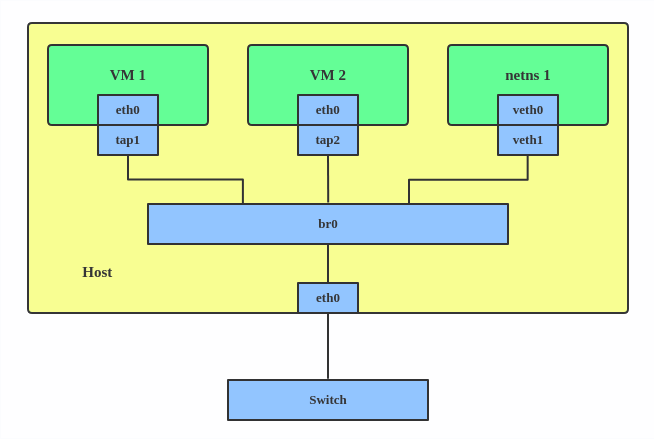
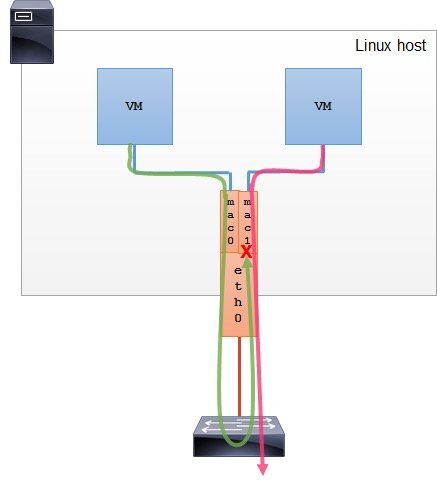
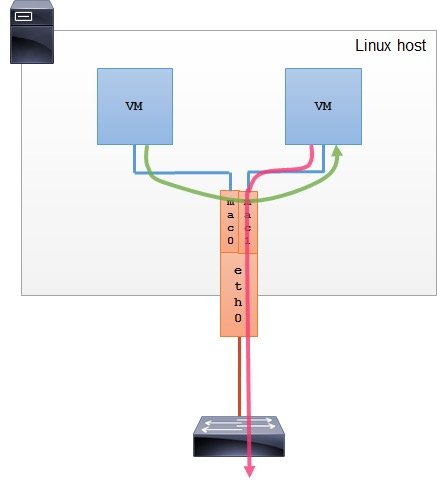
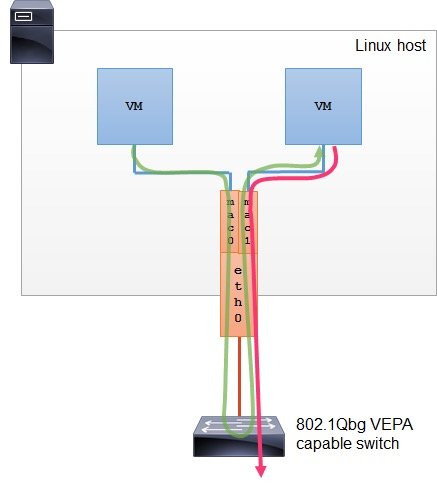
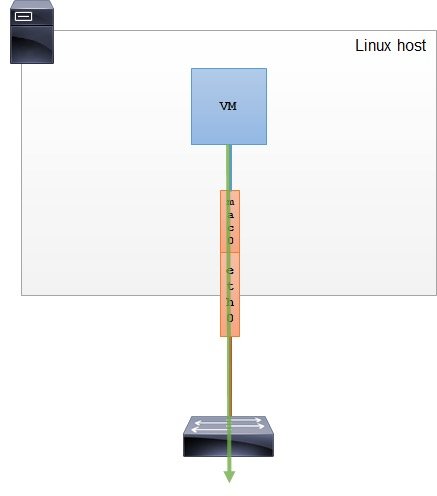
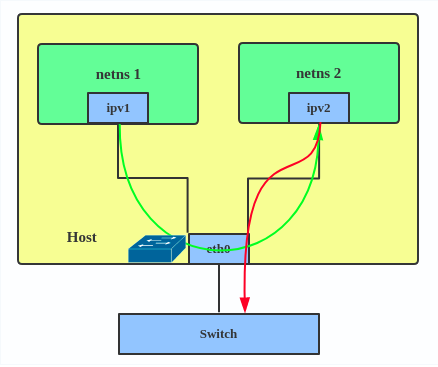
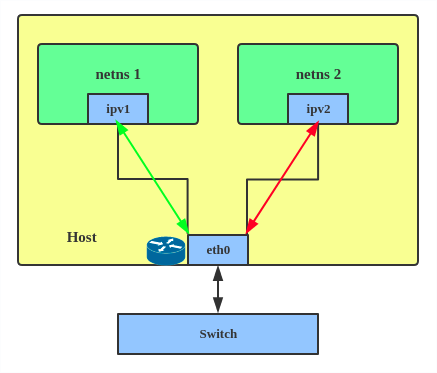
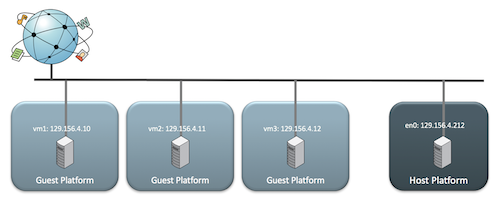
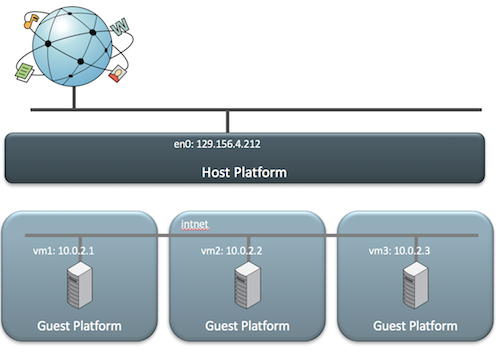
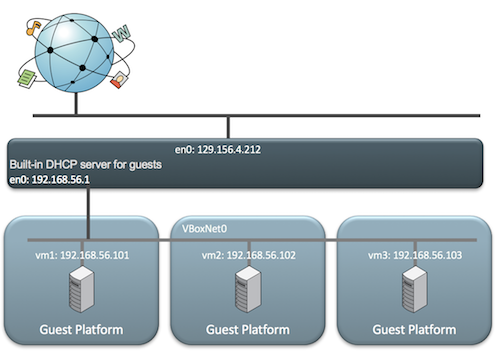
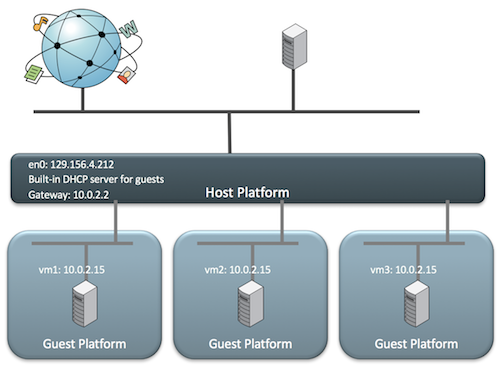
ip link add ${bridge_name}type bridge ip linkset${bridge_name} up
ip addr add ${ip_bridge}/${ip_netmask} broadcast ${ip_broadcast} dev ${bridge_name} ip netns add ${namespace}
ip link add ${ifname_outside_ns}type veth peer name ${ifname_inside_ns}
ip linkset${ifname_outside_ns} up
ip linkset${ifname_outside_ns} master ${bridge_name} ip linkset${ifname_inside_ns} netns ${namespace}
ip netns exec${namespace} ip linkset${ifname_inside_ns} up ip netns exec${namespace} ip addr add ${ip_inside_ns}/${ip_netmask} broadcast ${ip_broadcast} dev ${ifname_inside_ns}
ip netns exec${namespace} ip linkset lo up
ip netns exec${namespace} ip route add default via ${ip_bridge} dev ${ifname_inside_ns}
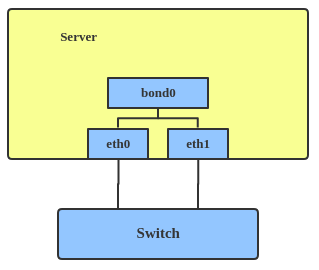
# 配置 source bond.sh export ifname_physics_1="eth0"# 待绑定的子网卡名称1 export ifname_physics_2="ens9"# 待绑定的子网卡名称2 export bond_name="bond_liuye"# bond名称 export bond_mode="active-backup"# bond模式,可以通过 ip link help bond 查询所有的mode export ip_bond="10.0.2.66" export ip_gateway="10.0.2.1" export ip_net="10.0.2.0" export ip_netmask="255.255.255.0" export ip_broadcast="10.0.2.255" setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add bond_liuye type bond miimon 100 updelay 100 downdelay 100 mode active-backup + ip linkset eth0 master bond_liuye + ip linkset ens9 master bond_liuye + ip linkset bond_liuye up + ip linkset eth0 up + ip linkset ens9 up + ip addr add 10.0.2.66/255.255.255.0 broadcast 10.0.2.255 dev bond_liuye + ip route add default via 10.0.2.1 dev bond_liuye + echo'nameserver 