阅读更多
1 General Concepts
1.1 Terminology Concepts
1.1.1 Concurrency vs. Parallelism
并发与并行是一个老生常谈的概念。简而言之,它们的含义相似,但存在细微差别:并发强调的是存在多个任务,但是这些任务并不一定真的同时执行(单核CPU也可有并发);并行强调同时执行(单核CPU不可能有并行)
1.1.2 Asynchronous vs. Synchronous
对于同步调用,调用方无法做其他事情,直到方法返回或者抛出异常。异步调用可以做其他事情,但是需要借助其他机制来拿到调用的结果,例如Callback、Future、Message
同步与异步是从调用方的角度来看待方法调用
1.1.3 Non-blocking vs. Blocking
阻塞指的是一个线程会让其他线程无期限地等待(例如,多个线程共享一个互斥锁,但是某个线程进入了一个死循环中);而非阻塞指的是一个线程不会让其他线程无期限地等待下去
1.1.4 Deadlock vs. Starvation vs. Live-lock
当多个线程产生循环依赖时,就可能产生死锁。例如,线程A、B、C分别持有独占资源α、β、γ,但A还需要β,B还需要γ,C还需要α,这样就会产生死锁
当高优先级的任务足够多的时候,如果系统总是优先调度高优先级任务,那么低优先级的任务就会发生饥饿
活锁与死锁很像,区别在于活锁处于一个连续变化的状态,而死锁处于一个静止的状态。例如,线程A、B分别持有独占资源α、β,且A尝试获取β,B尝试获取α,线程A、B若检测到有其他线程正在请求他们所占有的资源时,就会释放该资源
1.1.5 Non-blocking Guarantees
1.1.5.1 Wait-freedom
所有方法都在有限步骤内完成,不会发生死锁、饥饿等现象
1.1.5.2 Lock-freedom
几乎所有的方法在有限步骤内完成,不会发生死锁,但是可能发生饥饿现象
1.1.5.3 Obstruction-freedom
方法在有限时间内完成,意味着在执行过程中,其他线程会阻塞
Optimistic concurrency control (OCC)通常是obstruction-free。在这种方式下,线程会尝试修改一个共享资源的状态,并且能够感知到状态修改是否有冲突(例如,CAS),当发生冲突时,会重试
1.2 Actor System
Actors就是一些封装了状态和行为的对象,它们仅通过交换消息来通信。Actor严格遵循了OOP(object-oriented programming)原则
1.2.1 Hierarchical Structure
Actors自然地形成层次结构。一个Actor通常会将一个任务分解成多个简单的任务,并监管这些任务的执行。
每个Actor都有一个监督者Supervisor,即创建它的那个Actor。例如Actor A创建了Actor B,那么A就是B的Supervisor
Actor System的典型特征就是,一个大任务通常会被分解成多个(可能包含多个层级)更易执行的子任务。为了达到这样的目的,任务本身需要清晰地定义,同时,返回的结果也必须清晰地定义。也就是说,一个Actor可以处理哪些响应,不可以处理哪些响应都是需要严格设计过的,当一个Actor收到了一个它无法处理的消息时,它应该将其返回给它的Supervisor,这样可以保证异常情况可以在一个合适的位置得到处理
设计一个满足上述要求的系统的难点在于:谁来监管什么。通常,这没有一个万能的解决方案,但是下面给出一些建议
- If one actor manages the work another actor is doing, e.g. by passing on sub-tasks, then the manager should supervise the child. The reason is that the manager knows which kind of failures are expected and how to handle them.
- If one actor carries very important data (i.e. its state shall not be lost if avoidable), this actor should source out any possibly dangerous sub-tasks to children it supervises and handle failures of these children as appropriate. Depending on the nature of the requests, it may be best to create a new child for each request, which simplifies state management for collecting the replies. This is known as the “Error Kernel Pattern” from Erlang.
- If one actor depends on another actor for carrying out its duty, it should watch that other actor’s liveness and act upon receiving a termination notice. This is different from supervision, as the watching party has no influence on the supervisor strategy, and it should be noted that a functional dependency alone is not a criterion for deciding where to place a certain child actor in the hierarchy.
