阅读更多
1 前言
本篇文章针对MySQL的InnoDB数据库引擎
2 ACID
A:事务的原子性(Atomicity):指一个事务要么全部执行,要么不执行。也就是说一个事务不可能只执行了一半就停止了。比如你从取款机取钱,这个事务可以分成两个步骤:1划卡,2出钱。不可能划了卡,而钱却没出来。这两步必须同时完成,要么就不完成
C:事务的一致性(Consistency):指事务的运行并不改变数据库中数据的一致性。例如,完整性约束了a+b=10,一个事务改变了a,那么b也应该随之改变
I:独立性(Isolation):事务的独立性也有称作隔离性,是指两个以上的事务不会出现交错执行的状态。因为这样可能会导致数据不一致
D:持久性(Durability):事务的持久性是指事务执行成功以后,该事务所对数据库所作的更改便是持久的保存在数据库之中,不会无缘无故的回滚
3 名词解释
3.1 第一类丢失更新
A事务撤销时,把已经提交的B事务的更新数据覆盖了
| 时间 | 取款事务A | 转账事务B |
|---|---|---|
| T1 | 开始事务 | / |
| T2 | / | 开始事务 |
| T3 | 查询账户余额为1000元 | / |
| T4 | / | 查询账户余额为1000元 |
| T5 | / | 汇入100元,把余额改为1100元 |
| T6 | / | 提交事务 |
| T7 | 取出100元,把余额改为900元 | / |
| T8 | 撤销事务 | / |
| T9 | 余额恢复为1000元(丢失更新) | / |
第一类丢失更新的本质是:回滚覆盖,这个基本上可以算是数据库实现的bug了,mysql的任何隔离级别都不会有这个问题
3.2 第二类丢失更新
A事务覆盖B事务已经提交的数据,造成B事务所作的操作丢失
| 时间 | 取款事务A | 转账事务B |
|---|---|---|
| T1 | / | 开始事务 |
| T2 | 开始事务 | / |
| T3 | / | 查询账户余额为1000元 |
| T4 | 查询账户余额为1000元 | / |
| T5 | / | 取出100元,把余额改为900元 |
| T6 | / | 提交事务 |
| T7 | 汇入100元 | / |
| T8 | 提交事务 | / |
| T9 | 把余额改为1100元(丢失更新) | / |
第二类丢失更新的本质是:提交覆盖,基于一个过时的查询结果进行更新。因此Repeatable read可以解决第二类丢失更新问题
3.3 脏读
脏读就是指当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据
3.4 不可重复读
是指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读
3.5 幻读
一个事务在前后两次查询同一范围的时候,后一次查询看到了前一次查询没有看到的行。除非上表锁,否则无法阻止插入新的数据
3.6 快照/当前读
快照读是MVCC中的概念,即读的是数据副本,不加任何锁
当前读又称为加锁读或阻塞读,查询的是数据的最新版本,根据加锁的不同,又可以分为两类
SELECT ... LOCK IN SHARE MODE:S锁SELECT ... FOR UPDATE:X锁INSERT / UPDATE / DELETE:X锁
| 快照读 | 当前读 | |
|---|---|---|
| 读未提交 | / | 读取最新版本 |
| 读已提交 | 读取最新一份快照 | 读取最新版本,并加记录锁 |
| 可重复读 | 读取事务开始时的快照 | 读取最新版本,并加记录锁以及间隙锁 |
| 可序列化 | / | 读取最新版本,并加记录锁以及间隙锁 |
4 事务隔离级别以及实现方式
4.1 Read uncommitted(读未提交)
实现方式:
- 事务读数据时不加锁,只有当前读,无快照读
- 事务写数据的时候(写操作时才加锁而不是事务一开始就加锁)加行级独占锁,事务结束释放
行级别的共享锁可以防止两个同时的写操作,但是不会对读产生影响。因此可以避免第一类丢失更新,但是会产生脏读的问题
4.1.1 验证
准备工作
1 | DROP DATABASE IF EXISTS test; |
客户端1
