods
与直接创建Pod不同,ReplicationController会在Pod删除或者不可用时创建新的Pod来替换原有的Pod,例如Node宕机,或者进行破坏性的维护,例如内核升级。即便我们的应用只需要一个Pod,也应该使用ReplicationController而不是直接管理Pod
3.2.2.8.4 Job
对于预期会终止的Pod而言,推荐使用Job而不是ReplicationController
3.2.2.8.5 DaemonSet
DaemonSet可以提供机器级别的功能,例如机器监控,机器日志等。这些Pod有着与机器强相关的生命周期,且优先于其他普通Pod运行。当机器重启或者关机时,可以安全地终止这些Pod
3.2.3 Deployments
Deployment提供了一种声明式的更新Pod或ReplicaSet的方式
3.2.3.1 Creating a Deployment
1 | apiVersion: apps/v1 |
- 通过
.metadata.name字段来指定Deployment的名字 - 通过
.spec.replicas字段来指定副本数量 - 通过
.sepc.selector字段来指定匹配何种标签的Pod - 通过
.spec.template字段来描述一个Pod Template
1 | # create deployment |
3.2.3.2 Updating a Deployment
Deployment会保证同时只有一小部分的Pod处于升级的过程中(可能会暂时无法提供服务),最多25%
Deployment会保证同时只有一小部分的Pod处于创建过程中,最多25%
Deployment不建议更新Label Selector,这意味着,我们最初就需要定义好Label Selector。但Deployment仍允许我们更新Label Selector
- 增加
Label Selector,那么Deployment要求Pod Template的Label必须匹配Label Selector。这个操作是非重叠的,意味着所有旧有的ReplicaSet以及Pod将会被孤立,新的ReplicaSet以及Pod会被创建出来 - 修改
Label Selector,会导致增加Label Selector相同的结果 - 删除
Label Selector中的key,不需要修改Pod Template的Label。现有的ReplicaSet不会被孤立,新的ReplicaSet不会被创建
3.2.3.3 Rolling Back a Deployment
有时候,我们会想要进行回滚,比如新版本不够稳定,或者出现了很严重的错误。Deployment允许我们回滚到任意一次版本
注意到,只有在Deployment rollout触发时,才会创建revision,这意味着,当且仅当Pod Template发生变化时(例如修改Label或者镜像),才会创建revision。其他的更新,例如进行缩容或者扩容,不会创建revision。这意味着回滚到一个早期的版本,回滚的仅仅是Pod Template
1 | # check the revisions of this deployment |
3.2.3.4 Scaling a Deployment
1 | # scale a deployment |
3.2.3.5 Pausing and Resuming a Deployment
我们可以暂停一个Deployment,然后进行一些更新操作,再还原该Deployment
1 | # pause deployment |
3.2.3.6 Deployment Status
Deployment在生命周期中会经历多个不同的状态
progressingcompletefailed
progressing
- 正在创建
ReplicaSet - 正在扩容
- 正在缩容
complete
- 所有副本都更新到期望的版本了
- 所有副本都可用了
- 没有正在运行的旧版本的副本
failed
- 配额不足
Readiness Probe失败了- 拉取镜像失败
- 权限不足
- 应用配置有问题
3.2.3.7 Clean up Policy
我们可以通过设置.spec.revisionHistoryLimit来控制Deployment保留多少个历史版本,默认是10,超过该数值的ReplicaSet会被回收
3.2.3.8 Writing a Deployment Spec
与其他Kubernetes Config类似,Deploymenet必须包含apiVersion、kind、metadata、spec四个字段
Pod Template
.spec.template:.spec的唯一必须的字段,它描述了一个Pod Template,Pod Tempalte的schema与Pod几乎完全一致(不需要apiVersion和kind)Pod Template必须指定Label以及Restart Policy,其中.spec.template.spec.restartPolicy只允许设置成Always,默认就是Always
Replicas
.spec.replicas: 指定副本数量,默认1
Selector
.spec.selector: 定义了一个Label Selector.spec.selector与.spec.template.metadata.labels必须匹配,否则会被拒绝
Strategy
.spec.strategy: 定义了新老Pod更替的策略,可选项有Recreate、RollingUpdate,默认是RollingUpdateRecreate在更新时,旧的Pod全部被终结后,新的Pod才会创建RollingUpdate: 灰度更新,仅允许一小部分的Pod进行更替,始终保持服务的可用状态
3.2.3.9 Alternative to Deployments
