阅读更多
1 kubectl get nodes提示tls handshake timeout
抓包结果如下
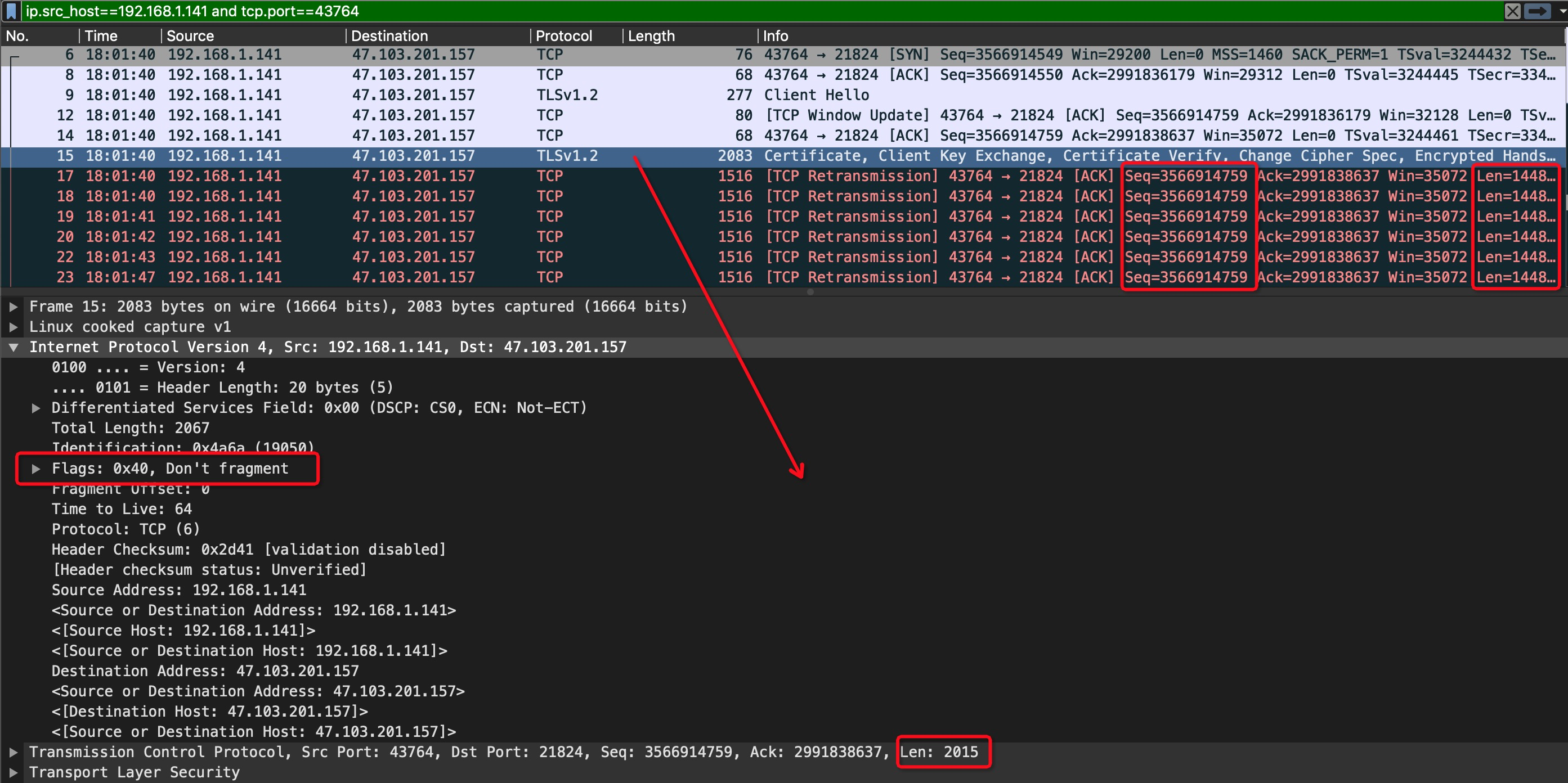
我们可以发现如下信息
- tcp三次握手阶段的交互都是正常的,说明网络是通畅的
seq=3566914759的这个数据包第一次发送的时候,len=2015,且IP数据报头部的DF标志位置位,即不可分片。紧随其后的是多次重传,重传包的大小是1448
那么这个数据包发送失败的原因可能就是当前主机的mtu要远高于链路的最小mtu。调小mtu后,再次执行kubectl get nodes,能够正常返回结果
如何检查链路的mtu
1 | # 发送大小是1460 + (28)字节,禁止路由器拆分数据包 |
如何修改mtu(临时生效,重启后会复原),若要永久生效,那么可以通过nmtui或者nmcli配置相应的网卡连接信息
1 | IF_NAME="eno1" |
2 某个cpu的软中断si占用比例特别高
场景复现:用wget下载一个大文件,使用top命令查看每个cpu的使用详情,可以发现cpu1的软中断(si)数值特别高,而其他cpu的该数值基本为0,如下图
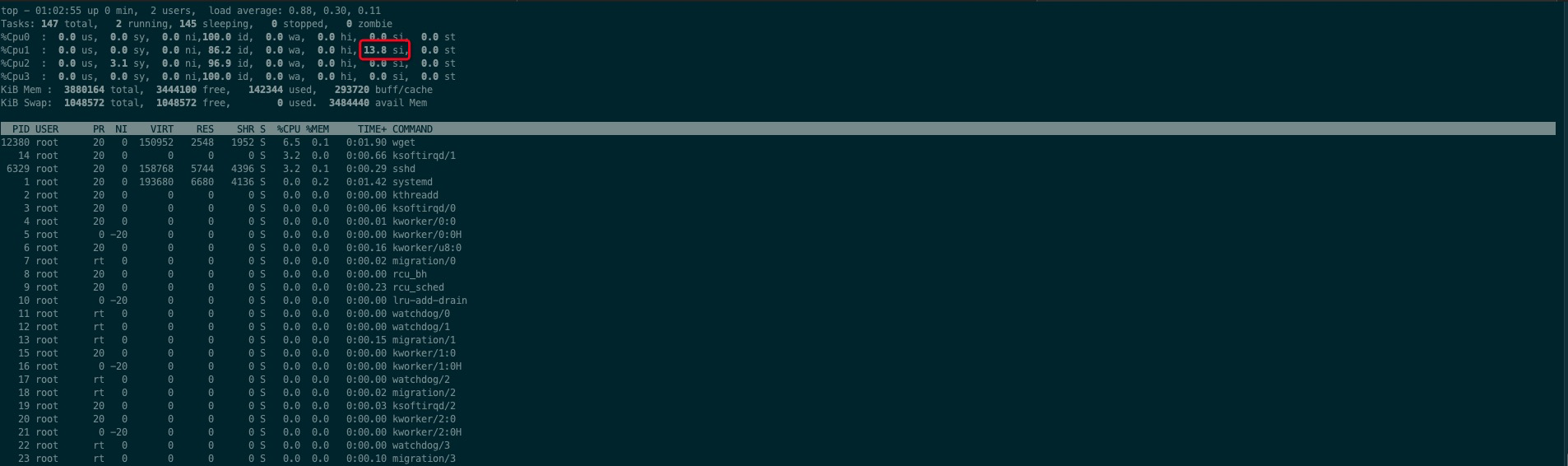
机器的外网网卡为enp0s3,可以通过/proc/interrupts找到该网卡设备对应的软中断号
1 | cat /proc/interrupts | grep 'enp0s3' |
可以看到,该网卡只有一个队列,且该队列的软中断号为19,可以通过/proc/irq/19/smp_affinity或/proc/irq/19/smp_affinity_list文件获取该中断号对应的cpu亲和性配置
对于/proc/irq/{中断号}/smp_affinity文件而言,其内容是cpu亲和性掩码
- 假设CPU的序号从0开始,
cpu0 = 1,cpu1 = cpu0 * 2,cpu2 = cpu1 * 2,… - 把该中断号亲和的cpu的数值全部相加,其结果以16进制表示,就是亲和性掩码
1 | Binary Hex |
对于/proc/irq/{中断号}/smp_affinity_list文件而言,会直接列出该中断号亲和的所有cpu序号
查看中断号19的亲和性配置