1.2.2 Actor Best Practices
Actors应该像一群友好的同事:高效地工作,避免打扰其他人,且不占用资源。对应到编程领域,这意味着以事件驱动的方式处理事件,并生成响应。Actor不应该阻塞在一些外部的实体上,例如锁、socket等- 不要在
Actor之间传递可变对象(mutable objects),而应该传递不可变的消息。如果将可变状态暴露到外部,那么Actor的封装将会被破坏,这样就回到了传统的Java并发编程中 Actor被设计成状态和行为的容器,不要通过消息来传递行为(例如,一个封装了行为的闭包对象)。其风险就是在Actor之间传递可变状态,这种方式破坏了Actor编程模型- 上游
Actor是错误内核最核心的部分,要谨慎地对待它们
1.3 What is an Actor
Actor是一个包含了Stage、Behavior、a Mailbox、Child Actors、a Supervisor Strategy的容器,这些被封装在Actor Reference中
值得一提的是,Actor有一个明确的生命周期:Actor不会自动销毁,即便你不再使用它。当创建了一个Actor后,销毁它便是我们的职责,这样有助于更好地控制资源的释放
1.3.1 Actor Reference
为了从Actor模型中获益,我们需要将Actor object与外部屏蔽。Actor Reference是我们使用Actor的唯一方式
这种分为内部对象和外部对象的方法可以实现所有所需操作的透明性:我们可以简单地重启Actor,而不用关心引用的更新;将Actor对象放在远程主机上;在完全不同的应用程序中向Actor发送消息。在任何时候,我们都不要将Actor内部的状态暴露出来,或者依赖这些状态
1.3.2 Stage
Actor会包含一些变量用以表示它当前的状态。这些数据正是Actor的核心价值所在,它们必须被严格保护起来,防止被外部污染。每个Actor都有它自己的轻量线程,这完全与系统的其他部分隔离开。这意味着,对于同一个Actor来说,其处理逻辑是无序考虑并发问题的(与Netty Handler类似)
Akka会在一组真实线程上运行一系列的Actor,通常情况下多个Actor共享一个线程,且一个Actor在其生命周期中,可能运行在不同的真实线程上,但这并不影响Actor的单线程特性
由于这些状态对于Actor来说至关重要,因此,状态不一致是致命的。当一个Actor出现异常被Supervisor重启,那么这个新的Actor与原来的Actor无任何关系。但是可以通过持久化消息,并重新执行来恢复先前的状态
1.3.3 Behavior
每次处理消息时,它都与当前Actor的行为匹配。行为指的是在某个时间点对某个消息的处理动作(通常表现形式是一个函数)
1.3.4 Mailbox
Acotr的目的就是处理消息。这些消息或是从一个Actor发往另一个Actor,或者来自外部系统。连接Sender与Receiver的就是Mailbox。每个Actor有且仅有一个Mailbox,接受来自所有Actor发送的消息。对于不同的Sender来说,消息enqueue的顺序是未知的。但是对于同一个Sender来说,消息enqueue的顺序与发送的顺序严格一致
Mailbox有多种不同的实现,默认的是FIFO模式:消息被处理的顺序与消息入队的顺序严格一致。其次,还有Priority模式,即消息处理的顺序可能与入队的顺序不一致,每次总是处理优先级最高的消息
1.3.5 Child Actors
每个Actor都可以是一个Supervisor,如果一个Actor创建了Subordinate Actor用于处理子任务,那么它将会自动监管这些Subordinate Actor。Subordinate Actor List保存在Actor的上下文中,我们可以通过context.actorOf(...)或 (context.stop(child))来改变Subordinate Actor List,这些操作会立即生效。值得一提的是,这些操作是异步执行的,并不会阻塞当前Actor
1.3.6 Supervisor Strategy
Akka会透明地处理错误,由于Strategy是如何构建Actor System的基础,因此一旦创建了Actor,就不能更改它
考虑到每个Actor有且仅有一个Strategy,如果一个Actor的Subordinate Actor包含了不同的Strategy,那么这些Subordinate Actor将会根据Strategy进行分组
1.3.7 When an Actor Terminates
当Actor出现异常,且不被重启,那么它将自我终结,或者被Supervisor终结。Actor终结后,它会释放资源,将Mailbox中所有未处理的message全部流转到系统的Dead Letter Mailbox,该邮箱将它们作为死信转发到事件流。然后将Actor中的Mailbox替换成System Mailbox,将所有新消息作为死信重定向到事件流。但是,这是在尽最大努力的基础上完成的,因此不要依赖它来构建guaranteed delivery
1.4 Supervision and Monitoring
1.4.1 What Supervision Means
