阅读更多
1 聚簇索引
聚簇索引又可以称为聚合索引
在《数据库原理》里面,对聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的解释是:索引顺序与数据物理排列顺序无关。正式因为如此,所以一个表最多只能有一个聚簇索引
不过这个定义太抽象了,我们可以这么理解,如下图
- 聚簇索引:叶节点就是数据节点
- 非聚簇索引:叶节点仍然是索引节点,只不过有一个指针指向对应的数据块
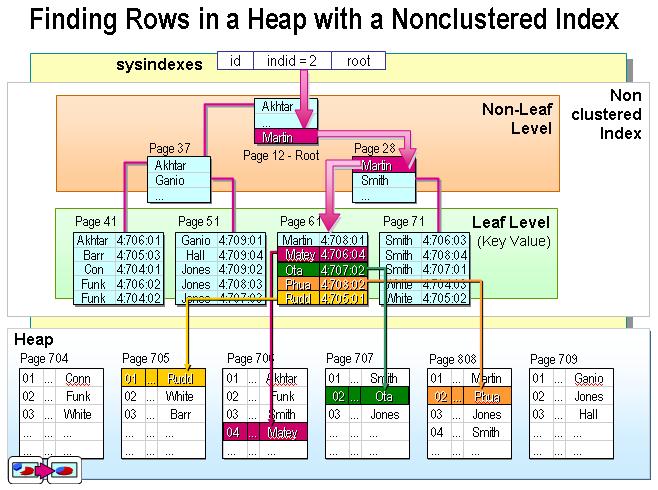
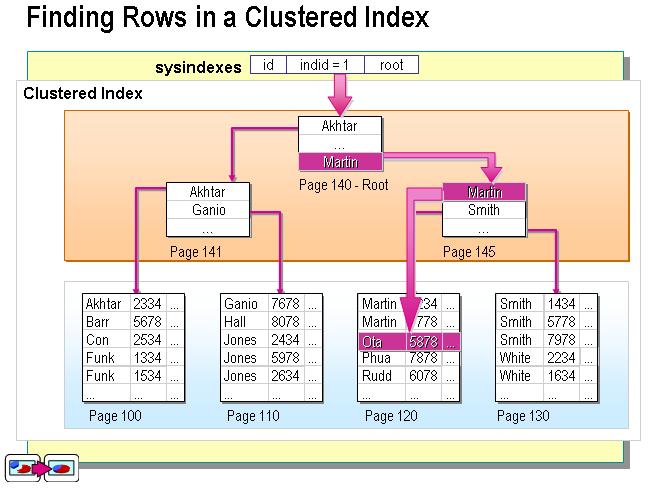
MySQL的聚簇索引是指InnoDB引擎的特性,MYISAM并没有,如果需要该索引,只要将索引指定为主键
InnoDB引擎的聚簇索引(clustered index)
- 有主键时,根据主键创建聚簇索引
- 没有主键时,会用一个唯一且不为空的索引列做为主键,成为此表的聚簇索引
- 如果以上两个都不满足那innodb自己创建一个虚拟的聚集索引
聚簇索引主键的插入速度要比非聚簇索引主键的插入速度慢很多。相比之下,聚簇索引适合排序,非聚簇索引(也叫二级索引)不适合用在排序的场合。因为聚簇索引本身已经是按照物理顺序放置的,排序很快。非聚簇索引则没有按序存放,需要额外消耗资源来排序
当你需要取出一定范围内的数据时,用聚簇索引也比用非聚簇索引好
另外,二级索引需要两次索引查找,而不是一次才能取到数据,因为存储引擎第一次需要通过二级索引找到索引的叶子节点,从而找到数据的主键,然后在聚簇索引中用主键再次查找数据
聚簇索引的优点:提高数据访问性能。聚簇索引把索引和数据都保存到同一棵B+树数据结构中,并且同时将索引列与相关数据行保存在一起。这意味着,当你访问同一数据页不同行记录时,已经把页加载到了Buffer中,再次访问的时候,会在内存中完成访问,不必访问磁盘。不同于MyISAM引擎,MyISAM引擎将索引和数据分开存放,放在不同的物理文件中,索引文件是缓存在key_buffer中,索引对应的是磁盘位置,不得不通过磁盘位置访问磁盘数据
聚簇索引的缺点:
- 维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(page split)的时候。建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZE TABLE优化表,因为被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
- 表因为使用uuid作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面更慢,所以建议使用int的auto_increment作为主键
- 如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值;过长的主键值,会导致非叶子节点占用占用更多的物理空间
2 辅助索引
在聚簇索引之上创建的索引称之为辅助索引,辅助索引访问数据总是需要二次查找。辅助索引叶子节点存储的不再是行的物理位置,而是主键值。通过辅助索引首先找到的是主键值,再通过主键值找到数据行的数据叶,再通过数据叶中的Page Directory找到数据行
2.1 复合索引
由多列创建的索引称为复合索引,在复合索引中的前导列必须出现在WHERE子句中,否则索引不会生效
2.2 前缀索引
当索引的字符串列很大时,创建的索引也就变得很大,为了减小索引体积,提高索引的扫描速度,就用索引的前缀子串部分索引,这样索引占用的空间就会大大减少,并且索引的选择性也不会降低很多