1 | cat /proc/irq/19/smp_affinity |
可以发现,该中断只亲和cpu1,这与我们的观测结果是一致的
接下来,尝试修改亲和性,想要达到的结果是:所有cpu都能够处理中断号为19的中断
1 | # 1 + 2 + 4 + 8 = 15 = f |
再次用top命令观察,发现cpu0的si数值特别高,而其他的cpu基本为0。这并不符合我们的预期。可能原因:对于网卡设备的某个队列而言,即便配置了多个亲和cpu,但是只有序号最小的cpu会生效

验证刚才这个猜想,将亲和性配置为cpu2和cpu3,预期结果为:只有cpu2的si值特别高,而其他cpu基本为0
1 | # 4 + 8 = 12 = c |
用top命令观察,发现cpu2的si数值特别高,而其他的cpu基本为0,符合我们的猜想
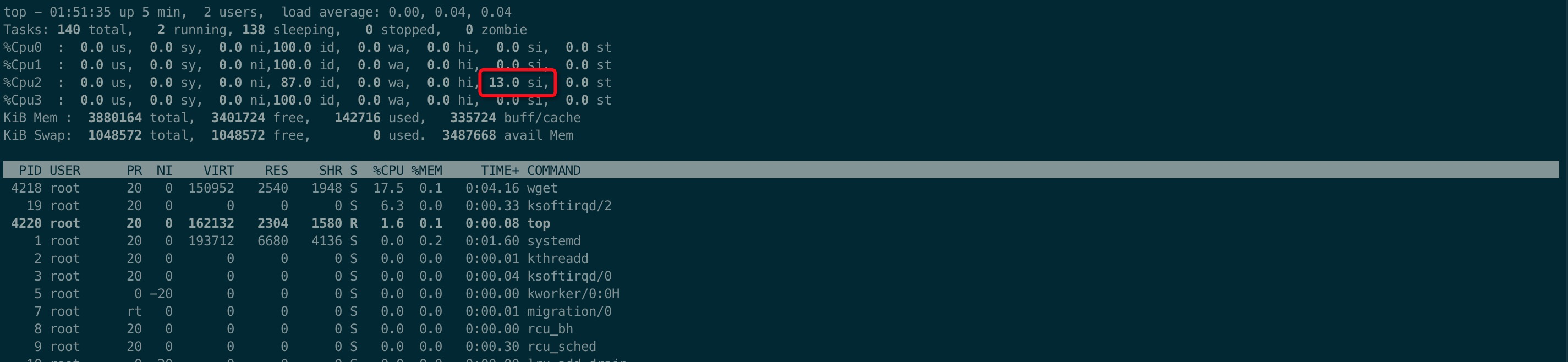
结论:
- 对于单队列的网卡而言,设置亲和多个cpu是无效的,只有编号最小的cpu会处理中断请求
- 对于多队列的网卡而言,可以单独配置每个队列亲和的cpu,以达到更高的性能
问题:irq, Interrupt Request是指硬件中断,为什么会导致si偏高,不应该是hi么
- 软中断会吃掉你多少CPU?
- 网卡软中断过高问题优化总结
- 硬中断与软中断之区别与联系?
- 硬中断是有外设硬件发出的,需要有中断控制器之参与。其过程是外设侦测到变化,告知中断控制器,中断控制器通过
CPU或内存的中断脚通知CPU,然后硬件进行程序计数器及堆栈寄存器之现场保存工作(引发上下文切换),并根据中断向量调用硬中断处理程序进行中断处理 - 软中断则通常是由硬中断处理程序或者进程调度程序等软件程序发出的中断信号,无需中断控制器之参与,直接以一个
CPU指令之形式指示CPU进行程序计数器及堆栈寄存器之现场保存工作(亦会引发上下文切换),并调用相应的软中断处理程序进行中断处理(即我们通常所言之系统调用) - 硬中断直接以硬件的方式引发,处理速度快。软中断以软件指令之方式适合于对响应速度要求不是特别严格的场景
- 硬中断通过设置
CPU的屏蔽位可进行屏蔽,软中断则由于是指令之方式给出,不能屏蔽 - 硬中断发生后,通常会在硬中断处理程序中调用一个软中断来进行后续工作的处理
- 硬中断和软中断均会引起上下文切换(进程/线程之切换),进程切换的过程是差不多的