使用kubectl rolling update来滚动升级Pod和ReplicationController与Deployment是类似的。但是Deployment是更推荐的方式,因为它是声明式的,服务级别的,未来可能会有新的功能
3.2.4 StatefulSets
与Deployment相同,StagefulSet管理基于相同容器规范的Pod。与Deployment不同,StagefulSet为每个Pod都生成一个唯一且不可变的标志符,这些标志符全局唯一
3.2.4.1 Using StatefulSets
StagefulSet有如下特点
- 稳定,唯一的网络标志
- 稳定的持久化存储
- 有序且优雅的部署以及扩缩容
- 有序自动的滚动更新
3.2.4.2 Limitations
3.2.4.3 Components
3.2.4.4 Pod Selector
3.2.4.5 Pod Indentity
3.2.4.6 Deployment and Scaling Guarantees
3.2.4.7 Update Strategies
3.2.5 DaemonSet
3.2.6 Garbage Collection
3.2.7 TTL Controller for Finished Resources
3.2.8 Jobs - Run to Completion
3.2.9 CronJob
4 Services, Load Balancing and Networking
4.1 Services
Pod是无法再生的。ReplicaSet可以动态地创建或删除Pod,每个Pod都会分配一个IP,显然随着Pod的新老更替,这些IP是不固定的。这就导致了一个问题,如果一个Pod提供了某种服务给其他位于同一集群中的Pod,那么这些Pod如何找到服务提供方呢
Service的引入解决了这个问题,Service是一组Pod以及他们访问方式的抽象。Service通过Label Selector来匹配对应的Pod。Service解耦了Consumer和Provider(从这个角度来说,Service与RPC框架解决了类似的问题)
4.1.1 Defining a service
与Pod类似,Service也是一个Rest Object,可以通过Api Server来创建实例,例如
1 | kind: Service |
通过上面这份配置,会创建一个名为my-service,该Service会将80端口的流量路由到任意包含标签app=MyApp的Pod的9376端口
每个Service都会被分配一个Cluster IP,Service Proxy会用到这个Cluster IP,Service的Label Selector匹配会持续进行,其结果过会同步到同名的Endpoint,Endpoint维护了Service与Pod的映射关系
Service可以将一个入口端口映射成任意targetPort,targetPort默认与port相同,此外targetPort还可以是一个字符串,指代端口的名称,不同的Pod包含的端口名与端口的映射关系可以不同,这提供了非常多的灵活性
Service支持TCP、UDP、SCTP协议,默认是TCP协议
4.1.1.1 Services without selectors
Service通常抽象了访问Pod的方式,但是它也可以抽象其他后端实体的访问方式,例如
- 在生产环境以及测试环境中使用的
database是不同的 - 我们想将
Service暴露给另一个Namespace或者另一个集群 - 应用的多分实例中,一部分部署在
Kubernetes集群中,另一部分部署在Kubernetes集群外
在以上这些情况中,我们可以定义一个没有Label Selector的Service,如下
1 | kind: Service |
由于这个Service没有配置Label Selector,因此不会有Endpoint对象生成。但是,我们可以手动配置Endpoint,如下
1 | kind: Endpoints |
在无Label Selector的场景下,Service的工作方式还是一样的。流量会被路由到Endpoint中
ExternalName Service是无Label Selector的,且使用的是DNS
4.1.2 Virtual IPs and service proxies
每个Node都运行着kube-proxy这个组件。kube-proxy为除了ExternalName类型之外的Service提供了一种虚拟IP
4.1.2.1 Proxy-mode: userspace
- 该模式最主要的特征是:流量重定向工作是由
kube-proxy完成的,也就是在用户空间完成的 kube-proxy会监听Service的创建和删除,当发现新的Service创建出来后,kube-proxy会在localhost网络开启一个随机端口(记为loPort)进行监听,同时向iptable写入路由规则(Cluster IP:Port->localhost:loPort),即将流向Service的流量转发到本地监听的端口上来kube-proxy会监听Endpoint的变更,并将Service及其对应的Pod列表保存起来

在Pod中访问Service的时序图如下

4.1.2.2 Proxy-mode: iptables
- 该模式最主要的特征是:流量重定向的工作是由
iptable完成的,也就是在内核空间完成的 kube-proxy会监听Service、Endpoint的变化,并且更新iptable的路由表- 更高效、安全,但是灵活性较差(当某个
Pod没有应答时,不会尝试其他Pod)

在Pod中访问Service的时序图如下

4.1.2.3 Proxy-mode: ipvs
与iptable模式类似,ipvs也是利用netfilter的hook function来实现的,但是ipvs利用的是哈希表,且工作在内核空间,因此效率非常高,同时ipvs还支持多种负载均衡算法
