阅读更多
1 $FIRST$集和$FOLLOW$集的计算
1.1 $FIRST$集
首先回顾一下$FIRST$的定义
- $FIRST(X)$:可以从$X$推导出的所有串首终结符构成的集合
- 如果$X \Rightarrow^* \varepsilon$,那么$\varepsilon \in FIRST(X)$
1.1.1 算法
不断应用下列规则,直到没有新的终结符或$\varepsilon$可以被加入到任何$FIRST$集合中为止
- 如果$X$是一个终结符,那么$FIRST(X) = \{ X \}$
- 如果$X$是一个非终结符,且$X \to Y_1 ... Y_k \in P (k \ge 1)$,那么如果对于某个$i$,$a$在$FIRST(Y_i)$中且$\varepsilon$在所有的$FIRST(Y_1), ..., FIRST(Y_{i-1})$中(即$Y_1 ... Y_{i-1} \Rightarrow^* \varepsilon$),就把$a$加入到$FIRST(X)$中。如果对于所有的$j = 1, 2, ..., k,\varepsilon$在$FIRST(Y_j)$中,那么将$\varepsilon$加入到$FIRST(X)$
- 如果$X \to \varepsilon \in P$,那么将$\varepsilon$加入到$FIRST(X)$中
计算串$X_1 X_2 ... X_n$的$FIRST$集合(上述算法的另一种描述过程)
- 向$FIRST(X_1 X_2 ... X_n)$加入$FIRST(X_1)$中所有的非$\varepsilon$符号
- 如果$\varepsilon$在$FIRST(X_1)$中,再加入$FIRST(X_2)$中的所有非$\varepsilon$符号;如果$\varepsilon$在$FIRST(X_1)$和$FIRST(X_2)$中,再加入$FIRST(X_3)$中的所有非$\varepsilon$符号,以此类推