- 硬中断是有外设硬件发出的,需要有中断控制器之参与。其过程是外设侦测到变化,告知中断控制器,中断控制器通过
2.1 参考
3 du/df看到的大小不同
区别
- du是递归统计某个目录下所有子文件和子目录的大小,可以横跨多个文件系统
- df只是读取目录所在文件系统的
super block,无法横跨多个文件系统
因此,这两个命令输出的结果不相同是在情理之中的,可能情况包括
- 目录并非挂载点,例如
/root目录一般来说就是/目录下的一个普通目录,如果执行df -h /root,结果等效于df -h / - 子目录作为另一个文件系统的挂载点,
df不会统计这个子文件系统,但是du会统计 - A进程在读某个文件F,B进程将文件F强制删除。此时
du会发现空间减小,但是df仍然是删除之前的大小,因为此时inode尚未释放
4 no space left on device(mount namespace)
最近项目上碰到一个非常奇怪的问题:执行docker cp拷贝容器内的文件或者执行docker run运行一个新的容器,都会报no space left on device这个错误
但是通过df -h以及df -ih查看,磁盘空间以及inode,剩余资源都非常充足
查阅大量资料后,在[WIP] Fix mount loop on “docker cp” #38993中找到了问题的根本原因:问题容器将主机的根目录挂载到了容器内,造成了挂载视图的扩散,每次执行docker cp都会将容器视图下的mount数量翻倍(内核默认的mount数量是10万,可以通过fs.mount-max参数进行设置)
复现方式如下
1 | # 启动容器,将宿主机的根目录挂载到容器内 |
如何解决:mount namespace支持多种不同的传播级别,可以通过命令(mount / --make-private)将根目录的传播级别设置为private,这样就可以避免两个命名空间的挂载视图相互污染
4.1 参考
- [WIP] Fix mount loop on “docker cp” #38993
- Linux Namespace系列(04):mount namespaces (CLONE_NEWNS)
- 黄东升: mount namespace和共享子树
5 文件系统inode被docker占满