8.8.8.8' + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 测试连通性 ping -c 3 www.aliyun.com #-------------------------↓↓↓↓↓↓------------------------- PING xjp-adns.aliyun.com.gds.alibabadns.com (47.88.251.168) 56(84) bytes of data. 64 bytes from 47.88.251.168 (47.88.251.168): icmp_seq=1 ttl=31 time=70.6 ms 64 bytes from 47.88.251.168 (47.88.251.168): icmp_seq=2 ttl=31 time=70.3 ms 64 bytes from 47.88.251.168 (47.88.251.168): icmp_seq=3 ttl=31 time=70.5 ms
# 将网卡1关掉,查看连通性 ip linkset${ifname_physics_1} down ping -c 3 www.aliyun.com #-------------------------↓↓↓↓↓↓------------------------- PING xjp-adns.aliyun.com.gds.alibabadns.com (47.88.251.175) 56(84) bytes of data. 64 bytes from 47.88.251.175 (47.88.251.175): icmp_seq=1 ttl=31 time=81.5 ms 64 bytes from 47.88.251.175 (47.88.251.175): icmp_seq=2 ttl=31 time=81.4 ms 64 bytes from 47.88.251.175 (47.88.251.175): icmp_seq=3 ttl=31 time=81.4 ms
# 查看此时生效的网卡 ip -d link show dev ${bond_name} #-------------------------↓↓↓↓↓↓------------------------- 12: bond_liuye: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:1e:f1:21 brd ff:ff:ff:ff:ff:ff promiscuity 0 bond mode active-backup active_slave ens9 miimon 100 updelay 100 downdelay 100 use_carrier 1 arp_interval 0 arp_validate none arp_all_targets any primary_reselect always fail_over_mac none xmit_hash_policy layer2 resend_igmp 1 num_grat_arp 1 all_slaves_active 0 min_links 0 lp_interval 1 packets_per_slave 1 lacp_rate slow ad_select stable tlb_dynamic_lb 1 addrgenmode eui64 numtxqueues 16 numrxqueues 16 gso_max_size 65536 gso_max_segs 65535 #-------------------------↑↑↑↑↑↑------------------------- # 可以看到,此时生效的网卡是ens9(bond mode active-backup active_slave ens9)
# 打开网卡1,关掉网卡2,再看连通性 ip linkset${ifname_physics_1} up ip linkset${ifname_physics_2} down ping -c 3 www.aliyun.com #-------------------------↓↓↓↓↓↓------------------------- PING xjp-adns.aliyun.com.gds.alibabadns.com (47.88.198.24) 56(84) bytes of data. 64 bytes from 47.88.198.24 (47.88.198.24): icmp_seq=1 ttl=31 time=80.6 