macros are preprocessor directives, and they get processed before the actual compilation phase. One of the most common preprocessor directives is #define which is used to define macros.
If you want to change a macro definition at compile time, there are several ways to do it:
Using Compiler Flags: You can use the -D flag (for most compilers like GCC and Clang) to define macros.
g++ your_file.cpp -o output -DMY_MACRO='"Compile Time Value"'
When you run the output, it will print “Compile Time Value”.
Using Conditional Compilation: This is where you use #ifdef, #ifndef, #else, and #endif directives to conditionally compile parts of your code based on whether a certain macro is defined or not.
intmain(){ type = HashMapVariantType::_int; dispatch(); type = HashMapVariantType::_long; dispatch(); type = HashMapVariantType::_double; dispatch(); return0; }
If, during scanning (or rescanning) an identifier is found, it is looked up in the symbol table. If the identifier is not found in the symbol table, it is not a macro and scanning continues.
If the identifier is found, the value of a flag associated with the identifier is used to determine if the identifier is available for expansion. If it is not, the specific token (i.e. the specific instance of the identifier) is marked as disabled and is not expanded. If the identifier is available for expansion, the value of a different flag associated with the identifier in the symbol table is used to determine if the identifier is an object-like or function-like macro. If it is an object-like macro, it is expanded. If it is a function-like macro, it is only expanded if the next token is an left parenthesis.
An identifier is available for expansion if it is not marked as disabled and if the the value of the flag associated with the identifier is not set, which is used to determine if the identifier is available for expansion.
If a macro is an object-like macro, skip past the next two paragraphs.
If a macro to be expanded is a function-like macro, it must have the exact number of actual arguments as the number of formal parameters required by the definition of the macro. Each argument is recursively scanned and expanded. Each parameter name found in the replacement list is replaced by the expanded actual argument after leading and trailing whitespace and all placeholder tokens are removed unless the parameter name immediately follows the stringizing operator (#) or is adjacent to the token-pasting operator (##).
If the parameter name immediately follows the stringizing operator (#), a stringized version of the unexpanded actual argument is inserted. If the parameter name is adjacent to the token-pasting operator (##), the unexpanded actual argument is inserted after all placeholder tokens are removed.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
// Concat x and y, both parameters won't be expanded before concatenation, and the result of concatenation can be expanded if possible #define TOKEN_CONCAT(x, y) x##y // Make sure x and y are fully expanded #define TOKEN_CONCAT_FORWARD(x, y) TOKEN_CONCAT(x, y)
#define DEFINE_INT_1 int prefix_1_##__LINE__ #define DEFINE_INT_2 int TOKEN_CONCAT(prefix_2_, __LINE__) #define DEFINE_INT_3 int TOKEN_CONCAT_FORWARD(prefix_3_, __LINE__) #define LINE_NUMBER_AS_VALUE TOKEN_CONCAT(__LINE, __)
For DEFINE_INT_1, DEFINE_INT_2 and DEFINE_INT_3, only DEFINE_INT_3 works as we expected.
when you use TOKEN_CONCAT or # directly with macro arguments, it won’t expand those arguments before concatenation. This means if x or y are themselves macros, they will not be expanded before concatenation.
The TOKEN_CONCAT_FORWARD macro is a forward macro that ensures its arguments are fully expanded before passing them to TOKEN_CONCAT
For LINE_NUMBER_AS_VALUE, the expansion happens after the concatenation.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
gcc -E main.cpp # 0 "main.cpp" # 0 "<built-in>" # 0 "<command-line>" # 1 "/usr/include/stdc-predef.h" 1 3 4 # 0 "<command-line>" 2 # 1 "main.cpp" # 11 "main.cpp" int main() { int prefix_1___LINE__ = 1; int prefix_2___LINE__ = 2; int prefix_3_14 = 3; int i4 = 15; return 0; }
using Container = std::vector<int32_t>; using ContainerPtr = std::shared_ptr<Container>;
voidappend_by_const_reference_shared_ptr(const ContainerPtr& container, constint num){ // can calling non-const member function container->push_back(num); }
voidappend_by_const_reference(const Container& container, constint num){ // cannot calling non-const member function // container.push_back(num); }
voidappend_by_bottom_const_pointer(const Container* container, constint num){ // cannot calling non-const member function // container->push_back(num); }
voidappend_by_top_const_pointer(Container* const container, constint num){ // can calling non-const member function container->push_back(num); }
When used in the declaration specifier sequence for functions, it declares the function as an inline function
A complete definition within a class/struct/union that is attached to the global module (since C++20) is implicitly an inline function, whether it is a member function or a non-member friend function
The original intent of the inline keyword was to serve as a hint to the optimizer to prefer inlining the function rather than invoking it through a function call—that is, instead of executing a CPU instruction that transfers control to the function body, the function body is copied in place without creating a call. This avoids function call overhead (passing arguments and returning results), but may lead to a larger executable since the function body must be duplicated multiple times
Because the inline keyword is non-mandatory, the compiler has the freedom to inline any function not marked as inline, and to generate a function call for any function marked as inline. These optimization decisions do not affect the rules regarding multiple definitions and shared static variables mentioned above
Functions declared with constexpr are implicitly inline functions
When used in the declaration specifier sequence for variables with static storage duration (static class members or namespace-scope variables), it declares the variable as an inline variable
Static member variables declared as constexpr (but not namespace-scope variables) are implicitly inline variables
3.3 Type Length
3.3.1 Memory Alignment
The most fundamental reason for memory alignment is that memory I/O is performed in units of 8 bytes, or 64 bits.
Suppose you request to access memory from 0x0001-0x0008, which is also 8 bytes but does not start at address 0. How does memory handle this? There’s no easy solution. The memory must first fetch 0x0000-0x0007, then fetch 0x0008-0x0015, and return the results of both operations to you. Due to hardware limitations of the CPU and memory I/O, it’s not possible to perform an I/O operation that spans across two data width boundaries. As a result, your application slows down — a small penalty imposed by the computer because you didn’t understand memory alignment.
Memory Alignment Rules
The offset of the first member of a structure is 0. For all subsequent members, the offset relative to the start address of the structure must be an integer multiple of the smaller of the member’s size and the effective alignment value. If necessary, the compiler will insert padding bytes between members.
The total size of the structure must be an integer multiple of the effective alignment value. If necessary, the compiler will add padding bytes after the last member.
Effective alignment value: the smaller of the value specified by #pragma pack(n) and the size of the largest data type in the structure. This value is also called the alignment unit. In GCC, the default is #pragma pack(4), and this value can be changed using the preprocessor directive #pragma pack(n), where n can be 1, 2, 4, 8, or 16.
Since the offset of each member must be an integer multiple of the smaller of that member’s size and the effective alignment value, we’ll refer to this smaller value as the member effective alignment value below.