Supervision描述了Actor System中各个Actor的依赖关系:主管Supervisor将任务委托给下属,因此必须处理由下属回报的错误信息。当一个Actor发现一个错误时,它会终止它以及它的所有Subordinate Actor,并将错误信息通过message发送给Supervisor Actor。作为一个Supervisor Actor,当其接收到来自Subordinate Actor的错误信息时,通常有如下几种处理方式
- 恢复
Subordinate Actor,并保持其累积的内部状态 - 重启
Subordinate Actor,重置其内部状态 - 永久地终结该
Subordinate Actor - 升级错误,继续向上层
Supervisor Actor汇报,因此自身也会进入异常状态
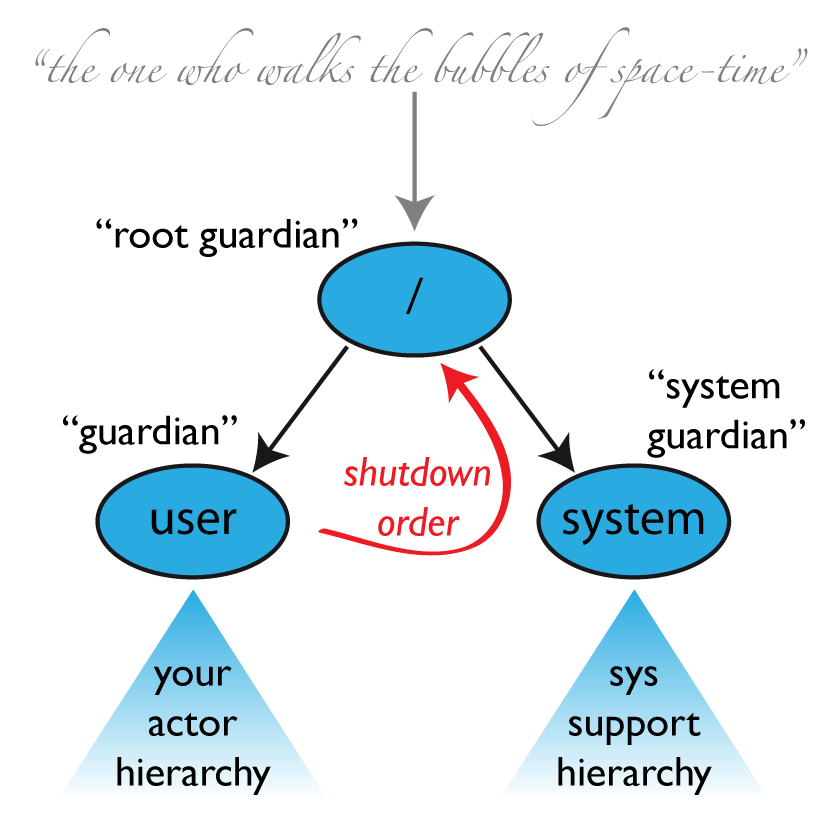
如上图所示,一个Actor Ssystem至少包含三个Actor
The Root Guardian:整个Actor System中只有它没有Subordinate Actor,且它处理错误的策略就是终结The Guardian Actor:它是我们创建的所有Normal Actor的父亲。用system.actorOf()方法创建的Actor就是User Actor的Subordinate Actor。当它进行错误升级,即向Root Actor汇报错误时,默认的行为就是终止该User Actor,于是所有Normal Actor都被终结了,因此整个Actor System都被终结了The System Guardian:这个特殊的Actor用于实现有序的关闭顺序,要知道Logging模块也是一个Actor,因此必须保证Logging Actor在所有其他Normal Actor终结之前,还处于激活状态
1.4.2 What Restarting Means
Actor进入异常状态的原因,大致上可以分成以下三类
- 系统错误,此时会收到一些特殊的Message
- 在处理消息时由外部资源的异常引起
Actor错误的内部状态引起
除非错误能够被精确地识别,那就不能排除第三种原因的可能性。如果能够断定某个Subordinate Actor产生的异常与自身或者其他Subordinate Actor无关时,最佳做法便是重启这个异常的Subordinate Actor。重启意味着创建一个新的Subordinate Actor,并且更新Subordinate Actor List,这也是封装的原因之一,使用者无须关心重启的细节。新创建的Actor会继续处理Mailbox中的消息,但是不会重复处理引发异常的那个消息。总之,对于外部而言,Actor重启是不可见的,无须感知的
重启的步骤
- 暂停当前
Actor、递归暂停所有的Subordinate Actor,暂停意味着停止处理消息 - 触发旧实例的
preRestart钩子方法,该方法默认会发送terminatation request给所有的Subordinate Actor(可以被覆盖,也就是说具体会给哪些Subordinate Actor发送terminatation request是可以定制的),并触发postStop钩子方法 - 在
preRestart钩子方法中等待所有要求被终结的Subordinate Actor终结完毕(正如第二条所说,具体会给哪些Subordinate Actor发送terminatation request是可以定制的,因此这里用的是要求被终结的Subordinate Actor) - 创建新的
Actor实例,即触发工厂方法创建实例 - 触发新实例的
postRestart钩子方法 - 对第三步中的所有
未终结的Subordinate Actor发送重启信号,重启的步骤重复步骤2-5 - 恢复当前
Actor
1.4.3 What Lifecycle Monitoring Means
与Subordinate Actor和Supervisor Actor的特殊关系不同,一个Actor可以Monitor任意其他Actor的生命周期。由于Actor的封装,重启等操作对于外部是不可见的,因此唯一可监控的状态变化就是从激活到终结。Monitor被用来将两个Actor绑定在一起,以便一个Actor可以感知另一个Actor的终结
Lifecycle Monitoring是通过发送终结消息(Terminated message)来实现的,该消息默认的处理行为就是抛出DeathPactException异常。ActorContext.watch(targetActorRef)方法开始监控,ActorContext.unwatch(targetActorRef)方法结束监控
值得一提的是,Lifecycle Monitoring中一个重要的属性就是:即便某个Actor A早已终结,后来Actor B监控了Actor A,Actor B仍然会收到Terminated message
1.4.4 BackoffSupervisor pattern
当Actor发生异常,且需要重启时,有时候我们需要延迟一段时间。例如Actor发生异常的原因是数据库宕机或者负载过高,我们需要等待一段时间,再重启该Actor,此时我们就可以使用内建的延迟重启策略
此外,加上一个随机因子,以避免Actor都在同一时刻重启
1 | final Props childProps = Props.create(EchoActor.class); |
