阅读更多
1 在递归的预测分析过程中进行翻译
为每个非终结符$A$构造一个函数,$A$的每个继承属性对应该函数的一个形参,函数的返回值是$A$的综合属性值。对出现在A产生式中的每个文法符号的每个属性都设置一个局部变量
非终结符$A$的代码根据当前的输入决定使用哪个产生式
与每个产生式有关的代码执行如下动作:从左到右考虑产生式右部的词法单元、非终结符及语义动作
- 对于带有综合属性$x$的词法单元$X$,把$x$的值保存在局部变量$X.x$中;然后产生一个匹配$X$的调用,并继续输入
- 对于非终结符$B$,产生一个右部带有函数调用的赋值语句$c := B(b_1, b_2, ..., b_k)$,其中,$b_1, b_2, ..., b_k$是代表$B$的继承属性的变量,$c$是代表$B$的综合属性的变量
- 对于每个动作,将其代码复制到语法分析器,并把对属性的引用改为对相应变量的引用




2 L-属性定义的自底向上翻译
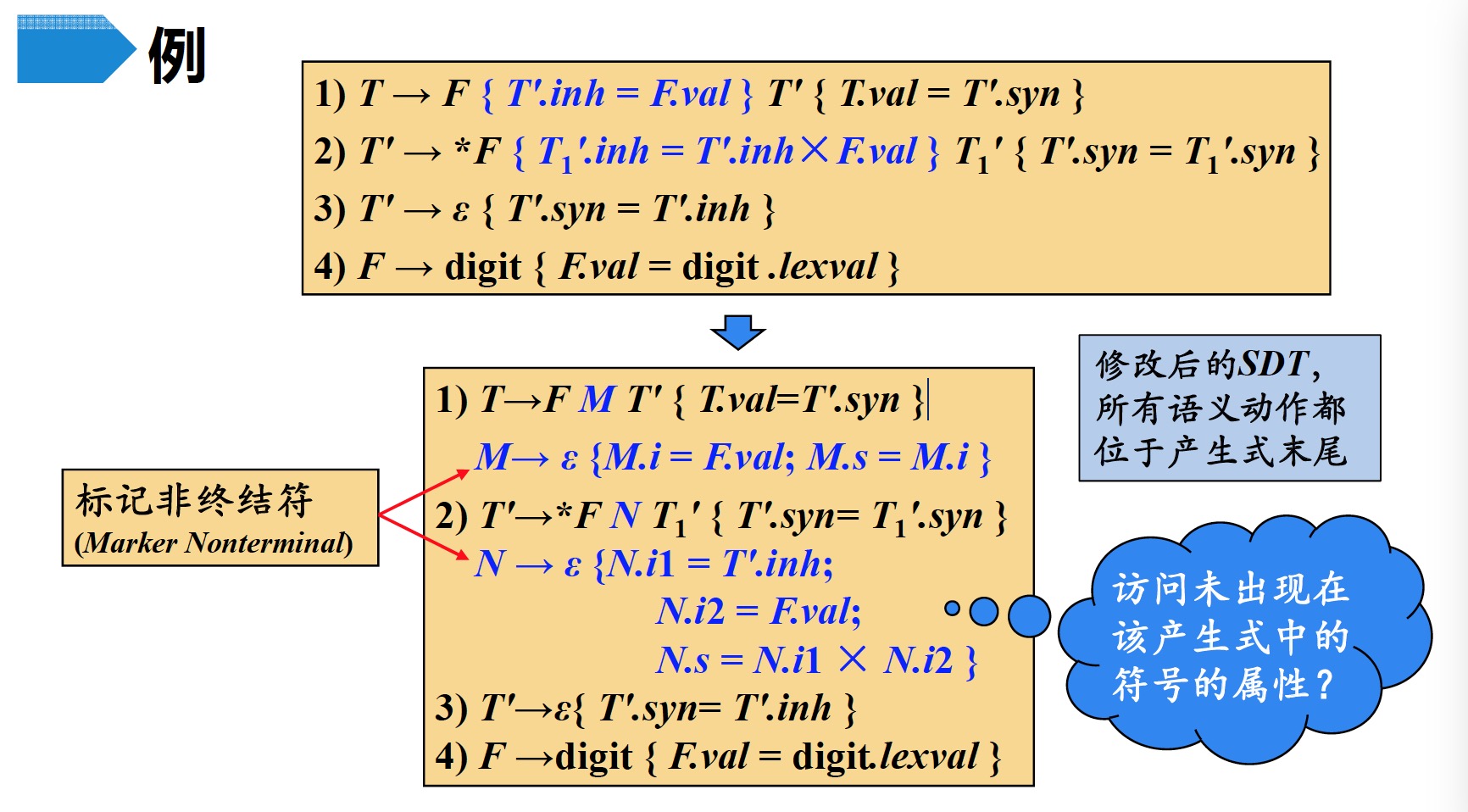
给定一个以LL文法为基础的L-SDD,可以修改这个文法,并在LR语法分析过程中计算这个新文法之上的SDD
- 首先构造SDT,在各个非终结符之前放置语义动作来计算它的继承属性,并在产生式后端放置语义动作计算综合属性
- 对每个内嵌的语义动作,向文法中引入一个标记非终结符来替换它。每个这样的位置都有一个不同的标记,并且对于任意一个标记$M$都有一个产生式$M \to \varepsilon$
- 如果标记非终结符$M$在某个产生式$A \to \alpha \{ a \} \beta$中替换了语义动作$a$,对$a$进行修改得到$a^{\prime}$ ,并且将$a^{\prime}$关联到$M \to \varepsilon$上。动作$a^{\prime}$
- 将动作$a$需要的$A$或$\alpha$中符号的任何属性作为$M$的继承属性进行复制
- 按照$a$中的方法计算各个属性,但是将计算得到的这些属性作为$M$的综合属性
2.1 将语义动作改写为可执行的栈操作
$$T \to FMT^{\prime} \{ stack[top-2].val = stack[top].syn;\;top = top-2; \}$$- 归约后,$T$位于$top-2$的位置(弹出3个元素,压入$T$)
- 归约后,$M$位于$top+1$的位置(弹出0个元素,压入$M$)
- 归约后$T^{\prime}$位于$top-3$的位置(弹出4个元素,压入$T^{\prime}$)
- 归约后$N$位于$top+1$的位置(弹出0个元素,压入$N$)
- 归约后$T^{\prime}$位于$top+1$的位置(弹出0个元素,压入$T^{\prime}$)
- 归约后$F$位于$top$的位置(弹出1个元素,压入$F$)
3 参考
- 《MOOC-编译原理-陈鄞》