Align1: The longest data type has a length of 1, and pack = 4, so the effective alignment value is min(1, 4) = 1
Rule 1:
f1, the first member, has offset = 0
Rule 2:
The total type length is 1, which is a multiple of the effective alignment value (1)
Align2: The longest data type has a length of 2, and pack = 4, so the effective alignment value is min(2, 4) = 2
Rule 1:
f1, the first member, has offset = 0
f2 has a type length of 2, so its member effective alignment value is min(2, 2) = 2. offset = 2 is a multiple of the member effective alignment value (2)
Rule 2:
The total type length is 4, which is a multiple of the effective alignment value (2)
Align3: The longest data type has a length of 4, and pack = 4, so the effective alignment value is min(4, 4) = 4
Rule 1:
f1, the first member, has offset = 0
f2 has a type length of 2, so its member effective alignment value is min(2, 4) = 2. offset = 2 is a multiple of the member effective alignment value (2)
f3 has a type length of 4, so its member effective alignment value is min(4, 4) = 4. offset = 4 is a multiple of the member effective alignment value (4)
Rule 2:
The total type length is 8, which is a multiple of the effective alignment value (4)
Align4: The longest data type has a length of 8, and pack = 4, so the effective alignment value is min(8, 4) = 4
Rule 1:
f1, the first member, has offset = 0
f2 has a type length of 2, so its member effective alignment value is min(2, 4) = 2. offset = 2 is a multiple of the member effective alignment value (2)
f3 has a type length of 4, so its member effective alignment value is min(4, 4) = 4. offset = 4 is a multiple of the member effective alignment value (4)
f4 has a type length of 8, so its member effective alignment value is min(8, 4) = 4. offset = 8 is a multiple of the member effective alignment value (4)
Rule 2:
The total type length is 16, which is a multiple of the effective alignment value (4)
sizeof is used to query size of the object or type.
sizeof(int32_t):4
sizeof(char[2][2][2]):8
3.3.3 alignof
alignof is used to obtain the effective alignment value of an object. alignas is used to set the effective alignment value (it cannot be less than the default effective alignment value).
// Compile error // Requested alignment is less than minimum int alignment of 4 for type 'Foo2' // struct alignas(1) Foo2 { // char c; // int32_t i32; // };
// Compile error // Requested alignment is less than minimum int alignment of 4 for type 'Foo3' // struct alignas(2) Foo3 { // char c; // int32_t i32; // };
The alignas type specifier is a portable C++ standard method used to specify the alignment of variables and user-defined types. It can be used when defining a class, struct, union, or when declaring a variable. If multiple alignas specifiers are encountered, the compiler will choose the strictest one (i.e., the largest alignment value).
Memory alignment allows the processor to better utilize the cache, including reducing cache line accesses and avoiding cache miss penalties caused by multi-core consistency issues. Specifically, in multithreaded programs, a common optimization technique is to align frequently accessed concurrent data according to the cache line size (usually 64 bytes). On one hand, for data smaller than 64 bytes, this ensures that only one cache line is touched, reducing memory access. On the other hand, it effectively dedicates an entire cache line to that data, preventing other data from sharing the same cache line and causing cache miss in other cores due to potential modifications.
Arrays: When alignas is applied to an array, it aligns the starting address of the array, not each individual array element. That means the following array does not allocate 64 bytes for each int. To align each element, you can define a struct, such as int_align_64.
In C++, storage classes determine the scope, visibility, and lifetime of variables. There are four storage classes in C++:
Automatic Storage Class (default): Variables declared within a block or function without specifying a storage class are considered to have automatic storage class. These variables are created when the block or function is entered and destroyed when the block or function is exited. The keyword “auto” can also be used explicitly, although it is optional.
Static Storage Class: Variables with static storage class are created and initialized only once, and their values persist across function calls. They are initialized to zero by default. Static variables can be declared within a block or function, but their scope is limited to that block or function. The keyword “static” is used to specify static storage class.
Register Storage Class (deprecated): The register storage class is used to suggest that a variable be stored in a register instead of memory. The keyword “register” is used to specify register storage class. However, the compiler is free to ignore this suggestion.
Extern Storage Class: The extern storage class is used to declare a variable that is defined in another translation unit (source file). It is often used to provide a global variable declaration that can be accessed from multiple files. When using extern, the variable is not allocated any storage, as it is assumed to be defined elsewhere. The keyword “extern” is used to specify extern storage class.
Here’s an example illustrating the usage of different storage classes:
Static storage duration specifier with external linkage
This symbol is defined in another compilation unit, which means it needs to be placed in the unresolved symbol table (external linkage)
Language linkage specification, to avoid name mangling
extern "C" {}
Explicit template instantiation declaration
For class templates
For function templates
3.6.1.2.1 Shared Global Variable
Each source file must have a declaration of the variable, but only one source file can contain the definition of the variable. A common approach is as follows:
Define a header file xxx.h that declares the variable (using the extern keyword)
Implementation principle (speculated): Variables modified with thread_local are stored at the beginning of each thread’s stack space (high address, since the stack allocates memory from top to bottom). The following program will be used to verify this hypothesis:
auto distance = addr_t1 - addr_t2; std::cout << "addr distance between t1 and t2 is: " << distance << std::endl; return0; }
In my environment, the output is as follows:
1 2 3 4 5 6 7
main_thread_local: 0x7f190e1a573c main_local: 0x7fff425e1dd4 t1_thread_local: 0x7f190e1a463c t1_local: 0x7f190e1a3ddc t2_thread_local: 0x7f190d9a363c t2_local: 0x7f190d9a2ddc addr distance between t1 and t2 is: 8392704
It can be observed that in different threads, the memory address of value is different and located at a high address. For two adjacent threads, the difference in the address of value is approximately equal to the size of the stack space (ulimit -s).
The constructor is called twice because both threads go through the declaration of the foo variable, so each will allocate storage space and perform initialization.
The constructor is called once because only the main thread goes through the declaration of the foo variable, so it allocates storage space and performs initialization. The t1 thread does not go through the declaration of the foo variable, so it only allocates storage space without initialization.
A name can have external linkage, module linkage(since C++20), internal linkage, or no linkage:
An entity whose name has external linkage can be redeclared in another translation unit, and the redeclaration can be attached to a different modul(since C++20).
An entity whose name has module linkage can be redeclared in another translation unit, as long as the redeclaration is attached to the same module(since C++20).
An entity whose name has internal linkage can be redeclared in another scope in the same translation unit.
An entity whose name has no linkage can only be redeclared in the same scope.
3.7 Inheritance and Polymorphism
3.7.1 Inheritance Modes
Inheritance mode\member permissions
public
protected
private
public inherit
public
protected
invisible
protected inherit
protected
protected
invisible
private inherit
private
private
invisible
Regardless of the inheritance method, you can access the public and protected members of the parent class, but their access rights will be modified according to the inheritance method, thus affecting the access rights of the derived class.
Most importantly, only public inheritance can achieve polymorphism
Specifies whether a function could throw exceptions.
noexcept(true)
noexcept(false)
noexcept same as noexcept(true)
Non-throwing functions are permitted to call potentially-throwing functions. Whenever an exception is thrown and the search for a handler encounters the outermost block of a non-throwing function, the function std::terminate is called:
An exception throw by a noexcept function cannot be normally catched.
void *buf = // 在这里为buf分配内存 Class *pc = new (buf) Class();
4 Syntax
4.1 Initialization
4.1.1 Initialization Types
Default initialization: type variableName;
Direct initialization / Constructor initialization (with at least one argument): type variableName(args);
List initialization: type variableName{args};
Essentially, list initialization calls the corresponding constructor (matching the argument types and number) for initialization.
One of its advantages is that it can simplify the return statement, allowing return {args}; directly.
Copy initialization:
type variableName = otherVariableName, essentially calls the copy constructor.
type variableName = <type (args)>, where <type (args)> refers to a function that returns a type. It seems like the copy constructor would be called, but the compiler optimizes this form of initialization, meaning only the constructor is called within the function (if applicable), and the = does not call any constructor.
Value initialization: type variableName()
For built-in types, initialized to 0 or nullptr.
For class types, equivalent to default initialization. Testing shows that no constructor is actually called.
The initialization process is equivalent to the following program, where:
guard_for_bar is an integer variable used to ensure thread safety and one-time initialization. It is generated by the compiler and stored in the bss segment. The lowest byte of this variable serves as a flag indicating whether the corresponding static variable has been initialized. If it is 0, it means the variable has not been initialized yet; otherwise, it means it has been initialized.