rr: round-roginlc: least connectiondh: destination hashingsh: source hashingsed: shortest expected delaynq: never queue

在以上任何一种模式中,来自Cluster IP:Port的流量都会被重定向到其中一个后端Pod中,且用户不感知这些过程
4.1.3 Multi-Port Services
很多Service需要暴露多个端口。Kubernetes支持一个Service暴露多个端口,在这种方式下,我们必须为每个端口定义一个端口名(端口名只允许包含数字、小写字母以及-,且必须以数字或小写字母开头和记为)
1 | kind: Service |
4.1.4 Choosing your own IP address
我们可以通过.spec.clusterIP字段为Service分配静态的Cluster IP。该IP必须是一个合法的Cluster IP,否则会被Api Server拒绝(返回422错误码)
4.1.5 Discovering services
Kubernetes提供了两种服务发现的方式
Environment VariablesDNS
4.1.5.1 Environment Variables
kubelet会为每个Service设置一系列的环境变量,格式为<SERVICE_NAME>_<VARIABLE_NAME>,服务名和变量名都会被转成大写+下划线的方式
这种方式会引入顺序的问题,如果Pod想要访问一个Service,那么这个Service必须优先于Pod创建
4.1.5.2 DNS
DNS Server会监听Service的创建,并为其创建DNS Record,如此一来,Pod就可以通过服务名来访问服务了
举个例子,如果我们有一个Service,起名字为my-service,其对应的Namesapce为my-ns,那么DNS Server会为这个Service创建一个my-service.my-ns的记录。所有在my-ns下的Pod可以通过服务名来访问,即my-service;对于在其他Namespace下的Pod必须通过my-service.my-ns来访问
4.1.6 Headless services
有时候,我们不需要负载均衡,也不需要Service IP,我们可以通过.spec.clusterIP = None来进行配置。这种方式允许开发者与Kubernetes的服务发现机制解耦,允许开发者使用其他的服务发现机制
在这种模式下,Service不会被分配Cluster IP,kube-proxy也不会处理这些Service
如果该模式的Service包含Selector,Endpoint Controller会创建Endpoint来记录这个Service,并且会修改DNS记录(ServiceName->Backend Pod IP)
如果该模式的Service不包含Selector,那么Endpoint Controller不会为Service创建任何Endponit
4.1.7 Publishing services - service types
有时候,我们的服务需要对外暴露(不仅仅对其他Pod提供服务,而是对整个Internet提供服务),Kubernetes允许我们为Service指定ServiceType,默认的类型是ClusterIP,所有的可选类型如下
ClusterIP: 通过Cluster IP暴露该Service,意味着只有在集群内才能访问这个Service。这是默认的类型NodePort: 通过NodePort暴露该Service,即在集群中所有Node上都分配一个静态的端口。在该类型下,会自动为Service创建Cluster IP用于路由,我们也可以从外部通过<NodeIP>:<NodePort>来访问这个ServiceLoadBalancer: 通过Load Balancer对外暴露该Service。在该类型下,会自动为Service创建Cluster IP以及NodePort用于路由ExternalName: 通过CNAME暴露该服务,将服务映射到externalName字段对应的域名中,完全由DNS负责路由
4.1.7.1 Type NodePort
对于这种模式的Service,集群中所有的Node都会代理该相同的Port,该端口号对应于Service的.spec.ports[*].nodePort配置项
我们可以通过--nodeport-addresses选项来指定一个或一组IP的范围(多个的话,以,分隔),该选项的默认是是空[],意味着最大的IP范围
我们可以通过nodePort来指定暴露的Port,因此我们需要注意端口冲突的问题,且必须属于合法的NodePort范围
这种方式给予了开发者更多的自由度,允许配置自己的负载均衡服务,允许在精简版的Kubernetes环境中使用Service,允许我们直接暴露Node的IP来使用Service
服务可以通过<NodeIP>:spec.ports[*].nodePort或者.spec.clusterIP:spec.ports[*].port两种方式进行访问
4.1.7.2 Type LoadBalancer
对于提供负载均衡服务的云环境,我们可以将Service指定为LoadBalancer类型,Kubernetes会为Service创建LoadBalancer,事实上,LoadBalancer的创建过程与Service的创建过程是异步的。当LoadBalancer发布后,会更新Service的.status.loadBalancer字段
1 | kind: Service |
