阅读更多
1 数据流分析
数据流分析:一组用来获取程序执行路径上的数据流信息的技术
数据流分析应用
- 到达-定值分析(Reaching-Definition Analysis)
- 活跃变量分析(Live-Variable Analysis)
- 可用表达式分析(Available-Expression Analysis)
- 在每一种数据流分析应用中,都会把每个程序点和一个数据流值关联起来
1.1 语句的数据流模式
语句的数据流模式涉及的符号及其说明如下
- $IN[s]$:语句$s$之前的数据流值
- $OUT[s]$:语句$s$之后的数据流值
- $f_s$:语句$s$的传递函数(transfer function)
其中,传递函数具有两种风格
- 信息沿执行路径前向传播(前向数据流问题)$$OUT[s] = f_s (IN[s])$$
- 信息沿执行路径逆向传播(逆向数据流问题)$$IN[s] = f_s (OUT[s])$$
语句的数据流模式是指:一个赋值语句$s$之前和之后的数据流值的关系
基本块中相邻两个语句之间的数据流值的关系
- 设基本块B由语句$s_1, s_2, ..., s_n$顺序组成,则$$IN[s_{i+1}]= OUT[s_i], i=1, 2, ..., n-1$$
1.2 基本块上的数据流模式
基本块上的数据流模式涉及的符号及其说明如下
- $IN[B]$:紧靠基本块B之前的数据流值
- $OUT[B]$:紧随基本块B之后的数据流值
- $f_B$:基本块$B$的传递函数(transfer function)
基本块的传递函数也具有两种风格
- 前向数据流问题:$$OUT[B] = f_B(IN[B]), f_B = f_{s_n} \cdot ... \cdot f_{s_2} \cdot f_{s_1}$$
- 逆向数据流问题:$$IN[B] = f_B(OUT[B]), f_B = f_{s_1} \cdot f_{s_2} \cdot ... \cdot f_{s_n}$$