__cxa_guard_acquire is essentially a locking process, while __cxa_guard_abort and __cxa_guard_release release the lock.
__cxa_atexit registers a function to be executed when exit is called or when a dynamic library (or shared library) is unloaded. In this case, the destructor of Bar is registered.
// Using a pointer to a 2D array voidyourFunction1(bool (*rows)[9]){ // Access elements of the 2D array for (int i = 0; i < 9; i++) { for (int j = 0; j < 9; j++) { std::cout << rows[i][j] << " "; } std::cout << std::endl; } }
// Using a reference to a 2D array voidyourFunction2(bool (&rows)[9][9]){ // Access elements of the 2D array for (int i = 0; i < 9; i++) { for (int j = 0; j < 9; j++) { std::cout << rows[i][j] << " "; } std::cout << std::endl; } }
intmain(){ bool rows[9][9] = { // Initialize the array as needed };
// Pass the local variable to the functions yourFunction1(rows); yourFunction2(rows);
return0; }
4.3 Reference
4.3.1 Reference Initialization
References can only be initialized at the point of definition.
For built-in types, a direct value copy is made. There’s no difference between using an initializer list or initializing within the constructor body.
For class types:
Initializing in the initializer list: Calls either the copy constructor or the move constructor.
Initializing in the constructor body: Even though it’s not explicitly specified in the initializer list, the default constructor is still called to initialize it, followed by the use of the copy or move assignment operator within the constructor body.
What must be placed in the initializer list:
Constant members
Reference types
Class types without a default constructor, because using the initializer list avoids the need to call the default constructor and instead directly calls the copy or move constructor for initialization.
Non-static members are not allowed to use constructor initialization, but they are allowed to use list initialization (which essentially still calls the corresponding constructor).
4.4.5 Non-static members of a Class cannot undergo type deduction
Non-static members of a class cannot undergo type deduction; the type must be explicitly specified (as the type information must be immutable). Static members, however, can. For example, the following code contains a syntax error:
private: inlinestatic Delegate _s_delegate{Foo::do_something}; // Use of class template 'Delegate' requires template arguments // Argument deduction not allowed in non-static class member (clang auto_not_allowed Delegate _delegate; };
4.4.6 Member Function Pointer
Member function pointers need to be invoked using the .* or ->* operators.
Inside the class: (this->*<name>)(args...)
Outside the class: (obj.*obj.<name>)(args...) or (pointer->*pointer-><name>)(args...)
// invoke outside class with obj (demo1.*demo1.say_hi)();
// invoke outside class with pointer Demo *p1 = &demo1; (p1->*p1->say_hi)();
// invoke outside class with pointer std::shared_ptr<Demo> sp1 = std::make_shared<Demo>(false); (sp1.get()->*sp1->say_hi)(); }
4.4.7 Mock class
Sometimes during testing, we need to mock the implementation of a class. We can implement all the methods of this class (note, it must be all methods) in the test .cpp file, which will override the implementation in the original library. Below is an example:
Allows a function to accept any number of extra arguments.
Within the body of a function that uses variadic arguments, the values of these arguments may be accessed using the <cstdarg> library facilities:
va_start: enables access to variadic function arguments
va_arg: accesses the next variadic function argument
va_copy: makes a copy of the variadic function arguments
va_end: ends traversal of the variadic function arguments
va_list: holds the information needed by va_start, va_arg, va_end, and va_copy
Example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#include<cstdarg> #include<iostream>
intsum(int count, ...){ int result = 0; va_list args; va_start(args, count); for (int i = 0; i < count; i++) { result += va_arg(args, int); } va_end(args); return result; }
intsum(int count, ...){ int result = 0; va_list args; va_start(args, count); for (int i = 0; i < count; i++) { result += va_arg(args, int); } va_end(args); return result; }
intmain(){ int val1 = 1, val2 = 2, val3 = 3; IntWrap wrap1{&val1}, wrap2{&val2}, wrap3{&val3}; { // Implicit type conversion not happen int res = sum(3, wrap1, wrap2, wrap3); std::cout << res << std::endl; } { // Explicit type conversion works int res = sum(3, static_cast<int>(wrap1), static_cast<int>(wrap2), static_cast<int>(wrap3)); std::cout << res << std::endl; } { // Implicit type conversion works int res = sum_template(wrap1, wrap2, wrap3); std::cout << res << std::endl; } return0; }
4.7 Attributes
__attribute__ is a feature specific to the GCC compiler that allows programmers to provide the compiler with certain instructions to optimize during compilation or apply additional constraints during runtime. These instructions are called attributes (attributes) and can be applied to various program elements such as functions, variables, and types.
C++11 introduced a new language feature called attributes (attributes), which are similar to __attribute__ but are part of the standard C++, making them usable in C++ code after the compiler supports C++11. Unlike __attribute__, C++11 attributes can be used at the class and namespace levels, not just at the function and variable levels.
C++11 attributes also provide more flexibility and readability. They can be embedded in the code in a more natural way, unlike __attribute__, which requires some verbose syntax. Additionally, C++11 attributes offer some useful new features such as [[noreturn]], [[carries_dependency]], [[deprecated]], [[fallthrough]].
Common __attribute__ list:
__attribute__((packed)): Instructs the compiler to pack structure members as tightly as possible to reduce the memory footprint of the structure.
__attribute__((aligned(n))): Instructs the compiler to align a variable to an n-byte boundary.
__attribute__((noreturn)): Instructs the compiler that the function will not return, which is used to inform the compiler that no cleanup is needed after the function call.
__attribute__((unused)): Instructs the compiler not to issue a warning for unused variables.
__attribute__((deprecated)): Instructs the compiler that the function or variable is deprecated, and the compiler will issue a warning when they are used.
__attribute__((visibility("hidden"))): Instructs the compiler to hide the symbol, meaning it will not appear in the exported symbol table of the current compilation unit.
__attribute__((guarded_by(mutex))): is used to annotate a data member (usually a class member variable) to indicate that it is protected by a specific mutex. This attribute acts as a directive to the compiler or static analysis tools to help ensure thread safety.
__attribute__(alias): Allows you to specify the name of a function or variable as an alias for an existing function or variable. It can serve a similar purpose as the linker parameter --wrap=<symbol>.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
#include<stdio.h>
FILE* my_fopen(constchar* path, constchar* mode){ printf("This is my fopen!\n"); returnNULL; }
intmain(){ printf("Calling the fopen() function...\n"); FILE* fd = fopen("test.txt", "r"); if (!fd) { printf("fopen() returned NULL\n"); return1; } printf("fopen() succeeded\n"); return0; }
Common attributes list:
[[noreturn]] (C++11): Indicates that a function will not return. If a function is marked with [[noreturn]], the compiler will issue a warning or error for any attempt to return a value from that function.
[[deprecated]] (C++14): Indicates that a function or variable is deprecated. The compiler will issue a warning when a function or variable marked with [[deprecated]] is called or used.
[[fallthrough]] (C++17): Used to indicate a case label in a switch statement, signaling that the code intentionally falls through to the next case label.
[[nodiscard]] (C++17): Indicates that the return value of a function should be checked. When a function is marked with [[nodiscard]], the compiler will issue a warning if the return value is not checked.
[[maybe_unused]] (C++17): Indicates that a variable or function may be unused. The compiler will not issue a warning for unused variables or functions.
[[likely]] (C++20): Hints to the compiler that this branch is likely to be true.
[[unlikely]] (C++20): Hints to the compiler that this branch is likely to be false.