LoadBalancer接收到来自外部的流量后,会直接路由到提供服务的Pod,具体方式依赖于云服务提供商的实现。一些云服务提供商允许指定loadBalancerIP,在这种情况下会以配置的IP来创建LoadBalancer,若loadBalancerIP未配置,则会分配一个随机的IP。如果云服务商不提供这个功能,那么这个字段将会被忽略
4.1.8 The gory details of virtual IPs
本小节将介绍Service的一些细节问题
4.1.8.1 Avoiding collisions
Kubernetes的哲学之一就是尽量避免用户因为自身以外的因素,导致应用无法正常工作。对于端口而言,用户自己选择端口号,将会有一定概率导致冲突,因此,Kubernetes为用户自动分配端口号
Kubernetes确保每个Service分配到的IP在集群中是唯一的。具体做法是,Kubernetes会在etcd中维护一个全局的分配映射表
4.1.8.2 IPs and VIPs
Pod IP通常可以定位到一个确定的Pod,但是Service的Cluster IP(Virtual IP, VIP)通常映射为一组Pod,因此,Kubernetes利用iptables将Cluster IP进行重定向。因此,所有导入VIP的流量都会自动路由到一个或一组Endpoint中去。Service的环境变量和DNS实际上是根据服务的VIP和端口填充的
Kubernetes支持三种不同的模式,分别是userspace、iptables、ipvs,这三者之间有微小的差异
4.2 DNS for Services and Pods
4.2.1 Introduction
每个Service都会分配一个DNS Name。通常情况下,一个Pod的DNS搜索范围包括Pod所在的Namespace以及集群的默认domain。举例来说,Namspace bar中包含Service foo,一个运行在Namspace bar中的Pod可以通过foo来搜索这个Service,一个运行在Namspace quux中的Pod可以通过foo.bar来搜索这个Service
4.2.2 Services
4.2.2.1 A Records
Pod会被分配一个A Record,其格式为<pod-ip-address>.<my-namespace>.pod.cluster.local- 例如一个
Pod,其IP为1.2.3.4,其Namespace为default,且DNS Name为cluster.locals,那么对应的A Record为1-2-3-4.default.pod.cluster.local
4.2.3 Pods
4.2.3.1 Pod’s hostname and subdomain fields
- 当一个
Pod创建时,它的hostname就是metadata.name的值 Pod还可以指定spec.hostname,若spec.hostname与metadata.name同时存在时,以spec.hostname为准Pod还可以指定spec.subdomain。例如,若一个Pod,其spec.hostname为foo,spec.subdomain为bar,Namespace为my-namespace,则对应的FQDN为foo.bar.my-namespace.pod.cluster.local
1 | apiVersion: v1 |
4.2.3.2 Pod’s DNS Policy
可以基于每个Pod设置DNS Policy。目前,Kubernetes支持以下几种DNS Policy
Default: 从Node中继承DNS配置ClusterFirst: 任何不匹配集群域名后缀的DNS Query都会转发到从Node中继承而来的上游DNS服务器ClusterFirstWithHostNet: 若Pod以hostNetwork模式运行,那么DNS必须设置为ClusterFirstWithHostNetNone: 忽略Kubernetes的DNS Policy,同时依赖spec.dnsConfig提供更细粒度的配置
1 | apiVersion: v1 |
4.2.3.3 Pod’s DNS Config
Kubernetes在v1.9版本后允许用户进行更细粒度的DNS配置,需要通过--feature-gates=CustomPodDNS=true选项来开启该功能。开启功能后,我们就可以将spec.dnsPolicy字段设置为None,并且新增一个字段dnsConfig,来进行更细粒度的配置
dnsConfig支持以下几项配置
nameservers:DNS服务器列表,最多可以设置3个,最少包含一个searches:DNS Search Domain列表,最多支持6个options: 一些键值对的列表,每个键值对必须包含Key,但是Value可以没有
1 | apiVersion: v1 |
4.3 Connecting Applications with Services
在讨论Kubernetes的网络通信之前,我们先对比一下Docker的常规网络通信方式
默认情况下,Docker使用的是host-private网络,因此,只有处于同一个机器上的不同Container之间才可以通信。因此要想跨Node进行通信,那么必须为Container所在的机器分配IP用以代理该Container,这样一来就必须处理IP以及Port冲突的问题
在不同的开发者之间进行Port的统一分配是一件非常困难的事情,并且会增加扩容/缩容的复杂度。Kubernetes首先假设Pod可以与其他Pod进行通信,且无视他们所属的Node,Kubernetes会为每个Pod分配一个cluster-private-IP,且我们无需处理这些映射关系。这意味着,位于同一个Node上的Pod自然可以通过localhost进行通信,位于不同Node上的Pod无需使用NAT也可以进行通信,下面将详细介绍Kubernetes的实现方式
4.3.1 Exposing pods to the cluster