设基本块B由语句$s_1, s_2, ..., s_n$顺序组成,则
- $IN[B] = IN[s_1]$
- $OUT[B] = OUT[s_n]$
2 到达定值分析
2.1 概念
定值(Definition)
- 变量$x$的定值是(可能)将一个值赋给$x$的语句
到达定值(Reaching Definition)
- 如果存在一条从紧跟在定值$d$后面的点到达某一程序点$p$的路径,而且在此路径上$d$没有被“杀死”(如果在此路径上有对变量$x$的其它定值$d^{\prime}$,则称变量$x$被这个定值$d^{\prime}$“杀死”了),则称定值$d$到达程序点$p$
- 直观地讲,如果某个变量$x$的一个定值$d$到达点$p$,在点$p$处使用的$x$的值可能就是由$d$最后赋予的
2.2 例子
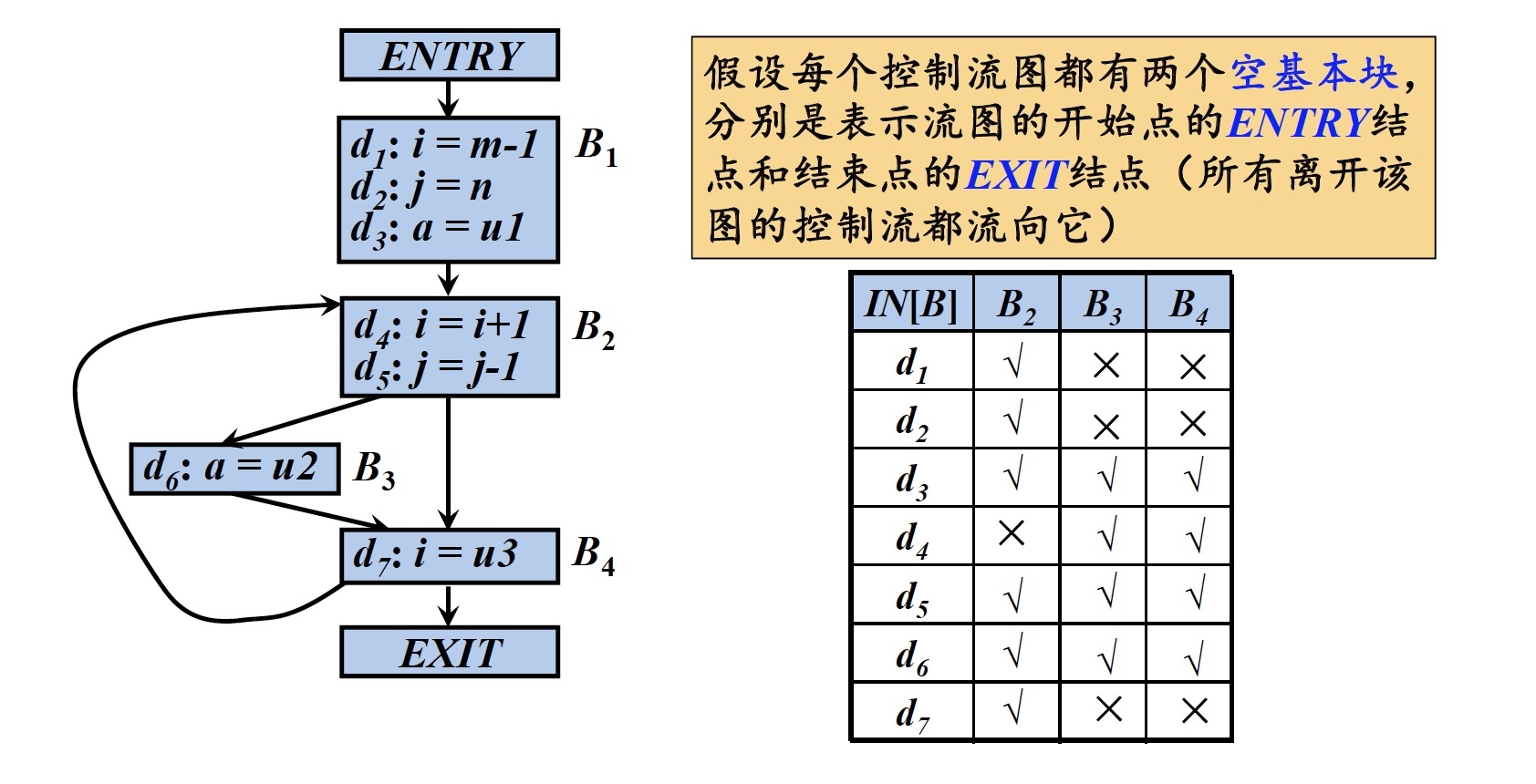
对于基本块$B_2$
- $d_1$是$i$的定值,可达
- $d_2$是$j$的定值,可达
- $d_3$是$a$的定值,可达
- $d_4$是$i$的定值,在经过循环重新到达$B_2$时,已被$d_7$杀死,不可达
- $d_5$是$j$的定值,在经过循环重新到达$B_2$时,未被杀死,可达
- $d_6$是$a$的定值,在经过循环重新到达$B_2$时,未被杀死,可达
- $d_7$是$i$的定值,在经过循环重新到达$B_2$时,未被杀死,可达
对于基本块$B_3$
- $d_1$是$i$的定值,在经过基本块$B_2$时,被$d_4$杀死,不可达
- $d_2$是$j$的定值,在经过基本块$B_2$时,被$d_5$杀死,不可达
- $d_3$是$a$的定值,在经过基本块$B_2$时,未被杀死,可达
- $d_4$是$i$的定值,可达
- $d_5$是$j$的定值,可达
- $d_6$是$a$的定值,在经过循环重新到达$B_3$时,未被杀死,可达