The lambda expression is a prvalue expression of unique unnamed non-union non-aggregate class type, known as closure type, which is declared (for the purposes of ADL) in the smallest block scope, class scope, or namespace scope that contains the lambda expression. The closure type has the following members, they cannot be explicitly instantiated, explicitly specialized, or (since C++14) named in a friend declaration
// Must use reference to capture itself recursiveLambda = [&recursiveLambda](int x) { std::cout << x << std::endl; if (x > 0) recursiveLambda(x - 1); };
The operand of the unary + operator shall be a prvalue of arithmetic, unscoped enumeration, or pointer type and the result is the value of the argument. Integral promotion is performed on integral or enumeration operands. The type of the result is the type of the promoted operand.
The type of a lambda-expression (which is also the type of the closure object) is a unique, unnamed non-union class type, called the closure type, whose properties are described below.
The closure type for a lambda-expression with no lambda-capture has a public non-virtual non-explicit const conversion function to pointer to function having the same parameter and return types as the closure type’s function call operator. The value returned by this conversion function shall be the address of a function that, when invoked, has the same effect as invoking the closure type’s function call operator.
Explicit cast to C-style function pointer by using unary operator +:
This is necessary in some cases like libcurl when you setting up the callback.
And in most cases, the labmda will automatically cast to C-style function pointer where there needs a C-style function pointer.
using AddFunType = int (*)(int, int); using NegativeFunType = int (*)(int);
enumOperatorType { ADD = 0, NEGATIVE = 1, };
intinvoke_operator(OperatorType op, ...){ va_list args; va_start(args, op); switch (op) { case ADD: { AddFunType add_func = va_arg(args, AddFunType); int num1 = va_arg(args, int); int num2 = va_arg(args, int); va_end(args); returnadd_func(num1, num2); } case NEGATIVE: { NegativeFunType negative_func = va_arg(args, NegativeFunType); int num = va_arg(args, int); va_end(args); returnnegative_func(num); } default: throw std::logic_error("Invalid operator type"); } }
intmain(){ { // Must use + to explicitly convert lambda to function pointer, otherwise it may crash auto lambda_add = +[](int num1, int num2) { return num1 + num2; }; int num1 = 1; int num2 = 2; auto ret = invoke_operator(OperatorType::ADD, lambda_add, num1, num2); std::cout << num1 << " + " << num2 << " = " << ret << std::endl; } { // Must use + to explicitly convert lambda to function pointer, otherwise it may crash auto lambda_negative = +[](int num) { return -num; }; int num = 1; auto ret = invoke_operator(OperatorType::NEGATIVE, lambda_negative, num); std::cout << "-(" << num << ") = " << ret << std::endl; } return0; }
A coroutine is a generalization of a function that can be exited and later resumed at specific points. The key difference from functions is that coroutines can maintain state between suspensions.
co_yield: Produces a value and suspends the coroutine. The coroutine can be later resumed from this point.
co_return: Ends the coroutine, potentially returning a final value.
co_await: Suspends the coroutine until the awaited expression is ready, at which point the coroutine is resumed.
A coroutine consists of:
A wrapper type
A type with the exact name promise_type inside the return type of coroutine(the wrapper type), this type can be:
Type alias
A typedef
Directly declare an inner class
An awaitable type that comes into play once we use co_await
An interator
Key Observation: A coroutine in C++ is an finite state machine(FSM) that can be controlled and customized by the promise_type
Coroutine Classifications:
Task: A coroutine that does a job without returning a value.
Generator: A coroutine that does a job and returns a value(either by co_return or co_yield)
4.10.1 Overview of promise_type
The promise_type for coroutines in C++20 can have several member functions which the coroutine machinery recognizes and calls at specific times or events. Here’s a general overview of the structure and potential member functions:
Stored Values or State: These are member variables to hold state, intermediate results, or final values. The nature of these depends on the intended use of your coroutine.
Coroutine Creation:
auto get_return_object() -> CoroutineReturnObject: Defines how to obtain the return object of the coroutine (what the caller of the coroutine gets when invoking the coroutine).
Coroutine Lifecycle:
std::suspend_always/std::suspend_never initial_suspend() noexcept: Dictates if the coroutine should start executing immediately or be suspended right after its creation.
std::suspend_always/std::suspend_never final_suspend() noexcept: Dictates if the coroutine should be suspended after running to completion. If std::suspend_never is used, the coroutine ends immediately after execution.
void return_void() noexcept: Used for coroutines with a void return type. Indicates the end of the coroutine.
void return_value(ReturnType value): For coroutines that produce a result, this function specifies how to handle the value provided with co_return.
void unhandled_exception(): Invoked if there’s an unhandled exception inside the coroutine. Typically, you’d capture or rethrow the exception here.
Yielding Values:
std::suspend_always/std::suspend_never yield_value(YieldType value): Specifies what to do when the coroutine uses co_yield. You dictate here how the value should be handled or stored.
Awaiting Values:
auto await_transform(AwaitableType value) -> Awaiter: Transforms the expression after co_await. This is useful for custom awaitable types. For instance, it’s used to make this a valid awaitable in member functions.
4.10.1.1 Awaiter
The awaiter in the C++ coroutine framework is a mechanism that allows fine-tuned control over how asynchronous operations are managed and how results are produced once those operations are complete.
Here’s an overview of the awaiter:
Role of the Awaiter:
The awaiter is responsible for defining the behavior of a co_await expression. It determines if the coroutine should suspend, what should be done upon suspension, and what value (if any) should be produced when the coroutine resumes.
Required Methods: The awaiter must provide the following three methods:
await_ready
Purpose: Determines if the coroutine needs to suspend at all.
Signature: bool await_ready() const noexcept
Return:
true: The awaited operation is already complete, and the coroutine shouldn’t suspend.
false: The coroutine should suspend.
await_suspend
Purpose: Dictates the actions that should be taken when the coroutine suspends.
handle: A handle to the currently executing coroutine. It can be used to later resume the coroutine.
await_resume
Purpose: Produces a value once the awaited operation completes and the coroutine resumes.
Signature: ReturnType await_resume() noexcept
Return: The result of the co_await expression. The type can be void if no value needs to be produced.
Workflow of the Awaiter:
Obtain the Awaiter: When a coroutine encounters co_await someExpression, it first needs to get an awaiter. The awaiter can be:
Directly from someExpression if it has an operator co_await.
Through an ADL (Argument Dependent Lookup) free function named operator co_await that takes someExpression as a parameter.
From the coroutine’s promise_type via await_transform if neither of the above methods produce an awaiter.
Call await_ready: The coroutine calls the awaiter’s await_ready() method.
If it returns true, the coroutine continues without suspending.
If it returns false, the coroutine prepares to suspend.
Call await_suspend (if needed): If await_ready indicated the coroutine should suspend (by returning false), the await_suspend method is called with a handle to the current coroutine. This method typically arranges for the coroutine to be resumed later, often by setting up callbacks or handlers associated with the asynchronous operation.
Operation Completion and Coroutine Resumption: Once the awaited operation is complete and the coroutine is resumed, the awaiter’s await_resume method is called. The value it produces becomes the result of the co_await expression.
Built-in Awaiters:
std::suspend_always: The method await_ready always returns false, indicating that an await expression always suspends as it waits for its value
std::suspend_never: The method await_ready always returns true, indicating that an await expression never suspends
4.10.2 Example
The Chat struct acts as a wrapper around the coroutine handle. It allows the main code to interact with the coroutine - by resuming it, or by sending/receiving data to/from it.
The promise_type nested within Chat is what gives behavior to our coroutine. It defines:
What happens when you start the coroutine (initial_suspend).
What happens when you co_yield a value (yield_value).
What happens when you co_await a value (await_transform).
What happens when you co_return a value (return_value).
What happens at the end of the coroutine (final_suspend).
Functionality:
Creating the Coroutine:
When Fun() is called, a new coroutine is started. Due to initial_suspend, it is suspended immediately before executing any code.