下面,我们用一个Nginx Pod作为例子,进行介绍
1 | apiVersion: apps/v1 |
下面创建一个Deployment Object
1 | # 创建 Deployment |
注意到,这些Pod并没有用附属Node的80端口,也没有配置任何NAT规则来路由流量,这意味着,我们可以在同一个Node上部署多个Pod,并且利用IP来访问这些Pod
登录Pod的命令如下
1 | kubectl exec -it <pod-name> -n <namespace> -- bash |
4.3.2 Create a Service
理论上,我们可以直接使用这些Pod的IP来与之通信,但是一旦Node挂了之后,又会被Deployment部署到其他健康的Node中,并分配一个新的Pod IP,因此,会带来非常大的复杂度
Serivce抽象了一组功能相同的Pod。每个Service在创建之初就会被分配一个独有的IP,称为Cluster IP,该IP在Service的生命周期中保持不变,进入Service的流量会通过负载均衡后,路由到其中一个Pod上
接着上面的例子,我们可以通过kubectl expose来创建一个Service
1 | # 创建service |
kubectl expose等价于kubectl create -f <如下配置文件>
1 | apiVersion: v1 |
根据上面的定义,该Serivce会代理所有匹配run: my-nginx的Pod。其中port是Serivce的流量入口端口;targetPort是Pod的流量入口端口,默认与port相同
这些Pod通过Endpoint露出,Service会持续筛选匹配Selector的Pod,并将结果输送到与Pod同名的Endpoint对象中。当一个Pod挂了之后,它会自动从Endpoint中被移除,新的Pod随即会被创建,并添加到Endpoint中
4.3.3 Accessing the Service
Kubernetes提供了两种服务发现的方式:Environment Variables以及DNS
4.3.3.1 Environment Variables
当Pod运行在Node之后,kubectl会为每个Service设置一些环境变量。这种方式会引入顺序问题
首先,我们查看一下现有Pod的环境变量
1 | kubectl exec <pod name> -- printenv | grep SERVICE |
可以看到,这里没有我们创建的Service的相关信息,这是因为我们在创建Service之前,首先创建了Pod。另一个弊端是,Scheduler可能会将上述两个Pod部署到同一个Node中,这会导致整个Service不可用,我们可以通过杀死这两个Pod并等待Deployment重新创建两个新的Pod来修复这个问题
1 | # 杀死现有的Pod,并创建新的Pod |
4.3.3.2 DNS
Kubernetes提供了一个DNS cluster addon Service,它会为每个Service分配一个DNS Name,我们可以通过如下命令查看
1 | kubectl get services kube-dns --namespace=kube-system |
在集群中的任何Pod都可以用标准的方式来访问Service,我们运行另一个curl应用来进行测试
1 | # 以交互的方式运行一个 container |
4.3.4 Securing the Service
对于需要对外露出的Service,我们可以为其添加TLS/SSL
1 | #create a public private key pair |
下面创建一个Secret,配置如下
1 | apiVersion: "v1" |
1 | kubectl create -f nginxsecrets.yaml |
现在需要替换掉之前的nginx服务,配置如下
1 | apiVersion: v1 |
上述的配置清单包括
Deployment以及Servicenginx暴露了80以及443端口,Service露出了这两个端口,分别是8080以及443端口Container通过挂载到/etc/nginx/ssl上的卷来获取secret key
利用上述配置,替换原先的nginx
1 | kubectl delete deployments,svc my-nginx; kubectl create -f ./nginx-secure-app.yaml |
于是我们就能通过Service来访问Nginx Server了
1 | # 查询Server的Cluster Ip |
1 | apiVersion: apps/v1 |
1 | # 创建另一个curl pod |
4.3.5 Exposing the Service(未完成)
如果我们的应用想要对外露出,Kubernetes提供了两种方式,即NodePort以及LoadBalancer,上面的例子中,使用的是NodePort方式,因此如果Node本身就有Public IP,那么就可以对外提供服务了
1 | # 查看nodePort |
4.4 Ingress
Ingress用于管理Service的访问方式(通常是HTTP)
Ingress可以提供Load Balancing、SSL Termination以及Virtual Host等服务
4.4.1 Terminology
涉及到的相关术语
Node:Kubernetes集群中的虚拟机或者物理机Cluster: 由一组Node组成,通常它们由Kubernetes进行管理Edge Router: 用于执行防火墙策略的路由器,通常形态是云服务商提供的网关或者是一个硬件Cluster Network: 用于进群内通信的网络基础设施Service: 定义了一组满足特定Label Selector的Pod,Serivce含有一个仅在集群内有效的Virtual IP