1 | final Props childProps = Props.create(EchoActor.class); |
上述两个例子的差异
Backoff.onStop:Actor正常终结的情况Backoff.onFailure:Actor崩溃的异常情况
1.4.5 One-For-One Strategy vs. All-For-One Strategy
在Akka中存在两种Supervision Strategy
OneForOneStrategy:默认的策略,只针对异常Subordinate ActorAllForOneStrategy:针对所有的Subordinate Actor
AllForOneStrategy通常用在Subordinate Actor之间关系紧密的场景下,一旦某个Subordinate Actor异常了,整体就无法正常处理消息。如果不用这种模式,我们就必须保证在异常Subordinate Actor恢复之前,只缓存消息,不处理消息
通常来说,在OneForOneStrategy模式下,终结一个Subordinate Actor不会影响到其他Subordinate Actor。但是,如果Terminated message没有被Supersivor Actor处理,那么Supersivor Actor就会抛出DeathPactException,并重启,于是默认的preRestart方法会终结所有Subordinate Actor
1.5 Actor References, Paths and Addresses
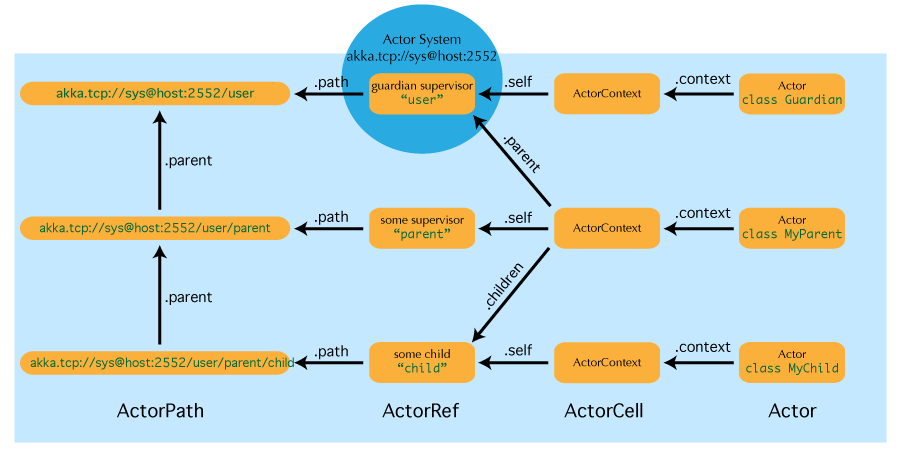
1.5.1 What is an Actor Reference
Actor Reference指的是ActorRef的子类,通常,我们用Actor Reference来发送消息。我们可以调用Actor.self()方法来获取到Actor自身对应的Actor Reference,同样,我们可以调用Actor.sender()方法来获取到消息发送方对应的Actor Reference
Actor Reference的种类
Purely Local Actor Reference: 不支持网络通信,无法跨应用,无法跨JVMLocal Actor Reference: 支持网络通信,但仅限在同一个JVM中的多个Java进程,无法跨JVMRemote Actor Reference: 支持网络通信,可以跨JVM
1.5.2 What is an Actor Path
由于Actor之间有严格的层级结构,因此对于每个Actor,根据层级关系,有唯一确定的名字。这些名字可以看做是文件系统中的文件。因此我们将这些名字称为Actor Path
1.5.2.1 Difference Between Actor Reference and Path
Actor Reference代表着一个Actor,因此Actor Reference的生命周期与Actor的生命周期匹配。Actor Path仅代表一个名字,本身并没有生命周期,因此永远不会失效。我们可以在不创建Actor的情况下,创建Actor Path;但是,不可以在不创建Actor的情况下,创建Actor Reference
我们可以创建一个Actor,然后终结它,然后再创建一个新的Actor,共享同一个Actor Path。这两个Actor仅仅共享了Actor Path,除此之外,无任何关系
1.5.2.2 Actor Path Anchors
pure local actor path: akka://<akka-system-name>/user/<actor-hierarchy-path>
remote actor path: akka.<protocol>://<akka-system-name>@<host>:<port>/user/<actor-hierarchy-path>
- 默认的
protocol是tcp
1.5.2.3 Logical Actor Paths
Logical Actor Path指的是:沿着Supervision Link,从Root Guardian到指定Actor的路径。即/user/<actor-hierarchy-path>
1.5.2.4 Physical Actor Paths
有时候,我们会在一个远程的Actor System中创建一个Actor,此时仅仅用Logical Actor Path,那么我们就需要处理额外的网络通信逻辑,这一部分会带来较大的工作量
值得注意的是,一个Physical Actor Path是全局唯一的,而Logical Actor Path仅仅在当前Actor System中唯一
1.5.2.5 Symbolic Link
与传统的文件系统不同,Actor Path不支持Symbolic Link
1.5.3 How are Actor References obtained
简单来说,获取Actor Reference的方式有且仅有两种:创建或者查找
1.5.3.1 Creating Actors
通过ActorSystem.actorOf方法或者ActorContext.actorOf方法来创建
ActorSystem.actorOf方法创建的Logical Actor Path为/user/<actor-name>ActorContext.actorOf方法创建的Logical Actor Path为/user/<original-actor-path>/<new-actor-name>
