阅读更多
1 内核态与用户态
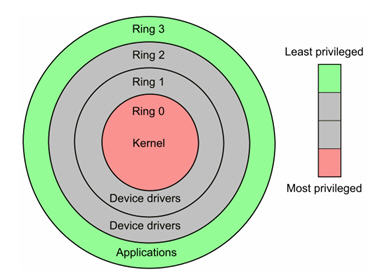
1.1 定义
用户态:
- Ring3运行于用户态的代码则要受到处理器的诸多检查,它们只能访问映射其地址空间的页表项中规定的在用户态下可访问页面的虚拟地址,且只能对任务状态段(TSS)中I/O许可位图(I/O Permission Bitmap)中规定的可访问端口进行直接访问
- 当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。此时处理器在特权级最低的(3级)用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈
内核态:
- Ring0在处理器的存储保护中,核心态,或者特权态(与之相对应的是用户态),是操作系统内核所运行的模式。运行在该模式的代码,可以无限制地对系统存储、外部设备进行访问
- 当一个任务(进程)执行系统调用而陷入内核代码中执行时,称进程处于内核运行态(内核态)。此时处理器处于特权级最高的(0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈(不仅进程,每个线程也有内核栈)
1.2 用户/内核态切换过程
进程从用户态到内核态切换过程中,Linux主要做的事:
- 读取tr寄存器,访问TSS段
- 从TSS段中的sp0获取进程内核栈的栈顶指针
- 由控制单元在内核栈中保存当前eflags,cs,ss,eip,esp寄存器的值
- 由SAVE_ALL保存其寄存器的值到内核栈
- 把内核代码选择符写入CS寄存器,内核栈指针写入ESP寄存器,把内核入口点的线性地址写入EIP寄存器
此时,CPU已经切换到内核态,根据EIP中的值开始执行内核入口点的第一条指令
1.3 用户态切换到内核态的3种方式
这3种方式是系统在运行时由用户态转到内核态的最主要方式,其中系统调用可以认为是用户进程主动发起的,异常和外围设备中断则是被动的
- 系统调用:这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作。而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的int 80h中断
- 异常:当CPU在执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行进程切换到处理此异常的内核相关程序中,也就转到了内核态,比如缺页异常、除零异常等
- 外围设备的中断:当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等
2 进程上下文Context
用户空间的应用程序,通过系统调用,进入内核空间。这个时候用户空间的进程要传递很多变量、参数的值给内核,内核态运行的时候也要保存用户进程的一些寄存器值、变量等。所谓的"进程上下文",可以看作是用户进程传递给内核的这些参数以及内核要保存的那一整套的变量和寄存器值和当时的环境等。
相对于进程而言,就是进程执行时的环境。具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文
- 用户级上下文:正文、数据、用户堆栈以及共享存储区
- 寄存器上下文:通用寄存器、指令指针寄存器(EIP)、处理器状态寄存器(EFLAGS)、栈指针(ESP)
- 系统级上下文:进程控制块
task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈
当发生进程调度时,进行进程切换就是上下文切换(context switch)。操作系统必须对上面提到的全部信息进行切换,新调度的进程才能运行。而系统调用进行的模式切换(mode switch)。模式切换与进程切换比较起来,容易很多,而且节省时间,因为模式切换最主要的任务只是切换进程寄存器上下文的切换
硬件通过触发信号,导致内核调用中断处理程序,进入内核空间。这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。所谓的"中断上下文",其实也可以看作就是硬件传递过来的这些参数和内核需要保存的一些其他环境(主要是当前被打断执行的进程环境)。中断时,内核不代表任何进程运行,它一般只访问系统空间,而不会访问进程空间,内核在中断上下文中执行时一般不会阻塞
3 系统调用的场景
系统调用是给操作系统通信用的。顺便说一句,操作系统的职责是进程管理、地址空间管理、设备管理、文件管理等。所以,用到系统调用的大多是:
- 让当前进程/线程睡觉,或让别的进程/线程醒来(进程管理)
- 内存映射,粗粒度地大块分配内存(内存管理)
- 对键盘、鼠标、硬盘、网络、显示器什么的进行操作(设备管理)
- 读写文件(文件管理)
如果不需要和操作系统通信,就不需要系统调用。比如:
- malloc,动态分配内存。偶尔需要和操作系统通信申请大块内存,但在当前进程已经有足够的内存的情况下,是不用系统调用的
- spin lock。就是通过循环来进行的锁操作。它靠CPU的原子内存操作来实现互斥,也不需要系统调用。但是,如果是blocking lock,就是那种如果无法获取,就阻塞等待的那种锁,就需要,因为要告诉操作系统“请让我停下来,然后在锁准备好的时候叫醒我”
- 写文件。如果是用内存映射的形式写文件,那么只要一开始用mmap系统调用映射内存,到最后用系统调用同步一下,中间就是普通的内存读写了,也不需要系统调用。但是,如果你用write函数,那么……没准,看操作系统如何实现了
