阅读更多
1 运行存储分配概述
1.1 运行存储分配策略
编译器在工作过程中,必须为源程序中出现的一些数据对象分配运行时的存储空间
- 对于那些在编译时刻就可以确定大小的数据对象,可以在编译时刻就为它们分配存储空间,这样的分配策略称为静态存储分配
- 反之,如果不能在编译时完全确定数据对象的大小,就要采用动态存储分配的策略。即在编译时仅产生各种必要的信息,而在运行时刻,再动态地分配数据对象的存储空间
- 栈式存储分配
- 堆式存储分配
- 其中,静态和动态分别对应编译时刻和运行时刻
1.2 运行时内存的划分
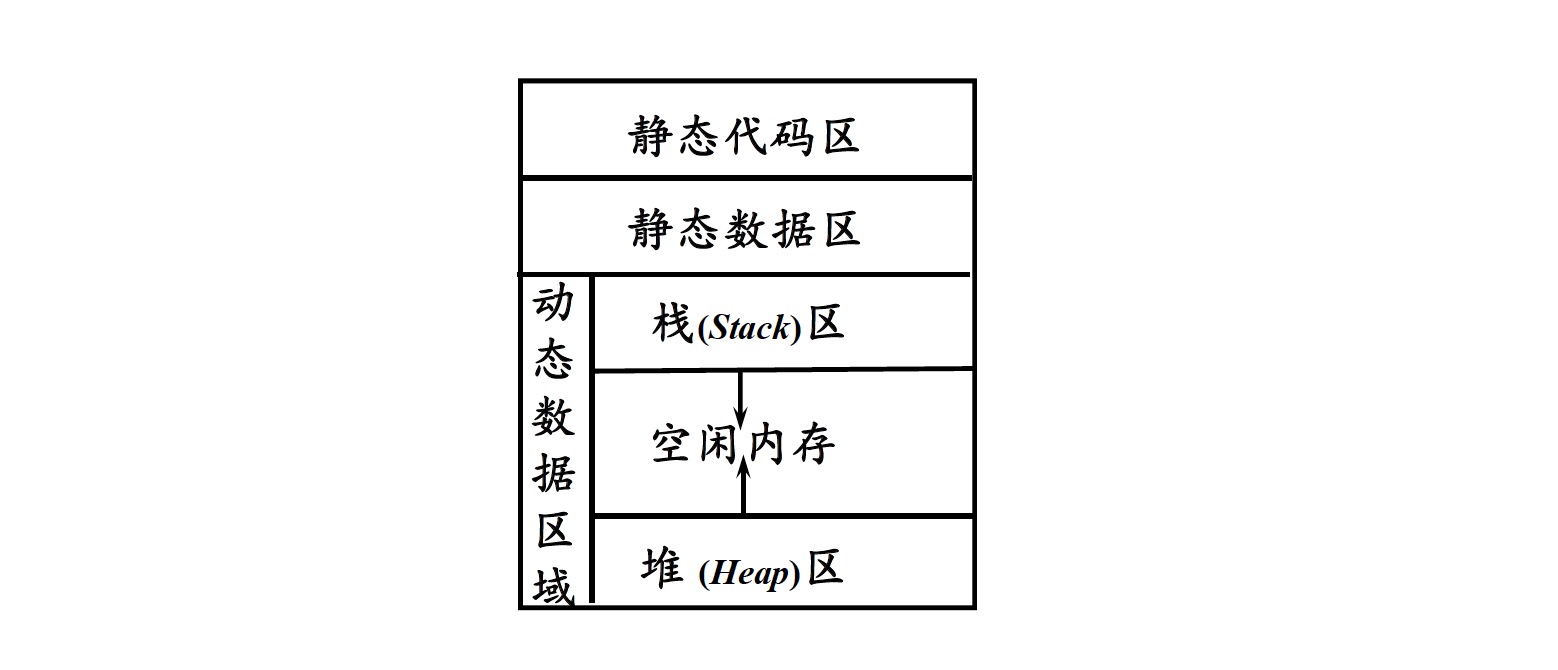
1.3 活动记录
使用过程(或函数、方法)作为用户自定义动作的单元的语言,其编译器通常以过程为单位分配存储空间
过程体的每次执行称为该过程的一个活动(activation)
过程每执行一次,就为它分配一块连续存储区,用来管理过程一次执行所需的信息,这块连续存储区称为活动记录(activation record)
1.4 活动记录的一般形式
活动记录一般包括以下内容
- 实参
- 返回值
- 控制链:指向调用者的活动记录
- 访问链:用来访问存放于其它活动记录中的非局部数据
- 保存的机器状态
- 局部数据
- 临时变量
2 静态存储分配
在静态存储分配中,编译器为每个过程确定其活动记录在目标程序中的位置
- 这样,过程中每个名字的存储位置就确定了
- 因此,这些名字的存储地址可以被编译到目标代码中
- 过程每次执行时,它的名字都绑定到同样的存储单元
2.1 静态存储分配的限制条件
适合静态存储分配的语言必须满足以下条件
- 数组上下界必须是常数
- 不允许过程的递归调用
- 不允许动态建立数据实体
满足这些条件的语言有BASIC和FORTRAN等
2.2 常用的静态存储分配方法
常用的静态存储分配方法有如下两种
- 顺序分配法
- 层次分配法
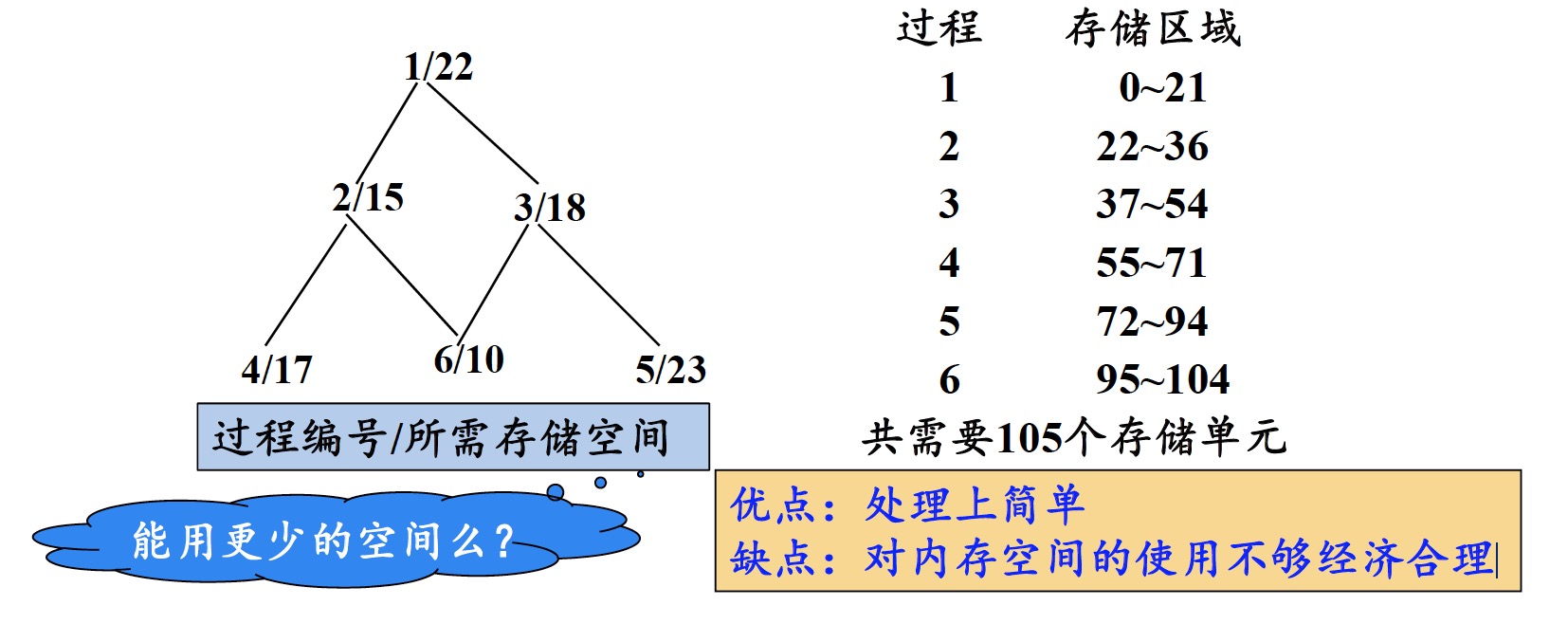
2.2.1 顺序分配法
按照过程出现的先后顺序逐段分配存储空间,各过程的活动记录占用互不相交的存储空间
优点:处理上简单
缺点:对内存空间的使用不够经济合理
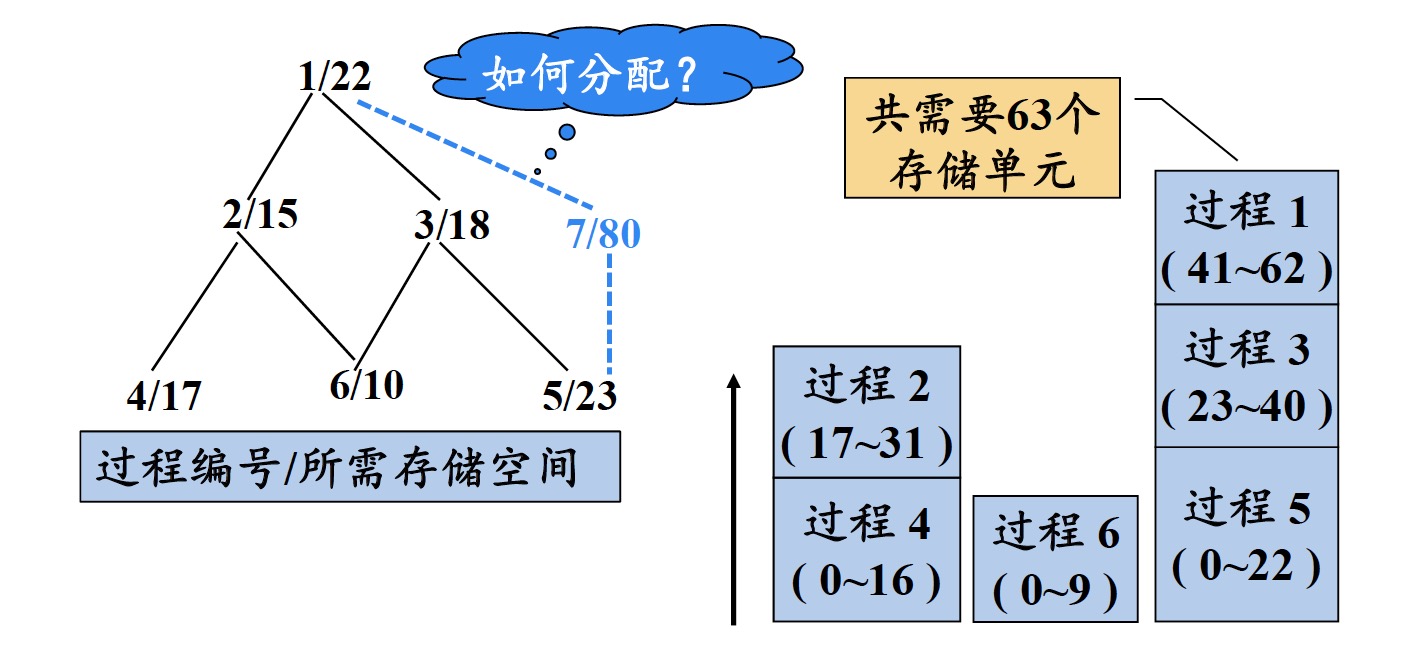
2.2.2 层次分配法
通过对过程间的调用关系进行分析,凡属无相互调用关系的并列过程,尽量使其局部数据共享存储空间。(类似操作系统内存管理中的覆盖技术)