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; -- 修改隔离级别 |
客户端2
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; -- 修改隔离级别 |
客户端1
执行如下操作
1 | mysql> SELECT name FROM test.user WHERE id = 1; -- 查询数据 |
客户端1读取到了客户端2未提交的数据,符合预期
客户端2
执行如下操作
1 | mysql> ROLLBACK; -- 回滚事务 |
客户端1
执行如下操作
1 | mysql> SELECT name FROM test.user WHERE id = 1; -- 查询数据 |
客户端1读取到了客户端2回滚后的数据,符合预期。接下来我们分析一下加锁情况(接着上面操作继续)
客户端1
执行如下操作
1 | mysql> UPDATE test.user SET name = '李四' WHERE id = 1; -- 更新数据 |
客户端2
执行如下操作
1 | mysql> BEGIN; -- 开始事务 |
客户端2阻塞了,符合预期
客户端3
执行如下操作
1 | mysql> SELECT * FROM information_schema.INNODB_LOCKS; -- 查看锁状态 |
可以看到写操作是有锁的,而且是X锁(排他锁)
客户端3
执行如下操作
1 | mysql> SELECT * FROM information_schema.INNODB_TRX; -- 查看事务状态 |
可以看出,一个事务(Client1)处于RUNNING状态,另一个事务(Client2)处于锁定状态。且独占锁在写操作后并未释放,而是等到事务结束后才释放
4.2 Read committed(读已提交)
实现方式:
- 事务读数据(对于mysql而言,特指S锁当前读)的时候(读操作时才加锁而不是事务一开始就加锁)加行级共享锁,读完释放
- 事务写数据的时候(写操作时才加锁而不是事务一开始就加锁)加行级独占锁,事务结束释放
由于事务写操作加上独占锁,因此事务写操作时,读操作不能进行,因此,不能读到事务的未提交数据,避免了脏读问题,但是由于读操作的锁加在读上面,而不是加在事务之上,所以,在同一事务的两次读操作之间可以插入其他事务的写操作,所以可能发生不可重复读的问题
4.2.1 验证
可以很负责人的跟大家说,MySQL中的READ COMMITTED隔离级别不单单是通过加锁实现的,实际上还有REPEATABLE READ隔离级别,其实这两个隔离级别效果的实现还需要一个辅助,这个辅助就是MVCC-多版本并发控制,但其实它又不是严格意义上的多版本并发控制,是不是很懵,没关系,我们一一剖析
4.2.1.1 快照读
准备工作
1 | DROP DATABASE IF EXISTS test; |
客户端1
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; -- 修改隔离级别 |
客户端2
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; -- 修改隔离级别 |
这里的读事务并没有按照预期那样阻塞,而是读到了写事务(Client1)事务开始前的数据。因为内部使用了MVCC机制,实现了一致性非阻塞读,大大提高了并发读写效率,写不影响读,且读到的是记录的镜像版本
客户端1
执行如下操作
1 | mysql> COMMIT; -- 提交事务 |
客户端2
执行如下操作
1 | mysql> SELECT name FROM test.user WHERE id = 1; -- 查询数据 |
在客户端2的事务中,读到了客户端1所提交的数据,符合预期
4.2.1.2 当前读
准备工作
1 | DROP DATABASE IF EXISTS test; |
客户端1
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; -- 修改隔离级别 |
客户端2
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED; -- 修改隔离级别 |