- 最后,如果对所有的$i$,$\varepsilon$都在$FIRST(X_i)$中,那么将$\varepsilon$加入到,$FIRST(X_1 X_2 ... X_n)$中
1.2 $FOLLOW$集
首先回顾一下$FOLLOW$的定义
- $FOLLOW(A)$:可能在某个句型中紧跟在$A$后边的终结符$a$的集合
- 如果A是某个句型的的最右符号,则将结束符$\$$添加到$FOLLOW(A)$中
1.2.1 算法
不断应用下列规则,直到没有新的终结符可以被加入到任何$FOLLOW$集合中为止
- 将$\$$放入$FOLLOW(S)$中,其中$S$是开始符号,$\$$是输入右端的结束标记
- 如果存在一个产生式$A \to \alpha B \beta $,那么$FIRST(\beta)$中除$\varepsilon$之外的所有符号都在$FOLLOW(B)$中
- 如果存在一个产生式$A \to \alpha B$,或存在产生式$A \to \alpha B \beta $且$FIRST(\beta)$包含$\varepsilon$,那么$FOLLOW(A)$中的所有符号都在$FOLLOW(B)$中
2 预测分析法
预测分析法$LL(1)$的分析方法包含如下两种
- 递归的预测分析法
- 非递归的预测分析法
2.1 递归的预测分析法
递归的预测分析法是指:在递归下降分析中,根据预测分析表进行产生式的选择
- 根据每个非终结符的产生式和$LL(1)$文法的预测分析表,为每个非终结符编写对应的过程

2.2 非递归的预测分析法
非递归的预测分析不需要为每个非终结符编写递归下降过程,而是根据预测分析表构造一个自动机,也叫表驱动的预测分析
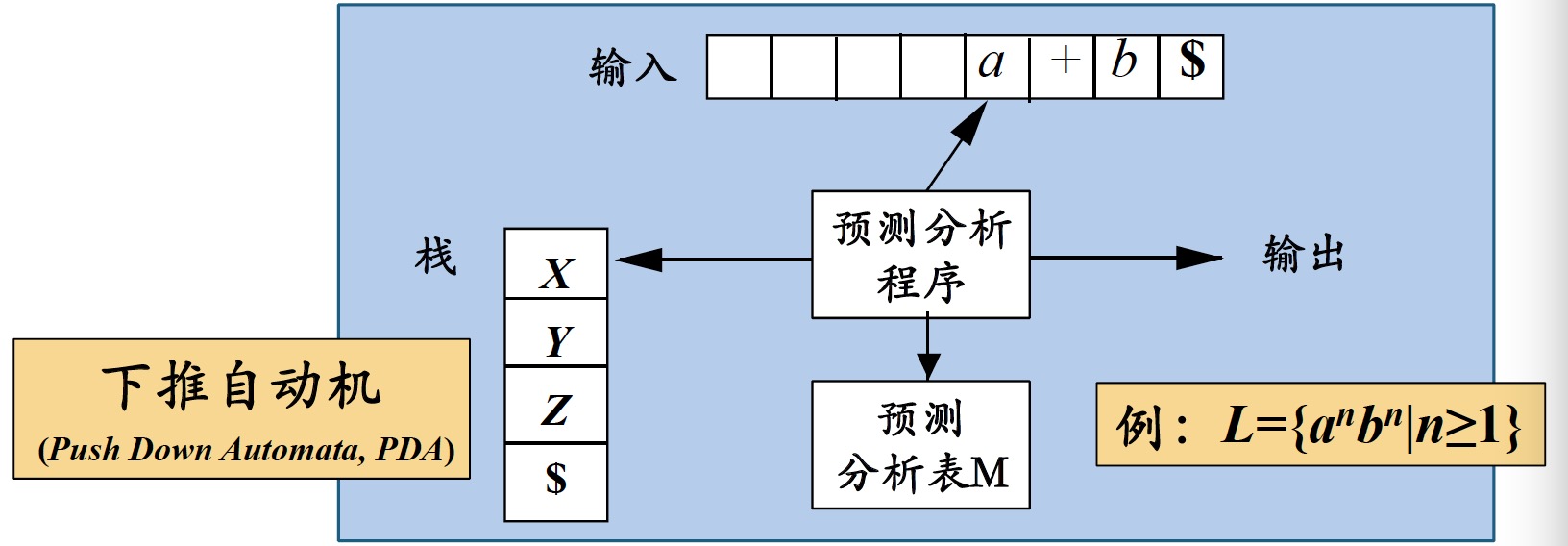
参考下面例子:
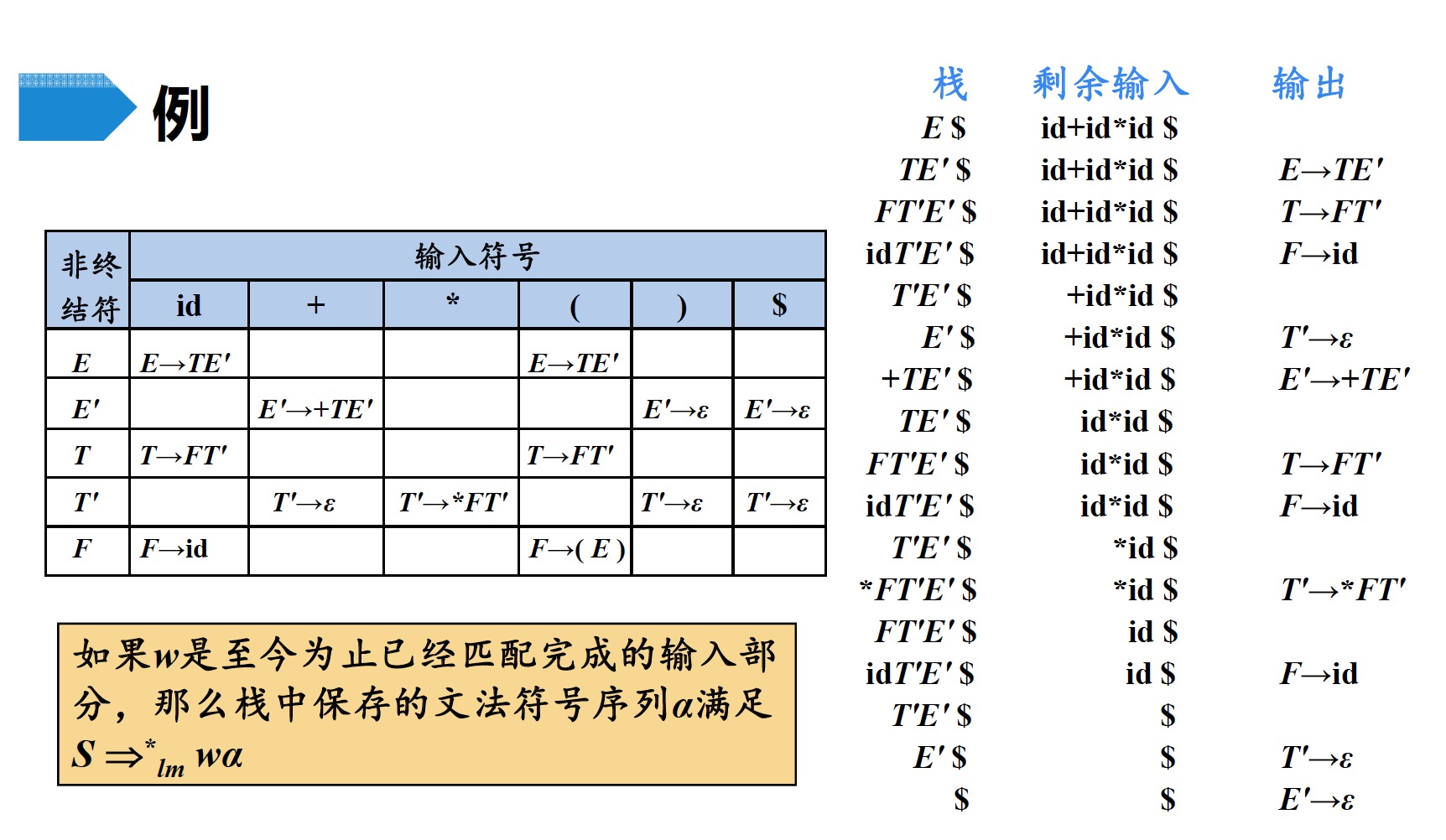
2.2.1 表驱动的预测分析法
输入:一个串$w$和文法$G$的分析表$M$
输出:如果$w$在$L(G)$中,输出$w$的最左推导;否则给出错误指示