项目中使用的docker版本是19.x,storage driver用的是overlay2,/var/lib/docker/overlay2目录下有几万条数据(大部分目录对应的容器早已退出),可以通过下面这个脚本清理
1 |
|
5.1 参考
6 系统内存彪高
机器的规格为4c8g
首先通过free -h查看系统内存使用情况,发现available的大小为730M,内存基本被占满
然后,通过ps aux | awk '{mem+=$6}END{print mem/1024/1024 G}'查看所有用户态进程的内存占用情况,发现总和只有4.16G
由于我们的应用是个接入层的应用,系统上会存在大量的连接,可以通过如下手段继续分析
cat /proc/net/sockstat或者ss -s查看socket的使用情况dmesg看下是否有socket out of memory- 查看tcp的一些配置信息,包括
/proc/sys/net/ipv4/tcp_rmem/proc/sys/net/ipv4/tcp_wmem/proc/sys/net/ipv4/tcp_mem
cat /proc/sys/fs/file-nr查看系统总共使用了多少文件描述符- 第一列:已分配文件句柄的数目(包括socket)
- 第二列:已分配未使用文件句柄的数目
- 第三列:文件句柄的最大数目(也可以通过
cat /proc/sys/fs/file-max查看)
slabtop查看内核占用的内存大小
6.1 参考
7 conntrack insert failed
在k8s集群中的两个服务通过k8s-service频繁相互调用,有概率会出现阻塞的情况
由于通过k8s-service进行服务的访问,那么势必会存在DNAT/SNAT规则,因为需要将service-name对应的clusterIp通过DNAT规则转换成指定的podIp。问题由此产生,生产环境中使用的k8s版本较低,还为支持NF_NAT_RANGE_PROTO_RANDOM_FULLY参数,当存在大量NAT转换的场景下,可能会出现冲突,一旦出现冲突,那么表象就是insert failed,如下图:
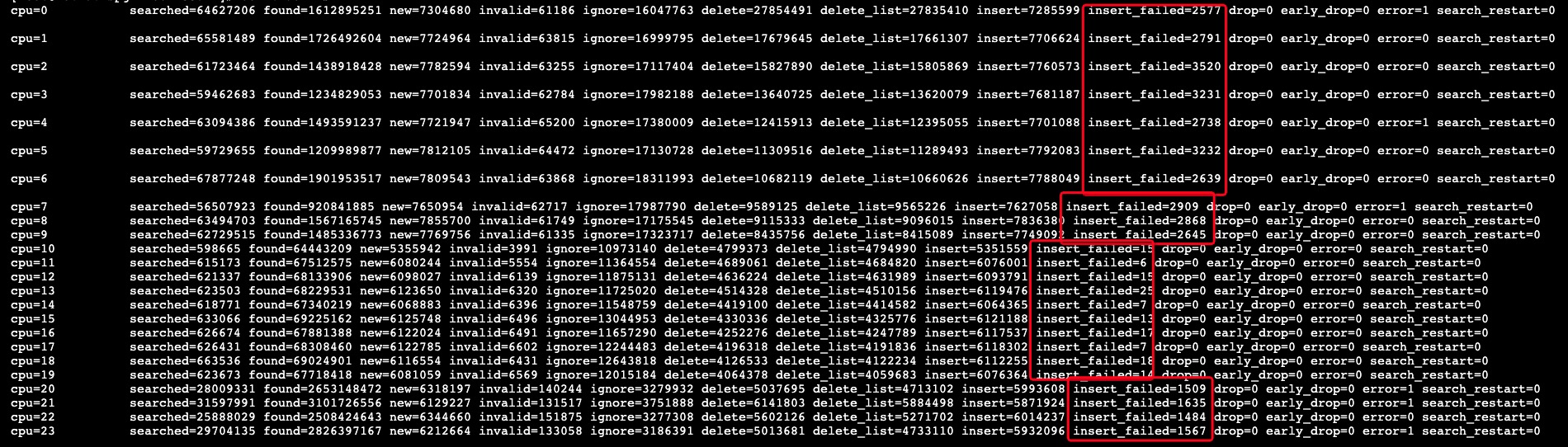
解决方式:将k8s升级到支持NF_NAT_RANGE_PROTO_RANDOM_FULLY参数的版本