The coroutine handle (with the promise) is wrapped inside the Chat object, which is then returned to the caller (main function in this case).
Interacting with the Coroutine:
chat.listen(): Resumes the coroutine until the next suspension point. If co_yield is used inside the coroutine, the yielded value will be returned.
chat.answer(msg): Sends a message to the coroutine. If the coroutine is waiting for input using co_await, this will provide the awaited value and resume the coroutine.
Coroutine Flow:
The coroutine starts and immediately hits co_yield "Hello!\n";. This suspends the coroutine and the string "Hello!\n" is made available to the caller.
In main, after chat.listen(), it prints this message.
Then, chat.answer("Where are you?\n"); is called. Inside the coroutine, the message "Where are you?\n" is captured and printed because of the line std::cout << co_await std::string{};.
Finally, co_return "Here!\n"; ends the coroutine, and the string "Here!\n" is made available to the caller. This message is printed after the second chat.listen() in main.
// A: Shortcut for the handle type using Handle = std::coroutine_handle<promise_type>; // B Handle _handle;
// C: Get the handle from promise explicitChat(promise_type* p) : _handle(Handle::from_promise(*p)) {}
// D: Move only Chat(Chat&& rhs) : _handle(std::exchange(rhs._handle, nullptr)) {}
// E: Care taking, destroying the handle if needed ~Chat() { if (_handle) { _handle.destroy(); } }
// F: Active the coroutine and wait for data std::string listen(){ std::cout << " -- Chat::listen" << std::endl; if (!_handle.done()) { _handle.resume(); } return std::move(_handle.promise()._msg_out); }
// G Send data to the coroutine and activate it voidanswer(std::string msg){ std::cout << " -- Chat::answer" << std::endl; _handle.promise()._msg_in = msg; if (!_handle.done()) { _handle.resume(); } } };
Function Templates: These are templates that produce templated functions that can operate on a variety of data types.
1 2 3 4
template<typename T> T max(T a, T b){ return (a > b) ? a : b; }
Class Templates: These produce templated classes. The Standard Template Library (STL) makes heavy use of this type of template for classes like std::vector, std::map, etc.
1 2 3 4
template<typename T> classStack { // ... class definition ... };
Variable Templates: Introduced in C++14, these are templates that produce templated variables.
1 2
template<typename T> constexpr T pi = T(3.1415926535897932385);
Alias Templates: These are a way to define templated typedef, providing a way to simplify complex type names.
1 2
template<typename T> using Vec = std::vector<T, std::allocator<T>>;
Member Function Templates: These are member functions within classes that are templated. The containing class itself may or may not be templated.
Template Template Parameters: This advanced feature allows a template to have another template as a parameter.
1 2 3 4
template<template<typename> classContainerType> classMyClass { // ... class definition ... };
Non-type Template Parameters: These are templates that take values (like integers, pointers, etc.) as parameters rather than types.
1 2 3 4 5
template<int size> classArray { int elems[size]; // ... class definition ... };
Nested Templates: This refers to templates defined within another template. It’s not a different kind of template per se, but rather a feature where one template can be nested inside another.
Function and Class Templates: When you define a function template or a class template in a header, you’re not defining an actual function or class. Instead, you’re defining a blueprint from which actual functions or classes can be instantiated. Actual instantiations of these templates (the generated functions or classes) may end up in multiple translation units, but they’re identical and thus don’t violate the ODR. Only when these templates are instantiated do they become tangible entities in the object file. If multiple translation units include the same function or class template and instantiate it in the same way, they all will have the same instantiation, so it doesn’t break One Definition Rule (ODR).
Variable Templates: A variable template is still a blueprint, like function and class templates. But the key difference lies in how the compiler treats template instantiations for variables versus functions/classes. For variables, the instantiation actually defines a variable. If this template is instantiated in multiple translation units, it results in multiple definitions of the same variable across those translation units, violating the ODR. Thus, for variable templates, the inline keyword is used to ensure that all instances of a variable template across multiple translation units are treated as a single entity, avoiding ODR violations.
In order for a template to be instantiated, every template parameter (type, non-type, or template) must be replaced by a corresponding template argument. For class templates, the arguments are either explicitly provided, deduced from the initializer, (since C++17) or defaulted. For function templates, the arguments are explicitly provided, deduced from the context, or defaulted.
A template parameter pack is a template parameter that accepts zero or more template arguments (non-types, types, or templates). A function parameter pack is a function parameter that accepts zero or more function arguments.
A template with at least one parameter pack is called a variadic template.
Reduces (folds) a parameter pack over a binary operator.
Syntax:
Unary right fold: ( pack op ... )
Unary left fold: ( ... op pack )
Binary right fold: ( pack op ... op init )
Binary left fold: ( init op ... op pack )
op: any of the following 32 binary operators: +-*/%^&|=<><<>>+=-=*=/=%=^=&=|=<<=>>===!=<=>=&&||,.*->*. In a binary fold, both ops must be the same.
pack: an expression that contains an unexpanded parameter pack and does not contain an operator with precedence lower than cast at the top level (formally, a cast-expression)
init: an expression that does not contain an unexpanded parameter pack and does not contain an operator with precedence lower than cast at the top level (formally, a cast-expression)
Note that the opening and closing parentheses are a required part of the fold expression.
std::cout << first << std::endl; std::cout << second << std::endl; std::cout << third << std::endl; return0; }
5.4.2 Traverse Parameter Pack
5.4.2.1 Parenthesis Initializer
Built-in comma operator: In a comma expression E1, E2, the expression E1 is evaluated, its result is discarded (although if it has class type, it won’t be destroyed until the end of the containing full expression), and its side effects are completed before evaluation of the expression E2 begins (note that a user-defined operator, cannot guarantee sequencing)
1 2 3 4 5 6 7
#include<iostream>
intmain(){ int n = 1; int m = (++n, std::cout << "n = " << n << '\n', ++n, 2 * n); // print 2, n=3, m=6 std::cout << "m = " << (++m, m) << '\n'; // print 7 }
Partial template specialization Allows customizing class and variable(since C++14) templates for a given category of template arguments.
template function don’t support partial template specialization.
The requirements of argument list:
The argument list cannot be identical to the non-specialized argument list (it must specialize something).
1 2
template<classT1, classT2, int I> classB {}; // primary template template<classX, classY, int N> classB<X, Y, N> {}; // error
Default arguments cannot appear in the argument list.
If any argument is a pack expansion, it must be the last argument in the list.
…
5.5.2.1 Members of partial specializations
The template parameter list and the template argument list of a member of a partial specialization must match the parameter list and the argument list of the partial specialization.
Just like with members of primary templates, they only need to be defined if used in the program.
Members of partial specializations are not related to the members of the primary template.
Explicit (full) specialization of a member of a partial specialization is declared the same way as an explicit specialization of the primary template.
// member of partial specialization template <classT> void A<T, 2>::g() {}
// explicit (full) specialization // of a member of partial specialization template <> void A<char, 2>::h() {}
intmain(){ A<char, 0> a0; A<char, 2> a2; a0.f(); // OK, uses primary template's member definition a2.g(); // OK, uses partial specialization's member definition a2.h(); // OK, uses fully-specialized definition of // the member of a partial specialization a2.f(); // error: no definition of f() in the partial // specialization A<T,2> (the primary template is not used) }
5.5.2.2 How to use std::enable_if in partial specialization
Wrong way:
Default arguments cannot appear in the argument list.
Template instantiation is the process by which the C++ compiler generates concrete code from a template when you use it with specific types.
5.6.1 Implicit Instantiation
Implicit instantiation happens automatically when a template is used. It is useful when you want to pre-compile template code in a .cpp file to reduce compile times or binary size.