ms 64 bytes from 47.88.198.24 (47.88.198.24): icmp_seq=2 ttl=31 time=80.9 ms 64 bytes from 47.88.198.24 (47.88.198.24): icmp_seq=3 ttl=31 time=80.5 ms
# 查看此时生效的网卡 ip -d link show dev ${bond_name} #-------------------------↓↓↓↓↓↓------------------------- 12: bond_liuye: <BROADCAST,MULTICAST,MASTER,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:1e:f1:21 brd ff:ff:ff:ff:ff:ff promiscuity 0 bond mode active-backup active_slave eth0 miimon 100 updelay 100 downdelay 100 use_carrier 1 arp_interval 0 arp_validate none arp_all_targets any primary_reselect always fail_over_mac none xmit_hash_policy layer2 resend_igmp 1 num_grat_arp 1 all_slaves_active 0 min_links 0 lp_interval 1 packets_per_slave 1 lacp_rate slow ad_select stable tlb_dynamic_lb 1 addrgenmode eui64 numtxqueues 16 numrxqueues 16 gso_max_size 65536 gso_max_segs 65535 #-------------------------↑↑↑↑↑↑------------------------- # 可以看到,此时生效的网卡是eth0(bond mode active-backup active_slave eth0)
# 清理 #-------------------------↓↓↓↓↓↓------------------------- + ip linkset bond_liuye down + ip linkset eth0 down + ip linkset ens9 down + ip link del bond_liuye + set +x #-------------------------↑↑↑↑↑↑-------------------------
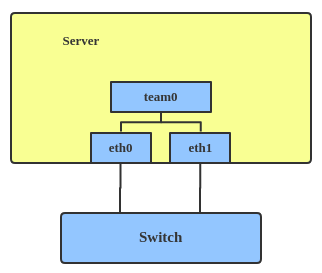
# 配置 source team.sh export ifname_physics_1="eth0"# 待绑定的子网卡名称1 export ifname_physics_2="ens9"# 待绑定的子网卡名称2 export team_name="team_liuye"# team名称 export ip_team="10.0.2.66" export ip_gateway="10.0.2.1" export ip_net="10.0.2.0" export ip_netmask="255.255.255.0" export ip_broadcast="10.0.2.255" setup #-------------------------↓↓↓↓↓↓------------------------- + teamd -o -n -U -d -t team_liuye -c '{"runner": {"name": "activebackup"},"link_watch": {"name": "ethtool"}}' This program is not intended to be run as root. + ip linkset eth0 master team_liuye + ip linkset ens9 master team_liuye + ip linkset team_liuye up + ip linkset eth0 up + ip linkset ens9 up + ip addr add 10.0.2.66/255.255.255.0 broadcast 10.0.2.255 dev team_liuye + ip route add default via 