层次分配算法
-
$B[n][n]$:过程调用关系矩阵
- $B[ i ][ j ] = 1$: 表示第$i$个过程调用第$j$个过程
- $B[ i ][ j ] = 0$:表示第$i$个过程不调用第$j$个过程
- $Units[n]$:过程所需内存量矩阵
- $base[ i ]$:第$i$个过程局部数据区的基地址
- $allocated[ i ]$:第$i$个过程局部数据区是否分配的标志
1 | //NoOfBlocks indicating how many blocks there are |
3 栈式存储分配
有些语言使用过程、函数或方法作为用户自定义动作的单元,几乎所有针对这些语言的编译器都把它们的(至少一部分的)运行时刻存储以栈的形式进行管理,称为栈式存储分配
- 当一个过程被调用时,该过程的活动记录被压入栈;当过程结束时,该活动记录被弹出栈
- 这种安排不仅允许活跃时段不交叠的多个过程调用之间共享空间,而且允许以如下方式为一个过程编译代码:它的非局部变量的相对地址总是固定的,和过程调用序列无关
3.1 活动树
用来描述程序运行期间控制进入和离开各个活动的情况的树称为活动树
- 树中的每个结点对应于一个活动。根结点是启动程序执行的main过程的活动
- 在表示过程p的某个活动的结点上,其子结点对应于被p的这次活动调用的各个过程的活动。按照这些活动被调用的顺序,自左向右地显示它们。一个子结点必须在其右兄弟结点的活动开始之前结束。
控制栈
- 每个活跃的活动都有一个位于控制栈中的活动记录
- 活动树的根的活动记录位于栈底
- 程序控制所在的活动的记录(即当前活动)位于栈顶
- 栈中全部活动记录的序列对应于在活动树中到达当前控制所在的活动结点的路径
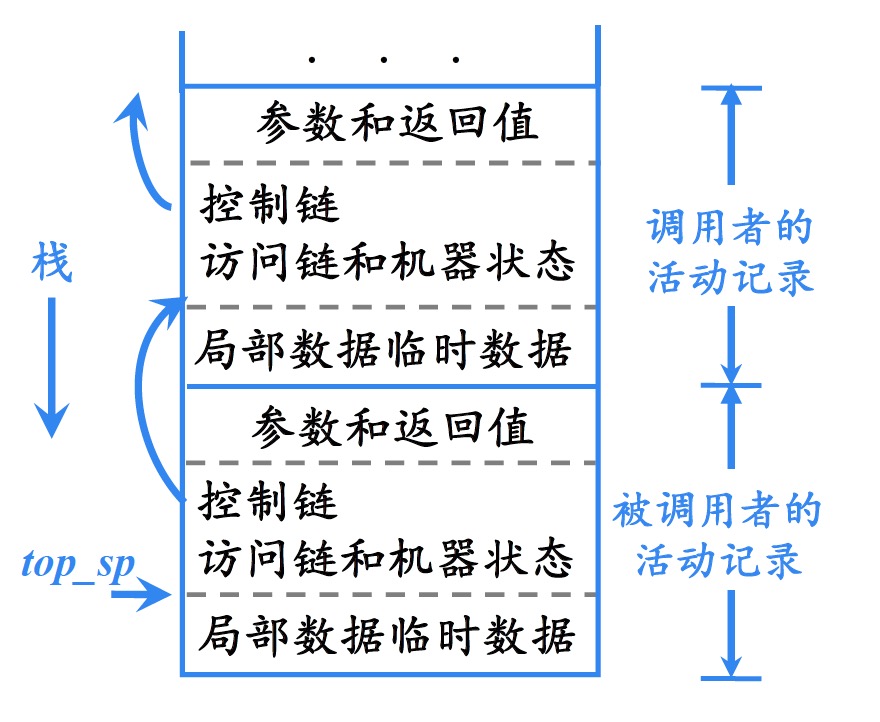
3.2 设计活动记录的一些原则
在调用者和被调用者之间传递的值一般被放在被调用者的活动记录的开始位置,这样它们可以尽可能地靠近调用者的活动记录
固定长度的项被放置在中间位置:控制连、访问链、机器状态字
在早期不知道大小的项被放置在活动记录的尾部
栈顶指针寄存器top_sp指向活动记录中局部数据开始的位置,以该位置作为基地址
4 调用序列和返回序列
过程调用和过程返回都需要执行一些代码来管理活动记录栈,保存或恢复机器状态等