5.6.2 Explicit Instantiation
Explicit Instantiation ask the compiler to generate a specific instantiation.
In C++ template programming, when a template parameter appears on the left side of ::, it typically cannot be deduced. This is because the left side of :: often represents a dependent type, which the compiler cannot resolve during template argument deduction.
// This one cannot be deduced template <typename T> classFoo<std::vector<T>::value_type> {};
// This one cannot be deduced template <typename T> classFoo<std::conditional_t<std::is_integral_v<T>, int, double>> {};
template <typename T, typename U> classBar {};
// T can be directly deduced from template parameter `std::vector<T>` // so the dependent type `std::vector<T>::value_type` can be also deduced template <typename T> classBar<std::vector<T>, typename std::vector<T>::value_type> {};
// T can be directly deduced from template parameter `std::vector<T>` // so the dependent type `std::conditional_t` and `std::is_integral_v` can be also deduced template <typename T> classBar<std::vector<T>, std::conditional_t<std::is_integral_v<T>, int, double>> {};
5.8 Using typename to Disambiguate
Under what circumstances would ambiguity arise? For example, foo* ptr;
If foo is a type, then this statement is a declaration, i.e., it defines a variable of type foo*.
If foo is a variable, then this statement is an expression, i.e., it performs the * operation on foo and ptr.
The compiler cannot distinguish which of the above two cases it is. Therefore, you can explicitly use typename to inform the compiler that foo is a type.
For templates, such as T::value_type, the compiler similarly cannot determine whether T::value_type is a type or not. This is because the class scope resolution operator :: can access both type members and static members. By default, the compiler assumes that something in the form of T::value_type is not a type.
Case 1:
1 2 3 4 5 6 7 8 9
// The following will fail to compile: template<typename T> T::value_type sum(const T &container){ T::value_type res = {}; for (constauto &item: container) { res += item; } return res; }
After refined:
1 2 3 4 5 6 7 8
template<typename T> typename T::value_type sum(const T &container){ typename T::value_type res = {}; for (constauto &item: container) { res += item; } return res; }
5.9 Using template to Disambiguate
Under what circumstances would ambiguity arise? For example, container.emplace<int>(1);
If container.emplace is a member variable, then < can be interpreted as a less-than symbol.
If container.emplace is a template, then < can be interpreted as the brackets for template parameters.
5.13 Separating the definition and implementation of a template
We can place the declaration and definition of a template in two separate files, which makes the code structure clearer. For example, suppose there are two files test.h and test.tpp, with the following contents:
template <typename T> void Demo<T>::func() { // do something }
As we can see, test.h references test.tpp at the end, so other modules only need to include test.h. The entire template definition can also be clearly viewed through a single file, test.h. However, there is an issue here: if we use vscode or the lsp plugin in vim to read or edit the test.tpp file, we may encounter syntax problems because test.tpp itself is incomplete and cannot be compiled.
template <typename T> void Demo<T>::func() { // do something }
#undef TEST_TPP
In this way, when editing these two files independently, lsp can work normally without causing circular reference issues.
When there is no compile_commands.json file, clangd will report an error when processing a standalone tpp file. The error message is: Unable to handle compilation, expected exactly one compiler job in ''.
5.13.1 Hide template implementation
We can even hide the specific implementation of the template, but in this case, all required types must be explicitly instantiated in the defining .cpp file. This is because the implementation of the template is not visible to other .cpp files and can only resolve the corresponding symbols during linking.
// Base class has a pure virtual function for cloning classAbstractShape { public: virtual ~AbstractShape() = default; virtual std::unique_ptr<AbstractShape> clone()const= 0; };
// This CRTP class implements clone() for Derived template <typename Derived> classShape : public AbstractShape { public: std::unique_ptr<AbstractShape> clone()constoverride{ return std::make_unique<Derived>(static_cast<Derived const&>(*this)); }
protected: // We make clear Shape class needs to be inherited Shape() = default; Shape(const Shape&) = default; Shape(Shape&&) = default; };
// Every derived class inherits from CRTP class instead of abstract class classSquare : public Shape<Square> {};
classCircle : public Shape<Circle> {};
intmain(){ Square s; auto clone = s.clone(); return0; }
5.15 PIMPL
In C++, the term pimpl is short for pointer to implementation or private implementation. It’s an idiom used to separate the public interface of a class from its implementation details. This helps improve code modularity, encapsulation, and reduces compile-time dependencies.
Here’s how the pimpl idiom works:
Public Interface: You define a class in your header file (.h or .hpp) that contains only the public interface members (public functions, typedefs, etc.). This header file should include minimal implementation details to keep the interface clean and focused.
Private Implementation: In the implementation file (.cpp), you declare a private class that holds the actual implementation details of your class. This private class is typically defined within an anonymous namespace or as a private nested class of the original class. The private class contains private data members, private functions, and any other implementation-specific details.
Pointer to Implementation: Within the main class, you include a pointer to the private implementation class. The public functions in the main class forward calls to the corresponding functions in the private implementation class.
By using the pimpl idiom, you achieve several benefits:
Reduces compile-time dependencies: Changes to the private implementation do not require recompilation of the public interface, reducing compilation times.
Enhances encapsulation: Clients of the class only need to know about the public interface, shielding them from implementation details.
Minimizes header dependencies: Since the private implementation is not exposed in the header, you avoid leaking implementation details to client code.
Eases binary compatibility: Changing the private implementation does not require recompiling or re-linking client code, as long as the public interface remains unchanged.
Cache coherence and memory consistency are two fundamental concepts in parallel computing systems, but they address different issues:
Cache Coherence:
This concept is primarily concerned with the values of copies of a single memory location that are cached at several caches (typically, in a multiprocessor system). When multiple processors with separate caches are in a system, it’s possible for those caches to hold copies of the same memory location. Cache coherence ensures that all processors in the system observe a single, consistent value for the memory location. It focuses on maintaining a global order in which writes to each individual memory location occur.
For example, suppose we have two processors P1 and P2, each with its own cache. If P1 changes the value of a memory location X that’s also stored in P2’s cache, the cache coherence protocols will ensure that P2 sees the updated value if it tries to read X.
Memory Consistency:
While cache coherence is concerned with the view of a single memory location, memory consistency is concerned about the ordering of multiply updates to different memory locations(or single memory location) from different processors. It determines when a write by one processor to a shared memory location becomes visible to all other processors.
A memory consistency model defines the architecturally visible behavior of a memory system. Different consistency models make different guarantees about the order and visibility of memory operations across different threads or processors. For example, sequential consistency, a strict type of memory consistency model, says that all memory operations must appear to execute in some sequential order that’s consistent with the program order of each individual processor.
In summary, while both are essential for correctness in multiprocessor systems, cache coherence deals with maintaining a consistent view of a single memory location, while memory consistency is concerned with the order and visibility of updates to different memory locations.
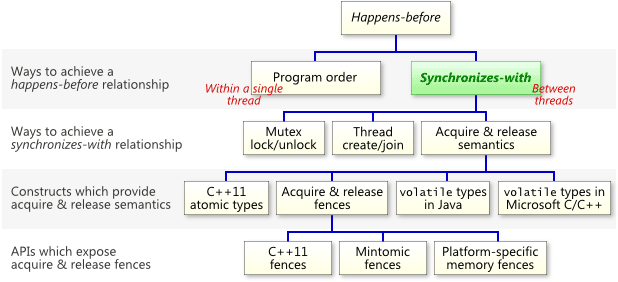
6.1.2 Happens-before
If an operation A “happens-before” another operation B, it means that A is guaranteed to be observed by B. In other words, any data or side effects produced by A will be visible to B when it executes.