当前读阻塞,符合预期
客户端1
执行如下操作
1 | mysql> COMMIT; -- 提交事务 |
客户端2
从阻塞中恢复
1 | mysql> SELECT name FROM test.user WHERE id = 1 LOCK IN SHARE MODE; -- 查询数据 |
事务2读到了事务1提交的数据,符合预期
4.3 undo/redo log
数据库通常借助日志来实现事务,常见的有undo log、redo log,undo/redo log都能保证事务特性,这里主要是原子性和持久性,即事务相关的操作,要么全做,要么不做,并且修改的数据能得到持久化
在概念上,innodb通过force log at commit机制实现事务的持久性,即在事务提交的时候,必须先将该事务的所有事务日志写入到磁盘上的redo log file和undo log file中进行持久化
假设数据库在操作时,按如下约定记录日志:
- 事务开始时,记录
START T - 事务修改时,记录
(T, x, v),说明事务T操作对象x,x的值为v - 事务结束时,记录
COMMIT T
4.3.1 undo log
undo log有两个作用:提供回滚和多个行版本控制(MVCC)
undo log是把所有没有COMMIT的事务回滚到事务开始前的状态,系统崩溃时,可能有些事务还没有COMMIT,在系统恢复时,这些没有COMMIT的事务就需要借助undo log来进行回滚
使用undo log时,要求
- 记录修改日志时,
(T, x, v)中v为x修改前的值,这样才能借助这条日志来回滚 - 事务提交后,必须在事务的所有修改(包括记录的修改日志)都持久化后才能写事务
T的COMMIT日志;这样才能保证,宕机恢复时,已经COMMIT的事务的所有修改都已经持久化,不需要回滚
使用undo log时事务执行顺序
- 记录
START T - 记录需要修改的记录的旧值(要求持久化)
- 根据事务的需要更新数据库(要求持久化)
- 记录
COMMIT T
使用undo log进行宕机回滚
- 扫描日志,找出所有已经
START,还没有COMMIT的事务 - 针对所有未
COMMIT的日志,根据undo log来进行回滚
如果数据库访问很多,日志量也会很大,宕机恢复时,回滚的工作量也就很大,为了加快回滚,可以通过checkpoint机制来加速回滚
- 在日志中记录
checkpoint_start(T1, T2, ..., Tn)(Tx代表做checkpoint时,正在进行还未COMMIT的事务) - 等待所有正在进行的事务
(T1~Tn)执行COMMIT操作 - 在日志中记录
checkpoint_end
借助checkpoint来进行回滚:从后往前,扫描undo log
- 如果先遇到
checkpoint_start,则将checkpoint_start之后的所有未提交的事务进行回滚 - 如果先遇到
checkpoint_end,则将前一个checkpoint_start之后所有未提交的事务进行回滚(在checkpoint的过程中,可能有很多新的事务START或者COMMIT)
4.3.2 redo log
为了实现持久化这一特性,必须保证:在事务提交后,所有的数据修改都需要落盘。最简单的做法是在每次事务提交的时候,将该事务涉及修改的数据页全部刷新到磁盘中。但是这么做会有严重的性能问题,主要体现在两个方面
- 因为
Innodb是以页为单位进行磁盘交互的,而一个事务很可能只修改一个数据页里面的几个字节,这个时候将完整的数据页刷到磁盘的话,太浪费资源了 - 一个事务可能涉及修改多个数据页,并且这些数据页在物理上并不连续,使用随机IO写入性能太差
于是mysql设计了redo log,具体来说就是只记录事务对数据页做了哪些修改,这样就能完美地解决性能问题了
- 随机写改为顺序写
- 每次写改为批量写
redo log包括两部分:一个是内存中的日志缓冲redo log buffer,另一个是磁盘上的日志文件redo log file。mysql每执行一条DML语句,先将记录写入redo log buffer,后续某个时间点再一次性将多个操作记录写到redo log file。这种先写日志,再写磁盘的技术就是WAL(Write-Ahead Logging)技术