- 调用序列:实现过程调用的代码段。为一个活动记录在栈中分配空间,并在此记录的字段中填写信息
- 返回序列:恢复机器状态,使得调用过程能够在调用结束之后继续执行
- 一个调用代码序列中的代码通常被分割到调用过程(调用者)和被调用过程(被调用者)中。返回序列也是如此
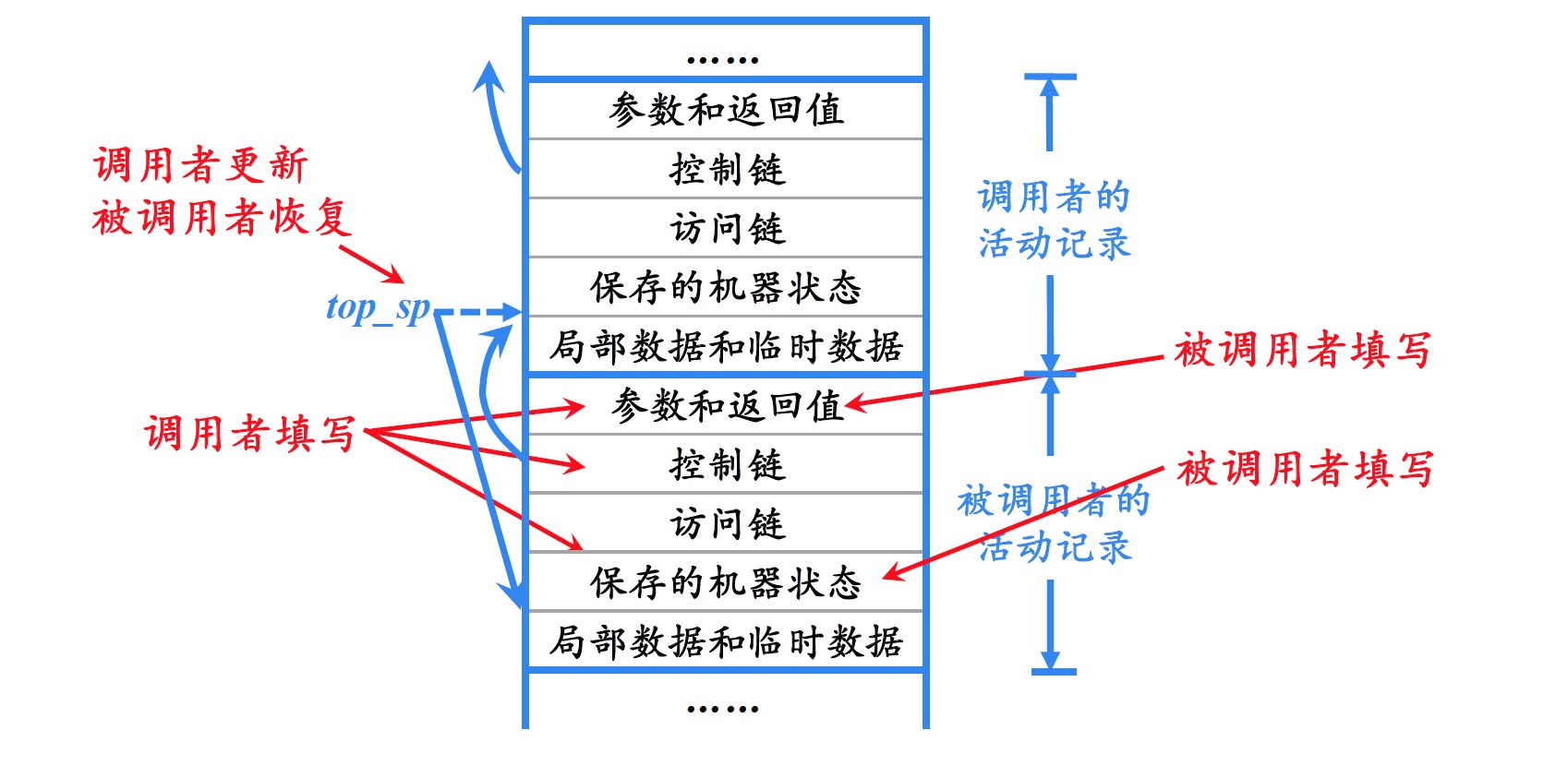
4.1 调用序列
- 调用者计算实际参数的值
- 调用者将返回地址(程序计数器的值)放到被调用者的机器状态字段中。将原来的
top-sp值放到被调用者的控制链中。然后,增加top-sp的值,使其指向被调用者局部数据开始的位置 - 被调用者保存寄存器值和其它状态信息
- 被调用者初始化其局部数据并开始执行
4.2 返回序列
- 被调用者将返回值放到与参数相邻的位置
- 使用机器状态字段中的信息,被调用者将恢复
top-sp和其它寄存器,然后跳转到由调用者放在机器状态字段中的返回地址 - 尽管
top-sp已经被减小(已恢复),但调用者仍然知道返回值相对于当前top-sp值的位置(位于下一个活动记录中,虽然此时已经弹出,但数据仍然有效)。因此,调用者可以使用那个返回值
4.3 变长数据的存储分配
在现代程序设计语言中,在编译时刻不能确定大小的对象将被分配在堆区。但是,如果它们是过程的局部对象,也可以将它们分配在运行时刻栈中。尽量将对象放置在栈区的原因:可以避免对它们的空间进行垃圾回收,也就减少了相应的开销
只有一个数据对象局部于某个过程,且当此过程结束时它变得不可访问,才可以使用栈为这个对象分配空间
5 非局部数据的访问
一个过程除了可以使用过程自身定义的局部数据以外,还可以使用过程外定义的非局部数据
语言可以分为两种类型
- 支持过程嵌套声明的语言
- 可以在一个过程中声明另一个过程
- 一个过程除自身定义的局部数据和全局定义的数据以外,还可以使用外围过程中声明的对象
- 例: Pascal
- 不支持过程嵌套声明的语言
- 不可以在一个过程中声明另一个过程
- 过程中使用的数据要么是自身定义的局部数据,要么是在所有过程之外定义的全局数据
- 例:C
5.1 无过程嵌套声明时的数据访问
变量的存储分配和访问
- 全局变量被分配在静态区,使用静态确定的地址访问它们
- 其它变量一定是栈顶活动的局部变量。可以通过运行时刻栈的
top_sp指针访问它们
5.2 有过程嵌套声明时的数据访问
嵌套深度
- 过程的嵌套深度
- 不内嵌在任何其它过程中的过程,设其嵌套深度为1