10.0.2.1 dev team_liuye + echo'nameserver 8.8.8.8' + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 测试连通性 ping -c 3 www.aliyun.com #-------------------------↓↓↓↓↓↓------------------------- PING xjp-adns.aliyun.com.gds.alibabadns.com (47.88.251.174) 56(84) bytes of data. 64 bytes from 47.88.251.174 (47.88.251.174): icmp_seq=1 ttl=30 time=69.2 ms 64 bytes from 47.88.251.174 (47.88.251.174): icmp_seq=2 ttl=30 time=68.8 ms 64 bytes from 47.88.251.174 (47.88.251.174): icmp_seq=3 ttl=30 time=68.6 ms
# 将网卡1关掉,查看连通性 ip linkset${ifname_physics_1} down ping -c 3 www.aliyun.com #-------------------------↓↓↓↓↓↓------------------------- PING xjp-adns.aliyun.com.gds.alibabadns.com (47.88.251.176) 56(84) bytes of data. 64 bytes from 47.88.251.176 (47.88.251.176): icmp_seq=1 ttl=31 time=70.3 ms 64 bytes from 47.88.251.176 (47.88.251.176): icmp_seq=2 ttl=31 time=70.2 ms 64 bytes from 47.88.251.176 (47.88.251.176): icmp_seq=3 ttl=31 time=70.2 ms
# 打开网卡1,关掉网卡2,再看连通性 ip linkset${ifname_physics_1} up ip linkset${ifname_physics_2} down ping -c 3 www.aliyun.com #-------------------------↓↓↓↓↓↓------------------------- PING xjp-adns.aliyun.com.gds.alibabadns.com (47.88.251.171) 56(84) bytes of data. 64 bytes from 47.88.251.171 (47.88.251.171): icmp_seq=1 ttl=30 time=82.7 ms 64 bytes from 47.88.251.171 (47.88.251.171): icmp_seq=2 ttl=30 time=218 ms 64 bytes from 47.88.251.171 (47.88.251.171): icmp_seq=3 ttl=30 time=340 ms
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip linkset team_liuye down + ip linkset eth0 down + ip linkset ens9 down + ip link del team_liuye + set +x #-------------------------↑↑↑↑↑↑-------------------------
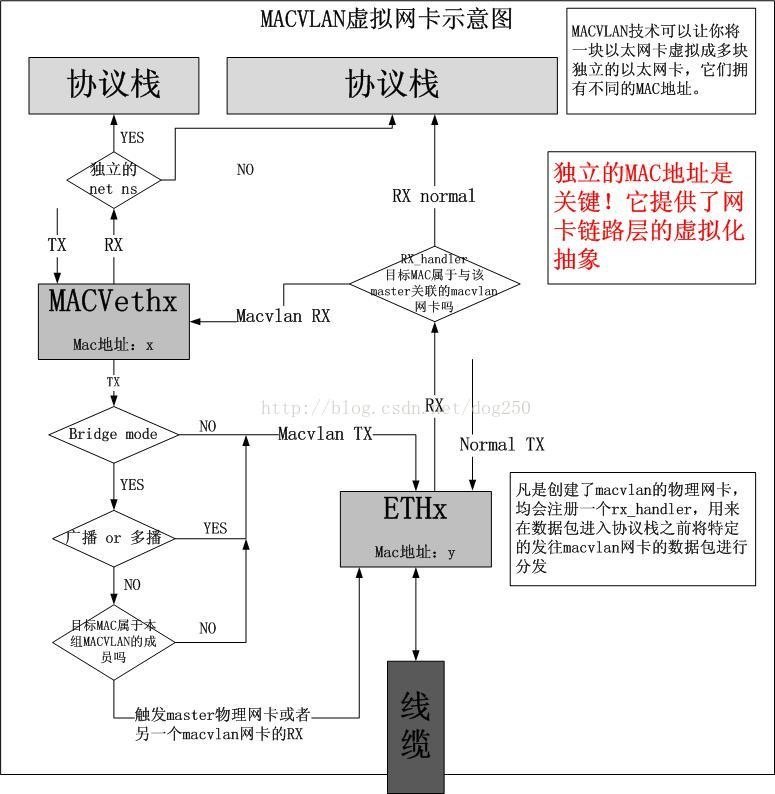
同一VLAN间数据传输是通过二层互访,即MAC地址实现的,不需要使用路由。不同VLAN的用户单播默认不能直接通信,如果想要通信,还需要三层设备做路由,macvlan也是如此。用macvlan技术虚拟出来的虚拟网卡,在逻辑上和物理网卡是对等的。物理网卡也就相当于一个交换机,记录着对应的虚拟网卡和MAC地址,当物理网卡收到数据包后,会根据目的 MAC 地址判断这个包属于哪一个虚拟网卡。这也就意味着,只要是从macvlan子接口发来的数据包(或者是发往macvlan子接口的数据包),物理网卡只接收数据包,不处理数据包,所以这就引出了一个问题:本机 macvlan 网卡上面的 IP 无法和物理网卡上面的 IP 通信!