使用redo log时事务执行顺序
- 记录
START T - 记录事务需要修改记录的新值(要求持久化)
- 记录
COMMIT T(要求持久化) - 将事务相关的修改写入数据库
在日志中使用checkpoint
- 在日志中记录
checkpoint_start(T1, T2, ..., Tn)(Tx代表做checkpoint时,正在进行还未COMMIT的日志) - 将所有已提交的事务的更改进行持久化
- 在日志中记录
checkpoint_end
根据checkpoint来加速恢复:从后往前,扫描redo log
- 如果先遇到
checkpoint_start,则把T1~Tn以及checkpoint_start之后的所有已经COMMIT的事务进行重做 - 如果先遇到
checkpoint_end,则T1~Tn以及前一个checkpoint_start之后所有已经COMMIT的事务进行重做
4.4 MVCC机制剖析
在MySQL中MVCC(Multi-Version Concurrency Control)是在Innodb存储引擎中得到支持的,Innodb为每行记录都实现了三个隐藏字段:
- 隐藏的ID
- 6字节的事务ID(
DB_TRX_ID):当某个事务对某条记录进行改动时,对会把对应的事务id赋值给该字段 - 7字节的回滚指针(
DB_ROLL_PTR):可以通过这个指针找到该记录修改前的信息
MVCC在MySQL中的实现依赖的是undo log与read view
undo log:undo log中记录的是数据表记录行的多个版本,也就是事务执行过程中的回滚段,其实就是MVCC中的一行原始数据的多个版本镜像数据read view:主要用来判断当前版本数据的可见性
行的更新过程
- 初始数据行
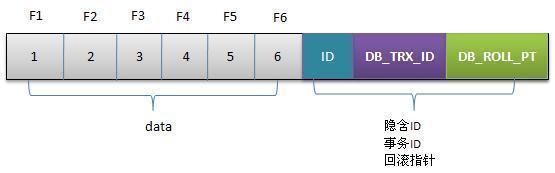
- F1~F6是某行列的名字,1~6是其对应的数据。后面三个隐含字段分别对应该行的事务号和回滚指针,假如这条数据是刚INSERT的,可以认为ID为1,其他两个字段为空
- 事务1更改该行的各字段的值
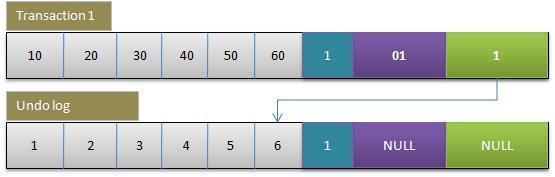
- 当事务1更改该行的值时,会进行如下操作:
- 用排他锁锁定该行
- 记录redo log
- 把该行修改前的值Copy到
undo log,即上图中下面的行 - 修改当前行的值,填写事务编号,使回滚指针指向
undo log中的修改前的行
- 事务2修改该行的值
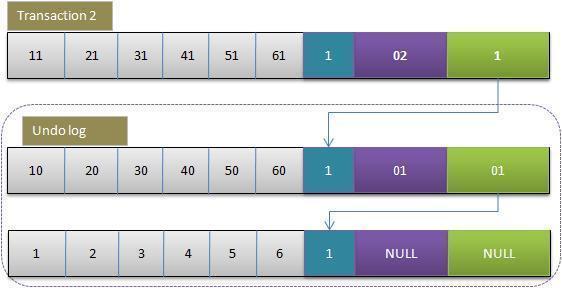
- 与事务1相同,此时
undo log,中有有两行记录,并且通过回滚指针连在一起
read view判断当前版本数据项是否可见:在innodb中,创建一个新事务的时候,innodb会将当前系统中的活跃事务列表创建一个副本(read view),副本中保存的是系统当前不应该被本事务看到的其他事务id列表。当用户在这个事务中要读取该行记录的时候,innodb会将该行当前的版本号与该read view进行比较。主要的概念如下
m_ids:表示在生成read view时,当前系统中活跃的读写事务id列表min_trx_id:表示在生成read view时,当前系统中活跃的读写事务中最小的事务id,也就是m_ids中最小的值max_trx_id:表示在生成read view时,系统中应该分配给下一个事务的id值creator_trx_id:表示在生成read view时,事务的id
read view具体的算法如下:
- 设该行的当前事务id为
trx_id
- 如果被访问版本的
trx_id,与read view中的creator_trx_id值相同,表明当前事务在访问自己修改过的记录,该版本可以被当前事务访问 - 如果被访问版本的
trx_id,小于read view中的min_trx_id值,表明生成该版本的事务在当前事务生成read view前已经提交(m_ids存的是活跃的事务列表,如果不在这个列表中的话,就表示已提交),该版本可以被当前事务访问 - 如果被访问版本的
trx_id,大于或等于read view中的max_trx_id值,表明生成该版本的事务在当前事务生成read view后才开启,该版本不可以被当前事务访问 - 如果被访问版本的