对BLOB和TEXT列进行索引,或者非常长的VARCHAR列,就必须使用前缀索引,因为MySQL不允许索引它们的全部长度
2.3 唯一索引
唯一索引比较好理解,就是索引值必须唯一,这样的索引选择性是最好的
2.4 主键索引
主键索引就是唯一索引,不过主键索引是在创建表时就创建了,唯一索引可以随时创建。一般InnoDB的主键索引就是聚合索引
3 最左匹配原则
下面以一个例子来说明最左匹配原则
假设,我们以name、birthday、phone_num建立一个联合索引
1 | CREATE TABLE person_info( |
这个索引是按如下方式构建的(可以这么理解)
- 首先按照name排序
- 然后按照birthday排序
- 最后按照phone_number排序
以下查询中索引生效
1 | SELECT * FROM person_info WHERE name = '张三' AND birthday = '2000-01-01' AND phone_number = '123456789'; |
以下查询中索引完全失效
1 | SELECT * FROM person_info WHERE birthday = '2000-01-01' AND phone_number = '123456789'; |
以下查询中索引部分失效
1 | SELECT * FROM person_info WHERE name = '张三' phone_number = '123456789'; |
4 索引覆盖
包含所有满足查询需要的数据的索引称为覆盖索引,即利用索引返回SELECT列表中的字段,而不必根据索引再次读取数据文件
5 索引相关操作
创建唯一索引
1 | CREATE UNIQUE INDEX index_name ON table_name(column_name); |
创建单列一般索引
1 | CREATE INDEX index_name ON table_name(column_name); |
创建单列前缀索引
1 | CREATE INDEX index_name ON table_name(column_name(10)); //单列的前10个字符创建前缀索引 |
创建复合索引
1 | CREATE INDEX index_name ON table_name(column_name1,column_name2); //多列的复合索引 |
删除索引
1 | DROP INDEX index_name on table_name;; |
查看索引
1 | SHOW INDEX FROM table_name; |
6 Bitmap Index
Bitmap索引是一种数据库索引,它使用位图(Bitmap)表示索引的数据。每一个不同的值都有一个对应的位图。
基数(Cardinality)在数据库中通常是指某个字段具有的不同值的数量。在Bitmap索引的上下文中,我们指的是需要多少个不同的位图
假设我们有一个T-Shirt Size字段,它可以有三个值:S、M和L,那么这个字段的基数就是3。我们可以为每个值创建一个位图。
现在,假设我们有下表的数据:
| UserID | T-Shirt Size |
|---|---|
| 1 | S |
| 2 | M |
| 3 | L |
| 4 | S |
| 5 | M |
| 6 | L |
| 7 | S |
| 8 | M |
| 9 | L |
| 10 | S |
对应的Bitmap索引会是:
S的位图为:1001001001M的位图为:0100100100L的位图为:0010010010
在这个例子中,T-Shirt Size的基数为3,因为它有三个可能的值。这就意味着我们需要三个位图来代表这个字段的索引