6.2 Memory consistency model
6.2.1 Sequential consistency model
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program
Sequential consistency model (SC), also known as the sequential consistency model, essentially stipulates two things:
Each thread’s instructions are executed in the order specified by the program (from the perspective of a single thread)
The interleaving order of thread execution can be arbitrary, but the overall execution order of the entire program, as observed by all threads, must be the same (from the perspective of the entire program)
That is, there should not be a situation where for write operations W1 and W2, processor 1 sees the order as: W1 -> W2; while processor 2 sees the order as: W2 -> W1
6.2.2 Relaxed consistency model
Relaxed consistency model also known as the loose memory consistency model, is characterized by:
Within the same thread, access to the same atomic variable cannot be reordered (from the perspective of a single thread)
Apart from ensuring the atomicity of operations, there is no stipulation on the order of preceding and subsequent instructions, and the order in which other threads observe data changes may also be different (from the perspective of the entire program)
That is, different threads may observe the relaxed operations on a single atomic value in different orders.
Looseness can be measured along the following two dimensions:
How to relax the requirements of program order. Typically, this refers to the read and write operations of different variables; for the same variable, read and write operations cannot be reordered. Program order requirements include:
read-read
read-write
write-read
write-write
How they relax the requirements for write atomicity. Models are differentiated based on whether they allow a read operation to return the written value of another processor before all cache copies have received the invalidation or update message produced by the write; in other words, allowing a processor to read the written value before the write is visible to all other processors.
Through these two dimensions, the following relaxed strategies have been introduced:
Relaxing the write-read program order. Supported by TSO (Total Store Order)
Relaxing the write-write program order
Relaxing the read-read and read-write program order
Allowing early reads of values written by other processors
Allowing early reads of values written by the current processor
6.2.3 Total Store Order
otal Store Order (TSO) is a type of memory consistency model used in computer architecture to manage how memory operations (reads and writes) are ordered and observed by different parts of the system.
In a Total Store Order model:
Writes are not immediately visible to all processors: When a processor writes to memory, that write is not instantly visible to all other processors. There’s a delay because writes are first written to a store buffer unique to each processor.
Writes are seen in order: Even though there’s a delay in visibility, writes to the memory are seen by all processors in the same order. This is the “total order” part of TSO, which means that if Processor A sees Write X followed by Write Y, Processor B will also see Write X before Write Y.
Reads may bypass writes: If a processor reads a location that it has just written to, it may get the value from its store buffer (the most recent write) rather than the value that is currently in memory. This means a processor can see its writes immediately but may not see writes from other processors that happened after its own write.
Writes from a single processor are seen in the order issued: Writes by a single processor are observed in the order they were issued by that processor. If Processor A writes to memory location X and then to memory location Y, all processors will see the write to X happen before the write to Y.
This model is a compromise between strict ordering and performance. In a system that enforces strict ordering (like Sequential Consistency), every operation appears to happen in a strict sequence, which can be quite slow. TSO allows some operations to be reordered (like reads happening before a write is visible to all) for better performance while still maintaining a predictable order for writes, which is critical for correctness in many concurrent algorithms.
TSO is commonly used in x86 processors, which strikes a balance between the predictable behavior needed for programming ease and the relaxed rules that allow for high performance in practice.
6.3 std::memory_order
std::memory_order_seq_cst: Provide happens-before relationship.
std::memory_order_relaxed: CAN NOT Provide happens-before relationship. Which specific relaxation strategies are adopted must be determined based on the hardware platform.
When you use std::memory_order_relaxed, it guarantees the following:
Sequential consistency for atomic operations on a single variable: If you perform multiple atomic operations on the same atomic variable using std::memory_order_relaxed, the result will be as if those operations were executed in some sequential order. This means that the final value observed by any thread will be a valid result based on the ordering of the operations.
Coherence: All threads will eventually observe the most recent value written to an atomic variable. However, the timing of when each thread observes the value may differ due to the relaxed ordering.
Atomicity: Atomic operations performed with std::memory_order_relaxed are indivisible. They are guaranteed to be performed without interruption or interference from other threads.
std::memory_order_acquire and std::memory_order_release: Provide happens-before relationship.
When used together, std::memory_order_acquire and std::memory_order_release can establish a happens-before relationship between threads, allowing for proper synchronization and communication between them
std::memory_order_acquire is a memory ordering constraint that provides acquire semantics. It ensures that any memory operations that occur before the acquire operation in the program order will be visible to the thread performing the acquire operation.
std::memory_order_release is a memory ordering constraint that provides release semantics. It ensures that any memory operations that occur after the release operation in the program order will be visible to other threads that perform subsequent acquire operations.
template <std::memory_order read_order, std::memory_order write_order> voidtest_atomic_happens_before(){ auto reader_thread = []() { for (auto i = 0; i < TIMES; i++) { // atomic read while (!atomic_data_ready.load(read_order)) ;
// normal read: atomic read happens-before normal read assert(data == EXPECTED_VALUE);
data = INVALID_VALUE; atomic_data_ready.store(false, write_order); } }; auto writer_thread = []() { for (auto i = 0; i < TIMES; i++) { while (atomic_data_ready.load(read_order)) ;
template <std::memory_order read_order, std::memory_order write_order> booltest_reorder(){ // control vars std::atomic<bool> control(false); std::atomic<bool> stop(false); std::atomic<bool> success(true); std::atomic<int32_t> finished_num = 0;
auto round_process = [&control, &stop, &finished_num](auto&& process) { while (!stop) { // make t1 and t2 go through synchronously finished_num++; while (!stop && !control) ;
process();
// wait for next round finished_num++; while (!stop && control) ; } };
auto control_process = [&control, &success, &finished_num](auto&& clean_process, auto&& check_process) { for (size_t i = 0; i < TIMES; i++) { // wait t1 and t2 at the top of the loop while (finished_num != 2) ;
// clean up data finished_num = 0; clean_process();
// let t1 and t2 go start control = true;
// wait t1 and t2 finishing write operation while (finished_num != 2) ;
// check assumption if (!check_process()) { success = false; }
finished_num = 0; control = false; } };
// main vars std::atomic<int32_t> flag1, flag2; std::atomic<int32_t> critical_num;
test std::memory_order_seq_cst, std::memory_order_seq_cst, res=true test std::memory_order_acquire, std::memory_order_release, res=false test std::memory_order_relaxed, std::memory_order_relaxed, res=false
template <std::memory_order read_order, std::memory_order write_order> booltest_reorder(){ // control vars std::atomic<bool> control(false); std::atomic<bool> stop(false); std::atomic<bool> success(true); std::atomic<int32_t> finished_num = 0;
auto round_process = [&control, &stop, &finished_num](auto&& process) { while (!stop) { // make t1 and t2 go through synchronously finished_num++; while (!stop && !control) ;
process();
// wait for next round finished_num++; while (!stop && control) ; } };
auto control_process = [&control, &success, &finished_num](auto&& clean_process, auto&& check_process) { for (size_t i = 0; i < TIMES; i++) { // wait t1 and t2 at the top of the loop while (finished_num != 2) ;