1.5.3.2 Looking up Actors by Concrete Path
通过ActorSystem.actorSelection方法或者ActorContext.actorSelection方法来搜索
ActorSystem.actorSelection方法的搜索起点是顶部ActorContext.actorSelection方法的搜索起点是当前Actor
1.5.3.3 Querying the Logical Actor Hierarchy
1.5.4 Actor Reference and Path Equality
只有当Actor Path相同,且封装了同一个Actor时,Actor Reference才相同。在Actor发生re-create(先terminate后create)前后的两个Actor Reference是不同的;在Actor发生re-start前后的两个Actor是相同的
1.5.5 Reusing Actor Paths
当一个Actor终结后,又重新创建了一个新的Actor,这两个Actor复用同一个Actor Path。Akka不保证在此过渡期间发往该Actor的任何事件的有序性,换言之,新创建的Actor可能收到本该发往旧Actor的消息
1.5.6 The Interplay with Remote Deployment
在远程模式下,我们创建一个Actor,Akka系统会决定在本地JVM创建该Actor或者在远程JVM中创建该Actor。对于后者,Action的创建可能触发在另一个远程JVM中,显然对应的是另一个Actor System。因此,Actor System会为这种方式创建的Actor赋予一个特殊的Actor Path。在这种情况下,新创建的Actor,其对应的Supervisor Actor就在另一个Actor System中(触发创建动作的Actor System),因此context.parent与context.path.parent并不是同一个Actor
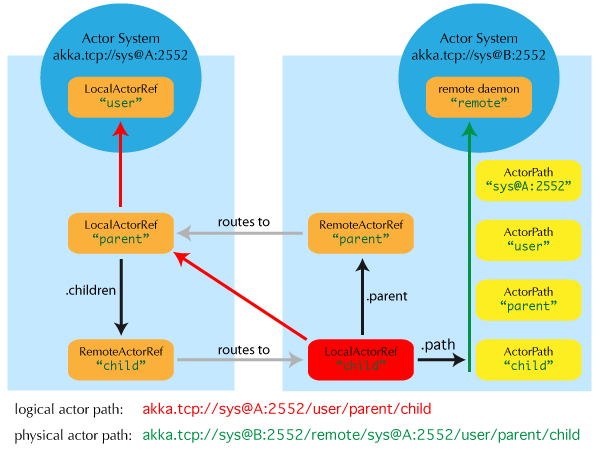
1.5.7 What is the Address part used for
当通过网络传递一个Actor Reference时,Actor Path即代表了这个Actor Reference。因此,Actor Path必须将所有必要的信息打包进Actor Path当中,这些信息包括protocol、host、port。当Actor System接收一个来自远程节点的Actor Reference时,首先会检查Actor Path是否匹配了本地的一个Actor,如果匹配成功,则将其替换成一个Local Actor Reference,否则就是Remote Actor Reference
1.5.8 Top-Level Scopes for Actor Paths
/: 根路径/user: 所有Normal Actor的起始路径/system: 所有System-created Actor的起始路径,包括Logging Actor/deadLetters: 所有发往已终结或者不存在的Actor的消息,最终都会被路由到这里/temp:Short-lived System-created Actor的起始路径/remote:Remote Actor的起始路径(其Supervisor Actor位于远程节点上)
1.6 Location Transparency
1.6.1 Distributed by Default
Akka在设计之初就考虑到了分布式的场景:Actor之间所有的交互都是通过Message来完成的,且都是异步的,这就保证了所有的操作在单节点或者多节点上都是等价的。为了实现这一愿景,所有的机制都是从Remote模式开始设计,然后对于Local模式进行优化。而不是从Local开始,然后再去考虑Remote的场景
1.6.2 How is Remoting Used
Akka几乎没有提供任何有关Remote的API,是否以Remote模式工作,完全取决于配置。这种特性可以让我们在不改动任何一行代码的情况下,让Akka System工作于不同的模式下,并且可以得到很好的可伸缩性、扩展性
Akka中唯一个与Remote相关的API就是:我们可以向Props提供一个Deploy参数,来改变模式。但是当Code与Configuration共存时,Configuration最终生效
1.6.3 Peer-to-Peer vs. Client-Server
Akka Remote是一个基于Peer-to-Peer的通信模块,用于连接多个Actor System,该模块是构建Akka Clustering的基础
选用Peer-to-Peer模式而不是Client-Server模式,主要有以下几个原因
- 不同
Actor System之间的通信是镜像对称的:Actor System A可以连接到Actor System B;同时Actor System B也可以连接到Actor System A - 不同
Actor System在通信系统中的角色是镜像对称的,没有一个Actor System只接受连接,也没有一个Actor System只发起连接