- 如果一个过程p在一个嵌套深度为i的过程中定义,则设定p的嵌套深度为i +1
- 变量的嵌套深度
- 将变量声明所在过程的嵌套深度作为该变量的嵌套深度

5.3 访问链(Access Links)
静态作用域规则:只要过程b的声明嵌套在过程a的声明中,过程b就可以访问过程a中声明的对象
可以在相互嵌套的过程的活动记录之间建立一种称为访问链(Access link)的指针,使得内嵌的过程可以访问外层过程中声明的对象
- 如果过程b在源代码中直接嵌套在过程a中(b的嵌套深度比a的嵌套深度多1),那么b的任何活动中的访问链都指向最近的a的活动
5.3.1 访问链的建立
建立访问链的代码属于调用序列的一部分
假设嵌套深度为$n_x$的过程$x$调用嵌套深度为$n_y$的过程$y(x \to y)$
-
$n_x \lt n_y$的情况(外层调用内层)
- y一定是直接在$x$中定义的(例如:$s \to q$, $q \to p$),因此,$n_y = n_x +1$
- 在调用代码序列中增加一个步骤:在$y$的访问链中放置一个指向$x$的活动记录的指针
-
$n_x = n_y$的情况(本层调用本层)
- 递归调用(例如: $q \to q$ )
- 被调用者的活动记录的访问链与调用者的活动记录的访问链是相同的,可以直接复制
-
$n_x > n_y$的情况(内层调用外层,如: $p \to e$ )
- 过程$x$必定嵌套在某个过程$z$中,而$z$中直接定义了过程$y$
- 从$x$的活动记录开始,沿着访问链经过$n_x - n_y + 1$步就可以找到离栈顶最近的$z$的活动记录。$y$的访问链必须指向$z$的这个活动记录
6 堆式存储分配
堆式存储分配是把连续存储区域分成块,当活动记录或其它对象需要时就分配
块的释放可以按任意次序进行,所以经过一段时间后,对可能包含交错的正在使用和已经释放的区域
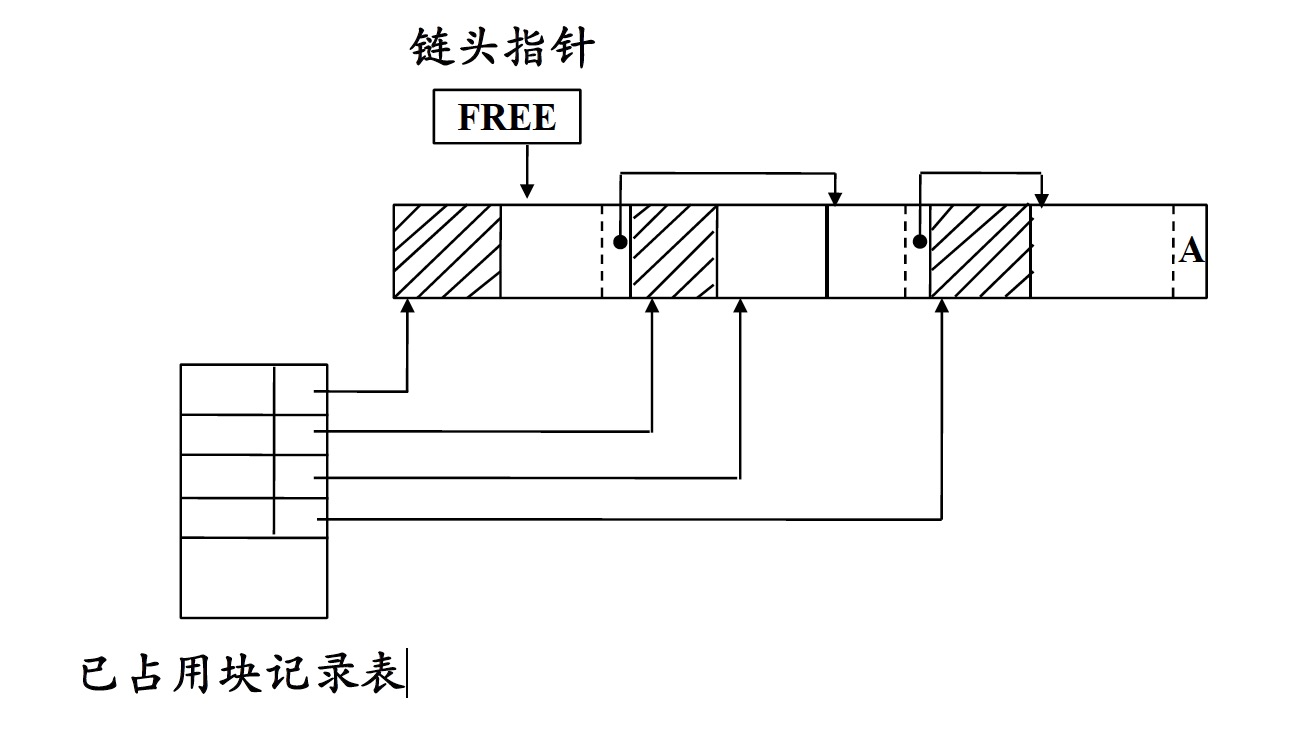
6.1 申请
设当前自由块总长为M,欲申请长度为n
- 如果存在若干个长度大于或等于n的存储块,可按以下策略之一进行存储分配
- 取长度m满足需求的第1个自由块,将长度为m-n的剩余部分仍放在自由链中
- 取长度m满足需求的最小的自由块
- 取长度m满足需求的最大的自由块
- 如果不存在长度大于或等于n的存储块