// clean up data finished_num = 0; clean_process();
// let t1 and t2 go start control = true;
// wait t1 and t2 finishing write operation while (finished_num != 2) ;
// check assumption if (!check_process()) { success = false; }
finished_num = 0; control = false; } };
// main vars std::atomic<int32_t> data; std::atomic<int32_t> head; std::atomic<int32_t> read_val;
auto process_1 = [&data, &head]() { data.store(2000, write_order); head.store(1, write_order); }; auto process_2 = [&data, &head, &read_val]() { while (head.load(read_order) == 0) ; read_val = data.load(read_order); }; auto clean_process = [&data, &head, &read_val]() { data = 0; head = 0; read_val = 0; }; auto check_process = [&read_val]() { return read_val == 2000; };
test std::memory_order_seq_cst, std::memory_order_seq_cst, res=true test std::memory_order_acquire, std::memory_order_release, res=true test std::memory_order_relaxed, std::memory_order_relaxed, res=true
template <std::memory_order read_order, std::memory_order write_order> booltest_reorder(){ // control vars std::atomic<bool> control(false); std::atomic<bool> stop(false); std::atomic<bool> success(true); std::atomic<int32_t> finished_num = 0;
auto round_process = [&control, &stop, &finished_num](auto&& process) { while (!stop) { // make t1 and t2 go through synchronously finished_num++; while (!stop && !control) ;
process();
// wait for next round finished_num++; while (!stop && control) ; } };
auto control_process = [&control, &success, &finished_num](auto&& clean_process, auto&& check_process) { for (size_t i = 0; i < TIMES; i++) { // wait t1, t2 and t3 at the top of the loop while (finished_num != 3) ;
// clean up data finished_num = 0; clean_process();
// let t1, t2 and t3 go start control = true;
// wait t1, t2 and t3 finishing write operation while (finished_num != 3) ;
// check assumption if (!check_process()) { success = false; }
finished_num = 0; control = false; } };
// main vars std::atomic<int32_t> a; std::atomic<int32_t> b; std::atomic<int32_t> reg;
auto process_1 = [&a]() { a.store(1, write_order); }; auto process_2 = [&a, &b]() { if (a.load(read_order) == 1) { b.store(1, write_order); } }; auto process_3 = [&a, &b, ®]() { if (b.load(read_order) == 1) { reg.store(a.load(read_order), write_order); } }; auto clean_process = [&a, &b, ®]() { a = 0; b = 0; reg = -1; }; auto check_process = [®]() { return reg != 0; };
test std::memory_order_seq_cst, std::memory_order_seq_cst, res=true test std::memory_order_acquire, std::memory_order_release, res=true test std::memory_order_relaxed, std::memory_order_relaxed, res=true
If a function receives an object of type T(not reference type), you pass lvalue, then copy constructor is called to create the object; you pass rvalue, then move constructor is called to create the object
intmain(){ std::vector<Foo> v; // Avoid scale up v.reserve(3);
std::cout << "\npush_back without std::move" << std::endl; // This move operation is possible because the object returned by getFoo() is an rvalue, which is eligible for move semantics. v.push_back(getFoo());
std::cout << "\npush_back with std::move (1)" << std::endl; v.push_back(std::move(getFoo()));
push_back without std::move Foo::Foo() Foo::Foo(Foo&&)
push_back with std::move (1) Foo::Foo() Foo::Foo(Foo&&)
push_back with std::move (2) Foo::Foo() Foo::Foo(Foo&&)
assign without std::move Foo::Foo() Foo::Foo() Foo::operator=(Foo&&)
assign with std::move Foo::Foo() Foo::operator=(Foo&&)
pass without std::move Bar::Bar(const Bar&) receiveBar(Bar)
pass with std::move Bar::Bar(Bar&&) receiveBar(Bar)
7.3 Structured Bindings
Structured bindings were introduced in C++17 and provide a convenient way to destructure the elements of a tuple-like object or aggregate into individual variables.
Tuple-like objects in C++ include:
std::tuple: The standard tuple class provided by the C++ Standard Library.
std::pair: A specialized tuple with exactly two elements, also provided by the C++ Standard Library.
Custom user-defined types that mimic the behavior of tuples, such as structs with a fixed number of members.
Copy elision is an optimization technique used by compilers in C++ to reduce the overhead of copying and moving objects. This optimization can significantly improve performance by eliminating unnecessary copying of objects, especially in return statements or during function calls. Two specific cases of copy elision are Return Value Optimization (RVO) and Named Return Value Optimization (NRVO). Let’s explore each of these:
Return Value Optimization (RVO): RVO is a compiler optimization that eliminates the need for a temporary object when a function returns an object by value. Normally, when a function returns an object, a temporary copy of the object is created (which invokes the copy constructor), and then the temporary object is copied to the destination variable. With RVO, the compiler can directly construct the return value in the memory location of the caller’s receiving variable, thereby skipping the creation and copy of the temporary object.
Named Return Value Optimization (NRVO): Similar to RVO, NRVO allows the compiler to eliminate the temporary object even when the object returned has a name. NRVO is a bit more challenging for the compiler because it involves predicting which named variable will be returned at compile time.
Moving a local object in a return statement prevents copy elision.
Widget createWidgetNonRVO(){ auto w = Widget(); return std::move(w); }
intmain(){ { std::cout << "Testing RVO:" << std::endl; Widget w = createWidgetRVO(); // With RVO, the copy constructor is not called } { std::cout << "Testing NRVO:" << std::endl; Widget w2 = createWidgetNRVO(); // With NRVO, the copy constructor is not called } { std::cout << "Testing non-RVO:" << std::endl; Widget w3 = createWidgetNonRVO(); // Without RVO, the copy constructor is called } return0; }
RAII, Resource Acquisition is initialization,即资源获取即初始化。典型示例包括:std::lock_guard、defer。简单来说,就是在对象的构造方法中初始化资源,在析构函数中销毁资源。而构造函数与析构函数的调用是由编译器自动插入的,减轻了开发者的心智负担
RAII (Resource Acquisition Is Initialization): The DeferOp class is an RAII wrapper that executes a provided function (or lambda) when its destructor is called. This is typically used for cleanup or deferred execution.
Destructor Behavior: In C++, destructors are implicitly called when an object goes out of scope. If an exception is thrown elsewhere in the scope, the stack unwinds, and destructors of automatic objects are invoked.
Exception Handling: A try-catch block catches exceptions thrown within its scope, but how exceptions interact with destructors is critical here.
This exception is thrown directly in the try block in main, so it’s caught by the corresponding catch (...) block, printing "normal_func exception caught".
raii_func
Creates a DeferOp object with a lambda: []() { std::cout << "hello world" << std::endl; throw std::runtime_error("raii_func"); }.
The lambda isn’t executed immediately—it’s stored in the DeferOp object’s _func member.
When raii_func returns, the DeferOp object goes out of scope, and its destructor ~DeferOp() is called.
The destructor invokes _func(), which executes the lambda, printing "hello world" and throwing the std::runtime_error.
Why the Exception Isn’t Caught: The key issue lies in when and where the exception is thrown in raii_func:
The try block in main surrounds the call to raii_func().
However, no exception is thrown during the execution of raii_func() itself—raii_func simply constructs the DeferOp object and returns.
The exception is thrown later, in the destructor of DeferOp, after the try block has already completed and the stack is unwinding (or after the function has exited normally).
At this point, the try-catch block in main is no longer active because the scope of the try block has ended. Exceptions thrown during stack unwinding or outside the try block aren’t caught by that block.
In C++, if an exception is thrown while the stack is already unwinding due to another exception—or outside of an active try block—it results in undefined behavior or program termination unless caught by a higher-level try-catch. In this case, there’s no prior exception causing unwinding, but the exception still occurs outside the try block’s scope.
And there’s a solution: add noexcept(false) to destructor of DeferOp, the exception can be catched as expected.
Variable-length array (VLA), which is a feature not supported by standard C++. However, some compilers, particularly in C and as extensions in C++, do provide support for VLAs.
____ The allocated block ____ / \ +--------+--------------------+ | Header | Your data area ... | +--------+--------------------+ ^ | +-- The address you are given
12.2 Do parameter types require lvalue or rvalue references
12.3 Does the return type require lvalue or rvalue references