方法:最初,语法分析器的格局如下:输入缓冲区中是$w\$$,$G$的开始符号位于栈顶
其下面是$\$$。下面的程序使用预测分析表$M$生成了处理这个输入的预测分析过程

2.3 递归与非递归预测分析法对比
| 递归的预测分析法 | 非递归的预测分析法 | |
|---|---|---|
| 程序规模 | 程序规模较大,不需载入分析表 | 主控程序规模较小,需载入分析表(表较小) |
| 直观性 | 较好 | 较差 |
| 效率 | 较低 | 分析时间大约正比于待分析程序的长度 |
| 自动生成 | 较难 | 较易 |
2.4 预测分析法实现步骤
- 构造文法
- 改造文法:消除二义性、消除左递归、消除回溯
- 求每个变量的$FIRST$集和$FOLLOW$集,从而求得每个候选式的$SELECT$集
- 检查是不是$LL(1)$文法。若是,构造预测分析表
- 对于递归的预测分析,根据预测分析表为每一个非终结符编写一个过程;对于非递归的预测分析,实现表驱动的预测分析算法
2.5 预测分析中的错误检测
两种情况下可以检测到错误
- 栈顶的终结符和当前输入符号不匹配
- 栈顶非终结符与当前输入符号在预测分析表对应项中的信息为空
恐慌模式
- 忽略输入中的一些符号,直到输入中出现由设计者选定的同步词法单元(synchronizing token)集合中的某个词法单元
- 其效果依赖于同步集合的选取。集合的选取应该使得语法分析器能从实际遇到的错误中快速恢复
- 例如可以把$FOLLOW(A)$中的所有终结符放入非终结符A的同步记号集合
- 如果终结符在栈顶而不能匹配,一个简单的办法就是弹出此终结符

带有同步记号的分析表的使用方法
- 如果$M[A,a]$是空,表示检测到错误,根据恐慌模式,忽略输入符号$a$
- 如果$M[A,a]$是$synch$,则弹出栈顶的非终结符$A$,试图继续分析后面的语法成分
- 如果栈顶的终结符和输入符号不匹配,则弹出栈顶的终结符
3 参考
- 《MOOC-编译原理-陈鄞》