ip link add ${ifname_macvlan1}link${ifname_external}type macvlan mode ${macvlan_mode} ip link add ${ifname_macvlan2}link${ifname_external}type macvlan mode ${macvlan_mode}
ip netns add ${namespace1} ip netns add ${namespace2}
ip linkset${ifname_macvlan1} netns ${namespace1} ip linkset${ifname_macvlan2} netns ${namespace2}
ip netns exec${namespace1} ip linkset${ifname_macvlan1} up ip netns exec${namespace1} ip addr add ${ip_macvlan1}/${ip_netmask} dev ${ifname_macvlan1} if [ -z "${default_gateway}" ]; then ip netns exec${namespace1} ip route add default dev ${ifname_macvlan1} else ip netns exec${namespace1} ip route add default via ${default_gateway} dev ${ifname_macvlan1} fi
ip netns exec${namespace2} ip linkset${ifname_macvlan2} up ip netns exec${namespace2} ip addr add ${ip_macvlan2}/${ip_netmask} dev ${ifname_macvlan2} if [ -z "${default_gateway}" ]; then ip netns exec${namespace2} ip route add default dev ${ifname_macvlan2} else ip netns exec${namespace2} ip route add default via ${default_gateway} dev ${ifname_macvlan2} fi
set +x }
functioncleanup() { set -x ip netns exec${namespace1} ip link delete ${ifname_macvlan1} ip netns exec${namespace2} ip link delete ${ifname_macvlan2}
ip netns delete ${namespace1} ip netns delete ${namespace2} set +x }
# 配置 source macvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export macvlan_mode="bridge" export ip_host="10.0.2.15"# 主机ip export default_gateway="10.0.2.2"# 默认路由网关ip export ip_macvlan1="10.0.2.16"# macvlan接口1的ip export ip_macvlan2="10.0.2.17"# macvlan接口2的ip export ip_netmask="255.255.255.0"# macvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add macvlan1 link enp0s3 type macvlan mode bridge + ip link add macvlan2 link enp0s3 type macvlan mode bridge + ip netns add liuye1 + ip netns add liuye2 + ip linkset macvlan1 netns liuye1 + ip linkset macvlan2 netns liuye2 + ip netns exec liuye1 ip linkset macvlan1 up + ip netns exec liuye1 ip addr add 10.0.2.16/255.255.255.0 dev macvlan1 + '[' -z 10.0.2.2 ']' + ip netns exec liuye1 ip route add default via 10.0.2.2 dev macvlan1 + ip netns exec liuye2 ip linkset macvlan2 up + ip netns exec liuye2 ip addr add 10.0.2.17/255.255.255.0 dev macvlan2 + '[' -z 10.0.2.2 ']' + ip netns exec liuye2 ip route add default via 10.0.2.2 dev macvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在macvlan1所在的网络命名空间中ping macvlan2的ip ip netns exec${namespace1} ping ${ip_macvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 10.0.2.17 (10.0.2.17) 56(84) bytes of data. 64 bytes from 10.0.2.17: icmp_seq=1 ttl=64 time=0.104 ms 64 bytes from 10.0.2.17: icmp_seq=2 ttl=64 time=0.071 ms 64 bytes from 10.0.2.17: icmp_seq=3 ttl=64 time=0.105 ms
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete macvlan1 + ip netns exec liuye2 ip link delete macvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 配置 source macvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export macvlan_mode="bridge" export ip_host="10.0.2.15"# 主机ip export default_gateway=""# 默认路由网关ip export ip_macvlan1="192.168.100.1"# macvlan接口1的ip export ip_macvlan2="192.168.200.1"# macvlan接口2的ip export ip_netmask="255.255.255.0"# macvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add macvlan1 link enp0s3 type macvlan mode bridge + ip link add macvlan2 link enp0s3 type macvlan mode bridge + ip netns add liuye1 + ip netns add liuye2 + ip linkset macvlan1 netns liuye1 + ip linkset macvlan2 netns liuye2 + ip netns exec liuye1 ip linkset macvlan1 up + ip netns exec liuye1 ip addr add 192.168.100.1/255.255.255.0 dev macvlan1 + '[' -z ''']' + ip netns exec liuye1 ip route add default dev macvlan1 + ip netns exec liuye2 ip linkset macvlan2 up + ip netns exec liuye2 ip addr add 192.168.200.1/255.255.255.0 dev macvlan2 + '[' -z ''']' + ip netns exec liuye2 ip route add default dev macvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在macvlan1所在的网络命名空间中ping macvlan2的ip ip netns exec${namespace1} ping ${ip_macvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 192.168.200.1 (192.168.200.1) 56(84) bytes of data. 64 bytes from 192.168.200.1: icmp_seq=1 ttl=64 time=0.243 ms 64 bytes from 192.168.200.1: icmp_seq=2 ttl=64 time=0.041 ms 64 bytes from 192.168.200.1: icmp_seq=3 ttl=64 time=0.045 ms
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete macvlan1 + ip netns exec liuye2 ip link delete macvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 配置 source macvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export macvlan_mode="vepa" export ip_host="10.0.2.15"# 主机ip export default_gateway="10.0.2.2"# 默认路由网关ip export ip_macvlan1="10.0.2.16"# macvlan接口1的ip export ip_macvlan2="10.0.2.17"# macvlan接口2的ip export ip_netmask="255.255.255.0"# macvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add macvlan1 link enp0s3 type macvlan mode vepa + ip link add macvlan2 link enp0s3 type macvlan mode vepa + ip netns add liuye1 + ip netns add liuye2 + ip linkset macvlan1 netns liuye1 + ip linkset macvlan2 netns liuye2 + ip netns exec liuye1 ip linkset macvlan1 up + ip netns exec liuye1 ip addr add 10.0.2.16/255.255.255.0 dev macvlan1 + '[' -z 10.0.2.2 ']' + ip netns exec liuye1 ip route add default via 10.0.2.2 dev macvlan1 + ip netns exec liuye2 ip linkset macvlan2 up + ip netns exec liuye2 ip addr add 10.0.2.17/255.255.255.0 dev macvlan2 + '[' -z 10.0.2.2 ']' + ip netns exec liuye2 ip route add default via 10.0.2.2 dev macvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在macvlan1所在的网络命名空间中ping macvlan2的ip ip netns exec${namespace1} ping ${ip_macvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 10.0.2.17 (10.0.2.17) 56(84) bytes of data.