- $d_7$是$i$的定值,在经过循环重新到达$B_3$时,已被$d_4$杀死,不可达
对于基本块$B_4$
- $d_1$是$i$的定值,在经过基本块$B_2$时,被$d_4$杀死,不可达
- $d_2$是$j$的定值,在经过基本块$B_2$时,被$d_5$杀死,不可达
- $d_3$是$a$的定值,经过基本块$B_2$直接到达$B_4$后(不经过$B_3$),没有被杀死,可达(存在一条即可,虽然经过$B_3$会被$d_6$杀死,但是不经过$B_3$就不会被杀死)
- $d_4$是$i$的定值,可达
- $d_5$是$j$的定值,可达
- $d_6$是$a$的定值,可达
- $d_7$是$i$的定值,在经过循环重新到达$B_4$时,已被$d_4$杀死,不可达
2.3 到达定值分析的主要用途
- 循环不变计算的检测
- 如果循环中含有赋值$x=y+z$,而$y$和$z$所有可能的定值都在循环外面(包括$y$或$z$是常数的特殊情况),那么$y+z$就是循环不变计算
- 常量合并
- 如果对变量$x$的某次使用只有一个定值可以到达,并且该定值把一个常量赋给$x$,那么可以简单地把$x$替换为该常量
- 判定变量$x$在$p$点上是否未经定值就被引用
2.4 “生成”与“杀死”定值
定值$d: u = v + w$
- 该语句“生成”了一个对变量$u$的定值$d$,并“杀死”了程序中其它对$u$的定值
2.5 到达定值的传递函数
定值$d: u = v + w$的传递函数为$f_d$
- $f_d(x) = gen_d \cup (x-kill_d)$,即生成-杀死形式
- $gen_d$:由语句$d$生成的定值的集合$gen_d =\{ d \}$
- $killd$:由语句$d$杀死的定值的集合(程序中所有其它对$u$的定值)
基本块B的传递函数为$f_B$
- $f_B(x) = gen_B \cup (x-kill_B)$