- 如果$M \ge n$,将自由块在堆中进行移位和重组(对各有关部分都需作相应的修改,是一件十分复杂和困难的工作)
- 如果$M \lt n$,则应采用更复杂的策略来解决堆的管理问题
6.2 释放
只需将被释放的存储块作为新的自由块插入自由链中,并删除已占块记录表中相应的记录即可
6.3 小结
为实现堆式存储管理,须完成大量的辅助操作。如排序、查表、填表、插入、删除、…。其空间和时间的开销较大
7 符号表
符号表的组织:为每个作用域(程序块)建立一个独立的符号表
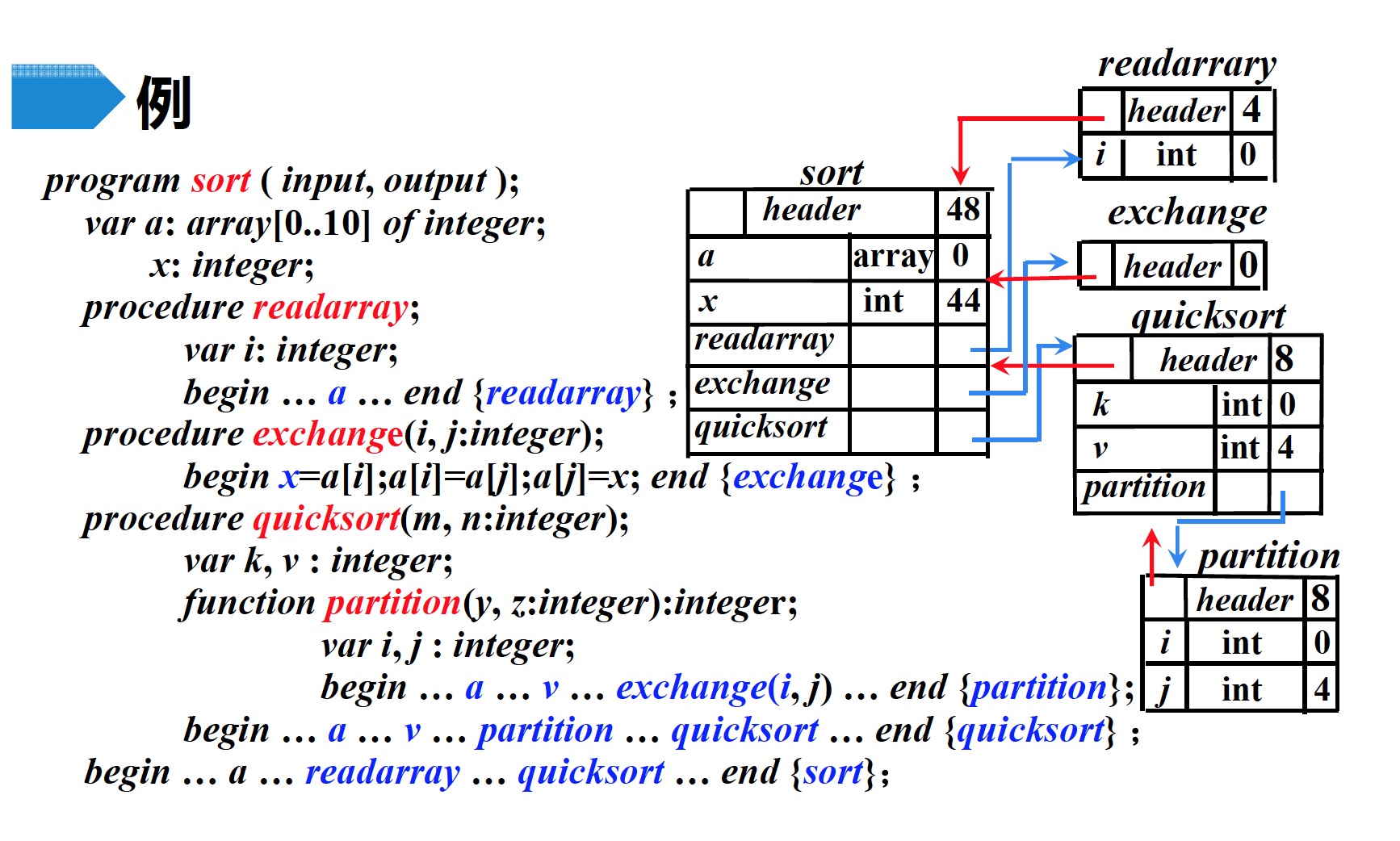
7.1 根据符号表进行数据访问
实际上,这种为每个过程或作用域建立的符号表与编译时的活动记录是对应的。一个过程的非局部名字的信息可以通过扫描外围过程的符号表而得到
7.2 标识符的基本处理方法
当在某一层的声明语句中识别出一个标识符(id的定义性出现)时,以此标识符查相应于本层的符号表
- 如果查到,则报错并发出诊断信息“id重复声明”
- 否则,在符号表中加入新登记项,将标识符及有关信息填入
当在可执行语句部分扫视到标识符时(id的应用性出现)
- 首先在该层符号表中查找该id,如果找不到,则到直接外层符号表中去查,如此等等,一旦找到,则在表中取出有关信息并作相应处理
- 如果查遍所有外层符号表均未找到该id,则报错并发出诊断信息“id未声明”
8 符号表的建立
嵌套过程声明语句的文法
$$\begin{split} P &\to D \\ D &\to D\;D| proc\;id ;D\;S| id : T ; \end{split}$$8.1 嵌套过程声明语句的SDT
涉及到的语义动作函数
- $mktable(previous)$:创建一个新的符号表,并返回指向新表的指针。参数$previous$指向先前创建的符号表(外围过程的符号表)
- $addwidth(table, width)$:将$table$指向的符号表中所有表项的宽度之和$width$记录在符号表的表头中
- $enterproc(table, name, newtable)$:在$table$指向的符号表中为过程$name$建立一条记录,$newtable$指向过程$name$的符号表
- $enter(table, name, type, offset)$:在$table$指向的符号表中为名字$name$建立一个新表项

8.2 例子