1.6.4 Marking Points for Scaling Up with Routers
更进一步,有时候,我们不想让我们的系统拆分成多个部分运行在不同的节点上,而是想让我们的系统在不同的节点上运行多个实例。Akka提供了不同的路由策略,包括round-robin。
The only thing necessary to achieve this is that the developer needs to declare a certain actor as “withRouter”, then—in its stead—a router actor will be created which will spawn up a configurable number of children of the desired type and route to them in the configured fashion. Once such a router has been declared, its configuration can be freely overridden from the configuration file, including mixing it with the remote deployment of (some of) the children.
1.7 Akka and the Java Memory Model
1.7.1 Java Memory Model
在Java 5之前,Java的内存模型存在很多问题
- 可见性问题:一个线程可以看到其他线程写的值
- 有序性问题:指令未能按照期望的顺序执行
在JSR-133之后,这些问题都得到了解决。Java内存模型中引入了happens-before原则,详细请参考Java-happens-before
1.7.2 Actors and Java Memory Model
介于Actor在Akka中的实现方式,多个线程同时操作共享内存的方式有如下两种
- 在大多数情况下,发送的消息要求是不可变的。但是如果消息是可变的,那么将不会存在
happens-before规则,接受者可能看到构建了一半的对象,或者说看到了某些值的一部分(例如double以及long) - 如果
Actor在处理某个消息时修改了该消息的内部状态,并且在后续某个时间点又访问了这个消息的状态。Actor Model不保证同一个Actor在处理不同消息时位于同一个线程中
为了避免可见性问题以及有序性问题,Akka保证了如下两条happens-before规则
The actor send rule:对于同一个Actor,消息的发送happens-before消息的接收???The actor subsequent processing rule:对于同一个Actor,处理某个消息happens-before处理下一个消息
1.7.3 Futures and the Java Memory Model
Future的完成happens-before注册回调的触发
Akka建议不要将non-final字段包装到闭包当中,如果一定要将non-final字段包装到闭包当中,那么这个字段需要用volatile关键字标记
1.8 Message Delivery Reliability
1.9 参考
2 Clustering
2.1 Cluster Specification
Akka Cluster提供了去中心化的容错机制,即无单点故障以及单机瓶颈。它使用了gossip协议以及自动故障检测机制。Akka Cluster允许构建一个分布式的应用,即整个应用/服务部署在多个节点上(准确地说是多个Actor System)
2.1.1 Term
node(下文称为节点):Akka Cluster中的逻辑单元,由hostname:port:uid三元组唯一确定。一台物理机上可能运行着多个node
cluster(下文称为集群):由多个node组成的一个有机整体
leader:在cluster中扮演者领导者的单个node。管理者cluter以及node状态的转换
2.1.2 Membership
cluster由一组node构成。每个node的由三元组hostname:port:uid唯一确定。这个标志符包含了一个UID,这个UID在hostname:port范围下是唯一的,也就是说,一个Actor System无法重复加入到一个集群之中,当创建一个新的Actor System时,会生成一个新的UID
2.1.2.1 Gossip
集群节点之间的通信,使用的是Gossip Protocol。集群状态信息会及时在节点上收敛,收敛意味着,一个节点观测到的集群状态与其他节点观测到的集群状态一致。
当任何节点变得unreachable时,这些节点需要变成reachable、down、removed状态,在此之前,处于非收敛状态
2.1.2.2 Failure Detector
Failure Detector用于检测那些unreachable的节点。Failure Detector用于解耦monitoring和interpretation。Failure Detector会保留一系列历史的异常数据,用于估计节点up或down的概率