4.4.2 What is Ingress?
Ingress定义从Internet到Service的路由规则,因此Ingress可以控制外来访问流量
Ingress通常包含LoadBalancer、Edge Router以及一些其他用于处理流量的组件
Ingress不露出任何协议以及端口,要想暴露Service而不是HTTP/HTTPS的话,应该使用Service.Type(设置成NodePort或者LoadBalancer方式)
4.4.3 Ingress controllers
为了使得Ingress能够正常工作,必须要在集群运行一个Ingress Controller,该Ingress Controller与其他Controller不同,它不属于kube-controller-manager的一部分,且不会自动启动
4.4.4 The Ingress Resource
1 | apiVersion: extensions/v1beta1 |
与其他Kubernetes Object相同,Ingress需要apiVersion、kind、metadata三个字段
每个HTTP Rule都包含了如下的信息
host: 匹配指定的hostpath: 匹配指定的path,每个path都包含了一个后端的serviceName以及servicePortbackend: 任何匹配host以及path的请求,都会被路由到backend对应的Service中
如果一个Ingress没有配置任何的rule,那么所有流量都会被路由到一个default backend;如果流量不匹配任何的host以及path,那么该流量也会被路由到default backend
default backend可以在Ingress Controller中进行配置
4.4.5 Types of Ingress
4.4.5.1 Single Service Ingress
一个Ingress只对应了一个后端的Service
1 | apiVersion: extensions/v1beta1 |
4.4.5.2 Simple fanout
一个Ingress对应着多个Service
1 | foo.bar.com -> 178.91.123.132 -> / foo service1:4200 |
1 | apiVersion: extensions/v1beta1 |
4.4.5.3 Name based virtual hosting
该类型常用于将多个Service通过同一个IP暴露出去,且对外的域名是不同的
1 | foo.bar.com --| |-> foo.bar.com s1:80 |
1 | apiVersion: extensions/v1beta1 |
4.4.5.4 TLS
我们可以在Ingress之上增加TSL/SSL协议
1 | apiVersion: v1 |
1 | apiVersion: extensions/v1beta1 |
4.4.5.5 Loadbalancing
一个Ingress Controller通常支持一些负载均衡的设置,包括负载均衡算法、权重策略等,目前尚不支持一些负载均衡的高级配置
4.4.6 Updating an Ingress
1 | kubectl edit ingress test |
4.5 Ingress Controller
为了使得Ingress能够生效,我们必须运行一个Ingress Controller。与其他Controller不同,Ingress Controller不会默认启动
4.5.1 Additional controllers
Ingress Controller有许多不同的实现
AmbassadorAppsCode IncContourCitrixF5 NetworksGlooHAProxyIstioKongNGINX, IncTraefik
4.6 Network Policies
Network Policy定义了Pod之间或者Pod与其他Endpoint之间的通信方式
4.6.1 Isolated and Non-isolated Pods
默认情况下,Pod都是non-isolated,意味着,它可以接收来自任何源的流量
当Pod匹配某个NetworkPolicy后,它就变成isolated的了,于是,它会拒绝所有不满足NetworkPolicy规则的流量
4.6.2 The NetworkPolicy Resource
1 | apiVersion: networking.k8s.io/v1 |
- 与其他
Kubernetes Object相同,NetworkPolicy需要apiVersion、Kind、metadata三个字段 spec: 描述NetworkPolicy的最主要的字段spec.podSelector: 用于匹配Pod的Selector。一个空的podSelector会选择当前Namespace下的所有Podspec.policyTypes: 可以是Ingress、Egress或者两者。默认情况下,会包含Ingress,且如果包含任何Egress规则,那么也会包含Egress-
ingress: 每个NetworkPolicy都包含了一个ingress rule列表,每项规则包含from以及ports两项。其类型可以是ipBlock、namespaceSelector或者podSelector -
egress: 每个NetworkPolicy都包含另一个egress rule列表,每项规则包含to以及ports两项
-
4.6.3 Behavior of to and from selectors