- 根据产生式$P \to M\;D$,执行$M$的语义动作
- 创建符号表$nil$
- 将新创建的符号表$t$压入$tblptr$
- 将偏移量0压入$offset$
- 读入字符串
program sort;,根据产生式$D_p \to proc\;id ; N\;D_1\;S$,执行$N$的语义动作- 创建符号表$sort$
- 将新创建的符号表$t$压入$tblptr$
- 将偏移量0压入$offset$
- 读入字符串
var a:int[11]; x:int;,根据产生式$D_v \to id: T ;$进行归约,然后执行归约后的语义动作- 在栈顶符号表$sort$中,创建一条记录:$a\;array\;0$
- 修改$offset$栈顶元素的值:$0 \to 44$
- 在栈顶符号表$sort$中,创建一条记录:$x\;int\;44$
- 修改$offset$栈顶元素的值:$44 \to 48$
- 读入字符串
proc readarray;,根据产生式$D_p \to proc\;id ; N\;D_1\;S$,执行$N$的语义动作- 创建符号表$readarrary$
- 将新创建的符号表$t$压入$tblptr$
- 将偏移量0压入$offset$
- 读入字符串
var i:int;,根据产生式$D_v \to id: T ;$进行归约,然后执行归约后的语义动作- 在栈顶符号表$readarrary$中,创建一条记录:$i\;int\;0$
- 修改$offset$栈顶元素的值:$0 \to 4$
- 读入
readarray的代码段字符串,根据产生式$D_p \to proc\;id ; N\;D_1\;S$进行归约,然后执行归约后的语义动作- 将$offset$栈顶记录的偏移量(4)记录到符号表$readarrary$中的
header部分 - $offset$与$tblptr$各自弹出栈顶元素
- 在$tblptr$栈顶指针指向的符号表($sort$)中建立一条记录$readarray$,存放指向符号表$readarray$的指针
- 将$offset$栈顶记录的偏移量(4)记录到符号表$readarrary$中的
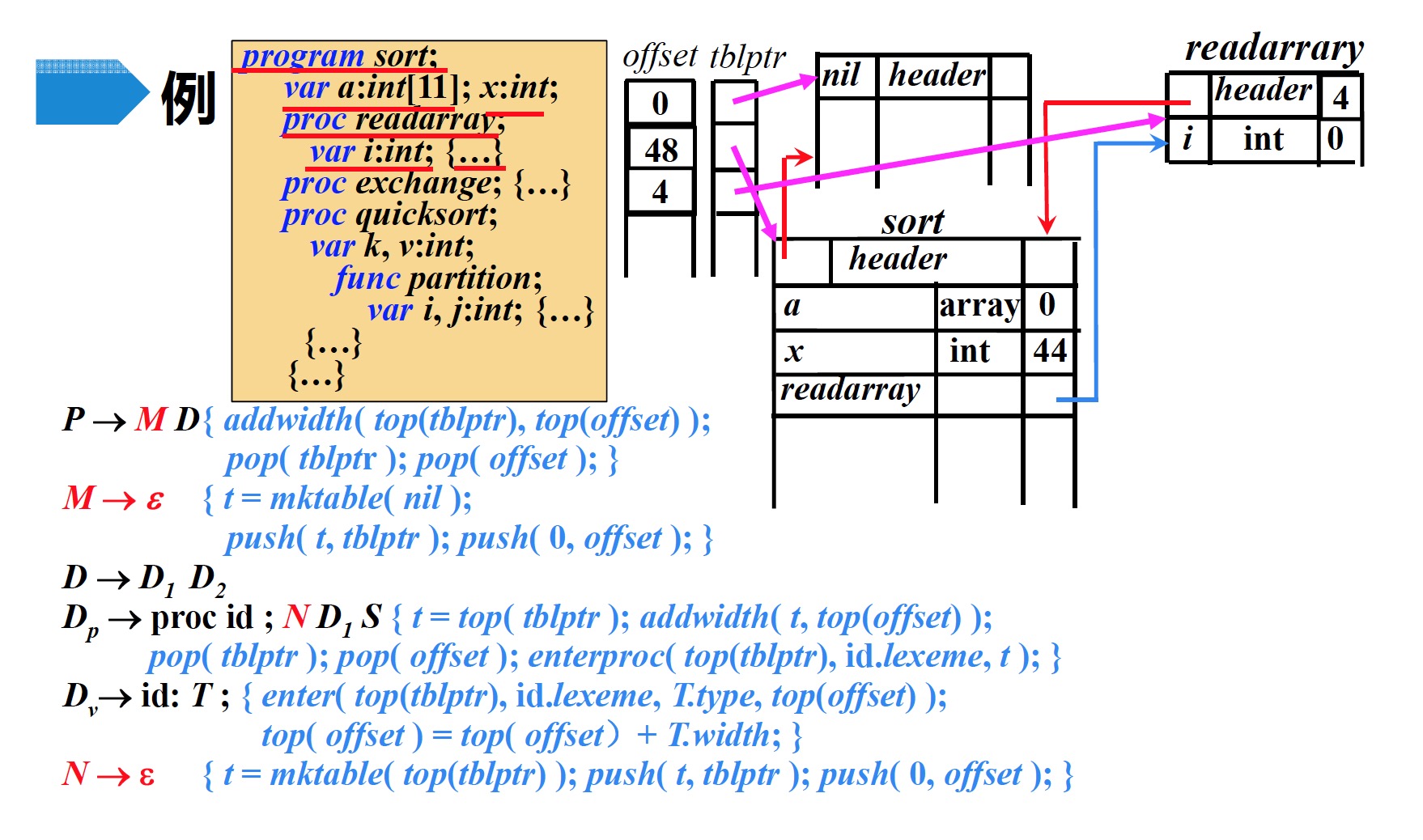
- 读入字符串
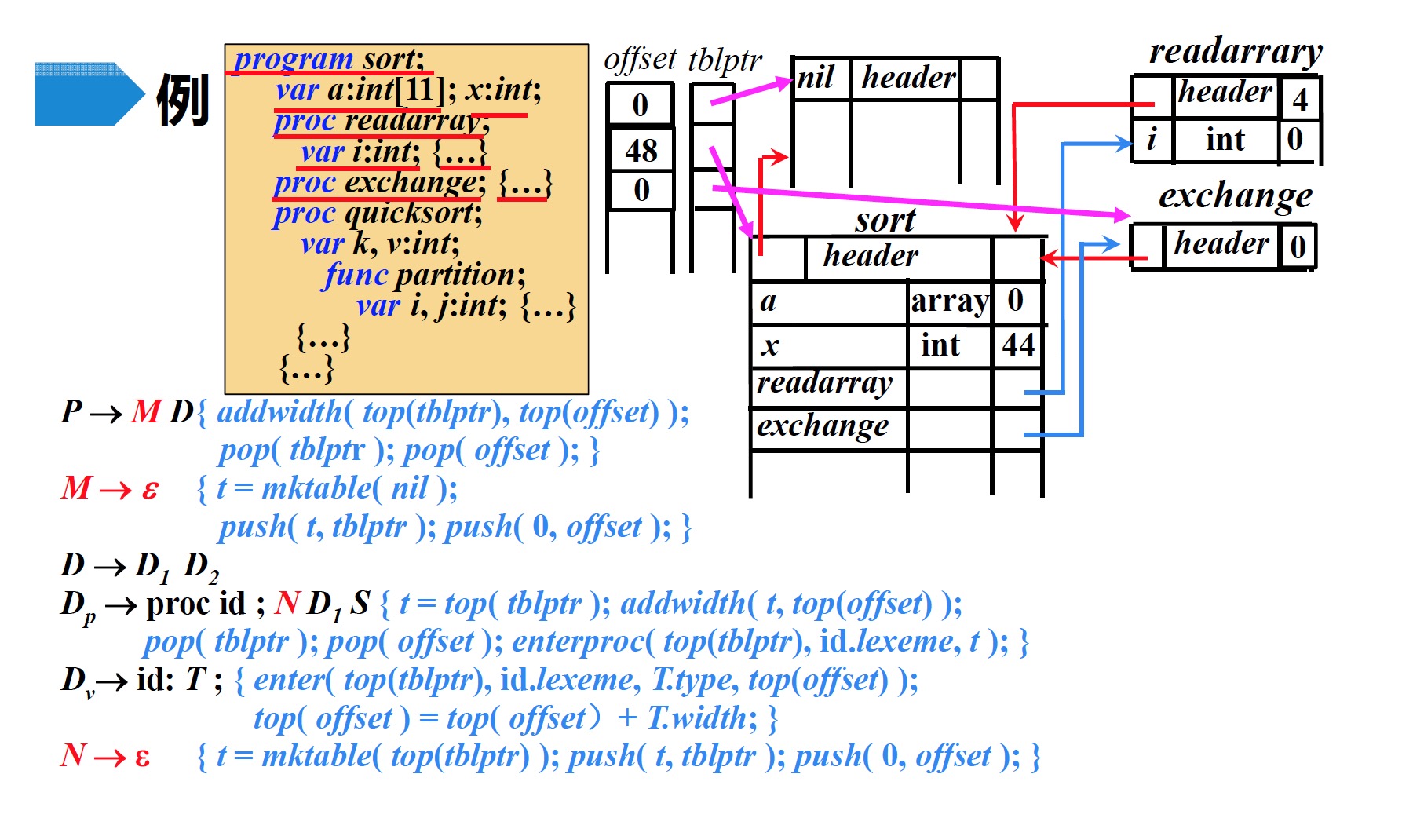