threshold用于调整Failure Detector的行为。举个例子,一个较低的threshold可能会产生较多的错误估计,但是能够快速地响应一些异常状态;一个较高的threshold很少会犯错,但是通常检测一个节点处于异常状态会消耗更多的时间。默认的threshold是8,适用于绝大部分的应用
在一个集群中,一个节点通常被多个节点监视(默认情况下,不超过5个),当任何一个监视节点检测到该节点变得unreachable时,借助于gossip协议,就会将该信息传播到集群的其他节点上。换句话说,当一个节点发现某个节点变得unreachable后,在很短时间内,其他节点也会同步这一信息
节点每秒都会发送心跳包,每个心跳包包含了request/reploy对,其中reploy被当做Failure Detector的输入
此外,Failure Detector还会检测到节点重新变回reachable状态,当所有检测节点都检测到该节点变为reachable状态,且经过gossip传播后,会将其标记为reachable状态
如果系统消息无法达到一个节点,那么该节点将会被隔离,且永远无法从unreachable中恢复。此时,节点会被标记为down或者removed状态,该Actor System只有重启后,才允许再次加入集群中
2.1.2.3 Leader
当达到gossip收敛状态后,leader才会被确定,在Akka中,leader不是通过选举产生的,在集群达到收敛状态后,leader总能被任意节点确定出来。leader只是一个角色,任何节点都可以成为leader,且可能在不同的收敛轮次内发生改变。leader通常是有序节点中的第一个节点,对应的状态是up或leaving
leader的作用是将节点加入或移除集群,将刚加入集群的节点标记为up状态,或者将已存在的节点标记为removed状态。同时,leader也拥有一定的特权,根据Failure Detector的结果,它可以将一个处于unreachable的节点标记为down状态
2.1.2.4 Seed Nodes
Seed Nodes是为新加入集群的节点所配置的接触点。当一个节点需要加入集群时,它会向所有Seed Node发送消息,并向最先回复的Seed Node发送Join Command消息
Seed Node的配置不会影响集群的运行时,它们只与加入集群的新节点相关,Seed Node帮助新节点找到发送Join Command消息的节点。新节点可以将该消息发送给集群中的任意节点,而不仅仅是Seed Node。换言之,集群中的任意节点都可以是Seed Node
2.1.2.5 Membership Lifecycle
一个节点从joining状态开始生命周期,当集群中的所有节点都观测到该节点加入后,leader就会将该节点标记为up
一个节点如果以一种安全、期望的方式离开集群,那么就会进入leaving状态,当leader观测到集群在leaving状态收敛时,就会将它标记为exiting,当其他所有节点观测到该节点进入exiting状态后,leader就会将其标记为removed状态
当一个节点变得unreachable时,收敛状态将无法达到,在此时,leader无法做任何工作(比如,让一个节点加入集群)。为了达到一个可收敛的状态,该节点必须重新reachable或者被标记为down状态,如果这个节点想要重新加入到集群中,那么它必须重新启动,然后重新走一遍join的流程。leader会在规定时间之后(基于配置),将unreachable节点标记为down状态
上面说到,当节点进入变得unreachable时,集群无法达到收敛状态,我们可以通过配置akka.cluster.allow-weakly-up-members(默认开启),这样一来,在非收敛状态时,新节点允许进入集群,但会被标记为weaklyup状态,当收敛状态重新达到时,leader会将weaklyup标记为up
akka.cluster.allow-weakly-up-members=off时,状态机如下
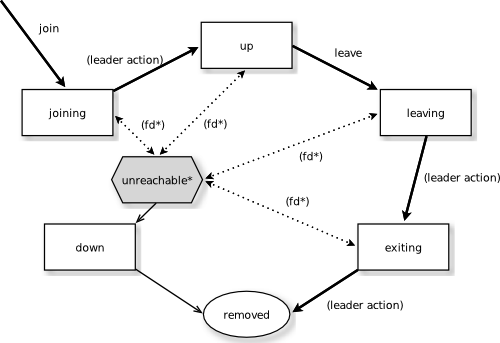
akka.cluster.allow-weakly-up-members=on时,状态机如下

成员状态
joinging:节点加入集群时的瞬态weakly up:当集群未收敛,且akka.cluster.allow-weakly-up-members=on时,节点加入集群时的瞬态up:正常的工作状态leaving/exiting:以优雅、期望地方式离开集群的状态down:不再参与集群的决策removed:不再是集群的成员
用户可以进行的操作
join:加入集群leave:优雅地离开集群down:将节点标记为down
leader actions
joinint->upweakly up->upexiting->removed
2.2 Cluster Usage
2.2.1 When and where to use Akka Cluster
微服务架构有着诸多的优点,微服务的独立性允许多个更小、更专业的团队能够频繁地提供新功能,能够快速响应业务需求
在微服务架构中,我们必须考虑服务间以及服务内这两种通信方式
通常,我们不建议用Akka Cluster来完成服务间的通信,因为这会导致两个微服务产生严重的代码耦合,且会带来部署的依赖性,这与微服务架构的初衷相悖
但是,对于一个微服务的不同节点之间的通信(一个微服务通常是一个集群,部署在多台机器上)对于耦合性的要求就很低,因为它们的代码是相同的,且是同时部署的