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete macvlan1 + ip netns exec liuye2 ip link delete macvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 配置 source macvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export macvlan_mode="vepa" export ip_host="10.0.2.15"# 主机ip export default_gateway=""# 默认路由网关ip export ip_macvlan1="192.168.100.1"# macvlan接口1的ip export ip_macvlan2="192.168.200.1"# macvlan接口2的ip export ip_netmask="255.255.255.0"# macvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add macvlan1 link enp0s3 type macvlan mode vepa + ip link add macvlan2 link enp0s3 type macvlan mode vepa + ip netns add liuye1 + ip netns add liuye2 + ip linkset macvlan1 netns liuye1 + ip linkset macvlan2 netns liuye2 + ip netns exec liuye1 ip linkset macvlan1 up + ip netns exec liuye1 ip addr add 192.168.100.1/255.255.255.0 dev macvlan1 + '[' -z ''']' + ip netns exec liuye1 ip route add default dev macvlan1 + ip netns exec liuye2 ip linkset macvlan2 up + ip netns exec liuye2 ip addr add 192.168.200.1/255.255.255.0 dev macvlan2 + '[' -z ''']' + ip netns exec liuye2 ip route add default dev macvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在macvlan1所在的网络命名空间中ping macvlan2的ip ip netns exec${namespace1} ping ${ip_macvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 192.168.200.1 (192.168.200.1) 56(84) bytes of data.
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete macvlan1 + ip netns exec liuye2 ip link delete macvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
ip link add ${ifname_ipvlan1}link${ifname_external}type ipvlan mode ${ipvlan_mode} ip link add ${ifname_ipvlan2}link${ifname_external}type ipvlan mode ${ipvlan_mode}
ip netns add ${namespace1} ip netns add ${namespace2}
ip linkset${ifname_ipvlan1} netns ${namespace1} ip linkset${ifname_ipvlan2} netns ${namespace2}
ip netns exec${namespace1} ip linkset${ifname_ipvlan1} up ip netns exec${namespace1} ip addr add ${ip_ipvlan1}/${ip_netmask} dev ${ifname_ipvlan1} if [ -z "${default_gateway}" ]; then ip netns exec${namespace1} ip route add default dev ${ifname_ipvlan1} else ip netns exec${namespace1} ip route add default via ${default_gateway} dev ${ifname_ipvlan1} fi
ip netns exec${namespace2} ip linkset${ifname_ipvlan2} up ip netns exec${namespace2} ip addr add ${ip_ipvlan2}/${ip_netmask} dev ${ifname_ipvlan2} if [ -z "${default_gateway}" ]; then ip netns exec${namespace2} ip route add default dev ${ifname_ipvlan2} else ip netns exec${namespace2} ip route add default via ${default_gateway} dev ${ifname_ipvlan2} fi
set +x }
functioncleanup() { set -x
ip netns exec${namespace1} ip link delete ${ifname_ipvlan1} ip netns exec${namespace2} ip link delete ${ifname_ipvlan2}
ip netns delete ${namespace1} ip netns delete ${namespace2}
source ipvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export ipvlan_mode="l2" export ip_host="10.0.2.15"# 主机ip export default_gateway="10.0.2.2"# 默认路由网关ip export ip_ipvlan1="10.0.2.16"# ipvlan接口1的ip export ip_ipvlan2="10.0.2.17"# ipvlan接口2的ip export ip_netmask="255.255.255.0"# ipvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add ipvlan1 link enp0s3 type ipvlan mode l2 + ip link add ipvlan2 link enp0s3 type ipvlan mode l2 + ip netns add liuye1 + ip netns add liuye2 + ip linkset ipvlan1 netns liuye1 + ip linkset ipvlan2 netns liuye2 + ip netns exec liuye1 ip linkset ipvlan1 up + ip netns exec liuye1 ip addr add 10.0.2.16/255.255.255.0 dev ipvlan1 + '[' -z 10.0.2.2 ']' + ip netns exec liuye1 ip route add default via 10.0.2.2 dev ipvlan1 + ip netns exec liuye2 ip linkset ipvlan2 up + ip netns exec liuye2 ip addr add 10.0.2.17/255.255.255.0 dev ipvlan2 + '[' -z 10.0.2.2 ']' + ip netns exec liuye2 ip route add default via 10.0.2.2 dev ipvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在ipvlan1所在的网络命名空间中ping ipvlan2的ip ip netns exec${namespace1} ping ${ip_ipvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 10.0.2.17 (10.0.2.17) 56(84) bytes of data. 64 bytes from 10.0.2.17: icmp_seq=1 ttl=64 time=1.01 ms 64 bytes from 10.0.2.17: icmp_seq=2 ttl=64 time=0.422 ms 64 bytes from 10.0.2.17: icmp_seq=3 ttl=64 time=0.050 ms