proc exchange;,根据产生式$D_p \to proc\;id ; N\;D_1\;S$,执行$N$的语义动作- 创建符号表$exchange$
- 将新创建的符号表$t$压入$tblptr$
- 将偏移量0压入$offset$
- 读入
exchange的代码段字符串,根据产生式$D_p \to proc\;id ; N\;D_1\;S$进行归约,然后执行归约后的语义动作- 将$offset$栈顶记录的偏移量(0)记录到符号表$exchange$中的
header部分 - $offset$与$tblptr$各自弹出栈顶元素
- 在$tblptr$栈顶指针指向的符号表($sort$)中建立一条记录$exchange$,存放指向符号表$exchange$的指针
- 将$offset$栈顶记录的偏移量(0)记录到符号表$exchange$中的
- 读入字符串
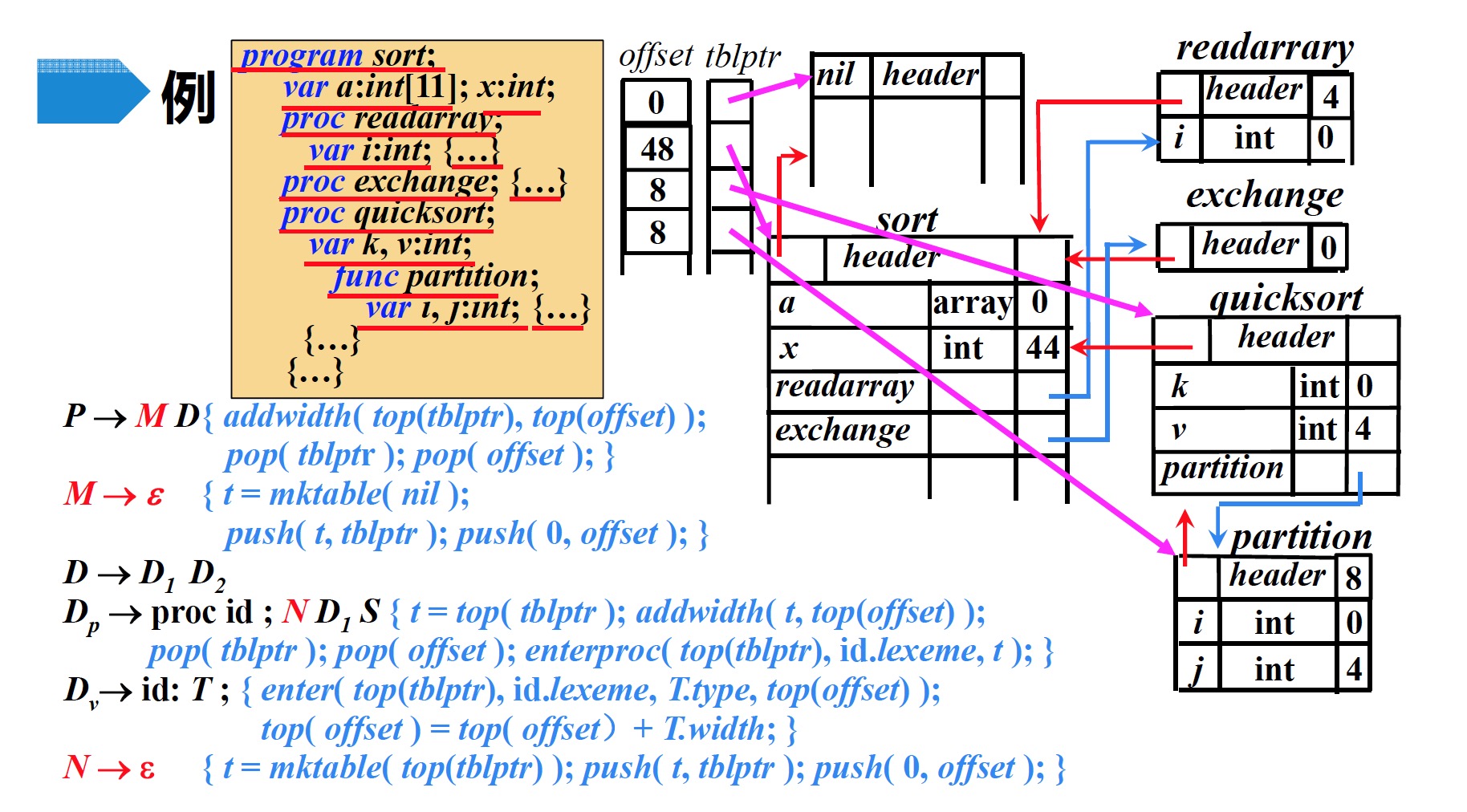
proc quicksort;,根据产生式$D_p \to proc\;id ; N\;D_1\;S$,执行$N$的语义动作- 创建符号表$quicksort$
- 将新创建的符号表$t$压入$tblptr$
- 将偏移量0压入$offset$
- 读入字符串
var k, v:int;,根据产生式$D_v \to id: T ;$进行归约,然后执行归约后的语义动作- 在栈顶符号表$quicksort$中,创建一条记录:$k\;int\;0$
- 修改$offset$栈顶元素的值:$0 \to 4$
- 在栈顶符号表$quicksort$中,创建一条记录:$v\;int\;4$
- 修改$offset$栈顶元素的值:$4 \to 8$
- 读入字符串
func partition,根据产生式$D_p \to proc\;id ; N\;D_1\;S$,执行$N$的语义动作- 创建符号表$partition$
- 将新创建的符号表$t$压入$tblptr$
- 将偏移量0压入$offset$
- 读入字符串
var i, j:int;,根据产生式$D_v \to id: T ;$进行归约,然后执行归约后的语义动作- 在栈顶符号表$partition$中,创建一条记录:$i\;int\;0$
- 修改$offset$栈顶元素的值:$0 \to 4$
- 在栈顶符号表$partition$中,创建一条记录:$j\;int\;4$