2.2.2 Joining to Seed Nodes
我们可以手动配置Seed Node或自动配置Seed Node。在完成连接过程之后,Seed Node与其他节点并无差别。此外,集群中的任意节点都可以作为Seed Node(即便配置文件中的Seed Node列表不包含该节点,只要该节点正常加入集群后,该节点就可以作为Seed Node)
我们可以在配置文件中配置Seed Node
1 | akka.cluster.seed-nodes = [ |
或者,在启动JVM时,指定环境变量
1 | -Dakka.cluster.seed-nodes.0=akka.tcp://ClusterSystem@host1:2552 |
Seed Node可以以任意顺序启动,除了第一个Seed Node,该Seed Node节点必须作为集群启动的第一个节点,否则其他Seed Node以及其他节点将无法加入集群。将第一个Seed Node特殊处理的原因是,避免形成多个孤立的集群
当Seed Node的数量超过1时,且集群正常启动后,停止第一个Seed Node是没有关系的,如果这个Seed Node再次加入,那么它首先会尝试连接其他的Seed Node。注意,如果我们将所有的Seed Node全部停止,然后重启所有的Seed Node,那么就会创建一个全新的集群,而不是重新加入之前的集群,于是之前的集群变成了一个孤岛(这也是为什么需要特殊处理第一个Seed Node的原因)
借助Cluster Bootstrap,我们无需手动配置Seed Node,便可以自动化地创建Seed Node
此外,我们还可以通过编程的方式,指定Seed Node
1 | final Cluster cluster = Cluster.get(system); |
2.2.3 Downing
当一个节点被Failure Detector认为是unreachable时,Leader便无法正常工作(因为此时集群处于非收敛状态),例如,无法将一个新加入集群的节点标记为up状态。该unreachable节点必须重新变得reachable或者被标记为down状态后,集群才会进入收敛状态,Leader才能进行正常工作。节点可以以手动或者自动的方式被标记为down状态。默认以手动方式,利用JMX或HTTP。此外,还可以以编程的方式将节点标记为down,即Cluster.get(system).down(address)
如果一个正常执行的节点将自身标记为down,那么该节点将会终止
此外,Akka还提供了一种自动将unreachable节点标记为down的机制,这意味着Leader会自动将超过配置时间的unreachable节点标记为down。Akka强烈建议不要使用该特性:该auto-down特性不应该在生产环境使用,因为当出现网络抖动时(或者长时间的Full GC,或者其他原因),集群的两部分变得相互不可见,于是会将对方移除集群,随后形成了两个完全独立的集群
2.2.4 Leaving
节点离开集群的方式有两种
- 直接杀掉JVM进程,该节点会被检测为
unreachable,于是被自动或手动地标记为down - 告诉集群将要离开集群,这种方式更为优雅,可以通过
JMX或HTTP来实现,或者通过编程方式来实现,如下
1 | final Cluster cluster = Cluster.get(system); |
2.2.5 WeaklyUp Members
当集群中的某节点变得unreachable后,集群无法收敛,Leader无法正常工作,在这种情况下,我们仍然想让新节点加入到集群中来
新加入的节点会首先被标记为WeaklyUp,当集群进入收敛状态,Leader会将标记为WeaklyUp状态的节点标记为Up,该特性是默认开启的,可以通过akka.cluster.allow-weakly-up-members = off来关闭
我们可以订阅MemberWeaklyUp事件来感知这一状态,但是由于这一事件是发生在集群非收敛状态下的,即节点并不一定能够感知到这个状态(网络问题或其他原因),因此不要基于这个状态来作出某些决策
2.2.6 Subscribe to Cluster Events
我们可以通过Cluster.get(system).subscribe来订阅某些消息
1 | cluster.subscribe(getSelf(), MemberEvent.class, UnreachableMember.class); |
与节点生命周期相关的事件如下
ClusterEvent.MemberJoined:节点刚加入集群,被标记为joining状态ClusterEvent.MemberUp:节点加入集群,被标记为up状态ClusterEvent.MemberExited:节点离开集群,被标记为exiting状态。注意到,当其他节点收到该消息时,离开集群的节点可能早已终结ClusterEvent.MemberRemoved:节点被集群移除ClusterEvent.UnreachableMember:节点被Failure Detector或者其他任意节点检测为unreachableClusterEvent.ReachableMember:节点再次被检测为reachable。之前所有检测到该节点为unreachable的节点,都需要再次检测到该节点为reachable