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete ipvlan1 + ip netns exec liuye2 ip link delete ipvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
source ipvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export ipvlan_mode="l2" export ip_host="10.0.2.15"# 主机ip export default_gateway=""# 默认路由网关ip export ip_ipvlan1="192.168.100.1"# ipvlan接口1的ip export ip_ipvlan2="192.168.200.1"# ipvlan接口2的ip export ip_netmask="255.255.255.0"# ipvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add ipvlan1 link enp0s3 type ipvlan mode l2 + ip link add ipvlan2 link enp0s3 type ipvlan mode l2 + ip netns add liuye1 + ip netns add liuye2 + ip linkset ipvlan1 netns liuye1 + ip linkset ipvlan2 netns liuye2 + ip netns exec liuye1 ip linkset ipvlan1 up + ip netns exec liuye1 ip addr add 192.168.100.1/255.255.255.0 dev ipvlan1 + '[' -z ''']' + ip netns exec liuye1 ip route add default dev ipvlan1 + ip netns exec liuye2 ip linkset ipvlan2 up + ip netns exec liuye2 ip addr add 192.168.200.1/255.255.255.0 dev ipvlan2 + '[' -z ''']' + ip netns exec liuye2 ip route add default dev ipvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在ipvlan1所在的网络命名空间中ping ipvlan2的ip ip netns exec${namespace1} ping ${ip_ipvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 192.168.200.1 (192.168.200.1) 56(84) bytes of data. 64 bytes from 192.168.200.1: icmp_seq=1 ttl=64 time=0.783 ms 64 bytes from 192.168.200.1: icmp_seq=2 ttl=64 time=0.041 ms 64 bytes from 192.168.200.1: icmp_seq=3 ttl=64 time=0.087 ms
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete ipvlan1 + ip netns exec liuye2 ip link delete ipvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
source ipvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export ipvlan_mode="l3" export ip_host="10.0.2.15"# 主机ip export default_gateway="10.0.2.2"# 默认路由网关ip export ip_ipvlan1="10.0.2.16"# ipvlan接口1的ip export ip_ipvlan2="10.0.2.17"# ipvlan接口2的ip export ip_netmask="255.255.255.0"# ipvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add ipvlan1 link enp0s3 type ipvlan mode l3 + ip link add ipvlan2 link enp0s3 type ipvlan mode l3 + ip netns add liuye1 + ip netns add liuye2 + ip linkset ipvlan1 netns liuye1 + ip linkset ipvlan2 netns liuye2 + ip netns exec liuye1 ip linkset ipvlan1 up + ip netns exec liuye1 ip addr add 10.0.2.16/255.255.255.0 dev ipvlan1 + '[' -z 10.0.2.2 ']' + ip netns exec liuye1 ip route add default via 10.0.2.2 dev ipvlan1 + ip netns exec liuye2 ip linkset ipvlan2 up + ip netns exec liuye2 ip addr add 10.0.2.17/255.255.255.0 dev ipvlan2 + '[' -z 10.0.2.2 ']' + ip netns exec liuye2 ip route add default via 10.0.2.2 dev ipvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在ipvlan1所在的网络命名空间中ping ipvlan2的ip ip netns exec${namespace1} ping ${ip_ipvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 10.0.2.17 (10.0.2.17) 56(84) bytes of data. 64 bytes from 10.0.2.17: icmp_seq=1 ttl=64 time=0.037 ms 64 bytes from 10.0.2.17: icmp_seq=2 ttl=64 time=0.039 ms 64 bytes from 10.0.2.17: icmp_seq=3 ttl=64 time=0.055 ms
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete ipvlan1 + ip netns exec liuye2 ip link delete ipvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
source ipvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export ipvlan_mode="l3" export ip_host="10.0.2.15"# 主机ip export default_gateway=""# 默认路由网关ip export ip_ipvlan1="192.168.100.1"# ipvlan接口1的ip export ip_ipvlan2="192.168.200.1"# ipvlan接口2的ip export ip_netmask="255.255.255.0"# ipvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add ipvlan1 link enp0s3 type ipvlan mode l3 + ip link add ipvlan2 link enp0s3 type ipvlan mode l3 + ip netns add liuye1 + ip netns add liuye2 + ip linkset ipvlan1 netns liuye1 + ip linkset ipvlan2 netns liuye2 + ip netns exec liuye1 ip linkset ipvlan1 up + ip netns exec liuye1 ip addr add 192.168.100.1/255.255.255.0 dev ipvlan1 + '[' -z ''']' + ip netns exec liuye1 ip