igress的from部分与egress的to部分可以包含如下四种类型
podSelector: 在NetworkPolicy所在的Namespace下选择特定的PodnamespaceSelector: 选择特定的Namespace下的所有PodpodSelector和namespaceSelector: 选择特定Namespace下的特定PodipBlock: 选择特定的IP CIDR范围,且必须是cluster-external IP
区分以下两种配置的区别
1 | ... |
这种配置包含一个规则: podSelector和namespaceSelector
1 | ... |
这种配置包含两种规则: podSelector或namespaceSelector
4.6.4 Default policies
默认情况下,不存在任何Policy,但是我们可以修改默认的行为
4.6.4.1 Default deny all ingress traffic
1 | apiVersion: networking.k8s.io/v1 |
4.6.4.2 Default allow all ingress traffic
1 | apiVersion: networking.k8s.io/v1 |
4.6.4.3 Default deny all egress traffic
1 | apiVersion: networking.k8s.io/v1 |
4.6.4.4 Default allow all egress traffic
1 | apiVersion: networking.k8s.io/v1 |
4.6.4.5 Default deny all ingress and all egress traffic
1 | apiVersion: networking.k8s.io/v1 |
4.7 Adding entries to Pod /etc/hosts with HostAliases
当没有DNS的时候,我们可以通过配置/etc/hosts来提供一种Pod-Level的域名解决方案
4.7.1 Default Hosts File Content
1 | kubectl run nginx --image nginx --generator=run-pod/v1 |
4.7.2 Adding Additional Entries with HostAliases
通过为Pod配置.spec.hostAliases属性,可以增加额外的域名解析规则,如下
1 | apiVersion: v1 |
1 | kubectl apply -f hostaliases-pod.yaml |
4.7.3 Why Does Kubelet Manage the Hosts File?
kubelet为每个Container管理host文件,是为了避免Docker在启动容器后修改该文件
由于文件托管的性质,只要在Container重新启动或者Pod重新被调度的情况下,kubelet都会重新载入host文件,任何用户编写的内容都将被覆盖,因此,不建议修改文件的内容
5 Storage
5.1 Volumes
Container中的磁盘文件是短暂的,这会带来一些问题。首先,当一个Container崩溃之后,kubelet会重启该Container,但是这些磁盘文件会丢失。其次,在一个Pod中运行的不同Container之间可能需要共享一些文件。因此Kubernetes利用Volume来解决上述问题
5.1.1 Backgroud
Docker也有Volume的相关概念,但是其能力相比于Kubernetes较弱。在Docker中,一个Volume就是磁盘中或者其他Container中的一个目录,Volume的生命周期不受管控。Docker现在还提供了Volume Driver,但是其功能还是非常薄弱
Kubernetes中的Volume有明确的生命周期,Volume的生命周期比Pod中任何Container的生命周期更长,因此数据能够在Container重启时保留。当然,如果一个Pod停止了,那么Volume也会相应停止。此外,Kubernetes提供了多种类型的Volume,且Pod可以同时使用任意类型,任意数量的Volume
本质上而言,Volume就是一个包含数据的可被Container访问的目录,至于该目录是如何形成的,支持它的介质以及存储的内容是由具体的类型决定的
我们可以通过配置.spec.volumes字段来指定Volume的类型以及相应的参数,通过.spec.containers.volumeMounts来指定具体的挂载目录
在Container中的应用可以看到由Docker Image以及Volume组成的文件系统视图。Docker Image位于文件系统的顶层,所有的Volume必须挂载到Image中。Volume不能挂载到其他Volume中或者与其他Volume存在hard link。在Pod中的每个Container必须独立地指定每个Volume的挂载目录
5.1.2 Types of Volumes
- awsElasticBlockStore
- azureDisk
- azureFile
- cephfs
- configMap
- csi
- downwardAPI
- emptyDir:由容器运行时管理,容器退出就销毁了
- fc (fibre channel)
- flexVolume
- flocker
- gcePersistentDisk
- gitRepo (deprecated)
- glusterfs
- hostPath
- iscsi
- local