trx_id,值在read view的min_trx_id和max_trx_id之间,就需要判断trx_id属性值是不是在m_ids列表中- 如果在:说明创建
read view时生成该版本的事务还是活跃的,该版本不可以被访问 - 如果不在:说明创建
read view时生成该版本的事务已经被提交,该版本可以被访问
- 如果在:说明创建
生成read view时机
RC隔离级别:每次读取数据前,都生成一个read view,只要当前语句执行前已经提交的数据都是可见的RR隔离级别:在第一次读取数据前,生成一个read view,只要是当前事务执行前已经提交的数据都是可见的
4.4.1 问题
- 事务尚未提交或者回滚之前,已经修改的数据是否会持久化到磁盘上?
- 会持久化到硬盘中。这也就是为什么在
Read uncommitted这一事务隔离级别中,可以读取到未提交的数据 - 在
Read committed及Repeatable read事务隔离级别中,其他事务可以通过undo log来读取记录的初始值
- 会持久化到硬盘中。这也就是为什么在
- 事务A更新某一行,提交;事务B同时更新同一行,回滚(在时间上,提交早于回滚)。
undo log如何工作?- 当前事务id记为
id_current,事务B对应的undo log中记录的原始数据的事务id记为id_original,若id_current > id_original且id_current对应的事务已提交,那么不做任何操作(这只是我的猜想)
- 当前事务id记为
4.5 Repeatable read(可重复读)
实现方式:
- 事务读数据(对于mysql而言,特指S锁当前读)的时候(读操作时才加锁而不是事务一开始就加锁)加行级共享锁,事务结束释放
- 事务写数据的时候(写操作时才加锁而不是事务一开始就加锁)加行级独占锁,事务结束释放
由于事务读操作在事务结束后才释放共享锁,因此可以避免在同一读事务中读取到不同的数据,另外可以避免第二类丢失更新的问题
4.5.1 验证
真实情况是:读不影响写,写不影响读
- 读不影响写:事务以排他锁的形式修改原始数据,读时不加锁,因为MySQL在事务隔离级别Read committed 、Repeatable Read下,InnoDB存储引擎采用非锁定性一致读–即读取不占用和等待表上的锁。即采用的是MVCC中一致性非锁定读模式。因读时不加锁,所以不会阻塞其他事务在相同记录上加X锁来更改这行记录
- 写不影响读:事务以排他锁的形式修改原始数据,当读取的行正在执行delete或者update 操作,这时读取操作不会因此去等待行上锁的释放。相反地,InnoDB存储引擎会去读取行的一个快照数据
4.5.1.1 当前读
准备工作
1 | DROP DATABASE IF EXISTS test; |
客户端1
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- 修改隔离级别 |
客户端2
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- 修改隔离级别 |
这里的读事务并没有按照预期那样阻塞,而是读到了写事务(Client1)事务开始前的数据。因为内部使用了MVCC机制,实现了一致性非阻塞读,大大提高了并发读写效率,写不影响读,且读到的是记录的镜像版本
客户端1
执行如下操作
1 | mysql> COMMIT; -- 提交事务 |
客户端2
执行如下操作
1 | mysql> SELECT name FROM test.user WHERE id = 1; -- 查询数据 |
在客户端2的事务中,读到的还是事务1提交之前的数据,符合预期
4.5.1.2 当前读
准备工作
1 | DROP DATABASE IF EXISTS test; |
客户端1
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- 修改隔离级别 |
客户端2
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- 修改隔离级别 |
当前读阻塞,符合预期