- $kill_B = kill_1 \cup kill_2 \cup ... \cup kill_n$:被基本块B中各个语句杀死的定值的集合
- $gen_B = gen_n \cup ( gen_{n-1} – kill_n ) \cup ( gen_{n-2} – kill_{n-1} – kill_n ) \cup ... \cup ( gen_1 –kill_2 –kill_3 – ... – kill_n )$:基本块中没有被块中各语句“杀死”的定值的集合
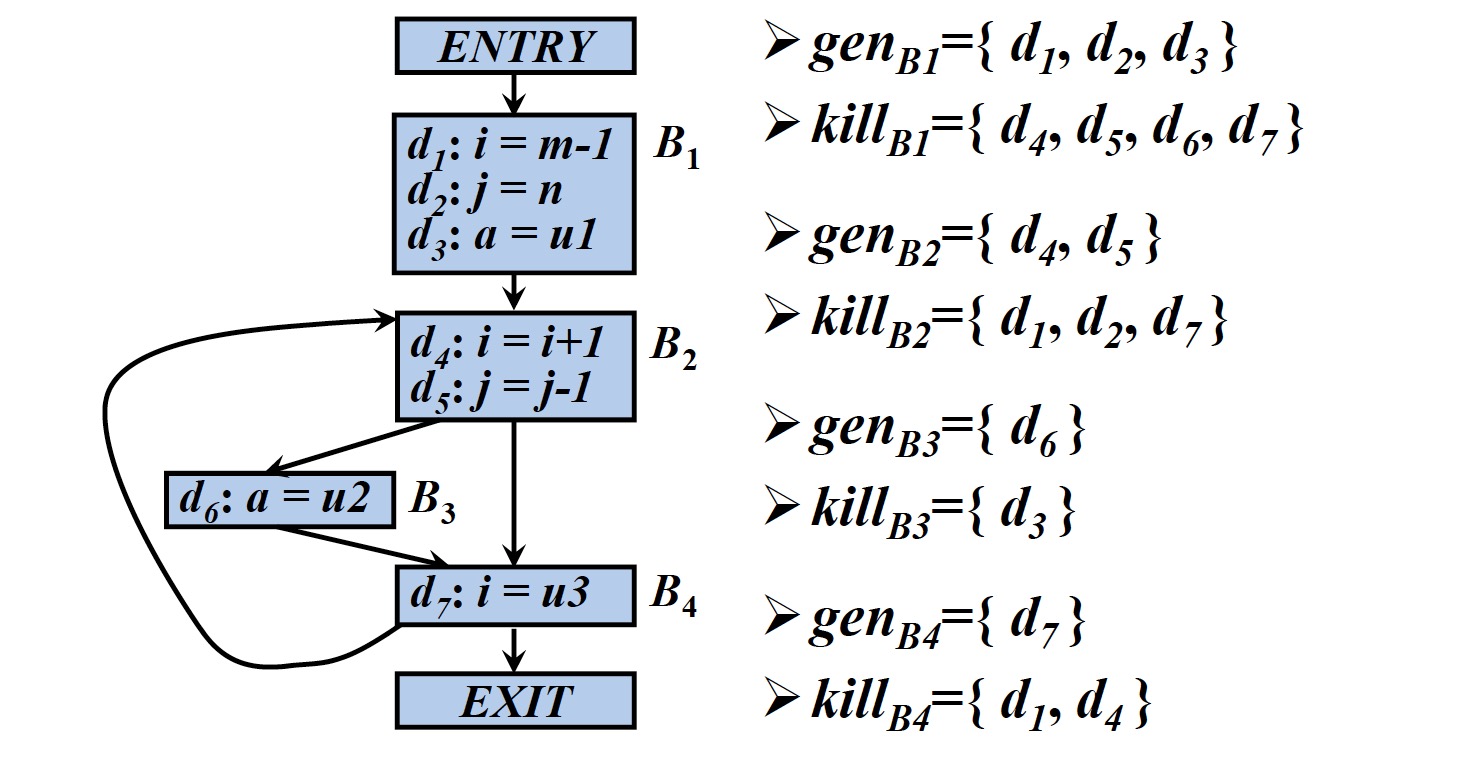
2.6 到达定值的数据流方程
符号及其说明
- $IN[B]$:到达流图中基本块B的入口处的定值的集合
- $OUT[B]$:到达流图中基本块B的出口处的定值的集合
方程
- $OUT[ENRTY]=\Phi$
-
$OUT[B]=f_B(IN[B]), B \ne ENTRY$
- $f_B(x) = gen_B \cup (x-kill_B)$
- $IN[B] = \cup_{P是B的一个前驱}\;\;\;\;\;\;\;OUT[P], B \ne ENTRY$
3 到达定值方程的计算
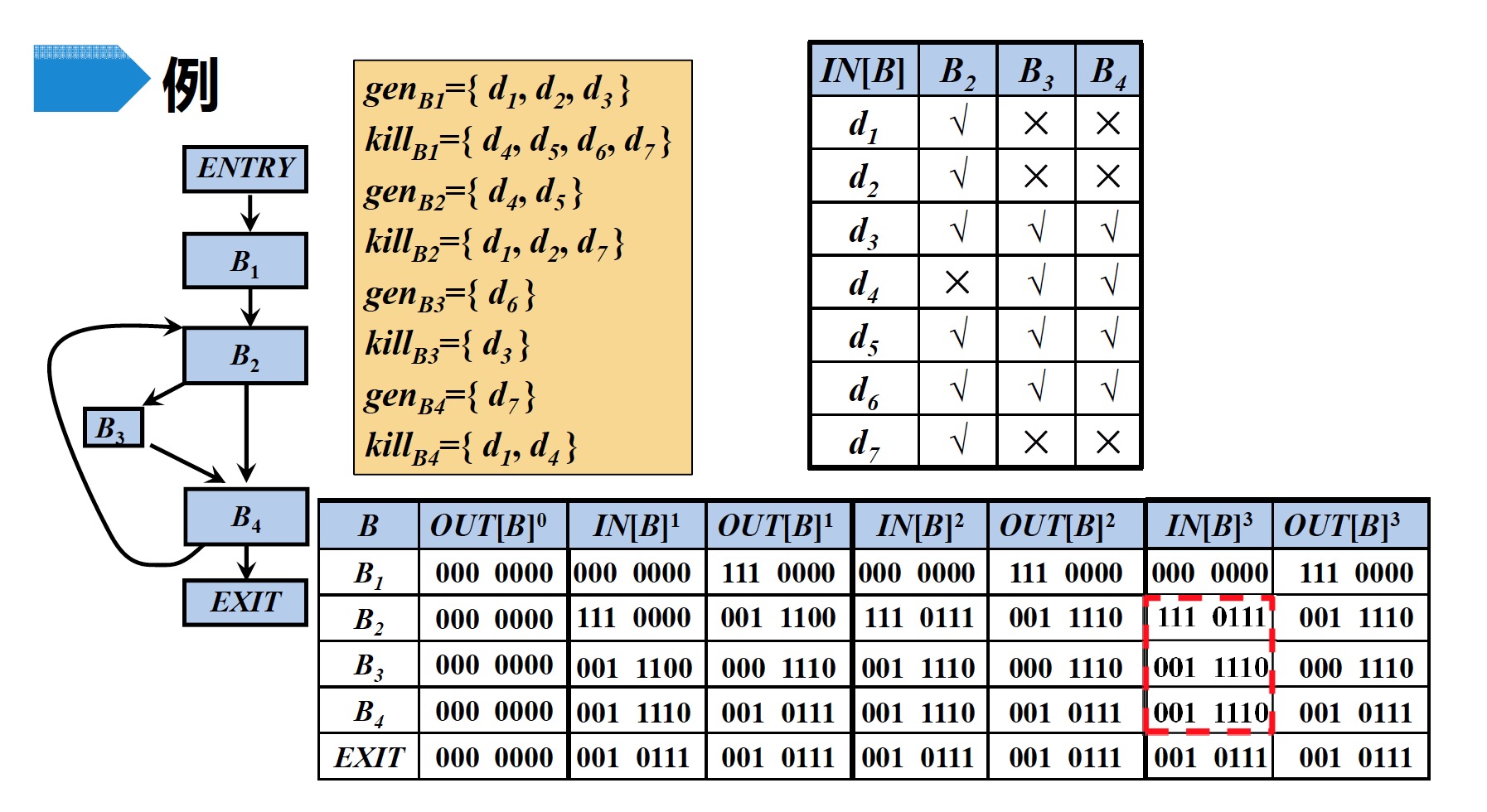
3.1 计算到达定值的迭代算法
输入:流图G,其中每个基本块B的$gen_B$和$kill_B$都已计算出来
输出:$IN[B]和OUT[B]$
方法:

3.2 示例
3.3 引用-定值链(Use-Definition Chains)
引用-定值链(简称$ud$链)是一个列表,对于变量的每一次引用,到达该引用的所有定值都在该列表中
- 如果块B中变量$a$的引用之前有$a$的定值,那么只有$a$的最后一次定值会在该引用的$ud$链中
- 如果块B中变量$a$的引用之前没有$a$的定值,那么$a$的这次引用的$ud$链就是$IN[B]$中$a$的定值的集合
4 参考
- 《MOOC-编译原理-陈鄞》