- nfs
- persistentVolumeClaim
- projected
- portworxVolume
- quobyte
- rbd
- scaleIO
- secret
- storageos
- vsphereVolume
5.2 Persistent Volumes
5.3 Storage Classes
5.4 Volume Snapshot Classes
5.5 Dynamic Volume Provisioning
5.6 Node-specific Volume Limits
6 Network
6.1 Overview
首先,我们来明确一下,Kubernetes面临的网络问题
- Highly-coupled Container-to-Container communications:高耦合的
Container之间的网络通信,通过pods以及localhost通信来解决 - Pod-to-Pod communications:本小节将详细展开说明
- Pod-to-Service communications:通过
services来解决 - External-to-Service communications:通过
services来解决
6.2 Docker Model
我们先来回顾一下Docker的网络模型,这对于理解Kubernetes的网络模型是很有必要的。在默认情况下,Docker利用host-private networking,Docker创建了一个虚拟网桥(virtual bridge),默认为docker0。对于Docker创建的每个Container都会有一个连接到网桥的虚拟以太网卡(virtual Ethernet device)veth,从Container内部来看,veth就被映射成了eth0网卡
在这种网络模型下,只要位于同一个物理机上(或者同一个虚拟网桥上),所有的Container之间可以进行通信。但是位于不同物理机上的Container是无法进行通信的
为了让Container可以跨node进行交互,必须为它们分配一个宿主物理机的ip。这样一来,我们就需要付出额外的精力维护ip以及port
6.3 Kubernetes model
Kubernetes要求网络模型必须满足如下条件
- 所有
Container之间的通信不能依赖NAT - 所有
node与Container之间的通信不能依赖NAT - 某个
Container在内部、外部看到的ip一致
这种模式不仅总体上不那么复杂,而且主要与Kubernetes希望将应用程序从VM轻松移植到容器的愿望兼容
到目前为止,都在讨论Container,但事实上,Kubernetes在Pod范围上使用ip地址,因此,在一个Pod内的所有Container共享网络命名空间(network namespaces),当然包括ip地址。这意味着,在一个Pod内的Container可以通过localhost与其他Container进行通信。这称为“IP-per-pod”模式,在这种模式下,一个Pod需要有一个pod contaner来管理网络命名空间,其他app container利用Docker的--net=container:<id>参数来加入这个网络命名空间即可
6.4 Kubernetes networking model implements
Kubernetes的网络模型有很多种实现方式,包括但不仅限如下几种
- ACI
- AOS from Apstra
- Big Cloud Fabric from Big Switch Networks
- Cilium
- CNI-Genie from Huawei
- Contiv
- Contrail
- Flannel
- Google Compute Engine (GCE)
- Kube-router
- L2 networks and linux bridging
- Multus (a Multi Network plugin)
- NSX-T
- Nuage Networks VCS (Virtualized Cloud Services)
- OpenVSwitch
- OVN (Open Virtual Networking)
- Project Calico
- Romana
- Weave Net from Weaveworks
6.5 参考
7 Question
Pod IP在Namespace下唯一,既然可以通过Namespace+Pod IP准确定位一个Pod,为什么还需要flannelflannel保证了在同一个集群中的Pod的ip不重复
8 参考
- 英文文档1
- 中文文档1
- 中文文档2
- k8s-api-reference
- k8s-阿里云公开课
- nginx ingress doc
- metallb doc
- Borg、Omega 和 Kubernetes:谷歌十几年来从这三个容器管理系统中得到的经验教训
- Kubernetes核心概念总结
- Kubernetes之Service
- Kubernetes学习4–容器之间通讯方式及Flannel工作原理
- Flannel网络原理
- 解决Flannel跨主机互联网络问题【Docker】
- Kubernetes Nginx Ingress 教程
- 使用kubeadm安装Kubernetes 1.12
- forbidden: User “system:serviceaccount:kube-system:default” cannot get namespaces in the namespace "default