客户端1
执行如下操作
1 | mysql> COMMIT; -- 提交事务 |
客户端2
从阻塞中恢复
1 | mysql> SELECT name FROM test.user WHERE id = 1 LOCK IN SHARE MODE; -- 查询数据 |
4.6 Serializable(串行化)
实现方式:
- 事务读数据的时候(读操作时才加锁而不是事务一开始就加锁)加表级共享锁,事务结束释放
- 事务写数据的时候(写操作时才加锁而不是事务一开始就加锁)加表级独占锁,事务结束释放
4.6.1 验证
准备工作
1 | DROP DATABASE IF EXISTS test; |
客户端1
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; -- 修改隔离级别 |
客户端2
执行如下操作
1 | mysql> SET SESSION TRANSACTION ISOLATION LEVEL SERIALIZABLE; -- 修改隔离级别 |
此时Client2阻塞了,与预期一致
客户端1
执行如下操作
1 | mysql> COMMIT; -- 提交事务 |
此时,客户端2从阻塞中恢复,显示查询结果
1 | +--------+ |
4.7 总结
| 隔离级别 | 是否出现脏读 | 是否出现不可重复读 | 是否出现幻读 | 是否出现第一类丢失更新 | 是否出现第二类丢失更新 |
|---|---|---|---|---|---|
| Serializable | 否 | 否 | 否 | 否 | 否 |
| Repeatable read | 否 | 否 | 是 | 否 | 否 |
| Read committed | 否 | 是 | 是 | 否 | 是 |
| Read uncommitted | 是 | 是 | 是 | 否 | 是 |
5 如何查看/修改隔离级别
修改隔离级别
1 | SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE} |
- 默认的行为(不带session和global)是为下一个(未开始)事务设置隔离级别
- 如果你使用GLOBAL关键字,语句在全局对从那点开始创建的所有新连接(除了不存在的连接)设置默认事务级别。你需要SUPER权限来做这个
- 使用SESSION关键字为将来在当前连接上执行的事务设置默认事务级别。任何客户端都能自由改变会话隔离级别(甚至在事务的中间),或者为下一个事务设置隔离级别
查询隔离级别
1 | SELECT @@global.tx_isolation; |
6 死锁问题分析
准备工作
1 | -- 将隔离级别设置为 RR |
1 | mysql> SELECT * FROM test; |
下面构造死锁场景

接下来使用SHOW ENGINE INNODB STATUS;命令可以查看死锁日志
1 | SHOW ENGINE INNODB STATUS; |
7 参考
- 数据库事务隔离级别和锁的实现方式
- 第一类第二类丢失更新
- 数据库事务隔离级别-- 脏读、幻读、不可重复读(清晰解释)
- 数据库事务特征、数据库隔离级别,以及各级别数据库加锁情况(含实操)–read uncommitted篇
- 数据库事务特征、数据库隔离级别,各级别数据库加锁情况(含实操)–read committed && MVCC
- 数据库事务特征、数据库隔离级别,各级别数据库加锁情况(含实操)–Repeatable Read && MVCC
- MVCC原理探究及MySQL源码实现分析
- mysql版本链&readview
- Mysql加锁过程详解
- Innodb中的事务隔离级别实现原理
- MySQL数据库事务各隔离级别加锁情况–read committed && MVCC
- 记录一次Mysql死锁排查过程
- 一分钟理清Mysql的锁类型——《深究Mysql锁》
- InnoDB locking
- undo log与redo log原理分析
- 数据库基础(四)Innodb MVCC实现原理
- 详细分析MySQL事务日志(redo log和undo log)
- 必须了解的mysql三大日志-binlog、redo log和undo log