- 修改$offset$栈顶元素的值:$4 \to 8$
- 读入
partition的代码段字符串,根据产生式$D_p \to proc\;id ; N\;D_1\;S$进行归约,然后执行归约后的语义动作- 将$offset$栈顶记录的偏移量(8)记录到符号表$partition$中的
header部分 - $offset$与$tblptr$各自弹出栈顶元素
- 在$tblptr$栈顶指针指向的符号表($quicksort$)中建立一条记录$partition$,存放指向符号表$partition$的指针
- 将$offset$栈顶记录的偏移量(8)记录到符号表$partition$中的
- 读入
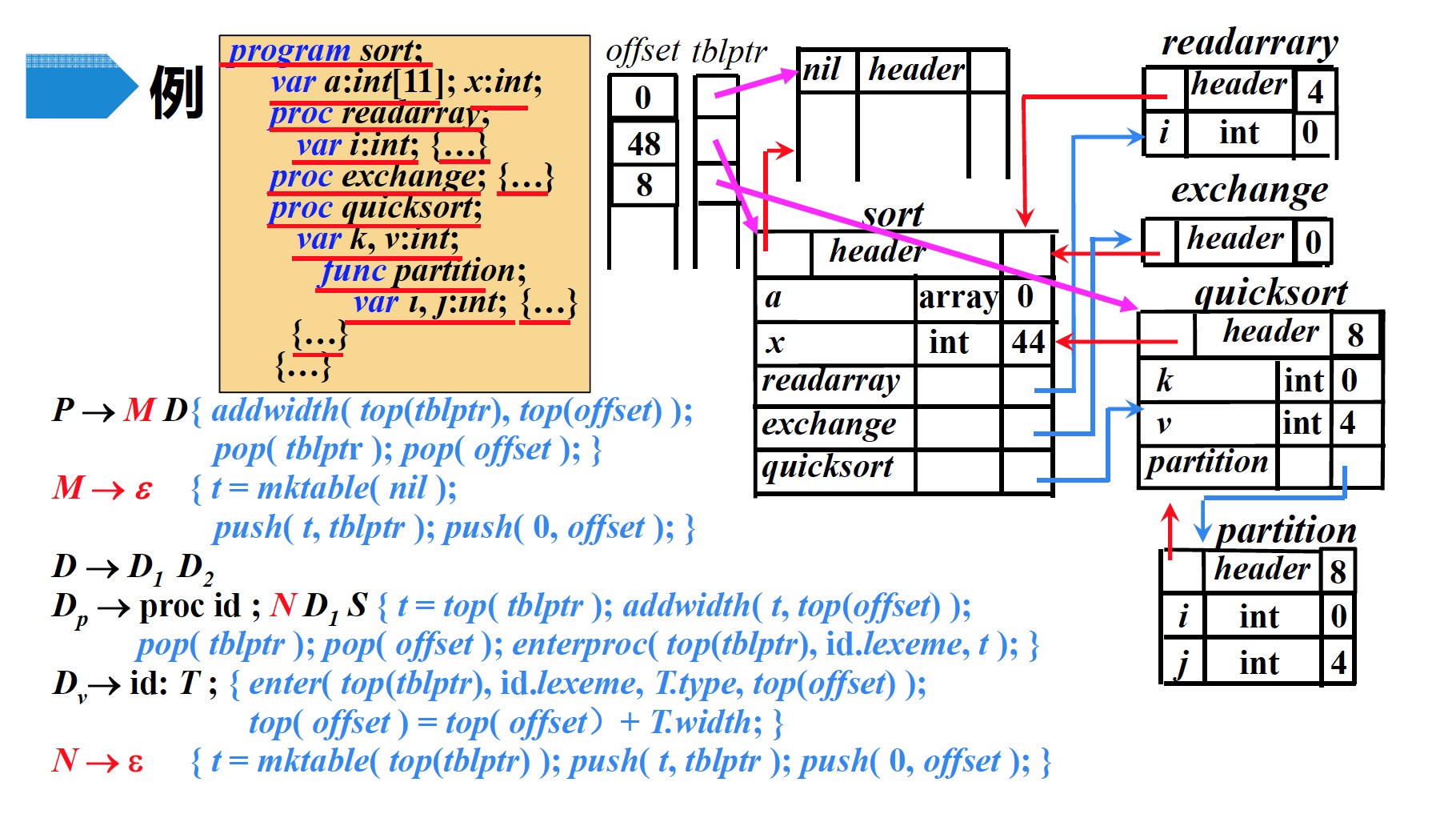
quicksort的代码段字符串,根据产生式$D_p \to proc\;id ; N\;D_1\;S$进行归约,然后执行归约后的语义动作- 将$offset$栈顶记录的偏移量(8)记录到符号表$quicksort$中的
header部分 - $offset$与$tblptr$各自弹出栈顶元素
- 在$tblptr$栈顶指针指向的符号表($sort$)中建立一条记录$quicksort$,存放指向符号表$quicksort$的指针
- 将$offset$栈顶记录的偏移量(8)记录到符号表$quicksort$中的
- 读入
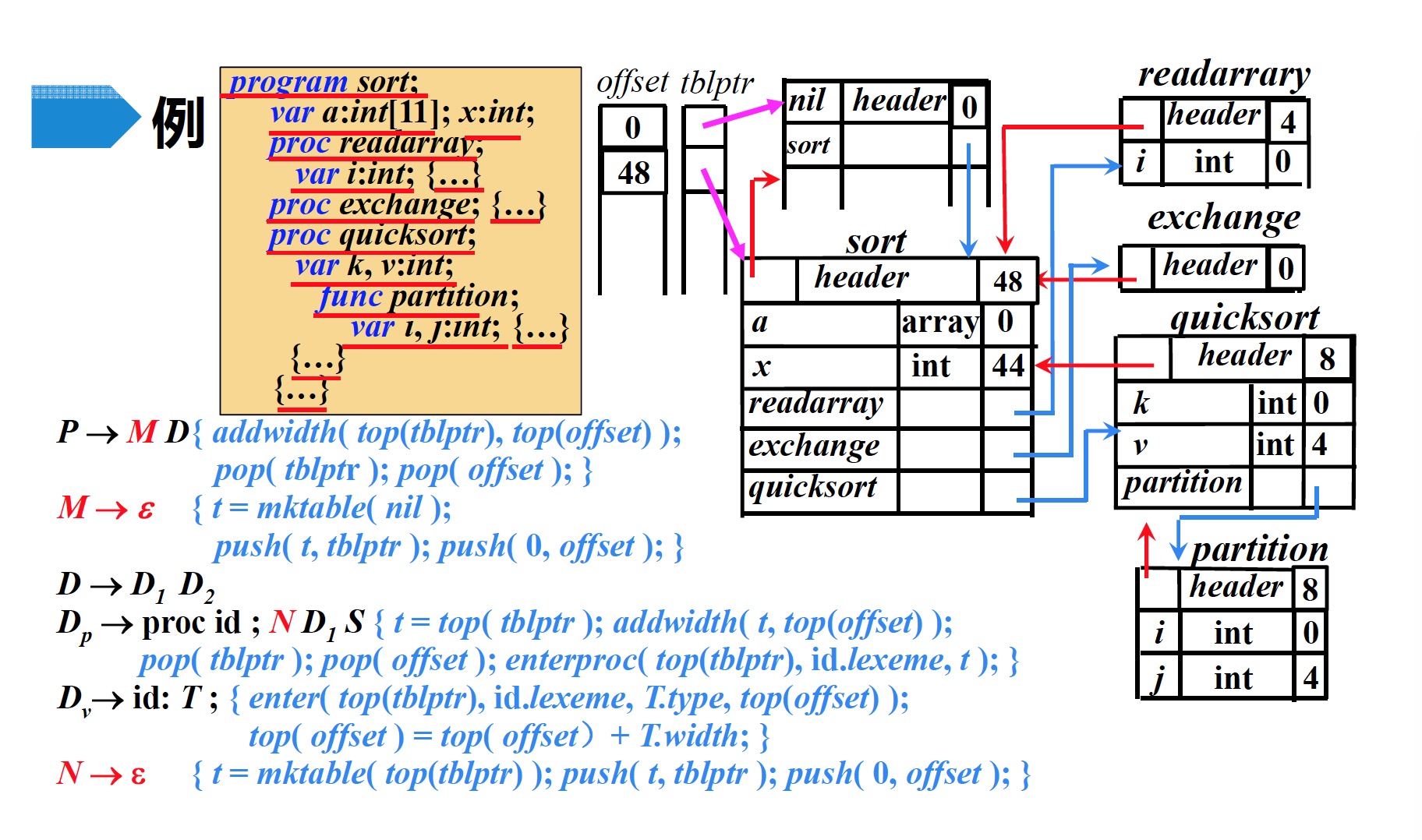
sort的代码段字符串,根据产生式$D_p \to proc\;id ; N\;D_1\;S$进行归约,然后执行归约后的语义动作- 将$offset$栈顶记录的偏移量(48)记录到符号表$sort$中的
header部分 - $offset$与$tblptr$各自弹出栈顶元素
- 在$tblptr$栈顶指针指向的符号表($nil$)中建立一条记录$sort$,存放指向符号表$sort$的指针
- 将$offset$栈顶记录的偏移量(48)记录到符号表$sort$中的
- 根据产生式$P \to M\;D$进行归约,然后执行归约后的语义动作
- 将$offset$栈顶记录的偏移量(0)记录到符号表$nil$中的
header部分 - $offset$与$tblptr$各自弹出栈顶元素
- 将$offset$栈顶记录的偏移量(0)记录到符号表$nil$中的
9 参考
- 《MOOC-编译原理-陈鄞》