route add default dev ipvlan1 + ip netns exec liuye2 ip linkset ipvlan2 up + ip netns exec liuye2 ip addr add 192.168.200.1/255.255.255.0 dev ipvlan2 + '[' -z ''']' + ip netns exec liuye2 ip route add default dev ipvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在ipvlan1所在的网络命名空间中ping ipvlan2的ip ip netns exec${namespace1} ping ${ip_ipvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 192.168.200.1 (192.168.200.1) 56(84) bytes of data. 64 bytes from 192.168.200.1: icmp_seq=1 ttl=64 time=0.044 ms 64 bytes from 192.168.200.1: icmp_seq=2 ttl=64 time=0.066 ms 64 bytes from 192.168.200.1: icmp_seq=3 ttl=64 time=0.047 ms
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete ipvlan1 + ip netns exec liuye2 ip link delete ipvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
source ipvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export ipvlan_mode="l3s" export ip_host="10.0.2.15"# 主机ip export default_gateway="10.0.2.2"# 默认路由网关ip export ip_ipvlan1="10.0.2.16"# ipvlan接口1的ip export ip_ipvlan2="10.0.2.17"# ipvlan接口2的ip export ip_netmask="255.255.255.0"# ipvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add ipvlan1 link enp0s3 type ipvlan mode l3s + ip link add ipvlan2 link enp0s3 type ipvlan mode l3s + ip netns add liuye1 + ip netns add liuye2 + ip linkset ipvlan1 netns liuye1 + ip linkset ipvlan2 netns liuye2 + ip netns exec liuye1 ip linkset ipvlan1 up + ip netns exec liuye1 ip addr add 10.0.2.16/255.255.255.0 dev ipvlan1 + '[' -z 10.0.2.2 ']' + ip netns exec liuye1 ip route add default via 10.0.2.2 dev ipvlan1 + ip netns exec liuye2 ip linkset ipvlan2 up + ip netns exec liuye2 ip addr add 10.0.2.17/255.255.255.0 dev ipvlan2 + '[' -z 10.0.2.2 ']' + ip netns exec liuye2 ip route add default via 10.0.2.2 dev ipvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在ipvlan1所在的网络命名空间中ping ipvlan2的ip ip netns exec${namespace1} ping ${ip_ipvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 10.0.2.17 (10.0.2.17) 56(84) bytes of data. 64 bytes from 10.0.2.17: icmp_seq=1 ttl=64 time=0.119 ms 64 bytes from 10.0.2.17: icmp_seq=2 ttl=64 time=0.042 ms 64 bytes from 10.0.2.17: icmp_seq=3 ttl=64 time=0.046 ms
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete ipvlan1 + ip netns exec liuye2 ip link delete ipvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
source ipvlan.sh export ifname_external="enp0s3"# 主机的外网网卡 export ipvlan_mode="l3s" export ip_host="10.0.2.15"# 主机ip export default_gateway=""# 默认路由网关ip export ip_ipvlan1="192.168.100.1"# ipvlan接口1的ip export ip_ipvlan2="192.168.200.1"# ipvlan接口2的ip export ip_netmask="255.255.255.0"# ipvlan接口的子网掩码 setup #-------------------------↓↓↓↓↓↓------------------------- + ip link add ipvlan1 link enp0s3 type ipvlan mode l3s + ip link add ipvlan2 link enp0s3 type ipvlan mode l3s + ip netns add liuye1 + ip netns add liuye2 + ip linkset ipvlan1 netns liuye1 + ip linkset ipvlan2 netns liuye2 + ip netns exec liuye1 ip linkset ipvlan1 up + ip netns exec liuye1 ip addr add 192.168.100.1/255.255.255.0 dev ipvlan1 + '[' -z ''']' + ip netns exec liuye1 ip route add default dev ipvlan1 + ip netns exec liuye2 ip linkset ipvlan2 up + ip netns exec liuye2 ip addr add 192.168.200.1/255.255.255.0 dev ipvlan2 + '[' -z ''']' + ip netns exec liuye2 ip route add default dev ipvlan2 + set +x #-------------------------↑↑↑↑↑↑-------------------------
# 在ipvlan1所在的网络命名空间中ping ipvlan2的ip ip netns exec${namespace1} ping ${ip_ipvlan2} -c 3 #-------------------------↓↓↓↓↓↓------------------------- PING 192.168.200.1 (192.168.200.1) 56(84) bytes of data. 64 bytes from 192.168.200.1: icmp_seq=1 ttl=64 time=0.059 ms 64 bytes from 192.168.200.1: icmp_seq=2 ttl=64 time=0.045 ms 64 bytes from 192.168.200.1: icmp_seq=3 ttl=64 time=0.122 ms
# 清理 cleanup #-------------------------↓↓↓↓↓↓------------------------- + ip netns exec liuye1 ip link delete ipvlan1 + ip netns exec liuye2 ip link delete ipvlan2 + ip netns delete liuye1 + ip netns delete liuye2 + set +x #-------------------------↑↑↑↑↑↑-------------------------