- 共享内存的进程间通信。和写文件一样,建立内存映射的过程需要系统调用,就是让两个进程的地址空间有重叠。但是,一旦建立好了,只要写内存就可以了,另一个进程是可以看到写入的内容的,因为本质就是从同样的物理内存地址读东西
- math.h里的东西。这些东西就是数值运算,会翻译成特殊CPU指令,但不是系统调用
- 异常处理(C++的throw、catch什么的),这些是特殊的控制流,可能需要特殊的库函数来做,这些库函数知道编译器生成的代码和栈的形状。但这完全在用户态就能做了,还是不涉及系统调用
- C标准库里的数据结构(数组、链表、映射什么的)和算法(查找、排序…),就是普通的C代码实现的
- 字符串处理函数(strcmp,strcpy,strcat,strstr什么的)还有内存拷贝(memcpy,memset什么的),有可能会为了性能而用汇编实现,但还是不需要系统调用
4 系统调用实现机制
4.1 概述
计算机系统的各种硬件资源是有限的,在现代多任务操作系统上同时运行的多个进程都需要访问这些资源。为了更好的管理这些资源,进程是不允许直接操作这些资源的,所有对这些资源的访问都必须有操作系统控制。也就是说操作系统是使用这些资源的唯一入口,而这个入口就是操作系统提供的系统调用(System Call)。
系统调用是属于操作系统内核的一部分的,必须以某种方式提供给进程让它们去调用。CPU可以在不同的特权级别下运行,而相应的操作系统也有不同的运行级别,用户态和内核态。运行在内核态的进程可以毫无限制的访问各种资源,而在用户态下的用户进程的各种操作都有着限制,比如不能随意的访问内存、不能开闭中断以及切换运行的特权级别。显然,属于内核的系统调用一定是运行在内核态下
但是如何切换到内核态呢?答案是中断。操作系统一般是通过中断从用户态切换到内核态。中断就是一个硬件或软件请求,要求CPU暂停当前的工作,去处理更重要的事情。比如,在x86机器上可以通过int指令进行软件中断,而在磁盘完成读写操作后会向CPU发起硬件中断
中断有两个重要的属性,中断号和中断处理程序。中断号用来标识不同的中断,不同的中断具有不同的中断处理程序。在操作系统内核中维护着一个中断向量表(Interrupt Vector Table),这个数组存储了所有中断处理程序的地址,而中断号就是相应中断在中断向量表中的偏移量
一般地,系统调用都是通过中断实现的,比如,Linux下中断号0x80就是进行系统调用的。接下来就来看一下linux下系统调用具体的实现过程
4.2 Linux下系统调用的实现
前文已经提到了Linux下的系统调用是通过0x80实现的,但是我们知道操作系统会有多个系统调用(Linux下有319个系统调用),而对于同一个中断号是如何处理多个不同的系统调用的?最简单的方式是对于不同的系统调用采用不同的中断号,但是中断号明显是一种稀缺资源,Linux显然不会这么做;还有一个问题就是系统调用是需要提供参数,并且具有返回值的,这些参数又是怎么传递的?也就是说,对于系统调用我们要搞清楚两点:
- 系统调用的函数名称转换
- 系统调用的参数传递
首先看第一个问题。实际上,Linux中处理系统调用的方式与中断类似。每个系统调用都有相应的系统调用号作为唯一的标识,内核维护一张系统调用表,表中的元素是系统调用函数的起始地址,而系统调用号就是系统调用在调用表的偏移量。在进行系统调用是只要指定对应的系统调用号,就可以明确的要调用哪个系统调用,这就完成了系统调用的函数名称的转换。举例来说,Linux中fork的调用号是2(下载Linux内核源码,下载地址,然后find . -name unistd_32.h查找该文件路径,所有的系统调用编号都定义在该文件中)
下面是部分系统调用的编号
1 |
Linux中是通过寄存器%eax传递系统调用号,所以具体调用fork的过程是:将2存入%eax中,然后进行系统调用,伪代码如下
1 | mov eax, 2 |
对于参数传递,Linux也是通过寄存器完成的。Linux最多允许向系统调用传递6个参数,分别依次由%ebx,%ecx,%edx,%esi,%edi和%ebp这个6个寄存器完成。比如,调用exit(1),伪代码是:
1 | mov eax, 1 |
因为exit需要一个参数1,所以这里只需要使用ebx。这6个寄存器可能已经被使用,所以在传参前必须把当前寄存器的状态保存下来,待系统调用返回后再恢复,这个在后面栈切换再具体讲
Linux中,在用户态和内核态运行的进程使用的栈是不同的,分别叫做用户栈和内核栈,两者各自负责相应特权级别状态下的函数调用。当进行系统调用时,进程不仅要从用户态切换到内核态,同时也要完成栈切换,这样处于内核态的系统调用才能在内核栈上完成调用。系统调用返回时,还要切换回用户栈,继续完成用户态下的函数调用
寄存器%esp(栈指针,指向栈顶)所在的内存空间叫做当前栈,比如%esp在用户空间则当前栈就是用户栈,否则是内核栈。栈切换主要就是%esp在用户空间和内核空间间的来回赋值。在Linux中,每个进程都有一个私有的内核栈,当从用户栈切换到内核栈时,需完成保存%esp以及相关寄存器的值(%ebx,%ecx…)并将%esp设置成内核栈的相应值。而从内核栈切换会用户栈时,需要恢复用户栈的%esp及相关寄存器的值以及保存内核栈的信息。一个问题就是用户栈的%esp和寄存器的值保存到什么地方,以便于恢复呢?答案就是内核栈,在调用int指令机型系统调用后会把用户栈的%esp的值及相关寄存器压入内核栈中,系统调用通过iret指令返回,在返回之前会从内核栈弹出用户栈的%esp和寄存器的状态,然后进行恢复